

 Graphcore发布最新IPU:世界首款采用台积电3D Wafer-on-Wafer的处理器
Graphcore发布最新IPU:世界首款采用台积电3D Wafer-on-Wafer的处理器
描述
电子发烧友网报道(文/李弯弯)3月3日,Graphcore发布最新一代IPU,性能比上一代提升40%,电源效率提升16%,这是全球首款基于台积电3D Wafer-on-Wafer的处理器。从上一代IPU到新的IPU,开发者无需修改代码,价格保持不变,现在已经上市。

世界首颗基于台积电3D Wafer-on-Wafer的处理器
Graphcore大中华区总裁兼全球首席营收官卢涛向媒体介绍,新一代IPU名叫Bow IPU,是一个3D封装的芯片,单个封装中有超过600亿个晶体管,具有350 TeraFLOPS的人工智能计算的性能,上一代MK2 IPU是250 TeraFLOPS。

Bow IPU在供电方面也做了很多优化,片内存储保持了0.9 GB的容量,但吞吐量从47.5TB/s提高到65TB/s。
处理器内核个数、独立线程个数等等,包括外部的一些接口,Bow IPU跟上一代处理器相比都没有变化。相比上一代,Bow IPU变化主要体现在它是一个3D封装的处理器,晶体管的规模有所增加,以及算力和吞吐量有所提升。
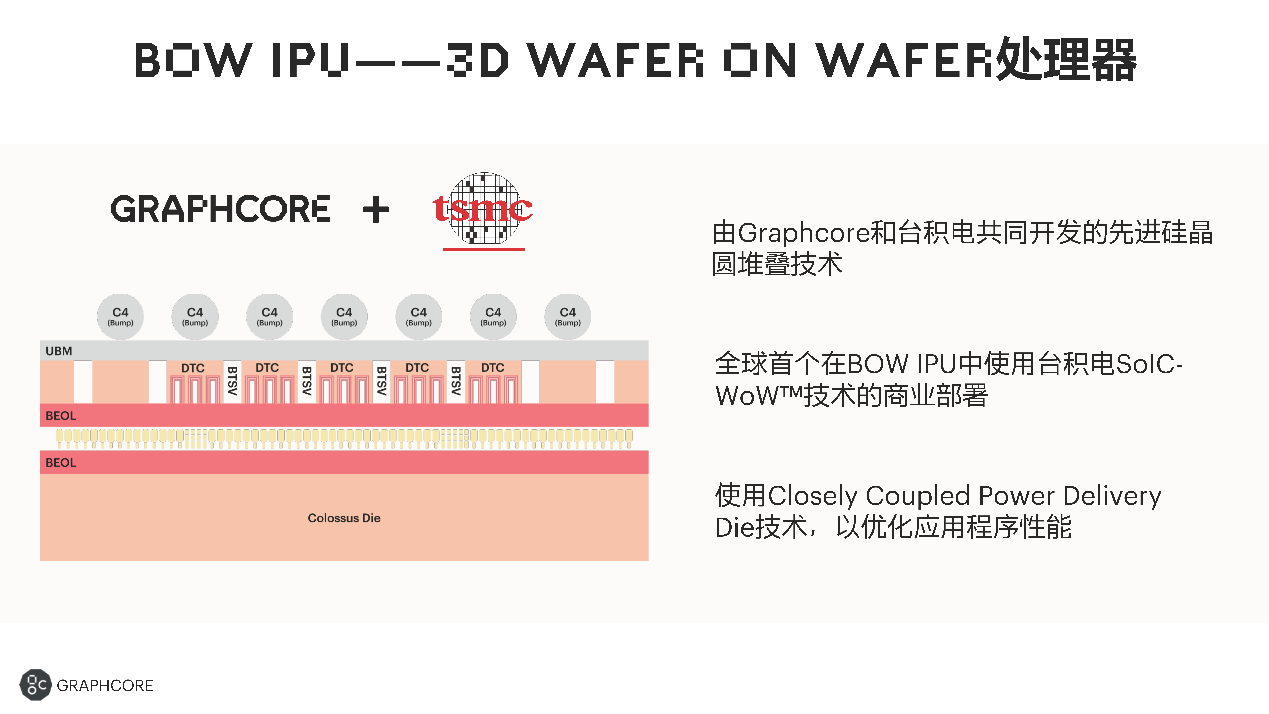
Bow IPU由2颗裸片叠在一起构成,使用了台积电的SoIC-WoW技术。一个IPU的裸片在下面,另一个裸片在上面。上面的裸片为供电、节能等功能提供帮助。
卢涛表示,跟之前的处理器相比,这个设计使得新产品在实际运算算力提高的情况下,能效方面也有所提升。
从某种意义来说,这是Graphcore跟台积电一起联合创新的结果。
基于Bow IPU的Bow系统性能大幅提升
除了Bow IPU,Graphcore同时发布了基于Bow IPU的Bow系统,包括Bow Pod16、Bow Pod32、Bow Pod64、Bow Pod256,以及Bow Pod1024。以Bow Pod16为例,Bow Pod16中包括4台1U的Bow-2000,还包括1台CPU服务器,能提供5.6 PetaFLOPS算力。

