

ntel I9的多核scalability是真的吗
描述
昨天我们用Intel I9的10核,每个核2个threads的机器跑了内核的编译:
超线程SMT究竟可以快多少?
今天,我换一台机器,采用AMD Ryzen。
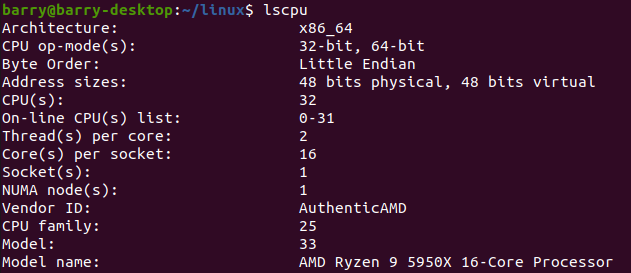
默认情况16核,每个核2个threads,共32个CPUs:
下面编译内核:
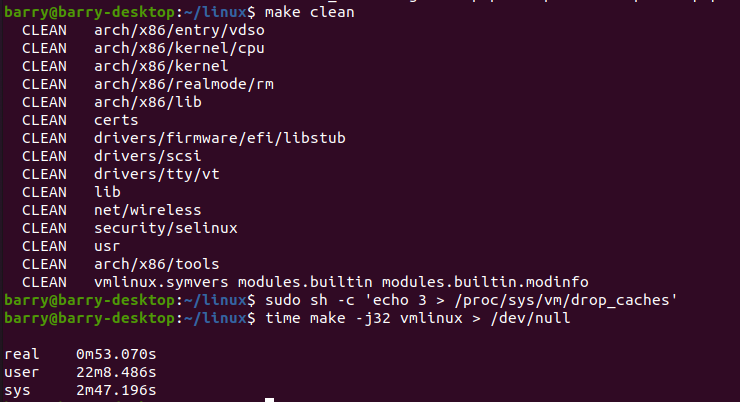
大约需要53秒。记得昨天用Intel I9 10核20线程需要2分钟30秒左右。
再来一遍:

这说明make clean, drop_caches后时间也差不多。51秒,53秒左右的正常抖动范围。
现在我们关闭smt,只保留16个CPU:
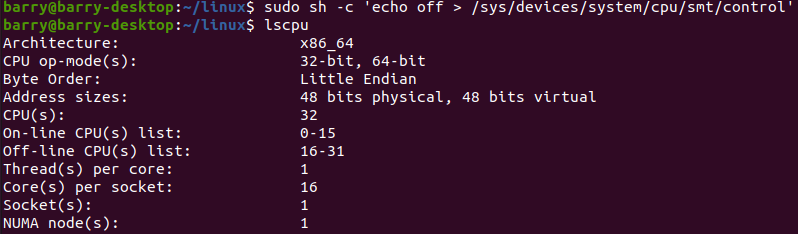
具体的关闭方法就是:
sudo sh -c ‘echo off 》 /sys/devices/system/cpu/smt/control’
这样只剩下16个CPU,下面来编译:

时间57秒,相对于51、53秒,速度下降不到10%。
这说明超线程SMT对编译内核这个workload的性能的提升绝对没有达到100%,甚至都没有达到10%。
我们现在重新开启超线程:
sudo sh -c ‘echo on 》 /sys/devices/system/cpu/smt/control
看一下哪个CPU和哪个CPU是thread sibling:

看起来CPU0和CPU16是一对,CPU1和CPU17是一对,依次类推。
刚才我们关闭SMT是把CPU16-CPU31全关了,只留下每对里面的1个CPU,也就是留下了CPU0-CPU15。
在开启SMT的时候(假设蓝色和红色是一个CORE里面的两个CPU):

