

vivo服务端监控架构设计与实践
描述
当今时代处在信息大爆发的时代,信息借助互联网的潮流在全球自由的流动,产生了各式各样的平台系统和软件系统,越来越多的业务也会导致系统的复杂性。
当核心业务出现了问题影响用户体验,开发人员没有及时发现,发现问题时已经为时已晚,又或者当服务器的CPU持续增高,磁盘空间被打满等,需要运维人员及时发现并处理,这就需要一套有效的监控系统对其进行监控和预警。
如何对这些业务和服务器进行监控和维护是我们开发人员和运维人员不可忽视的重要一环,这篇文章全篇大约5000多字,我将对vivo服务端监控的原理和架构演进之路做一次系统性整理,以便大家做监控技术选型时参考。
vivo服务端监控旨在为服务端应用提供包括系统监控、JVM监控以及自定义业务指标监控在内的一站式数据监控,并配套实时、多维度、多渠道的告警服务,帮助用户及时掌握应用多方面状态,事前及时预警发现故障,事后提供详实的数据用于追查定位问题,提升服务可用性。目前vivo服务端监控累计接入业务方数量达到200+,本文介绍的是服务端监控,我司还有其他类型的优秀监控包括通用监控、调用链监控和客户端监控等。
1.1 监控系统的基本流程
无论是开源的监控系统还是自研的监控系统,整体流程都大同小异。
1)数据采集:可以包括JVM监控数据如GC次数,线程数量,老年代和新生代区域大小;系统监控数据如磁盘使用使用率,磁盘读写的吞吐量,网络的出口流量和入口流量,TCP连接数;业务监控数据如错误日志,访问日志,视频播放量,PV,UV等。
2)数据传输:将采集的数据以消息形式或者 HTTP 协议的形式等上报给监控系统。
3)数据存储:有使用 MySQL、Oracle 等 RDBMS 存储的,也有使用时序数据库OpenTSDB、InfluxDB 存储的,还有使用 HBase 直接存储的。
4)数据可视化:数据指标的图形化展示,可以是折线图,柱状图,饼图等。
5)监控告警:灵活的告警设置,以及支持邮件、短信、IM 等多种通知通道。
1.2 如何规范的使用监控系统
在使用监控系统之前,我们需要了解监控对象的基本工作原理,例如JVM监控,我们需要清楚JVM的内存结构组成和常见的垃圾回收机制;其次需要确定如何去描述和定义监控对象的状态,例如监控某个业务功能的接口性能,可以监控该接口的请求量,耗时情况,错误量等;在确定了如何监控对象的状态之后,需要定义合理的告警阈值和告警类型,当收到告警提醒时,帮助开发人员及时发现故障;最后建立完善的故障处理体系,收到告警时迅速响应,及时处理线上故障。
二、vivo服务端监控系统架构及演进之路
在介绍vivo服务端监控系统架构之前,先带大家了解一下OpenTSDB时序数据库,在了解之前说明下为什么我们会选择OpenTSDB,原因有以下几点:
1) 监控数据采集指标在某一时间点具有唯一值,没有复杂的结构及关系。
2)监控数据的指标具有随着时间不断变化的特点。
3)基于HBase分布式、可伸缩的时间序列数据库,存储层不需要过多投入精力,具有HBase的高吞吐,良好的伸缩性等特点。
4)开源,Java实现,并且提供基于HTTP的应用程序编程接口,问题排查快可修改。
2.1 OpenTSDB简介
1)基于HBase的分布式的,可伸缩的时间序列数据库,主要用途就是做监控系统。譬如收集大规模集群(包括网络设备、操作系统、应用程序)的监控数据并进行存储和查询,支持秒级数据采集,支持永久存储,可以做容量规划,并很容易地接入到现有的监控系统里,OpenTSDB的系统架构图如下:
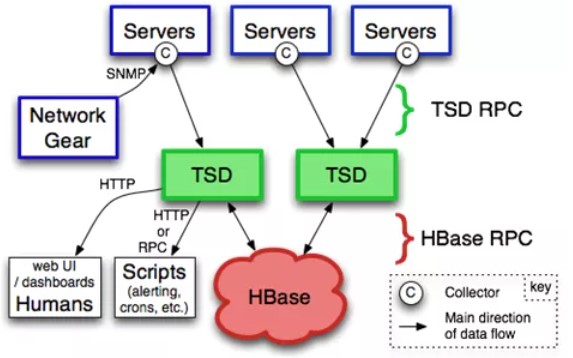
存储结构单元为Data Point,即某个Metric在某个时间点的数值。Data Point包括以下部分:
Metric,监控指标名称;
Tags,Metric的标签,用来标注类似机器名称等信息,包括TagKey和TagValue;
Value,Metric对应的实际数值,整数或小数;
Timestamp,时间戳。
核心存储两张表:tsdb和tsdb-uid。表tsdb用来存储监控数据,如下图:

Row Key为Metric+Timestamp的小时整点+TagKey+TagValue,取相应的字节映射组合起来;列族t下的Qualifier为Timestamp的小时整点余出的秒数,对应的值即为Value。
表tsdb-uid用来存储刚才提到的字节映射,如下图:

图中的“001”表示tagk=hots或者tagv=static,提供正反查询。
2)OpenTSDB使用策略说明:
不使用OpenTSDB提供的rest接口,通过client与HBase直连;
工程端禁用compact动作的Thrd线程;
间隔10秒获取Redis缓冲数据批量写入OpenTSDB。
2.2 OpenTSDB在实践中需要关注的点
1)精确性问题
String value = "0.51";
float f = Float.parseFloat(value);
int raw = Float.floatToRawIntBits(f);
byte[] float_bytes = Bytes.fromInt(raw);
int raw_back = Bytes.getInt(float_bytes, 0);
double decode = Float.intBitsToFloat(raw_back);
/**
* 打印结果:
* Parsed Float: 0.51
* Encode Raw: 1057132380
* Encode Bytes: 3F028F5C
* Decode Raw: 1057132380
* Decoded Float: 0.5099999904632568
*/
System.out.println("Parsed Float: " + f);
System.out.println("Encode Raw: " + raw);
System.out.println("Encode Bytes: " + UniqueId.uidToString(float_bytes));
System.out.println("Decode Raw: " + raw_back);
System.out.println("Decoded Float: " + decode);
如上代码,OpenTSDB在存储浮点型数据时,无法知悉存储意图,在转化时会遇到精确性问题,即存储"0.51",取出为"0.5099999904632568"。
2)聚合函数问题
OpenTSDB的大部分聚合函数,包括sum、avg、max、min都是LERP(linear interpolation)的插值方式,即所获取的值存在被补缺的现象,对于有空值需求的使用很不友好。详细原理参见OpenTSDB关于interpolation的文档。
目前vmonitor服务端监控使用的OpenTSDB是我们改造后的源码,新增了nimavg函数,配合自带的zimsum函数满足空值插入需求。
2.3 vivo服务端监控采集器原理
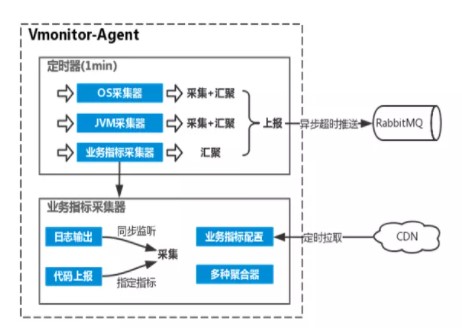
1)定时器
内含3种采集器:OS采集器、JVM采集器和业务指标采集器,其中OS及JVM每分钟执行采集和汇聚,业务指标采集器会实时采集并在1分钟的时间点完成汇聚重置,3份采集器的数据打包上报至RabbitMQ,上报动作异步超时。
2)业务指标采集器
业务指标采集方式有2种:日志输出过滤和工具类代码上报(侵入式),日志输出过滤是通过继承log4j的Filter,从而获取指标配置中指定的Appender输出的renderedMessage,并根据指标配置的关键词、聚合方式等信息进行同步监听采集;代码上报根据代码中指定的指标code进行message信息上报,属于侵入式的采集方式,通过调用监控提供的Util实现。业务指标配置每隔5分钟会从CDN刷新,内置多种聚合器供聚合使用,包括count计数、 sum求和、average平均、max最大值和min最小值统计。
2.4 vivo服务端监控老版本架构设计
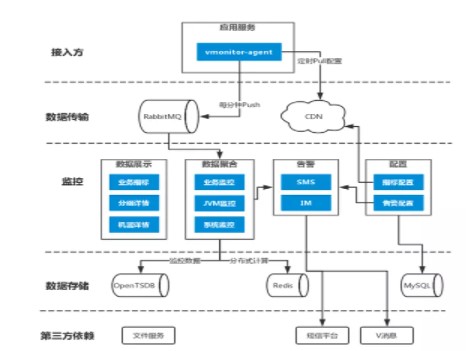
1)数据采集及上报:需求方应用接入的监控采集器vmonitor-agent根据监控指标配置采集相应数据,每分钟上报1次数据至RabbitMQ,所采用的指标配置每5分钟从CDN下载更新,CDN内容由监控后台上传。
2)计算及存储:监控后台接收RabbitMQ的数据,拆解后存储至OpenTSDB,供可视化图表调用,监控项目、应用、指标和告警等配置存储于MySQL;通过Zookeeper和Redis实现分布式任务分发模块,实现多台监控服务协调配合运作,供分布式计算使用。
审核编辑:汤梓红
-
服务端的测试主要是测什么内容2024-05-30 6439
-
商城库存系统中心架构设计与实践案例2023-08-30 2567
-
MQTT中服务端和客户端2023-07-30 4083
-
监控服务器资源利用率的服务端脚本2023-01-22 1711
-
监控系统客户端及服务端设计2021-12-21 1858
-
TCP服务端测试工具2020-06-29 2168
-
采用服务端完成端口通信技术对路灯监控系统软件进行优化设计2020-05-26 2206
-
TCP服务端的实现2019-09-26 1091
-
SSRF服务端请求伪造攻击2017-09-07 651
-
Android 仿QQ客户端及服务端源码2017-03-19 1249
-
Delphi教程之建立基本MTS服务端2016-04-11 743
全部0条评论

快来发表一下你的评论吧 !
