

网络通讯中随机数不随机引发的问题及解决方法
描述
1 写在前言
最近在排查一个项目的性能压测问题,十分偶然地发现一个莫名偶现的网络掉线问题,最后排查发现居然跟系统的随机数特性有莫大的关系。
由于我们现在的应用场景都是基于Wi-Fi的网络连接,所以本文会结合这个偶现的网络掉线问题,重点分析下在网络通讯中,如果随机数不随机会引发什么问题,以及如何去排查和解决这些问题。
通过本文的阅读,你将可以了解到:
-
在网络通讯中,如果随机数不随机会引发什么问题?
-
MQTT中的keepalive参数有何作用?
-
TCP三次握手和四次挥手的过程是怎么样的?
-
lwip协议栈的实现中是如何使用随机数的?
-
嵌入式Wi-Fi设备如何抓取通讯报文?
-
如何“重载”标准C库的rand函数?
2 问题描述
我们先来看下当时测试提的issue是怎么说的。
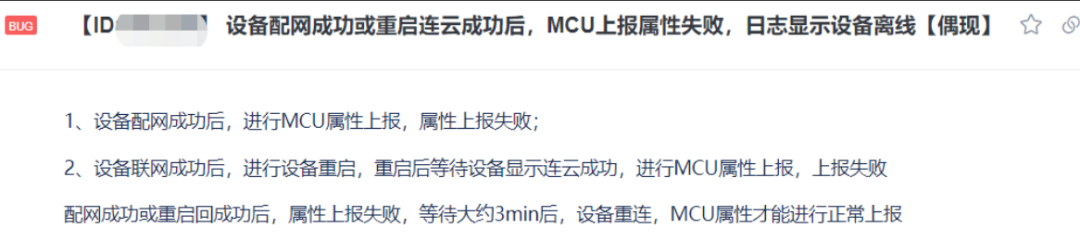
当我第一时间看到这个问题的时候,就想起来,其实我们的版本还在内测阶段的时候,就已经发现了类似的问题,只不过这个问题复现概率相对较低,当时还一度怀疑是偶然的热点掉线啥的,所以就不了了之了。当时内测的issue记录如下:

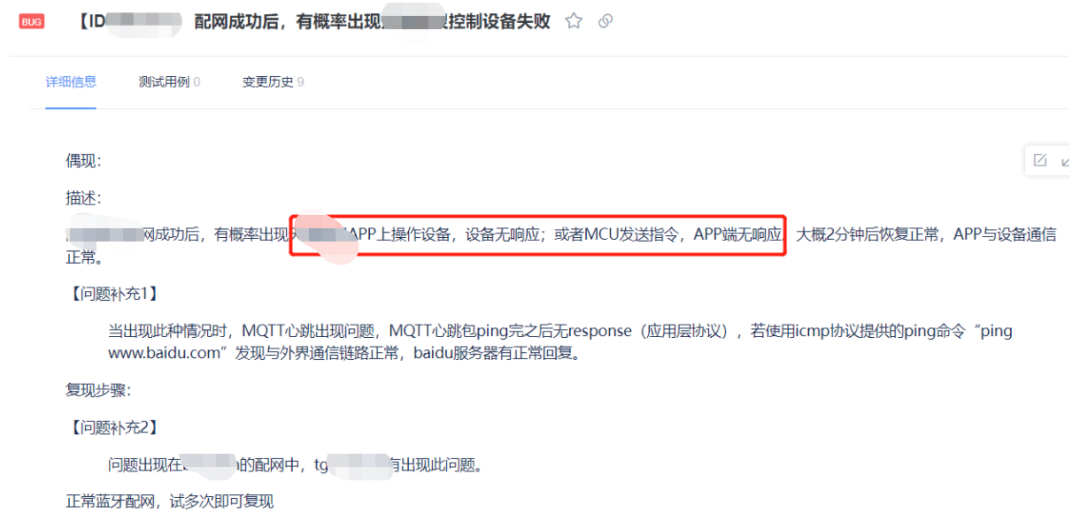
其中,仔细分析我们内测阶段提的issue是可以看出问题的,至少我们可以知道:
-
出现问题时,无论云端到终端,还是终端到云端,通讯数据都是不畅通的,这一点可以基本判定设备是掉线的;
-
出现问题时,排除是网络中断的情况;毕竟ping外网是通的;
-
issue中都提到了中断2-3分钟(感官时间,不是精准计时,精准应该是3分钟)后,触发重连机制,重连成功后,问题解除了;
-
该问题的触发时间节点,一定是某次重启之后的第一次网络通讯;
-
跟具体的云平台无关,但与具体的模组型号强相关。
以上就是这些是通过观看设备的log以及结合一些简单的测试方法就可以得出的基本结论,但是并不能准确得出结论,为何在这个节点下设备会掉线,或者说,为何在成功配网后,发起ping包才会发现掉线,前面的配网不是交互得好好的吗?掉线究竟是设备端主动掉的还是云端关闭连接的?最重要的是,这种情况能不能规避或者妥善解决?
