

《系统工程与电子技术》—空战决策知识构建方法研究
今日头条
描述
空战决策知识构建方法研究
本文来自《系统工程与电子技术》,作者吕跃等
0 引言 随着空战训练以及作战仿真实验的深入, 战训数据随之大量产生, 需要解决“数据丰富, 知识贫乏”的数据应用问题, 挖掘数据背后的空战决策知识, 客观说明“人在回路”的空战对抗过程。空战决策知识是指在特定的空战态势情境下, 通过飞行员潜意识对态势的理解和判断, 做出相应机动决策积累的定性经验知识。定性经验知识蕴含在定量的战训大数据中, 如何通过技术手段分析、处理定量数据, 提取反应优秀飞行员空战智慧经验的战术知识, 对于指导飞行员空战决策以及多智能体智能化作战具有重大意义。 空战决策知识构建[1]是从外部空战场态势的显性知识以及飞行员决策经验型隐性知识转换到计算机内部的过程, 包含态势信息事实性知识和决策规则性知识。在知识表达方面, 文献[2]提出了一种基于情境构建的经验型隐性知识表示方法, 显示飞行员空战决策经验知识用于无人战斗机(unmanned combatair vehicle, UCAV)自主空战决策; 文献[3]基于谓词演算, 提出飞行器能力的知识表示方法, 满足飞行器自主决策的需求; 文献[4]提出基于时序图的作战指挥行为知识表示学习方法, 有效地表征了具有时序关联特征的作战指挥行为。在空战知识挖掘方面, 文献[5]以飞行数据为研究对象, 提出改进人工免疫算法对飞行状态规则进行提取, 验证了规则在实际应用中的有效性; 文献[6] 基于飞参特征变化和专家识别飞行动作的先验知识建立了飞行动作识别知识库, 可快速、准确识别各种机动动作。从研究现状来看, 在知识表达方面, 对于战场决策影响因素分析不够全面, 并且未能描述空战决策知识之间因果关系; 在知识挖掘方面, 对于直接从战训数据中获取机动决策规则知识的研究较少, 且对于海量战训数据的挖掘利用不充分。 因此, 本文在战训数据的应用基础上, 提出一种空战决策知识构建方法, 对空战决策知识的生成过程与表示方法进行分析与研究, 应用k-means聚类、最小描述长度准则(minimum description length principle, MDLP)数据预处理算法实现对战训数据的离群点检测以及连续属性离散化, 基于粗糙集理论和模糊逻辑推理实现空战决策规则知识的挖掘与推理应用, 并将构建空战决策知识应用于空战对抗过程中, 以期解决“数据丰富、知识贫乏”的数据应用问题。 1 空战决策知识 空战决策知识是对当前对抗环境中空战态势和飞行员决策相互关系的抽象和描述, 它是建立在战训数据和飞行员经验基础上的知识处理, 是知识提取和知识理解的综合过程, 满足知识处理的“战训数据-特征信息-知识获取-知识理解”层次结构。 1.1 空战决策知识的生成 空战决策知识生成环节可以分为空战对抗过程信息特征提取、决策知识的生成、决策知识的展现3个部分, 如图 1所示。空战对抗过程信息特征提取包括对战训数据的预处理, 形成空战态势信息以及包含飞行员经验的决策结果信息, 是知识生成环节的基础; 决策知识的生成是知识生成环节的核心, 包括知识的提取、推理以及理解应用; 决策知识的展现表现为知识的可视化、互操作等, 是知识生成环节的后续阶段[7]。
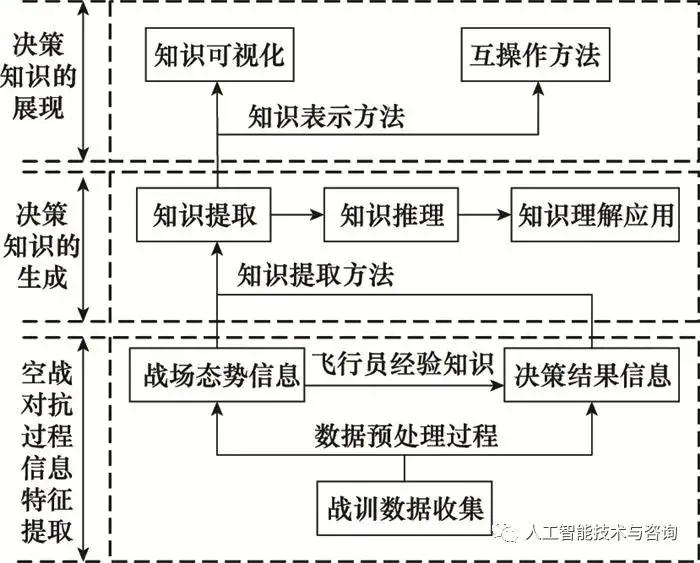
图1 空战决策知识生成过程 Fig.1 Air combat decision making knowledge generation process 本文将空战决策知识分为战场态势信息事实性知识和飞行员决策规则性知识。战场态势信息事实知识是在战训数据的基础上规范化描述战场的态势要素, 即空间几何态势、作战能力、空情事件等及其关系的表达。空间几何态势和空情事件表示状态信息的动态属性知识, 作战能力表示特征信息的静态属性知识[8]。可以表示为 == (1) 式中: Situation为空间几何态势的函数; Capability为相对作战能力的函数; Incident表征空情事件的函数。 