

基于H.264解码器的软件优化
视频技术
描述
1 引言
H.264 是在ITU-T和ISO/IEC等组织先前制定的编码标准的基础上提出的,它与现今国际上大多数的视频压缩标准一样,例如H.264、H.263、 MPEG-2、MPEG-4都是采用基于块的离散余弦变换与量化相结合的混合编码技术。基于分块的离散余弦变换具有压缩率高,计算复杂度低。易于实现等优点。H.264具有以下特点:比H.263+和MPEG-4(SP)减小50%码率;对信道时延的适应性较强;提高差错恢复能力;复杂度可分级设计,以适应不同复杂度的应用;引入先进技术,包括4×4整数变换、空域内的帧内预测、1/4像素精度的运动估计新技术带来较高的编码比,同时大大提高算法的复杂度。因此,H.264技术已广泛应用于高清视频的编解码设备。
视频解码算法的熵解码、反量化、反变换、帧内预测、帧间亮度插值、帧间色度插值以及去方块滤波等称为核心模块,减少这些核心模块的等待时间对加快解码器的工作具有重要意义。本文在DSP-BF533平台上,利用软件流水的思想,针对软件模块间协同工作提出一种新型的优化设计方案。
2 H.264解码器原理
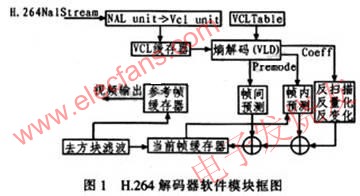
H.264编码器结构系统由以下几部分组成:网络数据提取层(NAL)、VAL缓存器、熵解码、反扫描反量化反变换、帧间预测、帧内预测、图像参考帧缓存器、去方块滤波,如图1所示。首先从码流中获取NAL单元数据,通过RBSP解析出序列参数集、图像参数集和图像数据。把数据和参数存储在VCL缓存器中,然后再在视频编码层(VCL Table)中熵解码。熵解码模块(VLD)解析所有参数和参考图像索引等,提供各种控制信息和残差数据。通过反量化反变化先将一维数据转换成二维数组或矩阵,再通过逆扫描过程将变换系数量化值序列映射到对应坐标,主要有逆zig_zag扫描和逆场扫描两种模式。之后读取数据读取并进行判断、帧内预测和帧间预测,再综合所有预测和反变换反量化的数据,最后进行方块滤波,这样能够大大减轻因预测、量化而产生的块效应,从而获得更好的主观图像质量和客观性能。同时还可选取已恢复的图像作为后续处理图像的参考帧。
3 DSP-BF533的解码器设计与优化
3.1 解码器软件设计框图
根据DSP-BF533的内含存储器控制器(DMA)的特点,设计一个整合DMA的解码流程,如图2所示。把两个与DMA有关的步骤添加到普通解码器中,步骤1是从片外存储器中读取数据;步骤2是将已处理好的数据输出到片外存储器。

