

【自适应计算在机器人领域的应用】连载二:工业类比CPU/GPU,ASIC和FPGA,谁更适合机器人计算
机器人
描述
作者: Víctor Mayoral-Vilches 和 Giulio Corradi,赛灵思公司
连载二:工业类比CPU/GPU,ASIC和FPGA,谁更适合机器人计算
CPU 和通用 GPU (GPGPU) 是两种广泛使用的商业计算平台,因为它们可用性高且具有通用性。这些计算技术的通用性,是机器人专家对其特别感兴趣的原因。但是通用性的代价是:
1. 通用平台的固定架构难以适应新的机器人场景。追加功能往往需要追加硬件,这也往往意味着要花时间对新的硬件进行新的系统集成度。
2. 通用性必然导致其在时效上的缺陷,从而影响确定性形成(难以满足严格的实时性要求)。
3. 其功耗通常比专用计算架构(如 FPGA 或 ASIC)高一到两个数量级 (1)。
4. 其固定的、不具备灵活应变能力的架构,导致其对网络安全威胁和恶意行为的抵御能力减弱。熔毁 ( Meltdown ) 或者幽灵 ( Spectre ) 等网络攻击示例表明,如果缺乏重新配置数据流流水线的能力,计算平台最终将丧失安全性。
总体而言,CPU、GPU 和 ASIC 等采用固定架构的器件,在其为开发者提供优势的同时,也让其付出了代价。它们所缺乏的灵活应变能力,导致其缺乏时效性,能耗增加。而且由于它们无法通过重新配置架构来提高硬件的抗风险能力,因此在网络威胁面前更加脆弱。
CPU的工业类比
图1是 CPU 的工业类比,它将 CPU 理解成一系列车间,并且每个车间安排一位技能非常娴熟的工人。
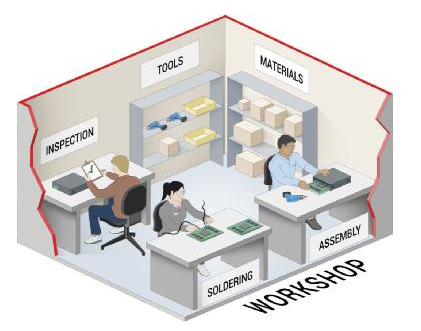
图1:CPU 的工业类比
这些工人每人都能使用通用工具生产出几乎任何产品。每位工人按顺序使用不同的工具,将原材料制造为成品,一次生产一件产品。根据任务的性质,这种串行生产流程可能用到大量步骤。这些车间基本(不考虑缓存的情况下)彼此独立,工人能全身心地完成不同任务,不必担心干扰或协调问题。尽管CPU 十分灵活,但它的底层硬件是固定的。CPU 仍然在基本的冯诺依曼架构(或者更确切地说,存储程序计算机)上运行。数据从存储器读取到处理器进行运算,然后写回到存储器。基本上每个 CPU 都以串行方式运行,一次一个指令。同时架构以算术逻辑单元 (ALU) 为中心,每次运算都需要将数据输入到 ALU 并从 ALU 输出数据。
CPU的工业类比
GPU 也可以用车间和工人类比,但它们的数量要大得多,并且工人的专业化程度也要高很多,如图2所示。
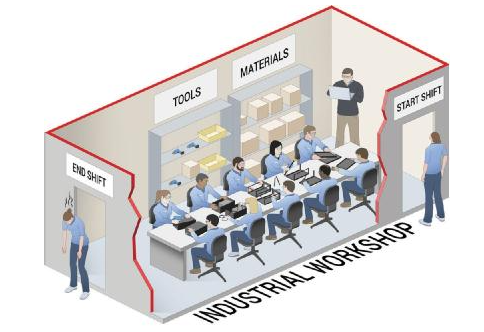
图 2: GPU 的工业类比
GPU 工人只能使用特定的工具,每人能完成的任务种类要少得多,但他们完成任务的效率非常高。GPU 工人在重复做相同的少量任务时效率最高,尤其是当他们全体同时做同一件事情时。GPU 解决了 CPU 的主要缺陷之一,即并行处理大量数据的能力。