以Bow Pod16纵向扩展的Bow Pod32、Bow Pod64分别包括8台Bow-2000、16台Bow-2000。基于Bow Pod64可以再横向扩展到Bow Pod256、Bow Pod1024等。Bow Pod1024包括256台Bow-2000,可以提供358.4 PetaFLOPS的人工智能计算。目前,除了Bow Pod1024在早期访问阶段外,Bow Pod16、Bow Pod32、Bow Pod64、Bow Pod256均已量产。

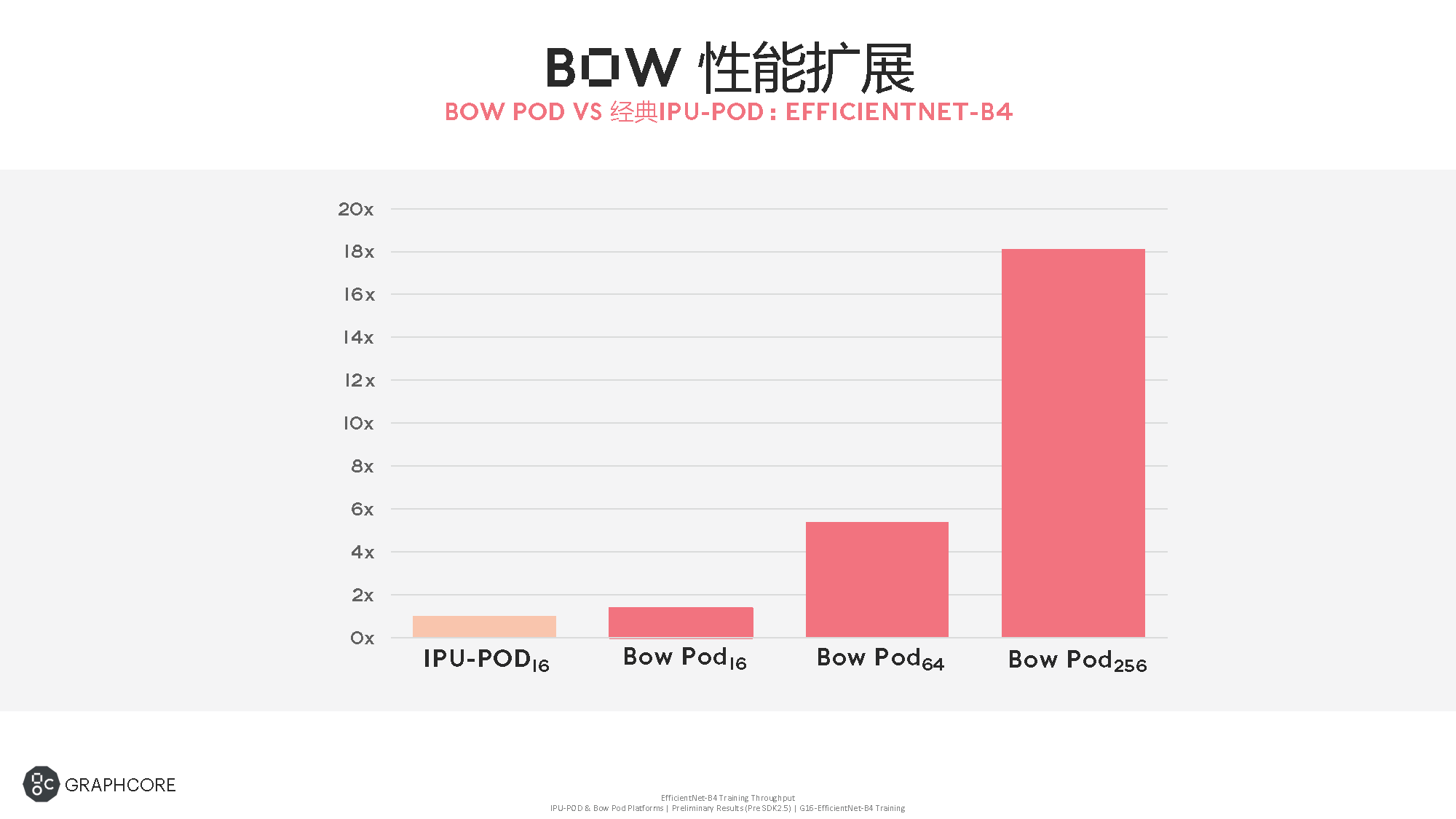
性能扩展方面,以IPU-POD16的性能作为基准,Bow Pod16的性能可以提升1.4倍,Bow Pod256可以提升18倍。
卢涛介绍,Bow-2000 IPU Machine使用了4颗Bow IPU。此前,在这样一个1U刀片里,Graphcore提供了1 PetaFLOPS的算力,现在Graphcore提供了1.4 PetaFLOPS的算力。Bow-2000具有3.6 GB处理器内存储,吞吐量为260TB/s,IPU流存储多达256 GB,IPU-Fabric为2.8 Tbps。
100%软件兼容,开箱即用无需更改代码

