

华大HC32F460 HC32F4A0加速程序运行速度
今日头条
描述
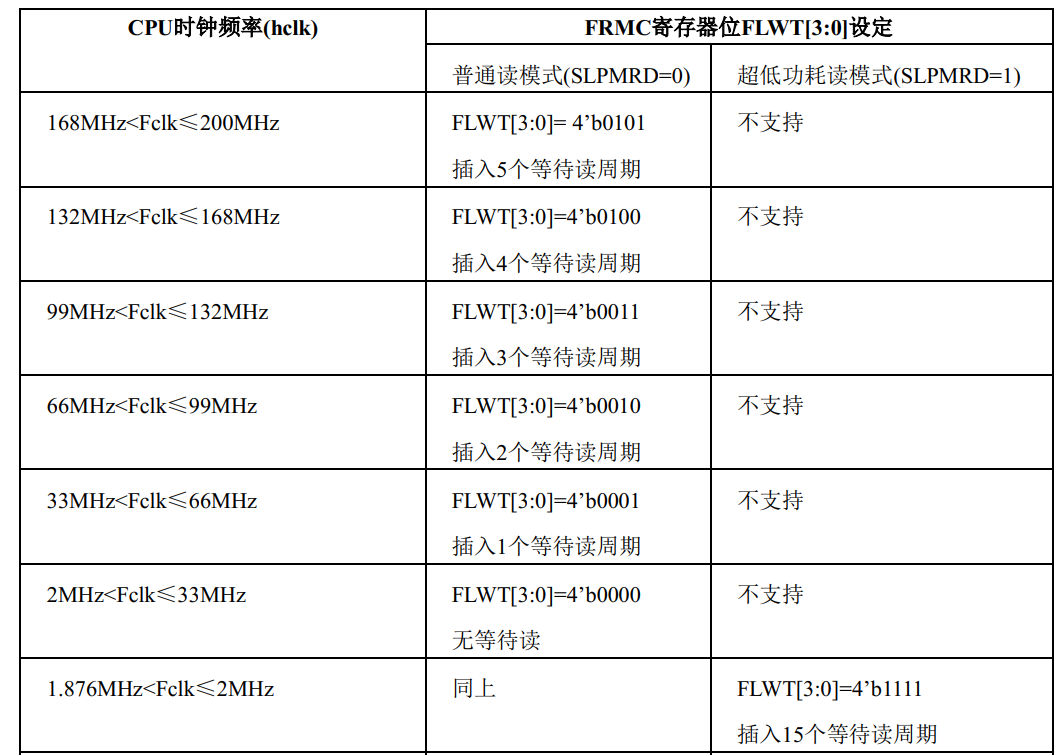
华大单片机HC32F4xx系类(HC32F460 HC32F4A0)可以运行最高200Mhz,但内部Flash在 CPU运行频率达到33M后,就需要加入不同的等待周期。
所以实际程序在内部FLash内运行时,是跟不上CPU速度,也就不能达到最高运行速度200Mhz。
如下图:可以看到在最高200Mhz时,读Flash中的指令需要等待5个CPU时钟周期,那大概200M运行时实际CPU能够跑到不到40Mhz。
那怎么能够使程序运行的快,跑出实际CPU的频率呢?