虽然 GPU 比 CPU 拥有非常多的核,但 GPU 采用的依然是固定的硬件架构。GPU 的核仍然包含某种类型的冯诺依曼处理器。一条指令就能处理上千条或者更多数量的数据,尽管通常必须对同时处理的每一条数据进行相同的运算。原子处理元在数据矢量上运算(非 CPU 情况下的数据点),但仍然是每个 ALU 执行一条固定的指令。因此,用户仍然需要通过固定的数据路径,从存储器将数据传递给这些处理单元。与 CPU 相似,GPU 也采用固定硬件构建,对所有的机器人应用而言,其基本架构和数据流都是固定不变的。
FPGA 的工业类比
如果说 CPU 和 GPU 是工人按照顺序依次将输入加工成输出的车间,那么 FPGA 就是灵活的自适应工厂,能够针对手中的具体任务定制创设装配线和传送带(参见图 3)。
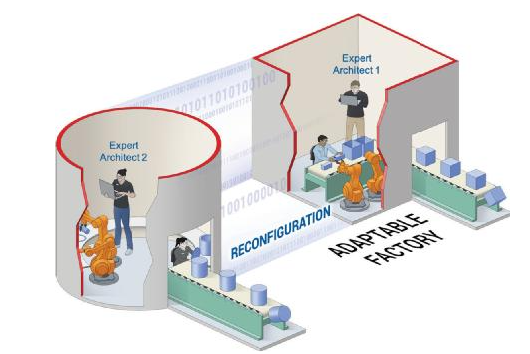
图 4: FPGA 的工业类比
这种灵活应变能力,意味着 FPGA 架构师可以先构建工厂、装配线和工位,然后根据所需完成的任务对它们进行量身定制,而不是使用通用工具。这些工厂中的原材料由分配在装配线上的工人小组逐步加工成成品。每名工人都重复地完成同样的任务,同时半成品通过传送带在工人间进行传递。这样能大幅提升生产力,并保证以最佳方式充分利用资源和电力。在这个类比中,工厂是 OpenCL 加速内核,装配线是数据流流水线,工位是 OpenCL 计算功能。
ASIC的工业类比
与 FPGA 类似,ASIC 也建造工厂,但是 ASIC 中的工厂是最终形态,不能改动(参见图 4)。换言之,这些 ASIC 内部只有机器人,工厂内不存在人类认知。这些装配线和传送带是固定的,不允许变更自动化流程。ASIC 的这种专用型固定架构赋予它们极高的能效,以及大批量规模化生产下的最低价格。但遗憾的是,ASIC 的开发通常需要耗时多年,而且不支持进行任何变更,这将会导致前期投入的资产很快跟不上未来生产力提升的变化。
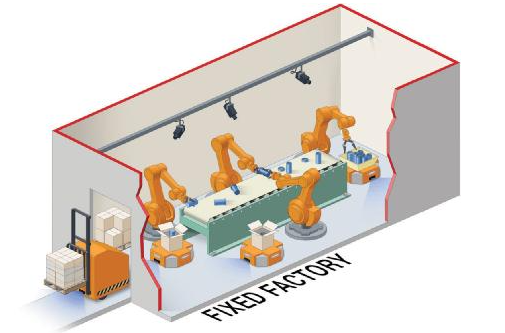
图 4: ASIC 的工业类比
-
工业机器人的特点2025-07-26 4506
-
机器人中的自适应计算2023-09-14 481
-
加速ROS2为机器人带来自适应计算能力2022-12-12 3155
-
【自适应计算在机器人领域的应用】连载三:为什么FPGA能在机器人中起到重要作用2021-11-12 4669
-
【自适应计算在机器人领域的应用】连载一:什么是自适应机器人?2021-11-11 3210
-
机器人的定义是什么?工业机器人的应用有哪些?2021-07-05 5437
-
工业机器人的发展趋势如何?2020-03-27 3587
-
工业机器人的技术原理2018-11-23 5072
-
选购工业机器人要了解哪些技术参数?2017-08-26 3647
-
六轴工业机器人的主要特点2017-08-08 6672
-
华南机器人应用培训中心工业机器人培训班招生2015-09-02 14428
-
什么是工业机器人2015-01-19 6815
-
基于结构自适应的多机器人协作机制研究2012-08-20 2757
全部0条评论

快来发表一下你的评论吧 !
