

Android内存优化的常用工具与手段
描述
前言
内存问题是一个普遍问题,但是却普遍缺少关注度,具体有以下几个原因:
内存问题相对比较隐蔽,表现并不明显。
同时android使用Jvm语言开发,垃圾回收是自动的,所以一般没有特别关注。
内存问题难以定位,出现问题的地方往往只是表现的地方,真正的原因难以收集。
内存优化的内容其实非常多而复杂,我们可以尝试从以下思路去了解:
要了解内存问题,我们首先要了解为什么要做内存优化?
同时需要了解一些内存优化的背景知识,如垃圾回收机制。
我们需要了解一些内存优化的常用工具与手段。
图片是内存优化的重点,我们需要重点了解下图片优化的知识点。
内存问题的一个直接体现是OOM,我们还需要了解下OOM治理的一些手段。
所以我们可以轻松得出本文的主要内容:
为什么要做内存优化?
android内存优化的一些背景知识。
android内存优化的常用工具与手段。
怎么做图片内存优化?
怎么做OOM线上监控?
本文主要内容思维导图如下:
1、为什么要做内存优化?
要回答这个问题,我们首先应该明确需求,当我们去做内存优化时是为了什么。
做内存优化的目的是降低OOM率、减少卡顿、增加应用存活时间。
1.1 降低OOM率
做内存优化的一个常见原因是为了降低OOM率。
申请内存过多而没有及时释放,常常就会导致OOM。
引起OOM的原因有多种,在后面我们再细谈。
1.2 减少卡顿
Android中造成界面卡顿的原因有很多种,其中一种就是由内存问题引起的。
内存问题之所以会影响到界面流畅度,是因为垃圾回收。
在GC时,所有线程都要停止,包括主线程。当GC和绘制界面的操作同时触发时,绘制的执行就会被搁置,导致掉帧,也就是界面卡顿。
1.3 增加应用存活时间
Android会按照特定的机制清理进程,清理进程时优先会考虑清理后台进程,如果某个应用在后台运行并且占用的内存更多,就会被优先清理掉。
我们通常希望App能尽量存活的久一点,所以内存不再使用时应该尽快释放。
2、android内存优化的一些背景知识
2.1 Java垃圾回收机制
Java内存回收主要包括以下内容:
判断对象是否回收的可达性分析算法。
强软弱虚4种引用类型。
用于GC回收的垃圾回收算法。
这些都是很常见的知识点了,这里也就不缀述了,如果想要了解更多细节的同学可参考:Java 垃圾回收机制。
https://juejin.cn/post/6844903897958449166
2.2 什么是内存泄漏?
内存泄漏指的是一块内存没有被使用且无法被GC回收,从而造成了内存的浪费,比如Handler匿名内部类持有Activity的引用,Activity 需要销毁时,GC 就无法回收它。
内存泄漏的表现就是可用内存逐渐减少,无法被回收的内存逐渐累积,直到应用无更多可用内存可申请时,就会导致内存溢出。
内存泄漏的直接原因是长生命周期的对象引用了短生命周期的对象,导致短生命周期对象无法回收。
常见的引起内存泄漏的原因有:
非静态内部类持有了外部引用。
静态变量持有了context的引用。
资源没有及时释放。
我们一般使用LeakCanary或者Profile检测内存泄漏。
2.3 什么是内存抖动?
当我们在短时间内频繁创建大量临时对象时,就会引起内存抖动,比如在一个for循环中创建临时对象实例,下面这张图就是内存抖动时的一个内存图表现,它的形状是锯齿形的,而中间的垃圾桶代表着一次GC。
内存抖动意味着频繁的创建对象与回收,容易触发GC,而当GC时所有线程都会停止,因此可能导致卡顿。
为了避免内存抖动,我们应该避免以下操作:
尽量避免在循环体中创建对象。
尽量不要在自定义View的onDraw()方法中创建对象,因为这个方法会被频繁调用。
对于能够复用的对象,可以考虑使用对象池把它们缓存起来。
2.4 什么是内存溢出?