空间态势几何函数可以表示为 Situation (t)={TA(φ,q,t),Tv(vm,vt,t),Th(hm,ht,t),Td(D,DRmax,DMmax,DMkmin,DMkmax,t)} Situation (t)={TA(φ,q,t),Tv(vm,vt,t),Th(hm,ht,t),Td(D,DRmax,DMmax,DMkmin,DMkmax,t)} (2) 式中: φ、q为目标方位角、进入角; vm、vt为载机、敌机速度; hm、ht为载机、敌机高度; D为双方作战单元的距离; DRmax为雷达最大探测距离; DMmax为导弹最大攻击距离; DMkmax、DMkmin为不可逃逸最大最小距离; TA、Tv、Th、Td为角度、速度、高度、距离态势函数, 具体计算方式见参考文献[8]。 相对作战能力函数与敌我双方战机的总体作战能力相关, 表示为 C=[lnB+ln(∑A1+1)+ln(∑A2)]ε1ε2ε3ε4C=[lnB+ln(∑A1+1)+ln(∑A2)]ε1ε2ε3ε4 (3) 式中: C为战斗机总体作战能力; B、A1、A2分别为战斗机的机动能力参数、攻击能力参数和探测能力参数; ε1、ε2、ε3、ε4分别为操纵能力参数、生存能力参数、航程能力参数和电子对抗能力参数[9]。作战能力为静态属性知识, 通过战场情报信息等手段获取得到, 用离散值Capacity={-1, 0, 1}表征相对作战能力的劣势、均势、优势。 空情事件函数表示影响空战胜负关键事件的关系, 表示为 Incident(t)={RaderOn(t),RaderLock(t), Weapon (t)}Incident(t)={RaderOn(t),RaderLock(t), Weapon (t)} (4) 式中:RaderOn(t)={0, 1}表示雷达开关机情况, 0表示雷达未开机, 1表示雷达已开机; RaderLock(t)={0, 1}表示雷达锁定情况, 0表示雷达未锁定, 1表示雷达已锁定; Weapon(t)={0, 1}表示武器发射情况, 0表示导弹未发射, 1表示导弹已发射。 飞行员决策规则性知识是飞行员在当前态势信息的基础上, 根据作战经验以及个性化特征所做出的决策方案。 < Knowledge_of_Decision >=< Pilot (V), Action (Sa)>< Knowledge_of_Decision >=< Pilot (V), Action (Sa)> (5) 式中: Pilot(V)表示飞行员主观风险态度形成的价值; Action(Sa)表示在飞行员在当前态势下的空战决策方案。 在激烈的空战对抗环境下, 飞行员不能完全保持理性, 所以在面对风险和收益时存在不同的态度, 从而导致决策结果的不同, 这也属于空战决策知识组成部分。前景理论将人的心理偏好引入决策过程中, 并将心理偏好以风险态度系数、损失规避系数等形式量化[10], 能够较好的描述飞行员空战个性化特征知识。 Pilot(V)=∑i=0nπ(pi)v(Δxi)Pilot(V)=∑i=0nπ(pi)v(Δxi) (6) 式中: π(pi)为决策权重; v(Δxi)为价值函数; 具体形式为 v(Δx)={σ(Δx)α,Δx⩾0−δ(−Δx)β,Δx<0v(Δx)={σ(Δx)α,Δx⩾0−δ(−Δx)β,Δx<0 (7) 式中: Δx为结果相对于参考点的收益或者损失; α和β为飞行员的风险偏好及规避系数, 描述价值函数在收益区域及损失区域的凹凸程度; σ和δ为收益敏感系数和损失厌恶系数, 若飞行员对收益更加敏感, 则σ>δ≥1, 若飞行员对损失更加敏感, 则δ>σ≥1。 空战决策方案集可以视为基本机动动作的组合, 当前态势下的决策方案集可以表示为 Action(Sa)=[j1,j2,⋯,jk]Action(Sa)=[j1,j2,⋯,jk] (8) 式中:k=1, 2, …, 11, jk表示基于NASA学者提出的7种基本机动动作,改进得到完备的11种空战机动动作[11], 决策问题可以表示为 ψΔt≤ts:{hm,h˙m,φ,φ˙,vm}→[j1,j2,⋯,jk]ψΔt≤ts:{hm,h˙m,φ,φ˙,vm}→[j1,j2,⋯,jk] (9) 式中:Δt为采样时间; ts表示决策过程时间上限; φ表示航向角; ψ为机动动作特征参数到决策方案集的决策函数。 