

基于预训练视觉-语言模型的跨模态Prompt-Tuning
描述
论文:CPT:Colorful Prompt Tuning for Pre-Training Vision-Language Models
状态:Work in Progress
单位:清华大学、新加坡国立大学
链接:https://arxiv.org/pdf/2109.11797.pdf
提取摘要
预训练的视觉语言模型 (VL-PTMs) 在将自然语言融入图像数据中显示出有前景的能力,促进了各种跨模态任务。
然而,作者注意到模型pre-training和finetune的客观形式之间存在显着差距,导致需要大量标记数据来刺激 VL-PTMs 对下游任务的视觉基础能力。
为了应对这一挑战,本文提出了跨模态提示调优Cross-modal Prompt Tuning(CPT,或者,彩色-Color提示调优),这是一种用于finetune VL-PTMs 的新范式,它在图像和文本中使用基于颜色的共同参照标记重新构建了视觉定位问题,使之成为一个填空问题,最大限度地缩小差距。
通过这种方式,本文的Prompt-Tuning方法可以让 VL-PTMs 在少样本甚至零样本的强大的视觉预测能力。
综合实验结果表明,Prompt-Tuning的 VL-PTMs 大大优于 finetune 的方法(例如,在 RefCOCO 评估中,一次平均提高 17.3% 准确度,one shot下平均相对标准偏差降低73.8%)。
数据和代码会在之后公开,小伙伴们不要急~
方法介绍
背景:该任务为Visual Grounding视觉定位问题,通过一个给定的expression来定位在图像中的位置。
Pre-training和fine-tuning
比如有一张识别好的图片和下面的文字:

普通使用MLM(masked language modeling)的预训练模型的到VL-PTMs方法为:

就是使用[mask]机制来预测被被掩盖的token。
而finetune的话,就是使用传统的[CLS]来迁就下游的任务,比如做二分类:
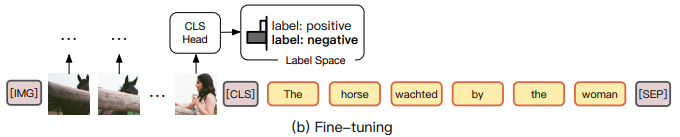
而使用被大规模数据预训练的模型通过[CLS]来迁就下游任务,其实并不可解释,而反过来让下游带着任务来到预训练模型的[mask]战场上,才能更能发挥其作用呀。
CPT: Cross-model Prompt Tuning
CPT方法首先将图片用不同颜色来区分不同的实体模块:

其次将Query Text插入到color-based的模板(eg. is in [mask] color)里:
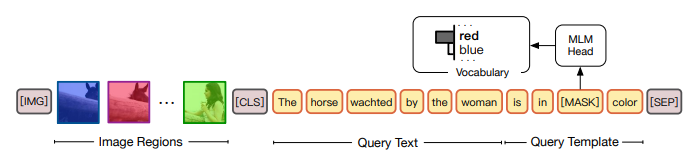
最后在[mask]上预测对应的该是哪个颜色即可,语义上非常行得通。
模型公式
普通Finetune for VL-PLMs
首先从图片 I 中通过目标检测工具,检测出一系列的region:
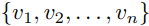
最终这些被选出来的region和Query Text(w)将被放入:
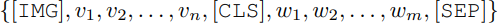
其中[IMG]、[CLS]和[SEP]为特殊token。
其中图片regions的representation通过视觉的encoder获得,而文本的就是lookup即可,最后通过预训练模型VL-PLMs会得到:
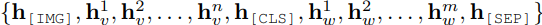
最终使用隐层finetune做分类即可。
但是,finetuned VL-PLMs需要大量的标注数据来提高视觉定位的效果,这个也是一个弊端吧。
Cross-Modal Prompt Tuning - CPT
上面说过了,CPT需要两个部分:
视觉子prompt
文本子prompt
视觉子prompt,目的是为了区分每一个region通过可分辨的标记,比如颜色,比如RGB (255, 0, 0)表示red,RGB和text要对应起来。
这里要注意的是,这个子prompt是直接加在原图片上的,所以既没有改变模型结果,又没有改变参数。
文本子prompt,目的就是在图片和Query Text之间建立一个链接,这里使用的模板为:
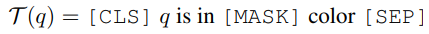
然后,VL-PTMs模型通过这样的提示(prompt)来决定哪个颜色的region填在这个空里最恰当:
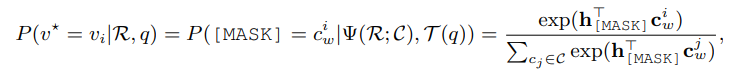
实验
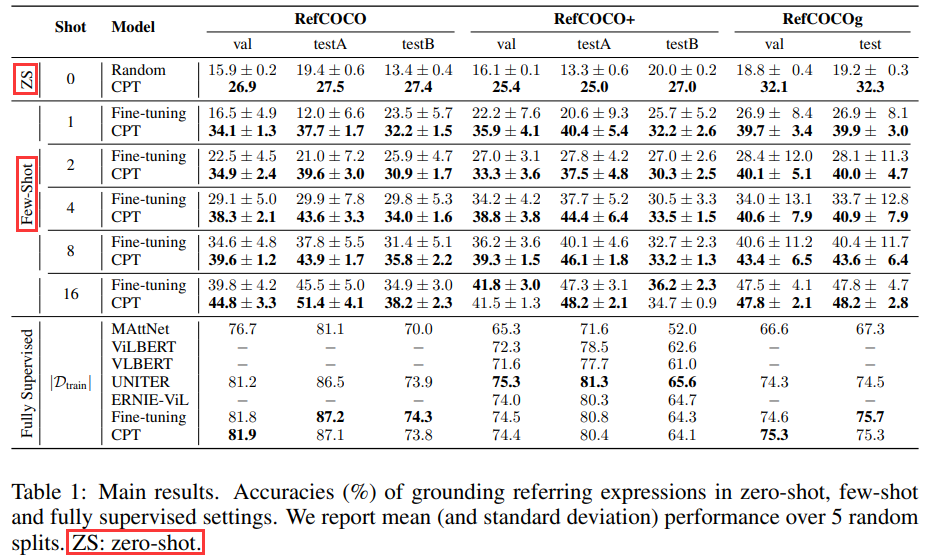
和finetune相比,CPT在zero-shot和few-shot下,性能可以说是爆表,巨额提升。在全量数据下,也能达到最佳值或者接近最佳值:
CPT在其他视觉任务上的应用
实体检测

谓元分类

场景图分类

总之,Prompt方法就是通过模板重新定义了任务,让模型更具有解释性,本篇文章第一次将Prompt用在了Vision-Language上,未来还会有很大的研究动向,感兴趣的小伙伴可以细读原文。
编辑:jq
-
【大语言模型:原理与工程实践】大语言模型的预训练2024-05-07 1590
-
《多模态大模型 前沿算法与实战应用 第一季》精品课程简介2026-05-01 219
-
【完结】多模态与视觉大模型开发实战 - 2026必会2026-07-11 29
-
多模态与视觉大模型开发实战 - 2026必会课分享2026-07-12 4
-
应用于任意预训练模型的prompt learning模型—LM-BFF2021-08-16 5578
-
ACL2021的跨视觉语言模态论文之跨视觉语言模态任务与方法2021-10-13 3682
-
如何更高效地使用预训练语言模型2022-07-08 2154
-
利用视觉语言模型对检测器进行预训练2022-08-08 2518
-
从预训练语言模型看MLM预测任务2022-11-14 4121
-
基于预训练模型和语言增强的零样本视觉学习2023-06-15 1427
-
基于多任务预训练模块化提示2023-06-20 1714
-
更强更通用:智源「悟道3.0」Emu多模态大模型开源,在多模态序列中「补全一切」2023-07-16 1755
-
机器人基于开源的多模态语言视觉大模型2024-01-19 1197
-
预训练模型的基本原理和应用2024-07-03 6132
-
大语言模型的预训练2024-07-11 2002
全部0条评论

快来发表一下你的评论吧 !