内存溢出即申请的内存超出可用的内存,即OOM,这会导致我们的程序异常退出,这也是我们重点关注的指标。
引起OOM的原因可能有多种,主要可以分为以下几类:
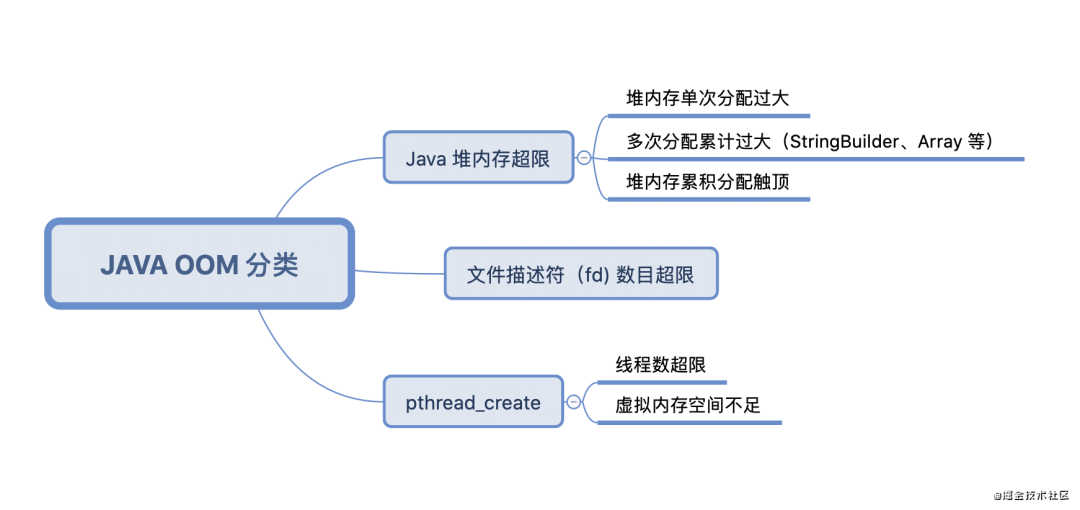
关于OOM治理及线上监控等,后面会详细介绍。
3、android内存优化的常用工具与手段
3.1 Memory Profiler
Memory Profiler是Profiler 中的其中一个版块,Profiler 是 Android Studio 为我们提供的性能分析工具,使用 Profiler 能分析应用的 CPU、内存、网络以及电量的使用情况。
使用Memory可以检测以下功能:
查看内存曲线及内存占用情况。
可以定位是否存在内存抖动问题。
堆转储(Dump Java Heap)可检测出内存泄漏的对象。
关于Memory Profiler的具体使用就不在此缀述了,想要了解的可参考:什么是 Memory Profiler?
https://juejin.cn/post/6844903897958449166
3.2 Memory Analyzer Tool
MAT工具可以帮助开发者定位导致内存泄漏的对象,以及发现大的内存对象,然后解决内存泄漏并通过优化内存对象,以达到减少内存消耗的目的。
比起Memory Profiler,MAT使用起来更加麻烦,同时现在Memory Profiler功能也越来越强大了,所以我现在已经很少使用MAT了。
如果想要更多地了解MAT,也可以参考:什么是Memory Analyzer Tool。
https://juejin.cn/post/6844903897958449166#heading-52
3.3 LeakCanary检测内存泄漏
相比Memory Profiler与MAT,LeakCanary在使用上更加简便。
只需要在项目中添加依赖,即可自动地检测内存泄漏并报警,使用起来非常方便。
LeakCanary有以下几个特点:
不需要手动初始化。
可自动检测内存泄漏并通过通知报警。
不能用于线上。
LeakCanary检测流程如下
关于LeakCanary的原理,我之前曾经总结过一篇文章,有兴趣的同学也可以参考:【带着问题学】关于LeakCanary2.0你应该知道的知识点。
https://juejin.cn/post/6968084138125590541
3.4 内存优化的一些常规手段
内存优化的一些细节问题可以在开发时避免,下面介绍一些常规的内存优化手段。
1)、使用LargeHeap属性增加最大可用内存。
2)、在系统触发资源紧张回调时,主动删除缓存。
3)、使用优化过后的集合:如SparseArray类等。
4)、谨慎使用 SharedPreference,SP会在应用初始化时将所有内容加载到内存中,所以不应该存放比较大的内容。
5)、谨慎使用外部库,引入时需要明确不会对应用性能造成大的影响。
6)、业务架构设计要合理,抽象可以优化代码的灵活性和可维护性,但是抽象也会带来其他成本,应权衡使用。
这些细节问题其实都很普通,如果平时注意到了,相信对应用的内存一定有所帮助。
4、怎么做图片内存优化?
