

AI终端应用中需要怎么选择最合适的闪存芯片
电子说
描述
2016年3月,Google AlphaGo在与韩国九段棋手李世石进行的围棋比赛中,以4:1的绝对优势完胜;2018年底,Google AlphaStar与两位世界顶尖游戏玩家在《星际争霸(StartCraft II)》中展开对决,最终以两个5:0的成绩横扫对手。尽管早在1997年,IBM开发的计算机程序“深蓝”就战胜了当时的国际象棋特级大师加里·卡斯帕罗夫,但考虑到国际象棋的下法难度远远低于围棋,所以AlphaGo的胜利在某种程度上也被视作“AI时代的真正来临”。
AI的起源
1955年到1956年间,时任Dartmouth学院助理教授的John McCarthy,也是后来世界公认的AI教父,与来自哈佛大学的Marvin Minsky、IBM的Claude Shannon、以及美国贝尔实验室的Nathaniel Rochester,首次共同定义了“人工智能(AI)”的概念,即:
“如果任何的机器通过不一样的语言,就可以将抽象的事务或概念表达出来,并且通过这个抽象的概念去帮助人们解决现有的问题,或者是它本身可以通过自主学习不断地精进,我们就将其称之为AI。” 或者用更精炼的话语进行陈述,那就是:当任何机器的行为模式与人一样时,我们就称它是“智能(intelligent)”的。 如此宽泛的定义自然带来了与之对应的宽泛应用。除了下棋与游戏,在自动驾驶领域,美国部分地区已经开放了Level 4级别的测试,相信真正的Level 5级别自动驾驶也是指日可待,而要保障车辆和行人的安全,我们依赖的除了法律法规,还有AI算法的开发者;而在IoT应用领域,传感、智能手机、网络搜索、人脸/汽车牌照识别、智能表计、机器视觉、工业控制……AI正变得无处不在,让工作和生活变得更加便捷与智慧。
IDC的统计数据显示,2020年到2021年间,全球AI服务的年复合增长率达到了17.4%,预计到2024年,这一数字将上升至18.4%,市值约为378亿美元。这其中包括了定制化的应用和针对定制化平台所提供的相关支持与服务,例如一些深度学习架构、卷积神经网络、与AI相关的芯片产品(CPU、GPU、FPGA、TPU、ASIC)等。
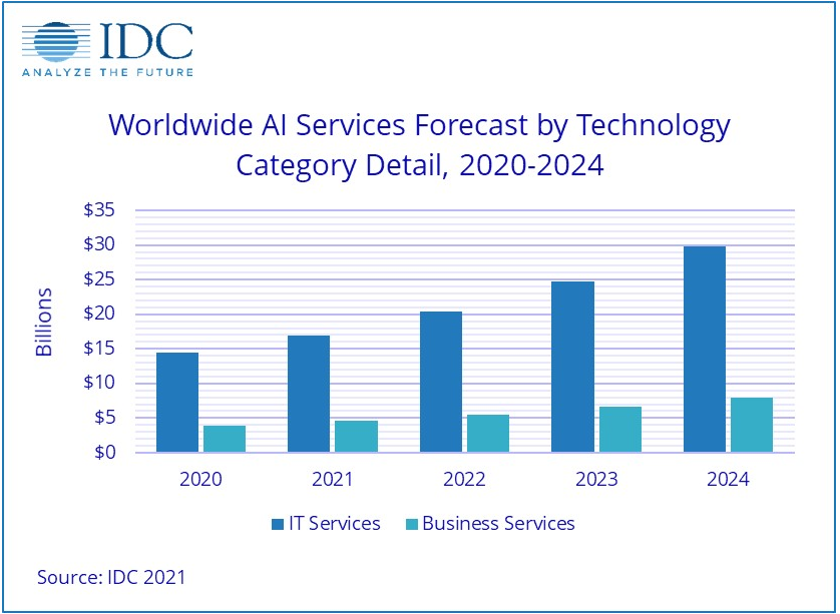
同样是来自IDC的数据,全球数据储存量将从2018年的33ZB猛增到2025年的175ZB,这其中超过50%都来自IoT设备。如果考虑到2025年,全球将会部署约140亿部IoT设备,那么我们似乎就应该大量地增加云端的计算单元数量与算力,才能应对海量的数据增长。 不过,事实并非如此,这一想法显然没有顾及到从终端到云端的数据传输链条中面临的带宽、时间延迟等事实性挑战,这也是为什么“边缘计算”能够得以迅速崛起的原因。 因为我们最终发现,随着IoT设备的快速增加,一味增加带宽和服务器数量的做法并非最优,不少应用完全可以在端侧设备中加以实现,而不必把所有数据都放到云端去进行处理和传输、存储和分析,这是不适合的。比如在工业自动化领域,数据存储距离一定要近才有效率;5G移动设备制造商如果不强化终端侧人工智能并进行计算-存储架构更改,将会遭遇严重的电池寿命问题。 隐私安全,是另一个值得我们重视的环节,尤其是在当前万物互联的时代,机密资料/数据外泄或是遭到黑客入侵的事件屡有发生。如果我们能让计算在边缘侧发生,节省“云-管-端”通路中数据传输的次数,那么,在确保数据和网络安全的同时,也降低了功耗和系统总拥有成本。
不同AI芯片的比较
众所周知,AI技术根据应用不同被分为“训练(Training)”和“推理(Inference)”两大类,前者主要在云端由CPU、GPU、TPU负责执行,目的是不断增加数据库资源以建立数据模型;后者则比较适合应用于边缘装置和特定应用,常由ASIC、FPGA类芯片进行处理,依托已经训练好的数据模型进行推理。