卢涛强调,新一代产品跟前一代产品百分之百软件兼容,基本上能做到开箱即用。用户得到性能提升的同时不需要修改代码,不仅是应用软件,包括底层软件、驱动等都不需要做任何修改,可以无缝集成到正在不断变得更加广泛的IPU软件合作伙伴生态中。
这一点特别关键。很多产品在从一代往另一代演进的时候,在实现性能提升的同时,还需要很多的软件适配工作。而100%的软件兼容,意味着已经使用Graphcore上一代IPU的用户在未来购置新的Bow IPU后,不需要做任何软件适配工作就能获得性能提升。
提供完整软件栈生态系统
Graphcore中国工程副总裁、AI算法科学家金琛对媒体表示,上述的这些性能提升,除了硬件新架构外,也要归功于Graphcore的软件栈和生态系统,其中的核心部分就是Poplar SDK。
金琛表示,Poplar SDK包括driver,上层XLA的backend,以及Graphcore自研的PopART等,这些软件的加持使得Graphcore能够实现在不同应用的性能上的广泛和通用的提升。
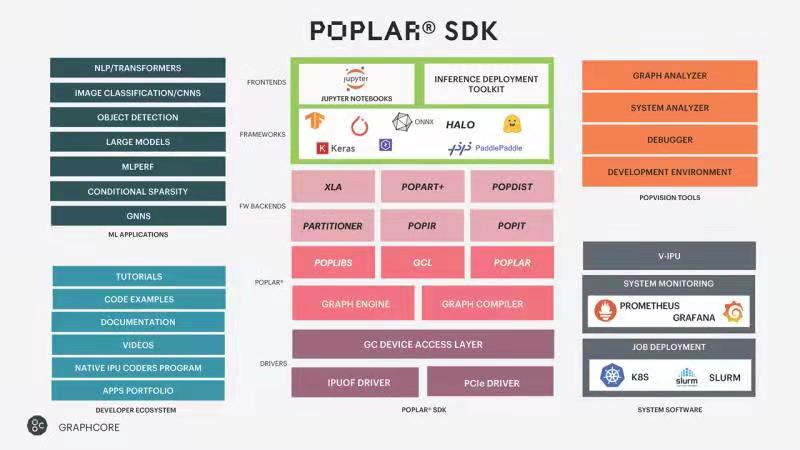
除此之外,Graphcore还提供比较丰富的生态。比如AI软件框架,支持PyTorch、TensorFlow、HALO、PaddlePaddle,以及Keras等。在用户方面,支持Jupyter NoteBook,以及Inference Deployment Toolkit等,帮助客户实现推算一体的部署。