通过对上述机动动作集及战斗机姿态的变化规律分析, 总结出各类机动动作对应上述特征参数的变化特征。将连续量机动特征参数区间化, 从而形成和定性描述的变化特征形成一一对应关系[12]。 在空战的高对抗性下, 飞机机动是在极短时间内根据态势情况调整机动动作特征属性变化的过程。本文用区间数[t, t+Δt]描述特征属性的变化范围, 将机动动作集根据变化规律进行区间化, 将战训数据中机动动作特征指标值作为比较序列, 机动动作集中的区间基准特征值作为参考序列, 基于灰色关联度模型, 求得关联度大小来识别机动动作, 基于区间灰色关联度机动动作识别模型实施步骤如下所示。 步骤 1 将机动动作基准特征参数区间化 u~ij=[uij−−−,uij¯¯¯¯¯¯]=[xij−2σij,xij+2σij]u~ij=[uij_,uij¯]=[xij−2σij,xij+2σij] (10) 式中:u~u~ij表示第i种基准机动动作的第j种特征指标值区间数; xij表示第i种基准机动动作的第j种特征指标值; σij表示标准方差。 步骤 2 构建决策矩阵U¯=[uij¯¯¯¯¯¯]11×5U¯=[uij¯]11×5并进行规范化处理, 得到新矩阵V~=[v~ij]11×5V~=[v~ij]11×5, 规范化方法见参考文献[8]。 步骤 3 计算比较序列与参考序列之间的关联系数ξi(k) ξi(k)=minimink(D0i)+ρmaximaxk(D0i)D0i+ρmaximaxk(D0i)ξi(k)=minimink(D0i)+ρmaximaxk(D0i)D0i+ρmaximaxk(D0i) (11) 式中:ρ为分辨系数; D0i为比较序列与参考序列区间数的欧式距离。 步骤 4 计算待识别机动动作与基本动作集的关联度Zi, 比较关联度大小识别机动动作。 Zi=1n∑k=1nξi(k),k=1,2,⋯,nZi=1n∑k=1nξi(k),k=1,2,⋯,n (12) 1.2 空战决策知识的表示 空战决策知识是态势属性结合飞行员特征到机动动作的映射, 既包含事实性知识又包含规则性知识, 存在知识间的因果关系。产生式规则表示法用于表示知识之间的因果关系, 与人的判断性知识基本一致, 且可以提供高粒度信息, 容易描述事实、规则以及它们的数量测度[13], 适用于空战决策知识的表示。 1.2.1 战场态势信息事实性知识的表示 产生式表示方法一般采用3元组对象、属性、值或者3元组关系、对象1、对象2来表示战场态势信息事实。若考虑态势信息获取的不确定性, 可以加入可信度量用4元组对象、属性、值、可信度来表示。例如: (敌机, 角度威胁值, 0.5)(态势, 载机, 敌机)(空情事件, 武器发射, 1, 0.8)。 1.2.2 飞行员决策规则知识的表示 飞行员决策规则知识是指在空战问题中的因果关系的知识, 可表示为 if Condition then Action(Sa) if Condition then Action(Sa) (13) 式中: condition为规则前件, 是战场态势信息以及飞行员个性化特征的合取, 表示为 Condition =( Situation ∧ Capability ∧ Incident ∧Pilot(V)) Condition =( Situation ∧ Capability ∧ Incident ∧Pilot(V)) (14) 式中:Action(Sa)为规则后件, 是基于规则前件的决策方案。 2 战训数据预处理 在战训数据收集、存储过程中,如果受到外界环境的干扰, 所记录的战训数据将会包含随机干扰和误差, 数据中存在离群点, 导致数据质量难以满足空战知识挖掘的要求。其次, 战训数据采用连续值记录的方式难以满足算法离散度量属性的要求。基于此, 本节采用基于k-means聚类的离群点检测以及基于MDLP的连续属性离散化来处理原始战训数据, 解决低质量战训数据导致的知识挖掘算法执行效率低以及知识生成偏差的问题。 2.1 基于k-means聚类的离群点检测 基于k-means聚类的离群点检测是通过聚类分析发现与其他对象无强相关的对象, 如果一个对象不强属于任何簇, 则认为该对象属于聚类的离群点[14]。战训数据集D被k-means聚类算法分为k个簇, C={C1, C2, …, Ck}, 对象p与所有簇间距离间的加权平均值为离群因子OF(p)。 OF(p)=∑i=1k|Cj||D|⋅d(p,Cj)OF(p)=∑i=1k|Cj||D|⋅d(p,Cj) (15) 基于k-means聚类的离群点检测流程如表 1所示。 表1 离群点检测流程 Table 1 Process of outlier detection(t),capability,incident(t)>(t),capability,incident(t)>