带着这些疑问,我们需要做更进一步的实验和分析。
3 场景再现
3.1 复现环境搭建
大部分软件问题难解决主要有两个方面,一个是难复现或者说找不到稳定复现的路劲,还有一种就是你能找到稳定复现的路劲,但是这个bug解决不了,或者说你解决不了,要么它有外部依赖,要么它就是个已知bug,你就是解决不了。
说句不好听的:写软件的,谁还没几个解决不了的bug?
但是,说是这样说,至少你需要去尝试复现,指不定能找到复现的路径呢;只有当你的确找到了复现路径,且使用了各种手段尝试去解决也没法解决,哪怕找原厂协助也依然无能为力,我们才能把问题归为第二类。
根据issue提供的信息,快速搭建复现环境,尝试复现。注意,我们在issue的附件log中很清晰地看到出问题的节点下,MQTT的ping包丢了,所以在搭建复现环境的时候,我们尝试了修改MQTT ping包的发送周期。我们提测的版本用的是典型值60S,所以复测中我们同步修改2个版本,分别是30S和120S。
好巧不巧,120S的版本,按照正常的配网流程操作个没几次,一下子就复现了。这让我们有点惊呆,不知是运气好,还是真的这个复现概率就是这么高!!!
3.2 复现问题的说明
既然问题很快复现了,我们应该正视问题的排查和分析思路。从复现问题点开始,尝试ping网关,尝试ping外网,发现都是通的,难道真的只是一次偶发的网络掉线?
为何会有这样的问号,那是因为办公室的Wi-Fi网络环境的确比较差,无线通讯干扰很大,不排除偶然有这种掉线的可能性。
面对这个复现问题,我们还想到了抓空口包,试着分析当前状态的空口数据的情况,顺带观测下当前无线网络的通畅情况。
我们也做好了另一份方案,抓网络包,也就是TCP/IP包;抓这个包的作用主要是观测问题节点下网络报文的传输情况,曾经在第一时间看到这个issue的时候,还有一个怀疑点就是通讯链路断了,到底断没断,TCP/IP包大概就能看出来。
以下就是基于复现的问题节点做出的初步排查和分析方案,具体的操作还得看下文后续的分析、解决及验证。
4 问题分析