内存优化应该优先去做见效快的地方,图片内存优化是内存优化的重点,可能一张图片没有回收就会造成几M内存的浪费。
4.1 常规的图片内存优化方法
我们都知道,图片所占内存=宽高一像素占用内存。
所以优化图片内存主要有以下几个思路:
缩放减小宽高。
减少每个像素所占用的内存。
内存复用,避免重复分配内存。
对于大图,可以采取局部加载的策略。
4.1.1 减少图片宽高
有时图片宽高为200*200, 而View宽高为100*100, 这种时候如果展示200*200的图片没有意义,应该对图片进行缩放。
这种情况一般通过inSampleSize实现。
BitampFactory.Options options = new BitmapFactory.Options();
// 设置为4就是宽和高都变为原来1/4大小的图片
options.inSampleSize = 4;
BitmapFactory.decodeSream(is, null, options);
4.1.2 减少每个像素所占用的内存
在API29中,将Bitmap分为ALPHA_8, RGB_565, ARGB_4444, ARGB_8888, RGBA_F16, HARDWARE六个等级。
ALPHA_8:不存储颜色信息,每个像素占1个字节;
RGB_565:仅存储RGB通道,每个像素占2个字节,对Bitmap色彩没有高要求,可以使用该模式;
ARGB_4444:已弃用,用ARGB_8888代替;
ARGB_8888:每个像素占用4个字节,保持高质量的色彩保真度,默认使用该模式;
RGBA_F16:每个像素占用8个字节,适合宽色域和HDR;
HARDWARE:一种特殊的配置,减少了内存占用同时也加快了Bitmap的绘制。
每个等级每个像素所占用的字节也都不一样,所存储的色彩信息也不同。同一张100像素的图片,ARGB_8888就占了400字节,RGB_565才占200字节。
所以在某些场景中,修改图片格式可以达到减少一半内存的效果。
4.1.3 内存复用,避免重复分配内存
Bitmap所占内存比较大,如果我们频繁创建与回收Bitmap,那么很容易造成内存抖动,所以我们应该尽量复用Bitmap内存。
在 Android 3.0(API 级别 11)开始,系统引入了BitmapFactory.Options.inBitmap字段。如果设置了此选项,那么采用 Options 对象的解码方法会在生成目标 Bitmap 时尝试复用 inBitmap,这意味着 inBitmap 的内存得到了重复使用,从而提高了性能,同时移除了内存分配和取消分配。
不过 inBitmap 的使用方式存在某些限制,在 Android 4.4(API 级别 19)之前系统仅支持复用大小相同的位图,4.4 之后只要 inBitmap 的大小比目标 Bitmap 大即可。
4.1.4 大图局部加载策略
对于图片加载还有种情况,就是单个图片非常巨大,并且还不允许压缩。比如显示:世界地图、清明上河图、微博长图等。
首先不压缩,按照原图尺寸加载,那么屏幕肯定是不够大的,并且考虑到内存的情况,不可能一次性整图加载到内存中。
所以这种情况的优化思路一般是局部加载,通过BitmapRegionDecoder来实现。
//设置显示图片的中心区域
BitmapRegionDecoder bitmapRegionDecoder = BitmapRegionDecoder.newInstance(inputStream, false);
BitmapFactory.Options options = new BitmapFactory.Options();
options.inPreferredConfig = Bitmap.Config.RGB_565;
Bitmap bitmap = bitmapRegionDecoder.decodeRegion(new Rect(width / 2 - 100, height / 2 - 100, width / 2 + 100, height / 2 + 100), options);
mImageView.setImageBitmap(bitmap);
4.1.5 小结
上面所说的这些关于Bitmap的内存优化策略其实都比较简单,而且我们在开发中可能很少用到
因为我们常用的图片框架比如Glide已经将这些都封装在里面了,所以一般情况下我们加载图片时不需要做这些特殊操作。
关于Glide对于加载图片都做了哪些优化,有兴趣的同学可以参考:【带着问题学】Glide做了哪些优化?
