

《光学精密工程》—采用优化卷积神经网络的红外目标识别系统
今日头条
描述
采用优化卷积神经网络的红外目标识别系统
人工智能技术与咨询 前天
本文来自《光学精密工程》,作者刘可佳等
关注微信公众号:人工智能技术与咨询。了解更多咨询!
摘要
针对视频数据利用低效和光测设备目标识别能力较弱的问题,提出一种使用海量视频数据建立数据库进而构建红外目标识别系统的方法。首先设计快速红外目标检测算法,提取目标并分类建立数据库;然后结合特定任务建立一组较匹配且结构不同的卷积神经网络,并提出基于测试准确度均值统计分析和参数规模的选型策略,选出泛化能力较好且结构简单的卷积神经网络以及适当的训练轮数;最后加载优选模型及其参数作为分类器,与检测器结合实现红外目标特征事件实时检测分类。仿真结果表明,目标分类准确率均值可达95%以上,速率约为50 pixel/s。卷积神经网络结构的设计和选型策略有效,构建的系统可以满足红外目标识别的精度和实时性要求。
1 引 言
光电探测系统是空间目标探测和预警的重要手段之一,被广泛应用于军事领域。光电设备可以部署于陆基、海基、空基或天基平台,获取目标在不同空域和时段的视频图像数据,为决策者提供大量信息。陆基光电探测系统常采用红外波段,用于飞行目标的探测与跟踪,具有探测距离较远、视场和成像较小等特点,可以观测和记录目标飞行过程中的特征事件或动作,一般成像为黑底白像,以视频或图像帧方式记录。
目前视频数据多以磁盘存储,事后多以人工加软件方式判读,数据利用效率低,长期积累的海量视频数据信息未被充分挖掘。近年来,深度学习技术在图像分类研究中取得突破性进展[1],利用海量视频数据提高设备探测和目标识别性能的研究进入了一个崭新的阶段。卷积神经网络(Convolution Neural Network,CNN)[2-3]算法已逐渐代替传统人工模型算法成为处理图像检测与识别问题的主流算法,为复杂战场环境下的军事目标自动检测、识别与分析提供了新的技术途径。
视频红外目标在其飞行周期内外观变化较大、成像大小可以从占据大部分屏幕到点目标。基于深度卷积神经网络的视频目标检测与识别方法可以按照是否利用时序信息分为两类,一类是基于单帧图像的算法,仅利用当前帧图像的空间信息完成目标检测和分类识别,如经典的R-CNN系列[4-5]、SSD系列[6-7]和YOLO系列[8-10]算法等,这类算法研究相对较为成熟且已有大范围的落地应用,主要针对多类别目标分类的通用场景,对中等大小目标效果很好,模型结构较为复杂,尽管近年提出许多轻量化的改进模型[11-15],但是这些算法对目标变化较大的情形尤其是特定任务中视场中目标外观很大或很小时的检测识别能力不足。另一类是基于多帧图像的视频行为识别[16-17]算法,这类算法同时利用帧序列蕴含的空间和时间信息进行目标分类识别,如C3D系列[18-19]、双流网络系列[20-21]、CNN加LSTM系列[22]算法,设计同时提取外观和运动特征的模型较为复杂、对训练数据集的标注要求较高,目前在红外目标识别领域的应用处于起步探索阶段。
国内应用深度学习技术研究和解决军事图像分类、高光谱图像分类、海战场图像目标识别、复杂背景下坦克装甲目标检测、飞行器图像识别等问题[23-27],并取得了较好的结果,但在利用海量视频数据建立训练数据集、针对特定任务的CNN结构选择与优化策略等重要问题上鲜有提及。针对这些问题,结合陆基红外探测系统成像特点,设计了一种基于优化卷积神经网络、快速生成红外目标检测识别系统的构建方法,让实时数据“开口说话”[28]。
2 系统模型
红外目标识别系统的设计思路是先设计快速红外目标检测器,从视频中提取并标注目标区域(Region of Interesting,ROI),建立数据集并存储到数据库,然后利用这些标注数据训练卷积神经网络;再设计基于测试准确度和模型复杂度的模型选择策略,获取红外目标分类识别器,达到实时识别目标特征事件的目的。该框架可以高效、灵活利用源视频数据快速获取目标识别能力。