作为一个嵌入式软件工程师,我个人认为,当出现问题,首先应该排除硬件的问题,也就是说,先假设设备硬件完好的情况下去分析软件问题;只有当你把所有的软件可能性排除得差不多了,或者你在排除的过程中,找到了充分的证据证明硬件问题的可能性非常大,那么这个时候你就可以去找硬件工程师battle battle了。
其次,排查软件问题,无非两个方向,要不从大到小,要么从小到大。从大到小指的是先从宏观的软件架构层面去思考和分析,层层剥离,循序渐进,直到分析可能出现的更小范围,各个排查突破;从小到大指的是从微观的末端错误log开始分析,一步步反推导致这个错误的出现的可能性,层层剥离,结合上下文信息深入分析,直至找到问题的根源。
4.1 从大到小:理解软件架构
上面也提到了,从小到大的排查方式是从代码架构层面去分析;为了聚焦在网络这一块,我把原本比较复杂的架构精简了一下,仅保留与网络通讯相关的内容,大致如下图所示:
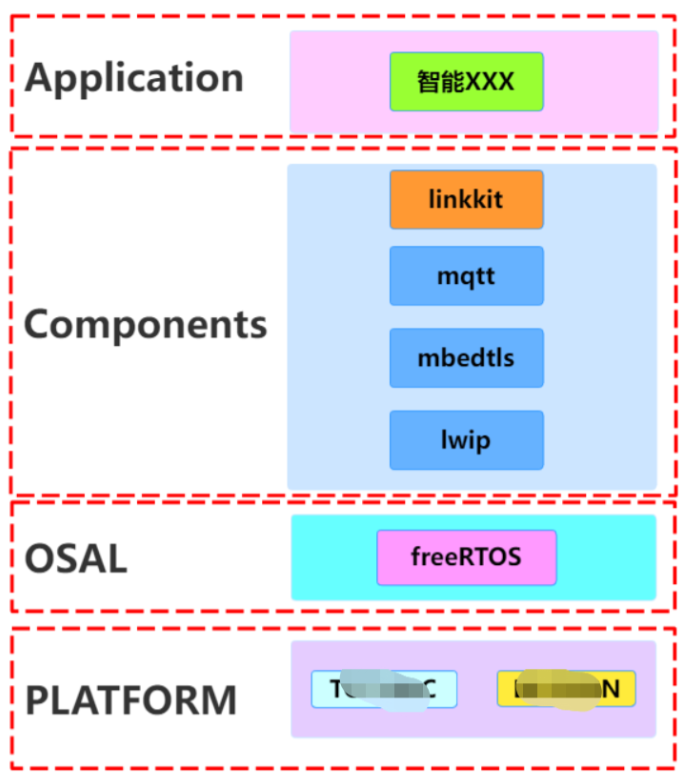
从第2章节的issue描述以及第3章节自己的复测,我们可以知道出现问题是在MQTT这个组件中爆发了问题,且在芯片PLATFORM中只有XXX上面才会出现,于是我们可以大胆地假设一个观点:问题很有可能出现在mbedtls组件或lwip组件!
同时,由于我们在做架构图的时候,更多的是在逻辑层面,所以在代码架构图中,并没有很好地对lwip的物理存在做准确的描述。理论上说,物理架构必须是服从于逻辑架构,但在实操过程中,我们在这一原则上的确偷了一下懒,原因就是YYY和XXX都已经移植好了现成的lwip组件,关键是他们适配的版本不一样,所以我们并没有统一lwip组件,而实际执行的软件架构图是下面这张图:
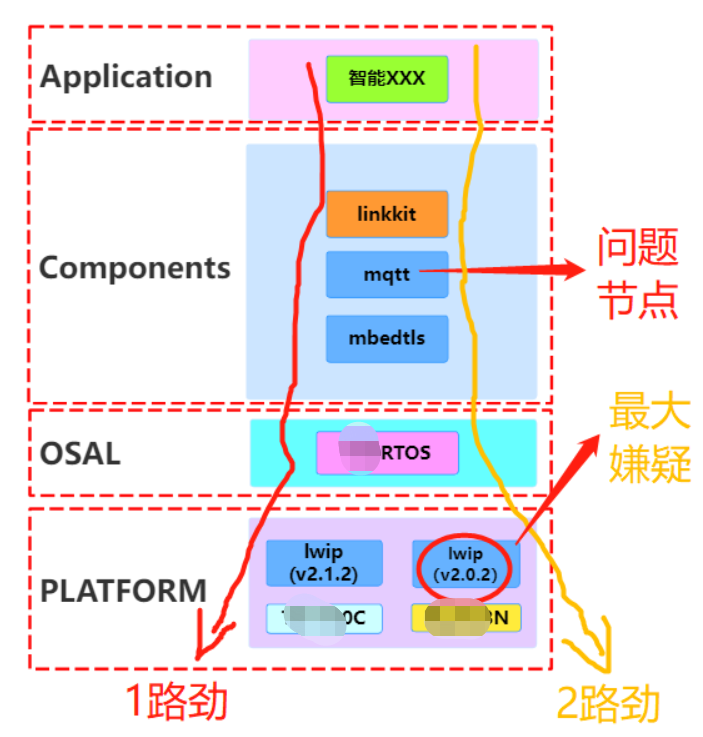
配合这个物理架构图,1路劲没有问题,而2路劲却出问题了,基本可以推断出是lwip组件的问题。
4.2 从小到大:抛开现象看本质
从复现的问题现场的末端,最直观的就是mqtt send ping发出去了,但是没有mqtt recv pingrsp。
单从这个现象,我们需要寻找的本质是:
MQTT模块是否工作不正常了?MQTT掉线了?MQTT自己断开掉线还是broker断开导致的掉线?