https://juejin.cn/post/6970683481127043085
4.2 图片兜底策略
针对因activity、fragment泄漏导致的图片泄漏,我们可以在onDetachedFromWindow时机进行了监控和兜底,具体流程如下:
通过这种方式可以方便地解决因Activity导致的图片泄漏问题。
4.3 线上大图监控方案
当运营在线上配置了不合理大小的图片时,如果我们及时发现,也会带来内存问题。
如果图片本身大小就不合理,我们在这个基础上谈图片优化也没有什么意义,因此大图监控这也是个比较常见的需求。
下面介绍几种大图监控的方案:
4.3.1 ArtHook 方案
该方案采用weishu大佬写的epic库实现,通过对ART虚拟机的hook,hook ImageView的 setImageBitmap 等方法。
解析对比方法参数中的 bitmap 宽高和 ImageView 实例的宽高,也可以获得bitmap的实际大小。
如果图片宽高比ImageView宽高大,或者图片大小超出了阈值,就可以把相关信息上报。
这种方案的优点在于:
侵入性极低,一次初始化配置即可hook全局的目标View控件。
可以获取代码调用堆栈,方便开发者快速定位。
而缺点则在于:
兼容性存在问题,使用了hook系统API ,不能用于线上。
4.3.2 BaseActivity 方案
大部分应用工程在业务发展的过程中都会沉淀封装自己的BaseActivity ,通过在BaseActivity onDestroy中动态地检测各个View控件,从而获知图片加载情况。
class BaseActivity : Activity(){
fun onDestory(){
if(isOpenCheckBitmap){
checkBitmapFromView()
}
}
fun checkBitmapFromView(){
//1、遍历activity中的各个View控件
//2、获取View控件加载的Bitmap
//3、对比Bitmap宽高与View宽高
}
}
这种方案的优点在于:
兼容性强,无任何反射。
加入简单,没有什么复杂逻辑。
缺点在于:
侵入性太强,需要修改BaseActivity。
BaseActivity.onDestory本身可能被重写,并不安全。
4.3.3 ASM方案
该方案在编译流程进行插桩,通过匹配setImageBitmap、 setBackground等关键方法,插入Bitmap大小检测逻辑。
这种方案优点在于:
编译时期插桩,对开发过程无侵入性。
缺点在于:
通过插桩的方式打点,可能会增加编译期耗时。
ASM代码维护成本较高,使用起来不是那么方便。
4.3.4 registerActivityLifecycleCallback方案
通过registerActivityLifecycleCallback监听Activity生命周期,在onStop时进行Bitmap大小检测的逻辑。
private fun registerActivityLifecycleCallback(application: Application) {
application.registerActivityLifecycleCallbacks(object :
Application.ActivityLifecycleCallbacks {
override fun onActivityStopped(activity: Activity) {
checkBitmapIsTooBig(childViews)
}
})
}
这种方案对原始代码无侵入性,同时使用起来比较简单,也没有兼容性问题,应该属于比较良好的方案。
详细实现可见:BitmapCanary 诞生。
https://juejin.cn/post/6956138531789996040#heading-14
5、怎么做OOM线上监控?