在关闭SMT的时候,等于每对里面只留1个CPU:
现在我们换一种关法,一对对关,只留下8对,也就是8个core:
指令如下:
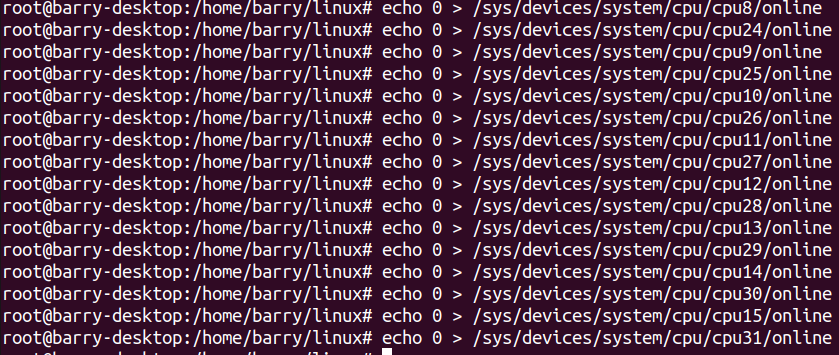
实现效果如下:
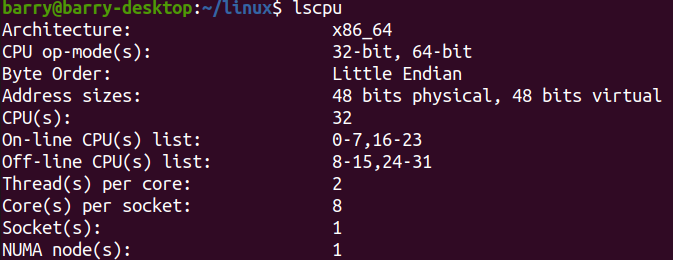
再重新编译内核:

现在耗时是1分21秒,相对于所有CPU全开,下降了很多,时间增大了59%,当然没有达到2倍。
再想想昨天的Intel I9,关闭5个完整核耗时是3分10秒,全开10核是2分30秒,Intel一半核工作和所有核同时工作的差距远不如AMD那么明显。
所以可以看出,就内核编译这个workload而言,AMD的16core相对于8core,性能的scale会更加成正比。当然AMD开关SMT,对内核编译这个workload而言,影响小于10%,而Intel I9的影响有14%。
很多童鞋昨天留言,说编译内核有一定的IO bound,另外提到link阶段是单线程,还有的童鞋说是Intel Turbo的影响,这些我们都认为是有一定道理的。但是,我始终坚信,profiling是检验猜想的唯一标准,后面有空再写一篇文章来profiling一些究竟是为什么。
这到底是为什么?牙膏厂的多核scalability究竟是不是骗纸?还是按摩店的部分核没有Intel部分核的威猛模式?「元芳,你怎么看?」
责任编辑:haq
-
还在追i7吗?英特尔酷睿i9处理器曝光!四个型号最快8月发布2017-05-13 5062
-
英特尔酷睿i9现身跑分 竟为i7至尊版的升级版2017-05-16 2647
-
酷睿i9头号竞争对手:Ryzen 9性能更强大!2017-05-17 1695
-
酷睿i9处理器来了!性能爆表将亮相台湾电脑展2017-05-26 1752
-
这口牙膏挤得猛!Intel酷睿i9半路杀出怒怼AMD Ryzen2017-05-31 1139
-
英特尔推18核i9你怎么看?英特尔十问十答解答酷睿i92017-06-02 1415
-
Intel旗舰i9性能怎么样?十核心酷睿i9-7900X评测:超频能力惊人2017-06-26 16161
-
新篇章的开始 强力反击 AMD 16核Ryzen发布时间曝光!实力叫板Intel i92017-06-30 1500
-
酷睿i9性能竟跑不过4核i7?Intel回应:新总线架构的原因2017-07-12 2727
-
英特尔i9系列曝光目前核心数产品Core i9-7920X:24个框框2017-07-20 2248
-
旗舰中的旗舰:18核酷睿i9处理器的外星人Area51今日发布2017-07-28 3181
-
每秒亿万次!核战正式打响大战AMD锐龙!Intel首款18核Core i9正式宣布9月上市2017-08-08 4366
-
酷睿i9有何不同2019-02-20 8702
-
i7和i9的处理器有什么区别2020-05-22 24651
-
酷睿i9处理器有何不同?2020-10-23 6928
全部0条评论

快来发表一下你的评论吧 !