| 输入 战训数据集D; 聚类个数k; |
新窗口打开| 下载CSV 基于k-means聚类的离群点检测的时间和空间复杂度是线性或者接近于线性的, 效率较高, 适用于大规模数据集。 2.2 基于MDLP的连续属性离散化 属性值离散化是进行数据压缩、提取决策规则的基础, 有效的属性离散化算法不仅可以提高知识挖掘的效率, 并且可以从得到的离散战训数据中获取相对简洁的空战决策知识规则。 MDLP是一种具备监督连续属性离散化的技术, 在选择最佳的切分点时, 考虑决策信息对属性进行递归分割的影响[15], 其消息编码的位数l为 l=Ent(O)=−∑i=1kpilog2pil=Ent(O)=−∑i=1kpilog2pi (16) 式中: 编码位数l对应了分类的熵Ent(O); k对应连续属性论域O={O1, O2, …, Ok}被决策属性A∈D分割后子集的个数。 条件属性B∈C将O′∈O分为若干子集O′={O′1, O′2, …, O′m}, 则条件属性B对O分类后的熵为 Ent(B,O)=∑i=1mpiEnt(Oi)Ent(B,O)=∑i=1mpiEnt(Oi) (17) 式中: pi为权重, 即Oi的元素占论域O的比例。 pi=|Oi||O|,i=1,2⋯,mpi=|Oi||O|,i=1,2⋯,m (18) 条件属性B会影响信息熵的压缩, 信息增益为 Gain(B)=Ent(O)−Ent(B,O)Gain(B)=Ent(O)−Ent(B,O) (19) 基于MDLP的连续属性离散化方法实施步骤为: 首先确定所有的候选离散切分点集dj(j=1, 2, …, k), 在确定候选集时不需要在所有属性值中间确定切分点, 只需将属性值排序后选取类别不同的两点值间作为候选切分点。其次, 搜寻点df将论域O划分为O=O1∪O2两部分, 并且满足以下条件: Gain(df)>log2(n−1)n+δ(df)nGain(df)>log2(n−1)n+δ(df)n (20) 式中: δ(df)=log2(3t−2)−tEnt(O)+∑i=12tiEnt(Oi)δ(df)=log2(3t−2)−tEnt(O)+∑i=12tiEnt(Oi) (21) 式中: n=|O|为战训数据样本数; t为论域O中包含的类别数。 最后, 将上述O1、O2两子区间重复递归上述步骤, 直至式(20)不满足为止。 3 基于粗糙集模糊理论的空战决策知识推理 粗糙集(rough set, RS)理论能够有效地处理战训数据, 从中发现隐含的空战决策知识, 通过决策知识属性的约简, 提取飞行员空战最小决策规则知识。模糊逻辑(fuzzy logical, FL)推理能够将战场态势信息和飞行员个性化特征, 根据粗糙集提取的最小决策规则推理得到模糊逻辑决策即机动动作的控制量, 实现空战决策知识的推理与应用。 3.1 基于RS最小空战决策规则知识库 S=(U, A, V, f)[16]是空战决策知识信息表, 其中: U={x1, x2, …, xm}为战训数据集; A=C∪D={a1, a2, …, an}为属性集合; 子集C为条件属性, 代表战场态势信息及飞行员个性化特征; 子集D为决策属性, 代表机动动作方案集; V=⋃a∈AVaV=⋃a∈AVa为属性值的集合, f: U×A→V为U和A之间的关系集。 