在开发者社区方面,Graphcore提供广泛的代码用例,以及各种文档、视频的示范。Graphcore在机器学习应用上提供了特别多模型范例,覆盖了不同的AI垂直领域,如图像识别、物体检测,语音模型、语言模型等,这个模型库还在不停迭代和增加。
在云上,Graphcore也提供了广泛的部署。此外,Graphcore的PopVision工具可以帮助用户和Poplar编程者更有效地提升应用在Graphcore的平台上的性能优化。
提供10倍的总体拥有成本优势
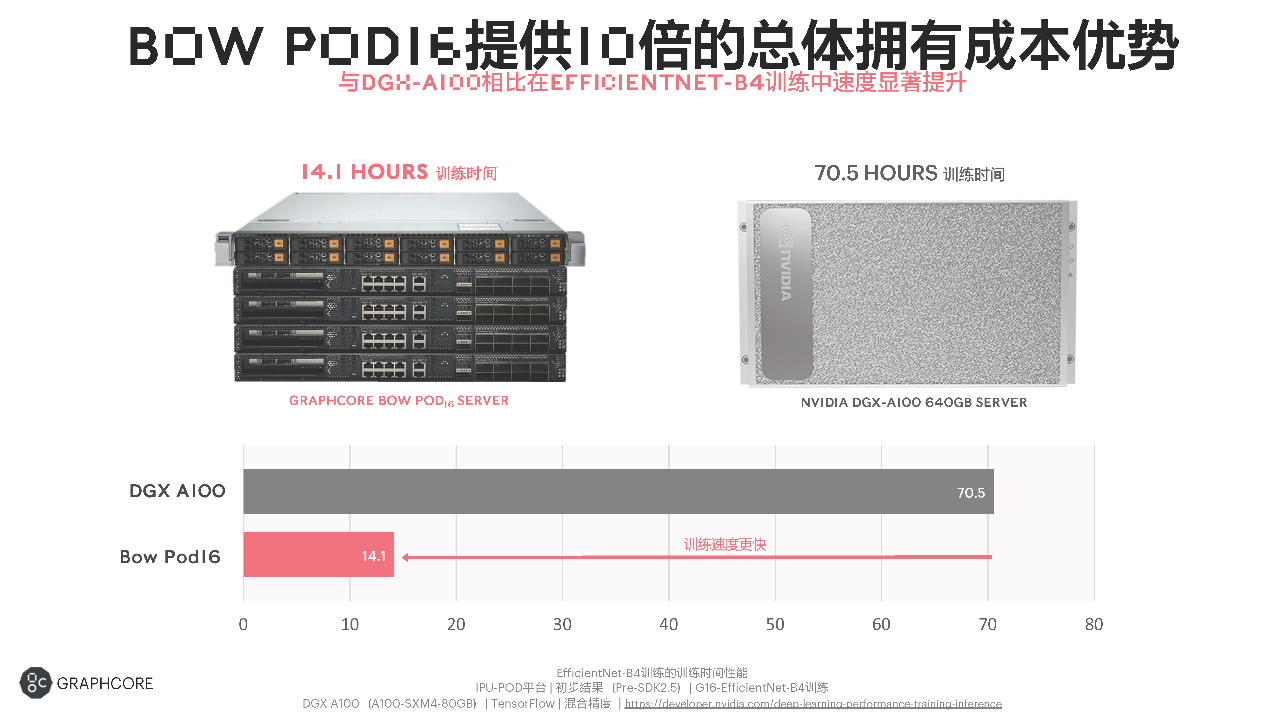
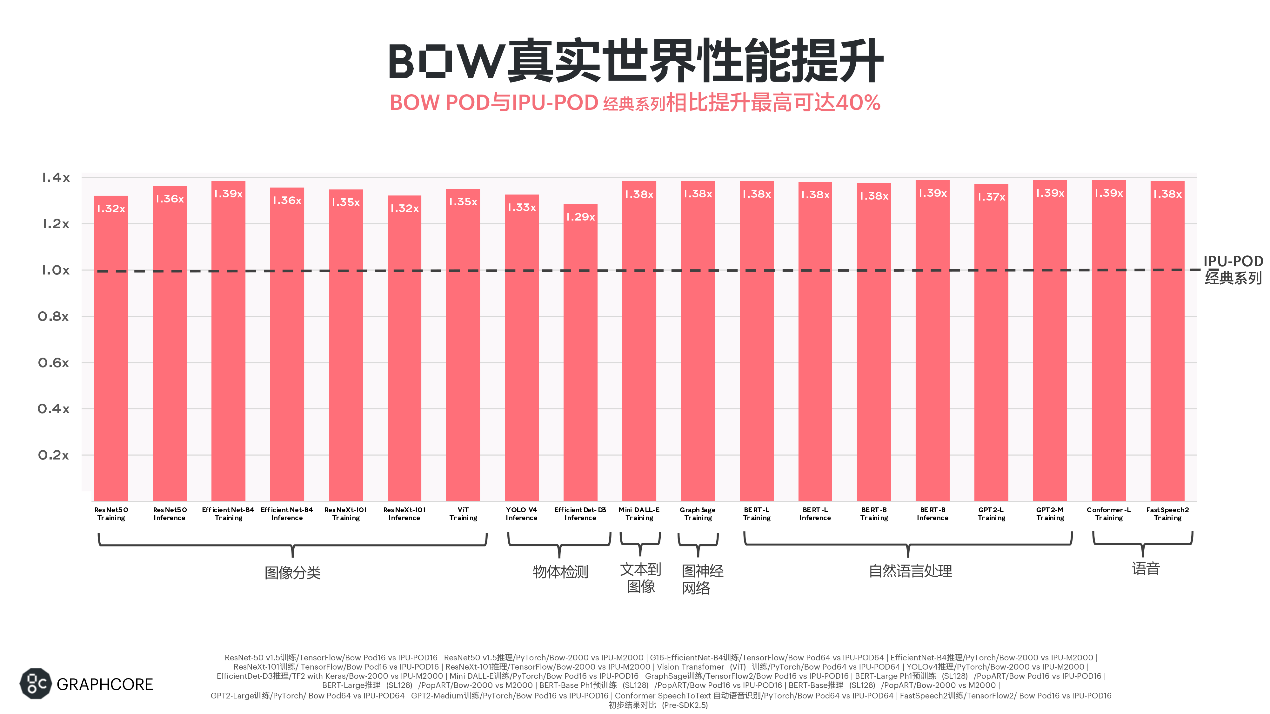
Graphcore不仅提供高效的性能,在性价比上也有比较显著的优势。比如,上图左边是Bow Pod的一个形态,右边是DGX-A100的一个形态。可以看到,在DGX-A100上需要70个小时的训练时间,在Bow Pod16上,EfficientNet-B4的backbone的训练只需要14个小时左右,基本快了5倍,性价比又有优势,总体拥有成本(TCO)的增益可以达到接近10倍左右。
Graphcore未来还要做什么?