上文我们介绍了,可以使用LeakCanary在线下监测内存泄漏,但是LeakCanary只能在线下使用,有以下问题:
线下场景能跑到的场景有限,很难把所有用户场景穷尽。碰到线上问题难以定位。
检测过程需要主动触发GC,Dump内存镜像造成app冻结,造成测试过程中体验不好。
适用范围有限,只能定位Activity&Fragment泄漏,无法定位大对象、频繁分配等问题。
hprof文件过大,如果整体上传的话需要耗费很多资源。
下面我们就介绍一下快手开源的线上OOM监控框架KOOM。
5.1 线上OOM监控框架KOOM介绍
上面我们介绍了LeakCanary不能用于线上监控的原因,所以要实现线上监控功能,就需要解决以下问题:
1、监控
主动触发GC,会造成卡顿
2、采集
Dump hprof,会造成app冻结
Hprof文件过大
3、解析
解析耗时过长
解析本身有OOM风险
其核心流程为三部分:
监控OOM,发生问题时触发内存镜像的采集,以便进一步分析问题。
采集内存镜像,学名堆转储,将内存数据拷贝到文件中,以下简称dump hprof。
解析镜像文件,对泄漏、超大对象等我们关注的对象进行可达性分析,解析出其到GC root的引用链以解决问题。
5.2 KOOM解决GC卡顿
LeakCanary通过多次GC的方式来判断对象是否被回收,所以会造成性能损耗。
koom通过无性能损耗的内存阈值监控来触发镜像采集,具体策略如下:
1、Java堆内存/线程数/文件描述符数突破阈值触发采集。
2、Java堆上涨速度突破阈值触发采集。
3、发生OOM时如果策略1、2未命中 触发采集。
4、泄漏判定延迟至解析时。
我们并不需要在运行时判定对象是否泄漏,以Activity为例,我们并不需要在运行时判定其是否泄漏,Activity有一个成员变量mDestroyed,在onDestory时会被置为true,只要解析时发现有可达且mDestroyed为true的Activity,即可判定为泄漏。
通过将泄漏判断延迟至解析时,即可解决GC卡顿的问题。
5.3 KOOM解决Dump hprof冻结app
Dump hprof即采集内存镜像需要暂停虚拟机,以确保在内存数据拷贝到磁盘的过程中,引用关系不会发生变化,暂停时间通常长达10秒以上,对用户来讲是难以接受的,这也是LeakCanary官方不推荐线上使用的重要原因之一。
利用Copy-on-write机制,fork子进程dump内存镜像,可以完美解决这一问题,fork成功以后,父进程立刻恢复虚拟机运行,子进程dump内存镜像期间不会受到父进程数据变动的影响。
流程如下图所示:
KOOM随机采集线上真实用户的内存镜像,普通dump和fork子进程dump阻塞用户使用的耗时如下:
可以看出,基本可以做到无感知的采集内存镜像。
5.4 KOOM解决hprof文件过大
Hprof文件通常比较大,分析OOM时遇到500M以上的hprof文件并不稀奇,文件的大小,与dump成功率、dump速度、上传成功率负相关,且大文件额外浪费用户大量的磁盘空间和流量。
因此需要对hprof进行裁剪,只保留分析OOM必须的数据,另外,裁剪还有数据脱敏的好处,只上传内存中类与对象的组织结构,并不上传真实的业务数据(诸如字符串、byte数组等含有具体数据的内容),保护用户隐私。
裁剪hprof文件涉及到对hprof文件格式的了解,这里就不缀述了。
5.5 KOOM解决hprof解析的耗时与OOM
解析hprof文件,对关键对象进行可达性分析,得到引用链,是解决OOM最核心的一步,之前的监控和dump都是为解析做铺垫。
解析分两种,一种是上传hprof文件由server解析,另一种是在客户端解析后上传报告(通常只有几KB)。
KOOM选择了端上解析,这样做有两个好处:
节省用户流量。
利用用户闲时算力,降低server压力,这样也符合分布式计算理念。
这样就可以把解析过程拆解成以下两个问题:
1、哪些对象需要分析,全部分析性能开销太大,很难在端上完成,并且问题没有重点也不利于解决。
2、性能优化,作为一个debug组件,要在不影响用户体验的情况下完成解析,对性能有非常高的要求。
5.5.1 关键对象判定
KOOM只解析关键的对象,关键对象分为两类,一类是根据规则可以判断出对象已经泄露,且持有大量资源的,另外一类是对象shallow / retained size 超过阈值。