图1是系统框图,分为建数据库、训练选型和加载检测三部分,分别用绿虚线、蓝实线和红虚线表示其流程,实线方框表示功能模块,虚线方框表示需要一定程度的人工交互,虚线圆角框表示产生的过程文件,圆柱体表示数据库(彩图见期刊电子版)。
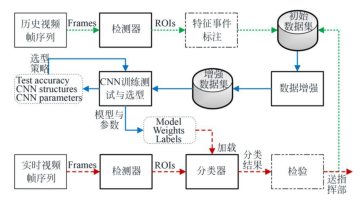
图1红外视频处理与红外目标识别系统框图
Fig.1Block diagram of infrared video processing and infrared target recognition system
建数据库包括设计检测器并从历史视频帧中提取目标ROI,在人工交互模式下将目标的飞行过程划分为若干特征事件子类,标明ROI的子类编号(例如子类编号1至3表示起飞、分离、抛整流罩),将ROI及其对应的子类标签作为初始数据集以统一文件格式存储到数据库。
训练选型是先对初始数据集进行数据增强,得到增强数据集,再根据子类数目、样本集规模和经验知识设计一组与特定任务较匹配的CNN模型,通过选型策略选出较优的模型及其参数。
加载检测是加载最优模型及其参数得到分类器,用检测器从实时红外视频帧中逐帧提取ROI送入分类器获得检测结果,通过人工交互检验后可提供实战信息或充实数据库。
下面详细叙述检测器、建数据库、训练选型和分类器等主要模块的实现过程。
2.1 检测器
飞行目标温度一般高于背景温度,红外视频目标成像为白色,背景为黑色,因此可以采用形心法和阈值分割方法构造检测器,快速检测和提取目标ROI,获取目标ROI图像集合。
图2是检测器框图,帧边缘处理模块将画面字幕区域填充为背景灰度值;中值滤波用于处理坏点和椒盐噪声;二值化掩膜可依据常量门限或自适应门限计算目标掩膜,再根据掩膜计算目标群外接矩形。二值化固定阈值可根据处理的红外目标灰度值,在[150,180]之间选择,基于背景分离的自适应门限功能作为可选项。为匹配CNN网络,提取ROI均为正方形,边长取ROI外接矩形长和宽较大者。
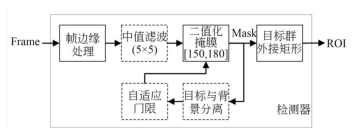
图2检测器框图
Fig.2Block diagram of detector
2.2 数据集的建立与存储
建立数据集时先针对特定分类任务,人工划分特征事件段落,将ROI进行子类标注并以固定格式储存,再进行增强处理得到增强数据集,用于训练CNN网络。
2.2.1 数据分类与标注
红外探测器视场一般约为1°,目标飞行过程中有姿态变化、分离、释放诱饵等动作,距离较近时成像多为具有某种特征的灰白色亮斑,形态缓变或突变;距离较远时多成像为点目标。
固定型号目标成像一般不超过20种形态,根据成像形态差异和变化规律将飞行过程划分为若干特征事件子类,目标具有多批次飞行视频,对应多组ROI样本集,可分别作为训练和测试数据集。ROI子类标注需要人工交互确定子类名称和剔除过渡样本,以使子类间具有更好的区分度。
2.2.2 数据增强
如果视频有限、训练数据库数量少、形式单一或子类样本量不均衡时,可采用数据增强技术,通过随机旋转、翻转、缩放、剪切、亮度调整、对比度调整及其组合方法处理初始数据集中的ROI,改善数据集。
如划分6个子类,建立训练和测试集,初始样本数为1 920,增强扩充为12 800,选择同型号目标另一批次红外视频建立测试数据集,因某些目标动作时间短、帧数少,某些状态持续时间长、变化慢,只选其子类中具有代表性的195帧并覆盖所有子类的ROI建立测试集。
2.2.3 数据存储
实际问题中的数据格式和属性并不统一,TensorFlow[29]提供了一种统一的TFRecord格式存储数据,可以统一不同的原始数据格式,并更加有效的管理不同的属性,可扩展性也更好,在存取时间和空间上效率更高。比如增强数据集包括12 800幅灰度图,大小为27 319 986 Byte,占用空间57 958 400 Byte;对应的带有标签信息的TFRecord文件大小为14 400 000 Byte,占用空间14 401 536 Byte;后者占用空间更少,训练模型输入效率更高。