人的大脑大概有860亿个神经元,100万亿个突触,这个突触相当于人工智能里面模型的参数个数。也就是说,最大的人工智能模型的参数跟真正的人的大脑比较起来,还有100倍左右的差距。
卢涛谈到,目前Graphcore正在开发一款可以用来超越人脑处理的超级智能机器——Good Computer,即古德计算机。这个命名有两层含义,一层是好的计算机,希望计算机能够带来正面的影响,另外也是向前辈致敬——Jack Good是一位非常知名的计算机科学家。

Good Computer大概能够达到8192个未来的IPU,提供超过10 Exa-Flops的AI算力,未来也许会继续向3D Wafer-on-Wafer演进,可以实现4 PB的存储,可以助力超过500万亿参数规模的人工智能模型的开发,Poplar SDK完全支持。
预计价格取决于不同的配置,大概在100万美元到1.5亿美元的规模。卢涛表示,从Bow IPU往前展望,这是Graphcore正在做的一个产品。
-
Alphawave推出业界首款支持台积电CoWoS封装的3nm UCIe IP2024-08-01 1659
-
5G手机全球出货量首次超过4G手机 台积电3D Fabric技术如何助力手机和HPC芯片2022-09-20 3208
-
Graphcore发布全新IPU产品Bow系列,令人WoW的40%性能提升2022-03-04 3127
-
台积电独吞iPhone处理器订单的秘密2021-01-07 3534
-
台积电开发SoIC新3D封装技术,中芯国际考虑跟随2020-12-30 3520
-
谷歌和AMD帮助台积电测试和验证3D堆栈封装技术,有望成为首批客户2020-11-23 2509
-
台积电和Graphcore准备合作研发3nm AI加速芯片2020-08-28 3067
-
arm与台积电共同发布业界首款CoWoS封装解决方案 提供更多优势2019-09-27 4331
-
晶圆对晶圆的3D IC技术2019-08-14 5402
-
台积电发布堆叠晶圆技术 目标是在5NM制造工艺上使用2018-05-05 4583
-
Xilinx与台积公司宣布全线量产采用CoWoSTM技术的28nm All Programmable 3D IC系列2013-10-22 1671
-
Wafer test system2012-05-05 7783
-
世界首款 BeSang 3D芯片诞生2008-08-18 5391
全部0条评论

快来发表一下你的评论吧 !