Activity/fragment泄露判定即为第一种:
对于强可达的activity对象,其mDestroyed值为true时(onDestroy时赋值),判定已经泄露。
类似的,对于fragment,当mCalled值为true且mFragmentManager为null时,判定已经泄露。
Bitmap/window/array/sufacetexture判定为第二种。
检查bitmap/texture的数量、宽高、window数量、array长度等等是否超过阈值,再结合hprof中的相关业务信息,比如屏幕大小,view大小等进行判定。
5.5.2 性能优化
KOOM在LeakCanary解析引擎shark的基础上做了一些优化,将解析时间在shark的基础上优化了2倍以上,内存峰值控制在100M以内。用一张图总结解析的流程:
详细流程就不在这里缀述了,详情可见:KOOM解析性能优化。
https://juejin.cn/post/6860014199973871624#heading-13
5.6 KOOM使用
KOOM目前已经开源,开源地址:
https://github.com/KwaiAppTeam/KOOM
直接参照接入指南接入即可,当发现内存超过阈值或者发生OOM时,就会触发采集内存快照,对hprof文件进行裁剪并分析后得到报告。
KOOM的报告是json格式,并且大小在KB级别,样式如下所示:
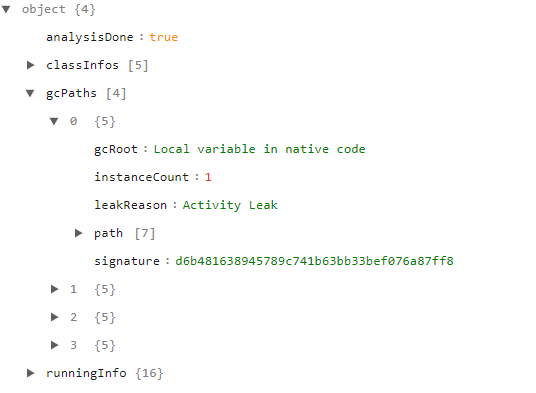
大概包括以下信息:
一些可能泄漏的类信息。
泄漏原因,gcRoot,泄漏实例数量等。
泄漏对象的引用链,方便定位问题。
可见KOOM上传的数据量并不太大,但相对准确,非常便于我们分析线上数据。
5.7 小结
本章主要介绍了线上监控OOM的开源框架KOOM。
其实线上监控OOM的框架各大厂都有开发,比如美团的Probe,字节的Liko。
https://tech.meituan.com/2019/11/14/crash-oom-probe-practice.html
https://juejin.cn/post/6908517174667804680#heading-7
不过大部分都没有正式开源,只是一些文章介绍原理,有兴趣的同学也可以都了解下。
总结
对于优化的大方向,我们应该优先去做见效快的地方,主要有以下几个部分:
内存泄漏。
内存抖动。
Bitmap大图监控。
OOM线上监控。
我们还介绍了内存优化的多种实用工具:
可以使用Profile,MAT在开发时定位内存抖动内存泄漏问题。
线下开发、回归、Monkey、压测等环节可以自动集成LeakCanary检测内存泄漏;
图片加载是内存优化的重点,我们可以结合图片兜底策略与线上大图监控,优化图片内存问题。
线上OOM时通过KOOM监测,内存超出阈值时主动dump内存快照,通过上传分析结果精准。分析OOM问题。
内存优化是个复杂的过程,我们在做内存优化的过程中,需要结合多种工具,线上线下结合,系统化地配合来定位与解决问题。
作者:RicardoMJiang
https://juejin.cn/post/6975876569990447134
责任编辑:haq
-
51单片机常用工具包2009-08-07 35239
-
单片机常用工具(光盘中带的)2013-05-30 2653
-
单片机常用工具集合2014-06-03 3356
-
LabVIEW 常用工具包集锦2015-12-11 25986
-
Fibocom 常用工具分享2022-12-01 1521
-
单片机常用工具2023-10-13 781
-
硬盘维修基础与常用工具.pdf2009-10-11 936
-
电工常用工具的使用技巧2008-11-20 2619
-
MATLAB 常用工具箱2015-01-06 751
-
常用工具软件2015-10-14 1086
-
Java常用工具类2015-11-06 598
-
Linux(ubuntu)常用工具2018-04-17 1238
-
电工常用工具仪表的使用2021-03-18 1266
-
修理电机常用工具和设备2021-07-20 8908
-
OpenHarmony常用工具汇总2023-01-04 2776
全部0条评论

快来发表一下你的评论吧 !