2.3 建立并优选卷积神经网络模型
CNN通常包含一个标准的叠加卷积层结构(可选择附加对比标准化和最大池化功能)后接一个或多个全连接层[30],结构复杂度应当与需要区分的类别数匹配,有助于减少欠拟合或过拟合,因此应当设计CNN模型结构选择策略,即首先根据子类数目和数据集规模设计一组较匹配的CNN模型,覆盖不同卷积层数和卷积核深度,通过多次训练,取得多组测试准确度(Test Accuracy,TA),利用测试准确度的统计分析结果和模型参数规模选出泛化能力较好且结构较简单的CNN模型。
根据MNIST,CIFAR10数据集经验,分类数较少时,如10个左右,CNN卷积层2到4层即可达到满意效果,这里参照较为简单的LeNet-5[31-32]网络结构。将CNN模型命名为CnnetNX,其中N表示卷积层数,可选1,2,3,4k,5;X表示首层卷积核深度可选b(4),c(8),d(16),e(32),f(64),之后各层卷积核深度以2为底指数级增加。例如Cnnnet3d具有3个卷积层、首层卷积核深度为16。图3表示3种CNN结构,从Cnnet2e到Cnnet4e网络深度逐渐加深,其中卷积层包含了线性整流函数ReLU(Rectified Linear Unit)。
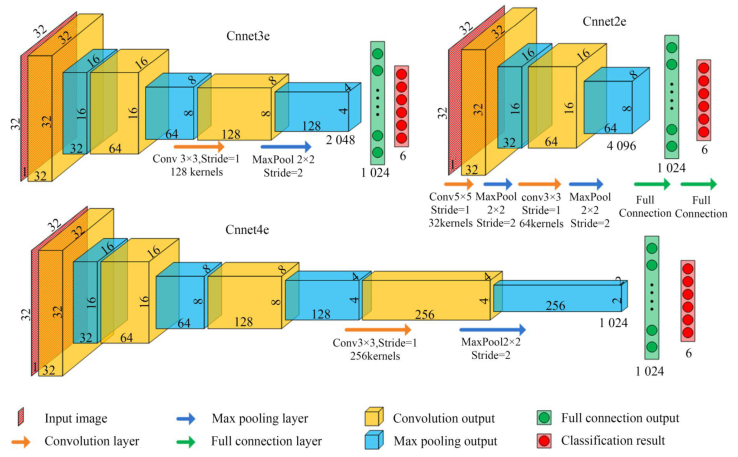
图3CNN结构框图
Fig.3Block diagram of CNN Structure
针对自建数据库规模小、类别少的特点,设计21种CNN结构,如表1所示。表1给出Cnnet5e的核参数和特征图尺寸,卷积核的节点矩阵尺寸即宽、高、通道数分别用w,h,c表示,卷积核的深度为d,池化层的滤波核大小均为2×2,sn表示卷积步进值为n,输出特征图的宽、高、通道数用W,H,C表示。X=d(16),c(8),b(4)的数据标于括号中,“√”表示具有该层结构,“Flat”表示最后一层池化层输出的特征图拉直向量维度,“FullC”表示全连接层,数值等于输入图的拉直向量维数。cnnet1f未标出,其对应的卷积核深度为64,拉直向量维度16 384。表2是21种CNN的参数数量,卷积层越多,全连接层参数占比越低,总参数越少;卷积核深度越深,总参数越多。
表121种具有不同卷积层和卷积核深度的CNN结构参数
Tab.121 kinds of CNN structure parameter with different convolution layer and convolution kernel depth
|
cnnet |
5e(d,c,b) |
4e(d,c,b) |
3e(d,c,b) |
2e(d,c,b) |
1e(d,c,b) |
|
|---|---|---|---|---|---|---|
|
层名 |
核参数 (w×h×c/d/stride) |
特征图(W×H×C) (输入图32×32×1) |
||||
|
Conv1 |
5×5×1/32(16,8,4)/s1 |
32×32×32(16,8,4) |
√ |
√ |
√ |
√ |
|
MaxP1 |
2×2/s2 |
16×16×32(16,8,4) |
√ |
√ |
√ |
√ |
|
Conv2 |
3×3×32/64(32,16,8)/s1 |
16×16×64(32,16,8) |
√ |
√ |
√ |
|
|
MaxP2 |
2×2/s2 |
8×8×64(32,16,8) |
√ |
√ |
√ |
|
|
Conv3 |
3×3×64/128(64,32,16)/s1 |
8×8×128(64,32,16) |
√ |
√ |
||
|
MaxP3 |
2×2/s2 |
4×4×128(64,32,16) |
√ |
√ |
||
|
Conv4 |
3×3×128/256(128,64,32)/s1 |
4×4×256(128,64,32) |
√ |
|||
|
MaxP4 |
2×2/s2 |
2×2×256(128,64,32) |