两种方法:
1.理所应当想到的第一种方法就是把关键程序或需要运行速度的代码搬到SRAM内运行。
这个方法不在本贴讨论范围内,不过原理和细节都不太复杂。
这里提醒以下两点,具体做法也不难,不管是谁家的MCU这种SRAM内运行的方法都是一样的。
1)只需要注意中断向量表要重映射到SRAM中,如果想把中断搬运到SRAM中运行的话。
2)还有一点是,搬运到SRAM内运行的代码如果有调用Flash内代码的,也是会影响速度。需要再把调用链上所有代码一同搬运到SRAM内。
2.就是在华大HC32Fxx系列MCU内,有一个1K大小的FLash Cache,可以使运行FLash内的代码加速,或读取Flash内数据加速。
使运行在Flash内的代码执行速度和CPU速度同频。当然,既然是读的cache,那么如果CPU没有命中cache中的内容,还是会从Flash中取数据和指令的。
所以在整个程序运行期间 cache起到了加速作用,而不能认为每个运行时段程序运行的速度都会和CPU一致。
如果HCLK是200Mhz,那么使能cache后,可以加速程序运行速度到200Mhz。
(千万别认为程序每时每刻都运行在200M,所以也不要用忙等待的方式做延时函数,建议使用systick做忙等待延时函数)
我做了一个试验,测试一段代码运行时在不开启cache和开启cache的运行表现:
测试的这段代码:
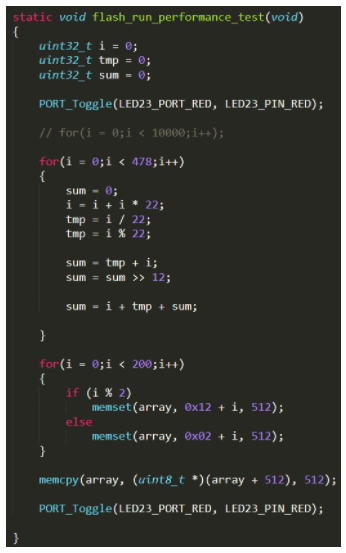
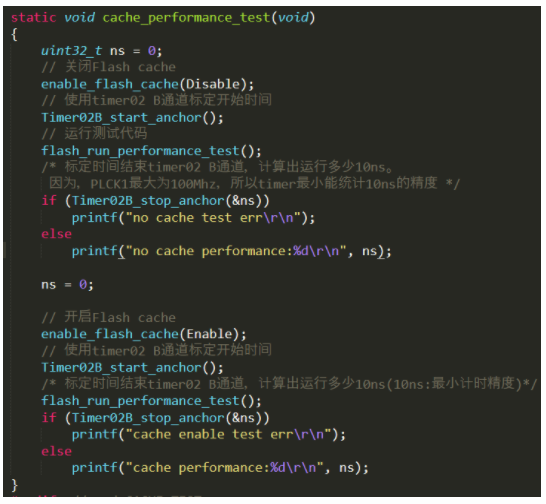
运行结果:
无cache时flash_run_performance_test函数使用了728023个10ns(10纳秒),
有cache时flash_run_performance_test函数使用了259880个10ns。
大家可以计算出测试函数花的时间,有cache时和无cache时速度的对比,是多少倍。
总结下:就是华大HC32F4XX系列ARM cortex-M4的这颗MCU速度还是不错的。
ymf
-
小华半导体HC32F460 、HC32F4A0获评 “2023年度最佳MCU芯片”2023-11-04 5431
-
HC32F460电机驱动源代码2022-09-30 1092
-
RT-Thread studio华大的HC32F460 BSP工程中有没有SPI相关的驱动呢2022-09-05 2967
-
怎么能够使HC32F460与HC32F4A0程序跑出实际CPU的频率呢2022-02-24 2778
-
华大HC32F460 HC32F4A0加速程序运行速度2022-01-12 2173
-
HC32F460的相关资料分享2021-12-06 2276
-
如何使用HC32F460系列MCU的DMA模块传输数据2021-11-26 2730
-
HC32F4602021-11-24 1644
-
华大HC32F460 Bootloader及应用程序的实现2021-11-23 3309
-
华大单片机HC32F460 系列MCU2021-11-18 1480
-
HC32F460替换STM32F411的步骤2021-11-01 2027
-
请问华大单片机HC32F460怎么样?2021-10-28 3362
-
如何去使用HC32F460看门狗2021-09-18 3669
-
HC32F460是什么?HC32F460有什么功能?2021-07-07 2681
全部0条评论

快来发表一下你的评论吧 !