如前文所述,与AI相关的芯片产品包括CPU、GPU、FPGA、TPU、ASIC等多种类型。华邦电子闪存产品企划处黄仲宇从五个维度对上述不同的芯片类型进行了概略性的初步比较,包括算力(Computing)、软件灵活性(Flexibility)、硬件兼容性(Compatibility)、功耗(Power)和成本(Cost)。
01
CPU
CPU发展多年,运算能力强大,在软硬件兼容性方面首屈一指。但是,由于受到冯·诺伊曼架构的限制,数据需要在内存和处理器之间不断往复传输,所以限制了处理的平均速度、且在功耗和成本表现上相较其他方案不是最好的,处于折中的位置。
02
GPU
以Nvidia GPU为例,由于采用了“Compute Unifiled Device Architecture”架构,且自身计算单元数量众多,使得GPU不但能够任意读取内存的位置,而且还可通过虚拟内存的共用加速计算能力,尽管同样受到冯·诺伊曼架构的限制,但其平均算力超过CPU几十倍甚至上千倍。
GPU同样发展多年,软硬件兼容性好,但在功耗与成本表现上仍有改善空间,此外还须考虑硬件上的投资,如额外加装冷却系统以降低发热。
03
ASIC芯片
ASIC芯片是针对特定应用开发出来的产品,在经过验证调整之后运算能力、整体功耗和成本可以达到最佳水平。
04
FPGA
FPGA同样发展多年,软硬件兼容方面值得称赞,整体算力、成本和功耗即便不是最佳水平,但也不失为一个不错的折中解决方案,对开发者来说,从FPGA入手切入AI芯片开发是个不错的角度。
突破冯·诺依曼架构瓶颈
在传统计算设备广泛采用的冯·诺依曼架构中,计算和存储功能不但是分离的,而且更侧重于计算。数据在处理器和存储器之间不停的来回传输,消耗了约80%的时间和功耗。学术界为此想出了很多方法试图改变这种状况,例如通过光互连、2.5D/3D堆叠实现高带宽数据通信,或者通过增加缓存级数、高密度片上存储这样的近数据存储,来缓解访存延迟和高功耗。 但试想一下,人类大脑有计算和存储的区别吗?我们是用左半球来计算,右半球做存储的吗?显然不是,人脑本身的计算和存储都发生在同一个地方,不需要数据迁移。
因此,学术界和产业界都希望尽快找到一种与人脑结构类似的创新架构的想法就不足为奇了,最好是能够将存储和计算有机地结合在一起,直接利用存储单元进行计算,或者是将计算单元进行分类,使之对应不同的存储单元,最大程度的消除数据迁移所带来的功耗开销,“计算存储设备(Computational Storage Device)”的应用概念应运而生。
存储业界已有公司提出很值得借鉴的概念。NVM不只存储经过数模转换器之后产生的模拟信号,还可以将算力进行输出,而输入电压和输出电流则在NVM中扮演着可变电阻的角色,将模拟电流信号经过模数转换器变为数字信号,从而完成数字信号输入-数字信号输出的全过程。这一做法的最大优势在于它完全可以利用成熟的20/28nm CMOS工艺,而不用像CPU/GPU一样去追求7nm/5nm这样费用高昂的先进制程。 而伴随成本和功耗开销的降低,时间延迟特性也得到了显著提升,这对无人机、智能机器人、自动驾驶、安防监控等应用来说都是至关重要的。 总体来说,终端推理过程计算复杂度低,涉及的任务较为固定,对硬件加速功能的通用性要求不高,无需频繁变动架构,更适合存内计算的实现。相关数据显示,2017年之前,人工智能无论是训练还是推理基本都在云端完成,但到了2023年,在边缘侧设备/芯片上进行AI推理将占据该市场一半以上的份额,总额高达200-300亿美元,这对IC厂商来说是一个非常庞大的市场。
AI需要怎样的闪存?