√ |
|||
|
Conv5 |
3×3×256/512(256,128,64)/s1 |
2×2×512(256,128,64) |
||||
|
MaxP5 |
2×2/s2 |
1×1×512(256,128,64) |
||||
|
Flat |
512(256,128,64) |
1 024 (512, 256, 128) |
2 048 (1 024, 512, 256) |
4 096 (2 048, 1 024, 512) |
8 192 (4096, 2 048, 1 024) |
|
|
FullC1 |
1 024 |
1 024 |
1 024 |
1 024 |
1 024 |
|
|
FullC2 |
6 |
6 |
6 |
6 |
6 |
|
表221种CNN网络参数数量(括号中为卷积层参数/全连接层参数个数)
Tab.2Number of 21 CNN network parameters(In parentheses, is the number of convolution layer /full connection layer parameters)
|
CNN |
1 |
2 |
3 |
4 |
5 |
|---|---|---|---|---|---|
|
b(4)
c(8)
d(16)
e(32)
f(64) |
1 054 824 (104/1 054 720) 2 103 504 (208/2 103 296) 4 200 864 (416/4 200 448) 8 395 584 (832/8 394 752) 16 785 024 (1 664/16 783 360) |
530 832 (400/530 432) 1 056 096 (1 376/1 054 720) 2 108 352 (5 056/2 103 296) 4 219 776 (19 328/4 200 448)
|
269 856 (1 568/268 288) 536 448 (6 016/530 432) 1 078 272 (23 552/1 054 720) 2 196 480 (93 184/2 103 296)
|
143 424 (6 208/137 216) 292 800 (24 512/268 288) 627 840 (97 408/530 432) 1 443 072 (388 352/1 054 720)
|
96 384 (24 704/71 680) 235 584 (98 368/137 216) 660 864 (392 576/268 288) 2 098 944 (1 568 512/530 432)
|
2.4 分类器
使用增强数据集按预设超参数和优化策略训练优选的模型,训练结束后将模型结构、学习到的参数和类别标签以文件形式保存;构造分类器时,加载模型、参数和子类标签文件,获得分类器函数,该函数输入图片,输出图片标签编号。使用检测器检测实时视频帧并提取目标ROI,逐帧输入分类器进行判断,输出该目标所属的子类编号。
3 实验结果与分析
实验分图像增强、模型训练选型和分类性能分析三部分。仿真计算机配置为Intel®Core™ i7-6700HQ CPU @ 2.60 GHz,仿真软件采用Anaconda3-5.2.0,Python-3.5.2。CNN网络搭建与训练、目标检测实现基于TensorFlow框架和python-OpenCV库。
3.1 图像增强及其效果仿真
图4用网络图片展示增强效果,末行中间是原图,自上而下为亮度、对比度、随机剪切和旋转四种处理结果,组合处理样本更加丰富。

图4亮度、对比度、随机剪切和旋转处理
Fig.4Brightness, contrast, random cut and rotation processing
如图5所示,用增强前后的数据集分别训练cnnet3e模型各5次,“src”和“aug”分别表示源数据集和增强数据集训练结果,测试准确度均值(Mean Test Accuracy,MTA)表明,数据增强技术在同等条件下使MTA提高约10%,且标准差更小,帮助模型学习到更好更稳定的泛化能力。