属性子集a在U上不可分辨关系Ia为 Ia={(x,y)∈U×U:f(x,a)=f(y,a),∀a∈A}Ia={(x,y)∈U×U:f(x,a)=f(y,a),∀a∈A} (22) 在S中属性a的决策矩阵[17]为 MDa(S)=(δDa(xi,xj))m×mMaD(S)=(δaD(xi,xj))m×m (23) 式中: δDa(xi,xj)={a∈A:a(xi)≠a(xj) 且 ∂A(xi)≠∂A(xj)}δaD(xi,xj)={a∈A:a(xi)≠a(xj) 且 ∂A(xi)≠∂A(xj)} (24) 通过决策矩阵ΜαD建立x∈U的决策函数为 fDA(x)=⋀y∈U{∨a∗:a∈δDA(x,y) 且 δDA(x,y)≠∅}fAD(x)=⋀y∈U{∨a∗:a∈δAD(x,y) 且 δAD(x,y)≠∅} (25) 对信息表S中所有决策类进行区分: gDA(U)=⋀x∈UfDA(x)gAD(U)=⋀x∈UfAD(x) (26) 式中: gAD(U)的主蕴涵表示区分决策类所需条件属性最小子集。 决策表中决策属性D的约简满足下述关系: B∈Red(S, D)↔∧a∈Ba∗∧a∈Ba∗为gAD(U)的一个主蕴涵; B∈Red(S, x, D)↔∧a∈Ba∗∧a∈Ba∗为fAD(x)的一个主蕴涵。 由约简确定最小决策规则: RUL(S,x,d)={FB(x)→(∂B=∂B(x)):B∈Red(S,x,d)}RUL(S,x,d)={FB(x)→(∂B=∂B(x)):B∈Red(S,x,d)} (27) RUL(S,d)=⋃x∈URUL(S,x,d)RUL(S,d)=⋃x∈URUL(S,x,d) (28) 3.2 空战决策规则知识模糊逻辑推理 模糊逻辑推理是基于模糊逻辑中的蕴涵关系和推理规则来进行[18], 是模糊逻辑控制的基础, 是进行不确定性推理的方法之一, 空战决策规则知识模糊逻辑推理系统组成如图 2所示。
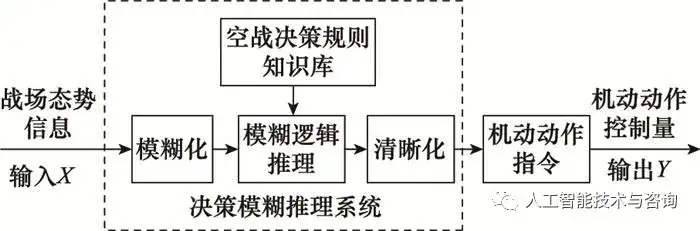
图2 模糊逻辑推理系统组成 Fig.2 Composition of fuzzy logic inference system 决策模糊推理系统的输入X与输出Y分别为战场态势信息以及飞行员个性化特征知识X={Situation, Capacity, Incident, Pilot}和机动动作控制量切向过载、法向过载以及滚转角Y={nx, nz, γ}, 其数学表现形式为 X(x1,x2,x3,x4)⟶FLJ(j1,j2,⋯,j11)⟶MPY={nx,ny,γ}X(x1,x2,x3,x4)⟶FLJ(j1,j2,⋯,j11)⟶MPY={nx,ny,γ} (29) 式中: FL表示模糊推理过程; J为11中机动动作方案集; MP机动动作与控制量之间的对应关系。 空战决策规则知识库由粗糙集理论进过属性约简后确定的最小决策规则得到, 用“if…then…”语句表示, 其规则库形式为 R={R1MISO,R2MISO,⋯,RnMISO}R={RMISO1,RMISO2,⋯,RMISOn} (30) 式中: RMISO表示多输入单输出规则。 RiMISO={[(A1×A2×⋯×An)→Di1],[(A1×A2×⋯×An)→Di2],⋯,[(A1×A2×⋯×An)→Diq]}RMISOi={[(A1×A2×⋯×An)→Di1],[(A1×A2×⋯×An)→Di2],⋯,[(A1×A2×⋯×An)→Diq]} (31) 对于第i条规则的模糊蕴涵关系Ri定义为 Ri=(A1 and A2 and ⋯ and Ai)→DiRi=(A1 and A2 and ⋯ and Ai)→Di (32) 即: uRi=u(A1 and A2 and ⋯ and Ai)→Di(a1,a2,⋯,ai,di)=[uA1(a1) and uA2(a2) and ⋯ and uAi(ai)]→uDi(di)uRi=u(A1 and A2 and ⋯ and Ai)→Di(a1,a2,⋯,ai,di)=[uA1(a1) and uA2(a2) and ⋯ and uAi(ai)]→uDi(di) (33) 式中: u为模糊隶属度函数。 3.3 空战决策知识构建流程 将粗糙集理论和模糊逻辑推理理论相结合构成了空战决策知识的构建模型, 其基础是战训数据以及战训数据的预处理, 具体流程如图 3所示。
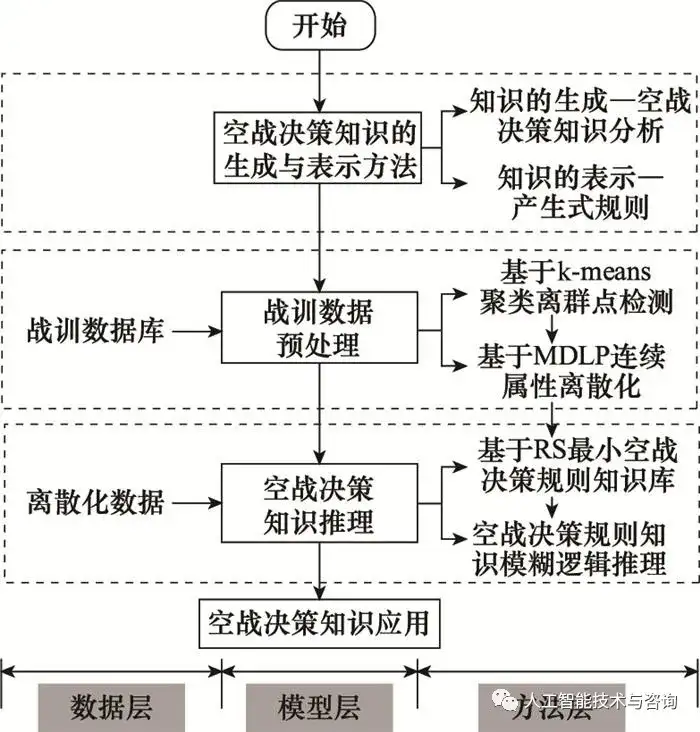