相信没有人会反对高品质、高可靠性和低延迟闪存(Flash Memory)对AI芯片与应用的重要性。但黄仲宇提醒,面对不同的应用,需要从性能、功耗、安全、可靠性、高效能等多方面加以综合考量,相比之下,成本考量虽然相当重要,但相较之下不是第一优先的考虑因素,不能顾此失彼。 高性能OctalNAND Flash W35N、面向低功耗应用的W25NJW系列、与安全相关的W77Q/W75F系列安全闪存,是华邦最具代表性的产品,例如,华邦QspiNAND Flash的数据传输率大概是83MB每秒,而OctalNAND系列最快的速度可以达到240MB每秒,几乎是前者的3倍;在车载应用中,大量AG1 125C NOR系列和AG2+ 115C NAND系列Flash已经量产面世;而在智能传感器或是产线机器人应用方面,华邦电子则可以提供具备成本-高效能的解决方案,比如W25N/W29N NAND Flash系列。
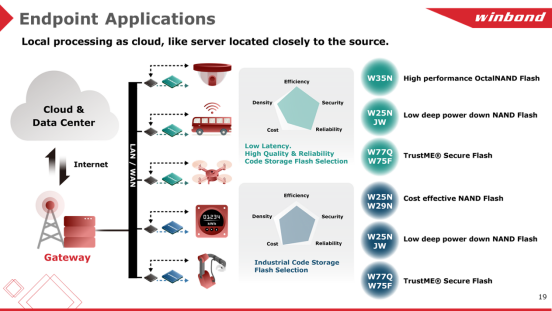
除了各式各样的不同类型的Flash产品外,华邦SpiStack (NOR+NAND) 也很具特点。它将NOR芯片和NAND芯片堆叠到一个封装中,例如64MB Serial NOR和1Gb QspiNAND芯片堆叠,使设计人员可以灵活地将代码存储在NOR芯片中,并将数据存储在NAND芯片。此外,虽然是两个芯片(NOR+NAND)的堆栈,但单一封装的SpiStack,在使用上仅需6个信号引脚。

“华邦可以提供不错的Flash选型来保护客户辛苦开发出来的代码模型。就像在一场篮球比赛中一样,芯片厂商扮演中锋或前锋,凭借强大的算力和算法不断得分,而华邦就像后卫,在后场提供高品质、高性能的Flash产品,确保用户在市场上不断得分。”黄仲宇表示。
原文标题:如何在AI终端应用中选择合适的闪存芯片
文章出处:【微信公众号:电子发烧友网】欢迎添加关注!文章转载请注明出处。
-
如何选择最合适的语音芯片2013-04-24 3583
-
tvs如何选型才最合适2020-06-12 2162
-
ADC转换器选型怎么搞?如何选择最合适的ADC转换器?2021-04-06 2068
-
怎么选择合适的嵌入式设计软件?2015-05-06 3257
-
说说如何选择最合适你的ARM开发板7.132017-10-09 853
-
一招教你如何选择最合适的变送器2018-07-09 9759
-
如何帮你的回归问题选择最合适的机器学习算法2019-05-03 3645
-
我们该如何选择最合适的LoRa产品2021-03-15 1331
-
如何在开关电源设计中选择最合适的高功率电感的磁芯方案2021-09-22 1236
-
电池保护器如何选择才最合适2022-09-02 66964
-
选择最合适的预测性维护传感器2022-12-29 1834
-
如何选择最合适的网络拓扑方式呢?如何解决CAN总线故障?2023-08-28 1123
-
为什么说没有完美的PLC,只有最合适的PLC?2023-10-14 1012
-
PCB表面处理的选择和优化,如何选择最合适的工艺?2023-11-24 1874
-
如何选择合适的RFID手持终端2024-10-29 1318
全部0条评论

快来发表一下你的评论吧 !