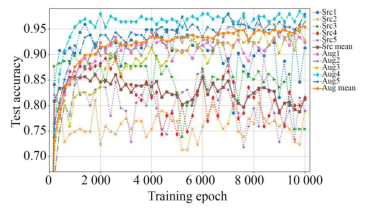
图5数据增强前后训练cnnet3e网络5次TA及MTA曲线
Fig.5Training cnnet3e network TA and MTA for 5 times before and after data enhancement
3.2 训练模型与选型策略实验
影响CNN模型性能的主要有网络结构、超参数以及损失函数和优化策略等,这里主要研究CNN结构尤其是网络深度变化对训练结果的影响,进而设计选型策略。实验选择的超参数有学习速率0.000 1、最小批处理数量50、随机失活比例0.5、训练轮数10 000轮;损失函数为交叉熵,优化采用自适应矩估计方法(adaptive moment estimation,Adam)[29]。
由于对批处理数据进行了随机扰乱,因此学习参数和测试准确度等训练结果具有随机性,而测试准确度是反映模型泛化能力的重要指标,为减少随机性干扰,使用增强前后的数据集分别对21种CNN进行5次训练,每次训练10 000步,每200步记录一次测试准确度结果,分别计算各CNN的5次训练结果的MTA,如图6~图7所示。从MTA变化趋势看,前者收敛较快,多数曲线呈现先升后降趋势,后者收敛较慢,大部分曲线由升转稳,且幅度有较大提高;原因是前者样本少,收敛快,后期出现过拟合,而后者样本数量和多样性都有改善,训练轮数也比较合适。可见MTA即能反映泛化能力,又能反映拟合状态,是选择模型和训练轮数的重要参考。
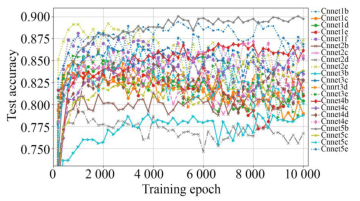
图621种CNN 5次MTA曲线(未增强数据)
Fig.6MTA of 21 CNN for 5 times with unenhanced data
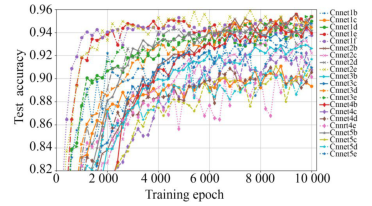
图721种CNN5次MTA曲线(增强数据)
Fig.7MTA of 21 CNN for 5 times with enhanced data
图8能更清晰地展示这种趋势,按顺序取每5个相邻的MTA为一段求均值,得到分段测试准确度均值(Partitioned Mean Test Accuracy,PMTA),幅度更稳定。
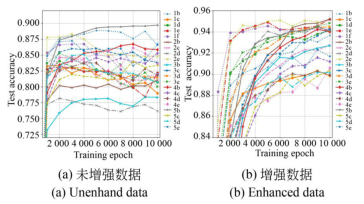
图821种CNN 5次PMTA曲线
Fig.8PMTA of 21 CNN for 5 times
对比图8的(a)和(b),前者5b,1b,2e较高,2d,3b,2b较低,后者1e,2b,2e较高,4e,5c,5d较低。这表明同等条件下增强样本会影响训练收敛过程和结果;前后两个2e幅度都较高,但曲线形态明显不同,前者先升后降,后者先升后稳,这说明同等条件下还应按数据集规模选择适当的训练轮数,防止欠拟合和过拟合。
基于上述分析,将各CNN中MTA类指标和参数规模绘制成热度图,如图9所示。优选模型主要依据PMTA和MTA的最大值,以及参数总数“total num”,前者反映模型泛化能力,后者表示模型复杂度,其他指标(FMTA表示MTA前5个最大值的均值,“fclayer num”和“convlayer num”表示全连接层和卷积层参数量)作参考。首先排除参数很多(>1 000 000)且MTA类指标并未显著提升者(1b~1f,2c~2e,3d,3e,4e,5e)和参数虽少但是MTA类指标明显较低者(3b,4c,4d,5c,5d),余下2b,3c,4b和5b(箭头所示)。其次2b,5b的参数规模分别略低于3c,4b但MTA更高,可淘汰后者。最后,余下的网络参数规模都不大,因此应以MTA为主;若MTA相等,根据奥卡姆剃刀原则,选参数少者。2b与5b模型相比,各有优势,前者以5倍左右的参数量,将MTA提高了近1%,在参数总数可接受的情况下,可提供更好的模型泛化能力。