如果MQTT工作不正常,那么TCP层工作是否正常?毕竟MQTT是基于TCP层,在其之上。
另外,4.1复现问题中,对MQTT的keepalive参数做了调整,是否这个参数有着致命的影响?
MQTT规范中对keepalive是如何描述的?
一个简单的现象,要看清其本质并不容易,需要下面大量的辅助分析过程。
就像这样:
MQTT掉线 --》PINGREQ包发出去了吗?--》PINGRESP包收到了吗?--》TCP链接什么情况?--》空口通讯是否正常?
4.3 要放大招:三板斧出击
从上面的都仅仅是初步的假设分析,还没法找到真正的证据;再要深入细节,底层的log以及网络报文肯定少不了。
4.3.1 第一板斧:MQTT log
我们使用的是pahu的C语言版本的MQTT,通过浏览器代码实现,我们可以知道其MQTT层的log开关位于:
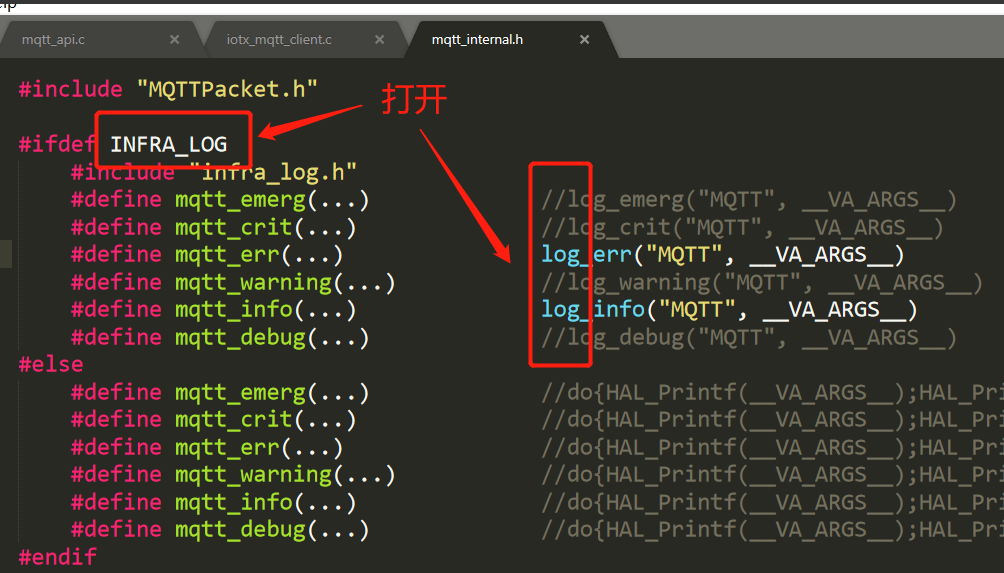
打开这里的开关,我们就可以看到更多细致的MQTT log,包括MQTT基础报文的收发都可以看到。这个就可以相对清晰地知道,在发生MQTT掉线(ping lost)的时候,究竟有没有收到ping resp?