图3 空战决策知识构建流程 Fig.3 Construction process of Air combat decision knowledge 4 仿真分析与验证 4.1 战训数据预处理 选取部分飞行速度数据为例, 并检验算法的有效性, 设置参数k=2, 阈值Θ=1 500。待检测速度样本以及离群点检测如图 4所示。
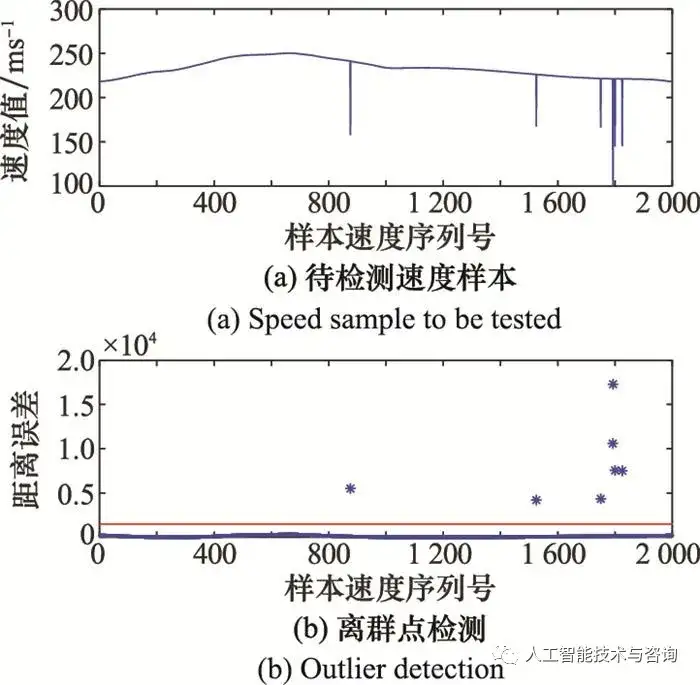
图4 原始数据离群点检测 Fig.4 Original data outlier detection 从图 4检测结果来看, 待检测速度样本中存在离群点, 序列号为(876, 1 525, 1 750, 1 792, 1 793, 1 800, 1 825), 表明本文采用的数据离群点检测方法是有效的。 将机动动作识别结果作为决策属性, 根据战训数据中角度、速度、距离和高度数据, 以及文献[8]提出的态势优势函数, 计算得到战场态势信息事实性知识中的空间几何态势为连续属性值, 部分节点态势值如图 5所示, 基于MDLP连续属性离散化方法得到离散型知识, 如图 6所示。
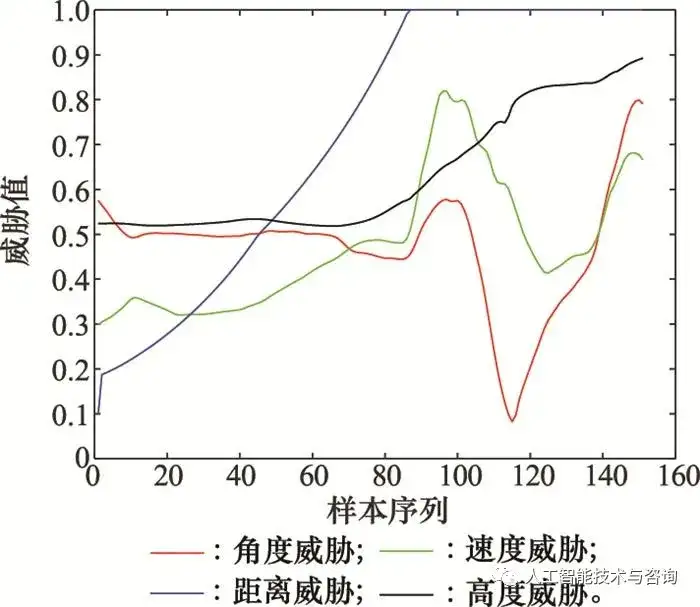
图5 空战几何态势图 Fig.5 Geometry of air combat
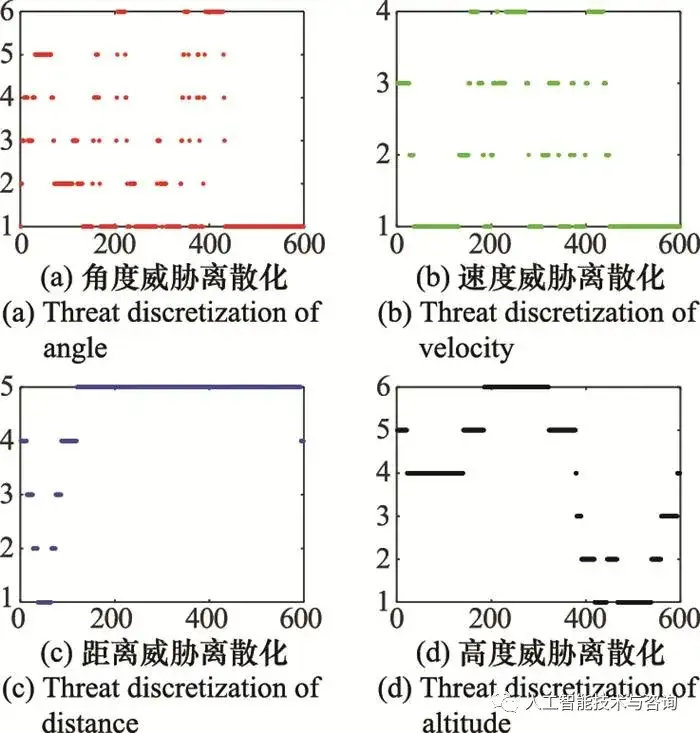
图6 离散化空战几何态势知识 Fig.6 Discretization of geometric situation knowledge of air combat 从图 5空战几何态势图来看, 空战对抗过程是高对抗性以及高敏捷性的敌我双方博弈过程, 飞行员根据作战经验以及对空战事实性知识的理解, 做出相应的机动动作, 这其中包含了丰富的空战决策知识, 从中提取有效的决策规则知识对于指导飞行员作战以及空战智能决策具有重要意义。 从图 6离散化结果来看, MDLP方法分别选取了角度威胁、速度威胁、距离威胁和高度威胁连续属性的5个、3个、4个、5个切分点, 并将其分为[1,6]、[1,4]、[1,5]、[1,6]离散值区间, 满足式(20)条件, 切分点如表 2所示。 表2 切分点区间 Table 2 Segmentation points interval
| 威胁属性 | 切分点区间 |
新窗口打开| 下载CSV 4.2 机动动作识别 选取时间间隔Δt=0.5 s, 分辨系数ρ=0.5, 用区间数表示战训数据中记录的我方机动动作特征参数值, 每种机动动作的识别用5种特征参数计算, 即高度hm、高度变化率h˙h˙m、航向角φ、航向角变化率φ˙φ˙、速度vm。根据专家知识将机动动作集J=[j1, j2, …, jk], k=1, 2, …, 11依次分为匀速直飞、加速前飞、减速前飞、爬升、左爬升、右爬升、俯冲、左俯冲、右俯冲、左转弯、右转弯11种, 各机动动作参数特征分析如表 3所示。 表3 机动动作特征参数分析 Table 3 Analysis of characteristic parameters of maneuver
| J | hm | h˙h˙m | φ | φ˙φ˙ | vm |
新窗口打开| 下载CSV 根据式(10)得到的计算机动动作特征参数方差σij, 得到基准特征参数区间数u~u~ij, 构建决策矩阵并规范化处理得到新矩阵V~V~, 将待识别机动动作的特征参数值作为行向量, 规范化处理后计算与参考序列之间的距离D0i, 根据式(11)计算比较序列与参考序列之间的关联系数ξi(k), 根据式(12)计算关联度大小Zi, 比较关联度大小识别机动动作, 基于区间关联度的机动动作识别结果如图 7所示。