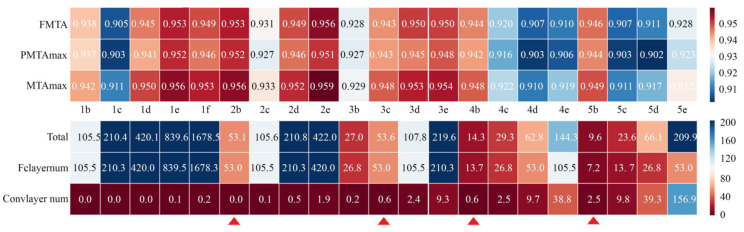
图9基于MTA类指标和参数规模的选型策略(参数数量单位:万)
Fig.9Selection strategy based on MTA class index and parameter scale (parameter unit: ten thousand)
综上所述,首先设计一组与特定任务较匹配的CNN,通过多次训练获得MTA类指标,绘制MTA类指标和参数规模热度图;再用排除法、对比法缩小选择范围;最后按照简单有效原则,可选出潜在的模型复杂度较低且泛化能力较高的CNN,用于构造分类器。
3.3 图像检测实验
TensorFlow提供多种方法保存和加载(部署)模型[33]。加载Cnnet2b结构、参数和标签文件,这里构造分类器函数用于仿真,输入为一幅归一化为32×32大小的ROI灰度图,输出为该图子类编号。仿真时先用检测器实时提取视频帧中的目标ROI,然后传入分类器函数判断其子类编号,这就构成一个快速目标识别系统。
图10上中下子图左侧是对Cnnet2b进行三次训练的训练准确度(Train Accuracy)和测试准确度,训练准确度在后期基本达到100%,测试准确度分别达98.46%,94.35%和95.89%;右侧是对应模型的预测结果与真实标签比较,可见模型训练结果具有随机性,但是在预期的范围。
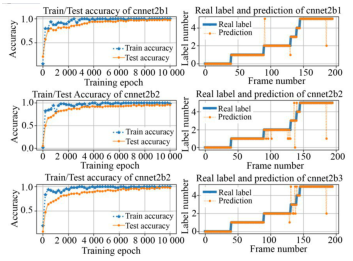
图10Cnnet2b模型三次训练和测试准确度及其分类结果
Fig.10Three times training and testing accuracy of cnnet2b model and its classification results
从预测结果看,错误帧分别为第3,9,7帧,其中分别有第2,6,5帧的错误发生在状态变换附近,约占68%,因此在选择训练测试样本时,通过减少过渡状态的样本,提高类间区分度,可进一步提高预测准确度。
在采用固定灰度阈值时,视频检测速率可达1 000 FPS,增加中值滤波和自适应灰度阈值功能时约为100 FPS,分类器运算时间约为100 FPS,检测分类总时间约为50 FPS,达到实时要求。
4 结 论
为快速利用现有数据提升设备能力,基于海量红外视频数据和卷积神经网络,分建立数据库、增强数据、选择CNN训练模型和设计检测器、分类器等若干步骤,设计了一种构建实时红外目标识别系统的方法。重点阐述了如何根据测试准确度均值及其分类统计结果、参数规模等要素选择适合特定任务的CNN卷积层层数和卷积核深度,在模型复杂度较低时,选出泛化能力较好的模型。实验结果表明,特征事件分类准确度可达95%,帧率约为50 FPS,选择CNN结构的策略合理有效,建立的系统模型可达到红外目标识别精度和实时性要求。
【转载声明】转载目的在于传递更多信息。如涉及作品版权和其它问题,请在30日内与本号联系,我们将在第一时间删除
关注微信公众号:人工智能技术与咨询。了解更多咨询!
编辑:fqj
-
卷积神经网络的应用 卷积神经网络通常用来处理什么2023-08-21 6926
-
卷积神经网络简介:什么是机器学习?2023-02-23 25588
-
卷积神经网络模型发展及应用2022-08-02 13420
-
卷积神经网络一维卷积的处理过程2021-12-23 2154
-
可分离卷积神经网络在 Cortex-M 处理器上实现关键词识别2021-07-26 3845
-
卷积神经网络的卷积到底是什么2020-05-05 6601
-
卷积神经网络如何使用2019-07-17 2914
-
基于联合层特征的卷积神经网络进行车标识别2017-12-23 1005
-
基于卷积神经网络的图像目标识别算法2017-12-20 1258
-
粒子群优化模糊神经网络在语音识别中的应用2010-05-06 2602
全部0条评论

快来发表一下你的评论吧 !