有一种情况是的确没有收到,这种肯定是lost;还有一种是,可能收到了,但是在MQTT层解析、拆包、校验的时候发现是一个非法包,然后直接丢弃了,不能丢到上层去处理。通常来说,第二种情况比较少见。
还有一点,我们使用的MQTT实现包中对MQTT收到的报文,全部都是在mqtt_yield(Client, timeout_ms)查询式接收,当收到一个有效的MQTT报文,会有类似下面一段的处理代码:
// check recv MQTT packet type
switch (packetType) {
case CONNACK: {
mqtt_debug("CONNACK");
break;
}
#if !WITH_MQTT_ONLY_QOS0
case PUBACK: {
mqtt_debug("PUBACK");
rc = iotx_mc_handle_recv_PUBACK(c);
if (SUCCESS_RETURN != rc) {
mqtt_err("recvPubackProc error,result = %d", rc);
}
break;
}
#endif
case SUBACK: {
mqtt_debug("SUBACK");
rc = iotx_mc_handle_recv_SUBACK(c);
if (SUCCESS_RETURN != rc) {
mqtt_err("recvSubAckProc error,result = %d", rc);
}
break;
}
case PUBLISH: {
mqtt_debug("PUBLISH");
/* HEXDUMP_DEBUG(c->buf_read, 32); */
rc = iotx_mc_handle_recv_PUBLISH(c);
if (SUCCESS_RETURN != rc) {
mqtt_err("recvPublishProc error,result = %d", rc);
}
break;
}
case UNSUBACK: {
mqtt_debug("UNSUBACK");
rc = iotx_mc_handle_recv_UNSUBACK(c);
if (SUCCESS_RETURN != rc) {
mqtt_err("recvUnsubAckProc error,result = %d", rc);
}
break;
}
case PINGRESP: {
rc = SUCCESS_RETURN;
mqtt_info("receive ping response!");
break;