从图2中可看到具体流程:①对下一个宏块进行顶部数据分割,分割出残差数据之前的数据。同时为解码提供帧内预测、参考图像索引和向量;②启动DMA读取分割出来的数据,其中也要读入解码参考图像索引和向量;③对图像数据进行帧内预测;④利用底部分割读入的映射数据,进行反变换和反量化;⑤通过滤波重建图像;⑥通过DMA把图像数据输出到片外和片内存储器;⑦对下一个宏块进行底部数据分割,然后取出映射数据供下一个宏块解码使用嘲。
为了避免DSP内核等待DMA读人数据,把解码数据预先从宏块中分割成顶部数据和底部数据,顶部数据包括残差数据之前的数据,剩下的数据就是底部数据。如果有P 帧到来时数据已事先分割,然后DMA启动。当DSP内核在解码当前宏块时,DMA读入下一个宏块。如果在当前宏块参考数据需要利用时,此数据解码完成后还可通过DMA输入到片内存储器。因为当前宏块顶部数据对下一个宏块的滤波没有参考价值,所以这些宏块顶部数据就被DMA传送到外部存储器。该设计第1个宏块未进入解码过程,因为初始状态时一系列参考图像和参数都没有设定,所以第1个宏块只是设定解码器参考图像和参数行初始化,为下一宏块解码使用。宏块数据的分割和DMA的数据读入都可在解码中并行执行,即执行当前宏块时可设定下一个宏块所需参数以及读入解码数据,这样可减少各模块间的等待时间,提高工作效率。上述可并行执行的过程如图2中以椭圆方框表示。
3.2 软件流水新型算法
很多设计中,解码参数准备、解码和DMA的数据输出等过程按顺序串行执行的,该设计有条理安排这3个过程并行执行,充分利用DSP-BF533的指令并行执行特点,减少各软件模块之间的等待时间。
下面以4×4的宏块矩阵为例,首先给4×4矩阵标上4行4列的坐标,然后把程序处理分成5个阶段.其状态分别按顺序对应1、2、4、8、16,以便状态机运算,如表1所列。CAVLC为解析读入的数据并为后续的图像整合重建提供参数和参考图像等数据的过程,hl_decode是高级解码过程,即根据准备好的条件综合重建图像的过程。DMA是对已解码数据的传送过程。对照表1和表2分析:当新的一帧图像到来时,当前状态标号为1,此时只有CAVLC执行;当运行到坐标为x=1,y=0时,进入第2个状态,当前状态标号为2,CAVLC和hl_decode并行执行;当运行到坐标x=1,y=1时,进入第3个状态,标号为4,3个模块同时并行执行;到坐标y>4时,进入第4个状态,标号为8,只有hl_decode和DMA两个并行执行,CAVLC已经完成对所有宏块的解码前准备工作;再判断x>0,进入第5个状态。标号为16,此时只运行DMA模块。

因此,解码第1个宏块时处在状态1,之后连续4个宏块是状态2,再连续11个宏块进入状态3,随后1个宏块是状态4,最后3个宏块进入状态5。
如果假设CAVLC的执行时间A,hl_decode的执行时间B,DMA的执行时间C,普通算法的执行总时间T=16A+16B+16C;本文提出的方法时间T2=A+16B+3C,因此,明显缩短了程序执行时间。
4 测试结果
在DSP-BF533测试平台上测试Claire.cif和Pairs.cif,从测试分析的结果看来:优化后的结果提高解码速率,达到实时应用要求。结果如表3所列。

5 结束语
针对移动视频终端应用,根据DSP的特点,提出一个新型的软件流水算法,使得模块问的协作更紧密,更好利用程序运行的空余时间,减少程序等待时间,提高解码速率。实验测试该程序已达到对CIF图像的实时解码要求,以后进一步优化,以达到更高更可靠的解码效率,使得基于DSP-BF533的设计完全可扩展到从无线3G网络、数字电视,到IP网络,媒体的存储格式等不同领域。
- 相关推荐
- 热点推荐
- H.264解码器
-
了解面向MS320DM365的H.264解码器缓冲机制2024-10-14 541
-
如何将imx8mm的h.264编解码器与FreeRTOS一起使用?2023-03-14 789
-
H.264解码器中CABAC硬件加速器怎么实现?2021-06-07 1910
-
怎么实现基于USB 2.0集成芯片的H.264解码器芯片设计?2021-06-04 1284
-
如何去实现并优化H.264解码器算法?2021-06-02 1836
-
下载Blackfin H.264解码器的免费生产版本以及示例和演示代码。2021-04-13 889
-
如何在Linux下实现H.264解码器的优化2021-02-25 1183
-
基于USB 2.0集成芯片的H.264解码器芯片设计2018-10-31 1308
-
omate网络视频编解码器H.2642016-12-23 1340
-
基于H.264的Exp-Golomb解码器ASIC设计2011-09-17 2346
-
H.264 PC解码库软件API参考2011-04-29 1252
-
H.264高清编解码器的片上系统MG35002010-12-25 1009
-
H.264 便携式实时编解码器的设计2009-12-28 701
全部0条评论

快来发表一下你的评论吧 !