图7 机动动作识别 Fig.7 Maneuvering identification 4.3 空战最小决策规则提取 在空战对抗前, 根据战场情报信息等手段判断敌机类型, 根据式(3)计算得到敌我双方相对作战能力; 在战训大数据中包含了雷达的开关机时间、雷达状态、武器状态等信号参数, 通过对数据的分析、提取, 得到空情事件的状态, 形成空情事件知识; 在高对抗性和敏捷性的空战环境下, 飞行员面对态势风险和收益时, 根据飞行员主观特点以及经验, 会有保守型, 稳健型和冒险型的不同决策态度, 这也是空战决策知识的组成部分之一, 根据式(6)~式(7)和文献[10]方法计算得到不同飞行员在面对不同态势下的价值, 离散化形成飞行员个性化特征知识。为了表示方便将角度威胁、速度威胁、距离威胁、高度威胁、相对作战能力、雷达开关机、雷达锁定、武器发射、飞行员个性化特征9个空战决策条件属性记为a1, a2, a3, a4, a5, a6, a7, a8, a9, 空战机动动作决策属性记为D, 由于篇幅限制, 列出部分节点空战知识构建决策信息表如表 4所示。 表4 决策信息表 Table 4 Decision information table
| 战训数据集U | 决策属性D | 条件属性C | ||||||
| a1 | a2 | a3 | a4 | a5 | a6 | a7 | a8 | a9 |
新窗口打开| 下载CSV 通过式(22)~式(24)构建对称的决策矩阵MaD(S)600×600, 由于决策信息表中存在不相容的数据, 说明针对不同的态势知识情况, 飞行员做出的决策存在不确定性, 本文暂不考虑, 将不相容数据删除处理。决策表全局约简为 gDA(U)=⋀x∈UfDA(x)=(a1∧a2∧a3∧a4∧a9)∨(a1∧a2∧a3∧a4∧a8)gAD(U)=⋀x∈UfAD(x)=(a1∧a2∧a3∧a4∧a9)∨(a1∧a2∧a3∧a4∧a8) 空战知识全局决策具有下列主蕴涵: (a1∧a2∧a3∧a4∧a9),(a1∧a2∧a3∧a4∧a8)(a1∧a2∧a3∧a4∧a9),(a1∧a2∧a3∧a4∧a8) 这些主蕴涵可以导出属性约简: {a5,a6,a7,a8},{a5,a6,a7,a9}{a5,a6,a7,a8},{a5,a6,a7,a9} 通过空战决策信息表的约简得到区分决策属性所需最小条件属性集合, 对应着空战最小决策规则知识, 计算共得到83条规则, 图 8为基于平行坐标图的部分规则可视化。
图8 空战决策规则可视化 Fig.8 Visualization of air combat decision rules 4.4 构建空战决策规则知识模糊逻辑推理系统 进行空战决策知识推理之前需要将态势信息等清晰量模糊化, 将观测量映射为模糊集合。根据基于MDLP划分的切分点区间设计模糊隶属度函数能够有效地决策属性对属性递归分割的影响。选择高斯型隶属函数, 能够体现人类判断的思维方式。 高斯函数的中心点c为邻近区分点的中心点, 曲线的宽度根据区分点区间长度来设定, 图 9为角度威胁模糊隶属度函数, 图 10为模糊规则浏览器。
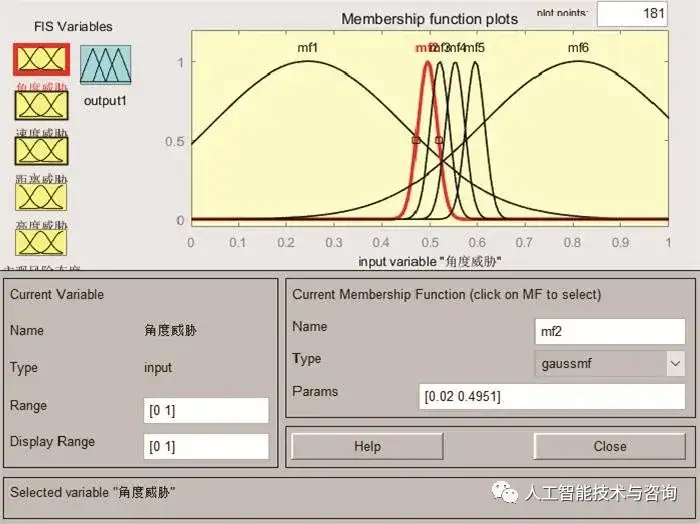
图9 角度威胁模糊隶属度函数 Fig.9 Angle threat fuzzy membership function
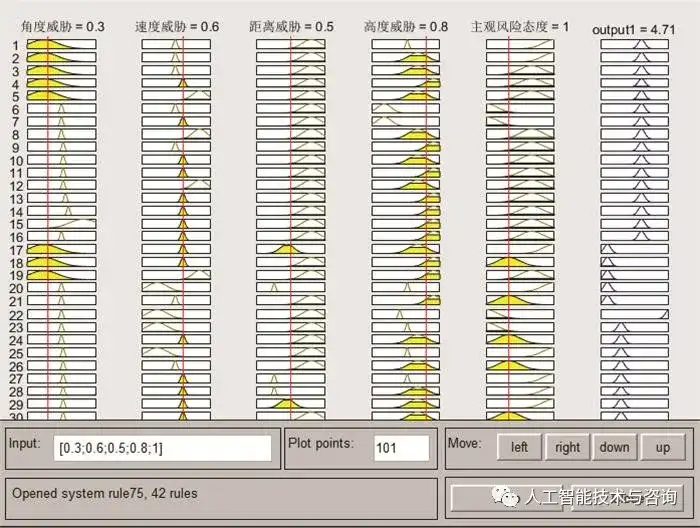
图10 模糊规则浏览器 Fig.10 Fuzzy rules browser 4.5 空战决策知识应用 将构建的空战决策规则知识模糊推理系统应用到空战对抗过程中, 验证方法的有效性。 情况 1 目标作左转弯机动, 初始时刻载机尾后接敌 载机的初始位置为(0, 0, 5 000)m, 速度为350 m/s, 航迹倾角为0°, 航迹偏角为-120°, 目标的初始位置为(30 000, 30 000, 5 000)m, 速度为350 m/s, 航迹倾角为0°, 航迹偏角为-120°, 空战对抗轨迹如图 11所示, 载机机动决策指令如图 12所示, 基于参考文献[8]中态势评估模型计算出的态势变化情况如图 13所示。
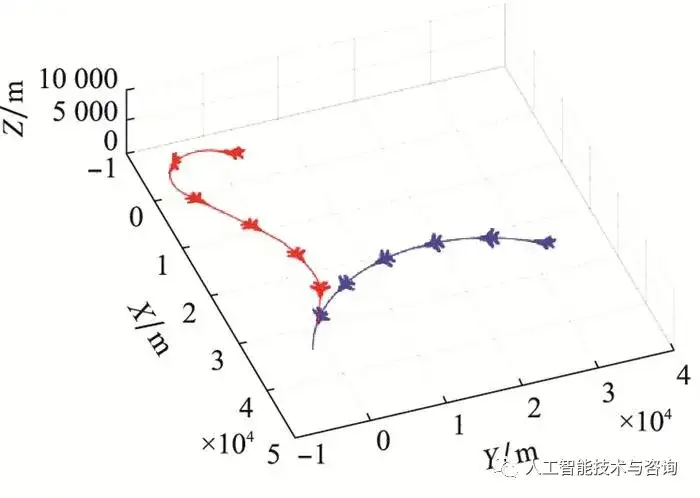
图11 空战对抗轨迹 Fig.11 Air combat trajectory
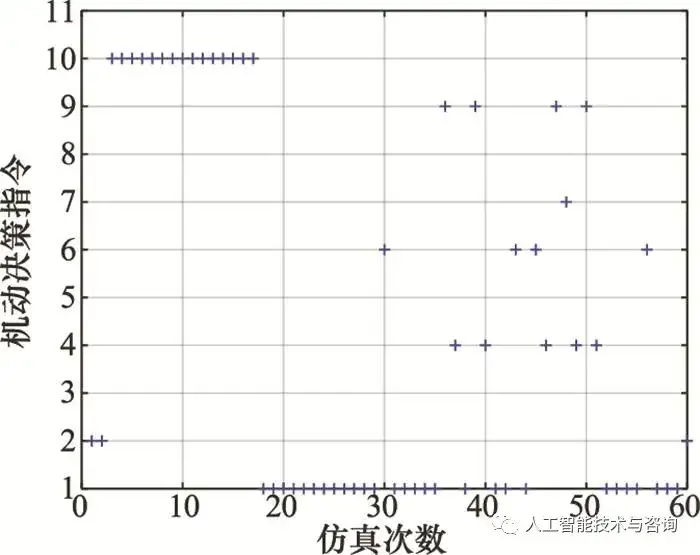
图12 情况1时载机机动决策指令 Fig.12 Our fighter's maneuver decision instruction in case 1
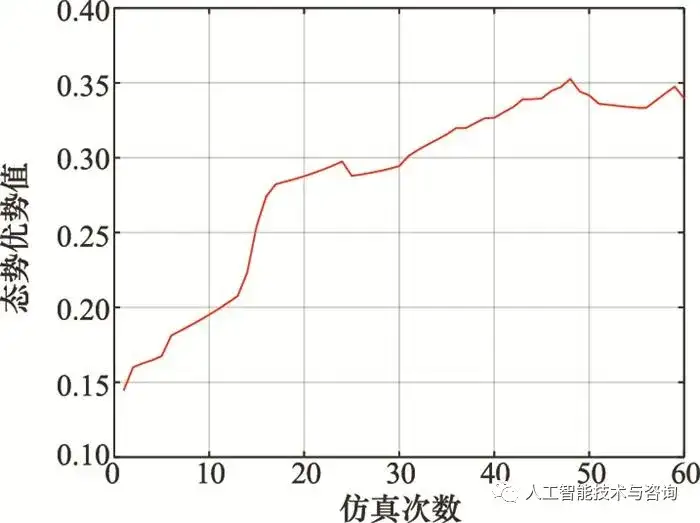