}
default:
mqtt_err("INVALID TYPE");
_reset_recv_buffer(c);
HAL_MutexUnlock(c->lock_read_buf);
return FAIL_RETURN;
}
倘若正常收到ping回复的,一定会有"receive ping response!"的log输出,这也是断定MQTT是否掉线的一个简单判断。
4.3.2 第三板斧:TCP/IP抓包
由于我们使用的是Wi-Fi网络通讯,所以要想抓取模组的TCP/IP报文,通常有以下几种方法:
-
方法1:在无线路由器中抓取流过路由器的报文,这种方法对路由器有要求,实践中,我们并没有采取这种方法,感兴趣可以去了解下。
-
方法2:利用中间人原理来抓包,以前我就曾经使用过这个方法抓一些蜂窝网络的网络报文,效果还是不错的,只不过代码层面需要稍作点服务器的地址、端口修改,它的原理如下图所示。它有个弊端,就是需要一个具备抓包环境的公网服务器;同时在公网PC端需要一个代理软件,这里推荐使用一个叫sockit的开源软件,感兴趣可以了解下。

-
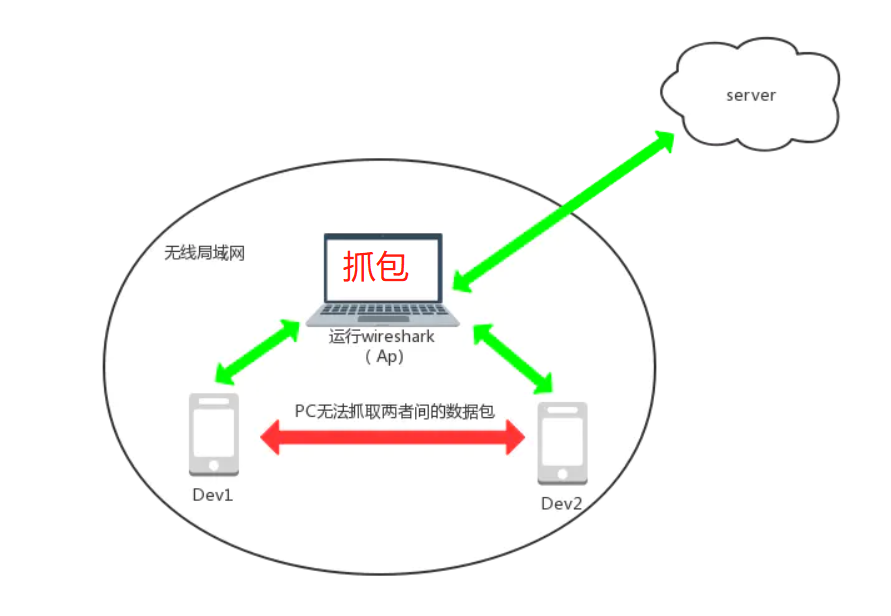
方法3:利用无线热点的功能特性来抓包,它的原理如下图所示,大家一看便懂,其实就是PC电脑使用无线网卡或类似360Wi-Fi这种,开启一个无线AP热点,让设备连接这个无线热点,从而达到探测网络报文的目的。不过,它也是多少有些缺陷,感兴趣可以了解下,但是基本应付我们这种抓包场景肯定是没有问题的。
经综合考虑,我们采用的是方法3来抓包,配合前面提及的复现方法,很快就抓到了对应的TCP报文(感兴趣的可以去[这里]()取报文)。
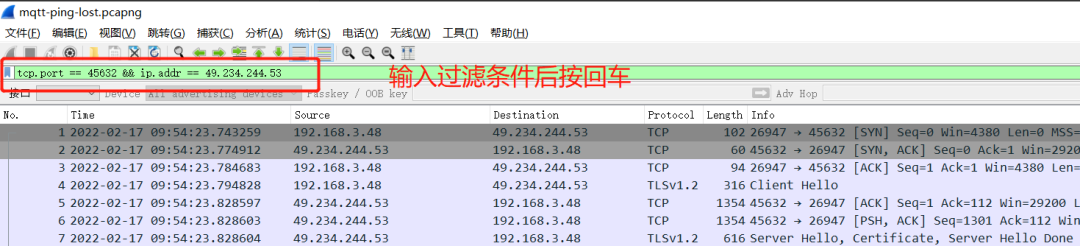
通过这种方式抓包会把PC上所有的网络报文中抓包,为了精准展示设备的报文,我们需要对所抓的报文进行过滤,使用的过滤指令是 “tcp.port=xxx && ip.addr=yyy.yyy.yyy.yyy“,其中xxx表示设备端链接服务器端的端口号,yyy.yyy.yyy.yyy是服务器主机的IP地址;如果服务器是域名的形式的话,先在PC上使用ping命令把域名解析成IP。
wireshark中对报文的过滤操作,如下图所示:
通过wireshark简单一看,找到对应ping lost的时间节点,MQTT的ping包看似压根就没发出去,因为ping包在TCP层一直是重传的,压根得不到服务器的ACK。
如下所示:
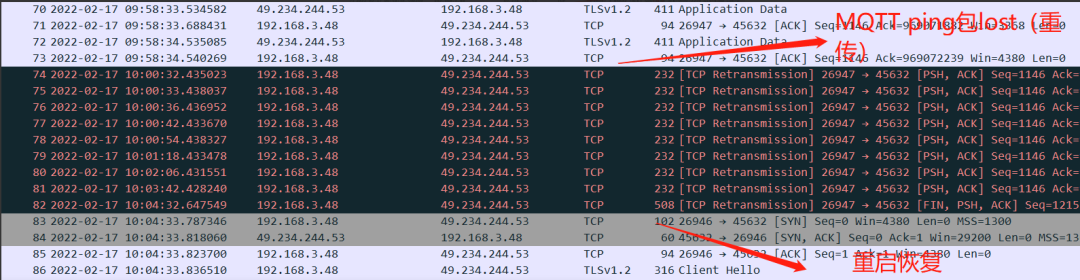
4.3.3 第二板斧:空口抓包
空口抓包,我们使用的是omnipeek软件,这也是业内常规使用的空口抓包工具。
关于如何搭建omnipeek的抓包环境,我这里不再赘述,感兴趣的可以科学上网,找一些参考教程,一学便会。
它的抓包界面长这样:
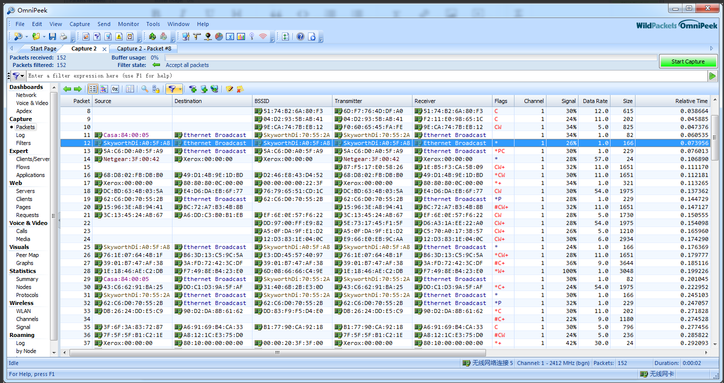
具体解析的数据帧解析界面长这样:
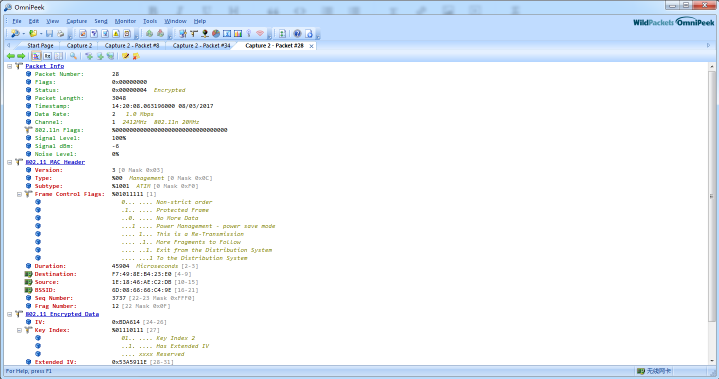
如不习惯使用它来看报文,倒是可以导出其网络包,使用wireshark来看网络报文,也是一种常见的分析手段。
有了omnipeek的抓包环境,配合前面的复现方法,我们发现当问题出现时,omnipeek是能抓到一些TCP报文流过的,这至少能说明,在问题节点下空口通讯是正常的,需要再往上层协议去排查。
4.3.4 分析小结
看这里好像是三板斧分三个阶段走,在实操过程中,其实三板斧是同时进行的,这也是为了能够在问题节点下分析出更多的线索和可能性。三者是相辅相成的,都联系在一起。
4.4 关键转机:找到突破口
谁来也巧,在上面抓TCP包分析的时候,我们可以看到MQTT ping包变成了Application Data,为什么?
原因在于我们在MQTT层上加了TLS,实际上跑的MQTTS;我们的实现是:MQTT+mbedtls。
我当时有个想法就是,能不能把MQTTS中的密文解开来,看着也舒服些,遇到开始查找资料,找到了这篇参考教程,是RT-Thread输出的教程:基于RT-Thread 使用 wireshark 抓取 HTTPS 数据包。
它的思路很新颖也很聪明,实现原理图长这样:
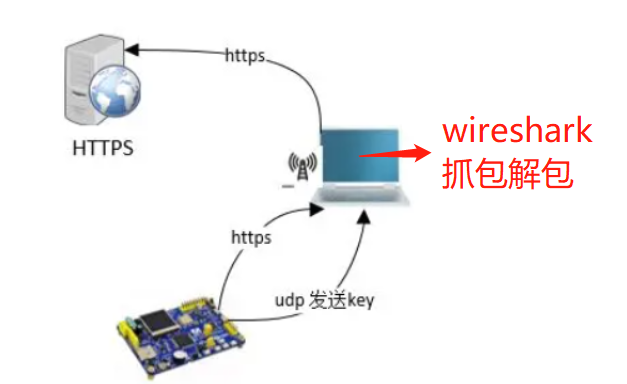
使用这个方案, 电脑创建 一个Wi-Fi 热点,设备端连接电脑热点,并发起 https 请求(TLS),服务器接收到请求,向设备端发出响应,设备端根据响应的内容,计算出密钥, 并将设备端随机数和密钥通过 udp 发送到 pc,保存到 sslkey.log 文件,wireshark 根据设备端随机数和密钥即可将TLS 数据包解密。
其核心逻辑就是让处于抓包状态的wireshark拿到设备与服务器端最终协商的那个数据加密的key,从而把密文的数据还原成明文。
参考教程,我很快就把相应的流程跑起来了,但是遗憾的是wireshark并没能成功地帮我解开密文数据。
不过也不是完全一无所获,因为我发现了一个致命的问题在里面,这个致命问题倒是给我提供了一个新思路,真是塞翁失马焉知非福!