图13 情况1时载机相对态势优势 Fig.13 Relative situation advantage of our fighter in case 1 从图 10~图 13可以看出, 当目标处于载机侧后方时, 载机处于态势劣势, 载机进行加速前飞以及左转弯机动正向接敌, 并且结合进行右爬升、爬升以及右俯冲占据最佳高度, 绕至目标后方并形成对目标的尾追态势, 获取态势相对优势。 情况 2 目标作蛇形机动, 初始时刻载机正面接敌 载机的初始位置为(0, 0, 5 000)m, 速度为350 m/s, 航迹倾角为0°, 航迹偏角为60°, 目标的初始位置为(30 000, 30 000, 5 000)m, 速度为350 m/s, 航迹倾角为0°, 航迹偏角为-90°, 空战对抗轨迹、载机机动决策指令以及态势变化情况如图 14~图 16所示。
图14 空战对抗轨迹 Fig.14 Air combat trajectory
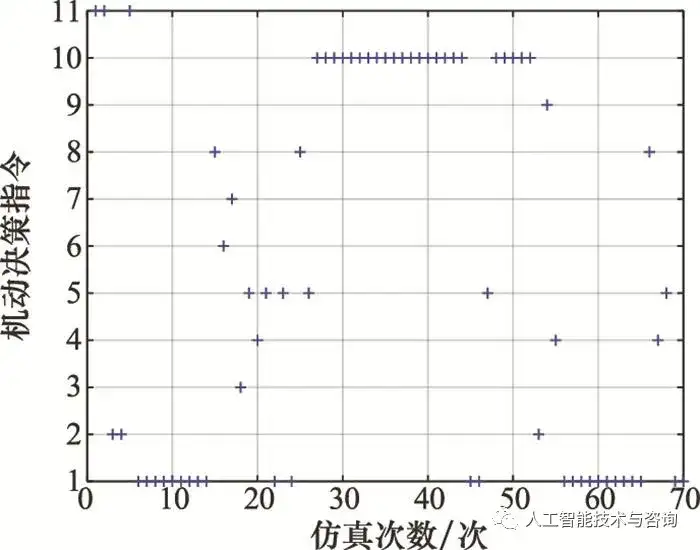
图15 情况2时载机机动决策指令 Fig.15 Our fighter's maneuver decision instruction in case 2
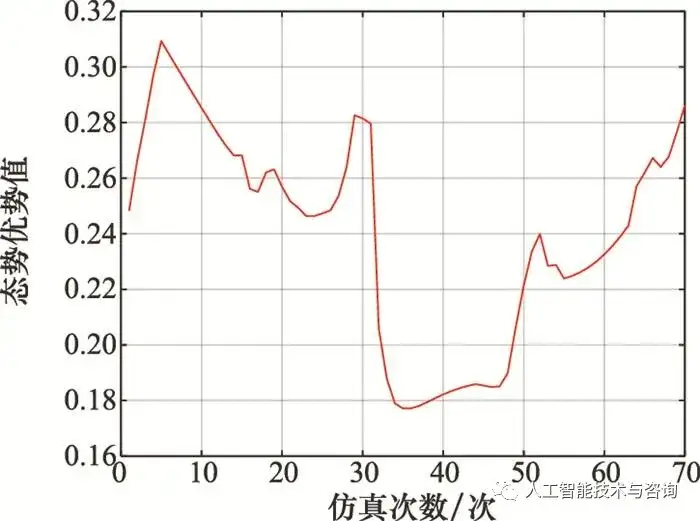
图16 情况2时载机相对态势优势 Fig.16 Relative situation advantage of our fighter in case 2 从图 14~图 16可以看出, 初始阶段载机与目标处于迎头态势, 载机与目标均可采用侧向迂回接敌的策略, 载机加速前飞以及右转弯机动, 随着空战距离的缩进, 载机的相对态势优势值逐渐减小, 在迎头阶段未分出胜负情况下, 载机与目标都会进行转弯机动, 目的是绕至对方后方形成尾追态势, 载机采用大过载机动, 连续左转弯, 迅速绕至目标后方形成尾追态势, 重新获取空战态势相对优势。 本文构建的空战决策知识属于单步决策, 是根据当前战场态势事实性知识在飞行员主观因素影响下得出的单步决策方案, 提取的空战决策规则知识是基于1Vs1空战仿真案例, 适用于1Vs1条件下飞行员当前时刻机动动作决策提示或者1Vs1条件下自主空战机动动作选择。 5 结论 本文从空战决策知识的生成与表示出发, 在全面考虑空战场决策影响因素基础上, 研究了空战决策知识的生成与表示方法; 由于战训数据存在噪声数据以及连续属性数据难以满足数据挖掘算法离散度量的要求, 应用了数据离群点检测以及连续属性离散化算法, 均能达到较好的数据预处理效果; 基于预处理后的战训数据, 提出了一种空战最小决策规则提取方法以及空战决策知识的应用推理方法。通过仿真验证分析, 本文提出的空战决策知识构建方法能够应用在指导飞行员1Vs1空战决策以及1Vs1无人作战方面, 对于解决战训大数据处理与应用、空战知识挖掘问题具有借鉴意义, 后续将进一步研究空战决策规则知识的精度与适用度问题以及多机协同下空战决策知识的构建问题。
审核编辑:符乾江-
电子技术课程设计分享2022-12-15 803
-
嵌入式系统工程专业就业方向与前景是什么2021-12-20 1491
-
可靠性系统工程中的测试性技术2020-12-25 2260
-
电力电子技术的概念2019-07-10 15101
-
《电子技术实验指导》下载2018-12-30 5047
-
如何快速学好电子技术2018-09-06 2512
-
第5版模拟电子技术基础PDF分享2017-12-18 118192
-
GNSS系统工程师-深圳2015-03-11 2273
-
如何从零开始学习电子技术呢2013-05-20 2384
-
决策支持系统在电子政务中的应用2011-03-04 2370
-
口诀总结法在《电子技术基础》教学中的应用2010-04-22 12270
-
数字电子技术基础教学大纲2009-10-11 3159
-
工艺规则知识管理系统的研究与开发2009-08-24 548
-
基于多Agent的UCAV群空战战术决策系统研究2009-08-11 837
全部0条评论

快来发表一下你的评论吧 !