在以前的金融POS机器安全研发的工作经历中,我曾经花很大的力气专门研究过TLS握手相关的握手以及数据的加解密流程,所以对上述教程中提及的TLS相关的讲解,也是理解得比较透彻。
但我发现其中的致命问题是,我从设备截获的CLIENT RANDOM字段保存在sslkey.log中,居然每次开机都是一模一样的:
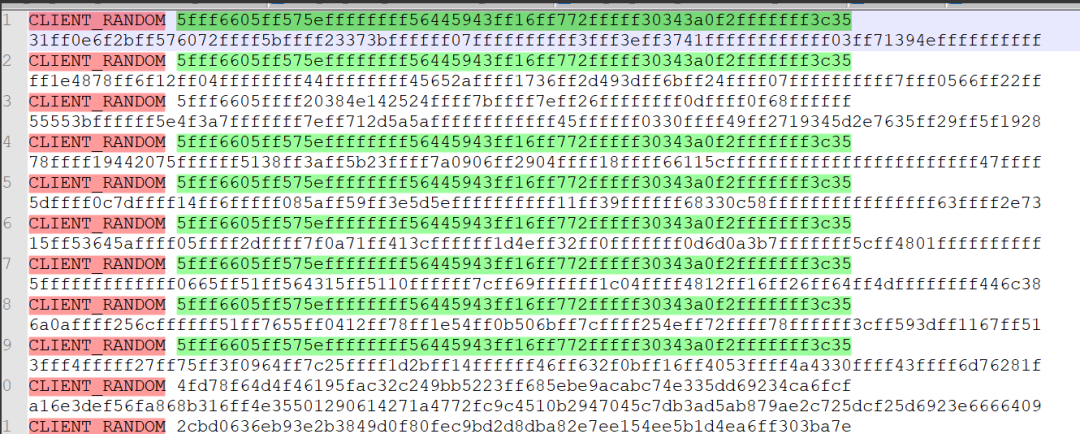
这肯定不行啊!要知道这可是TLS握手中客户端的随机数啊?怎么能每次都一样呢?岂不是会被人重放攻击?
这种情况下,要么是mbedtls库实现有问题,要不就是随机数有问题?
既然mbedtls别人用了那么多,而且我们其他芯片平台也用啊,也没遇到这种问题,所以随机数的可能就非常大了!
也确认了下mbedtls中使用随机数的最终调用接口:
static unsigned int _avRandom()
{
return (((unsigned int)rand() << 16) + rand());
}
static int _ssl_random(void *p_rng, unsigned char *output, size_t output_len)
{
uint32_t rnglen = output_len;
uint8_t rngoffset = 0;
while (rnglen > 0) {
*(output + rngoffset) = (unsigned char)_avRandom();
rngoffset++;
rnglen--;
}
return 0;
}
// mbedtls connection init
{
// ...
mbedtls_ssl_conf_rng(&(pTlsData->conf), _ssl_random, NULL);
// ...
}
WC !居然是标准C库的rand函数!这!!!
直到这里,我才正儿八经地往随机数的方向去怀疑了,最后的实践证明,这个思路恰好对了。
随机数这个思路一打开之后,我突然想起大概2个月前帮Wi-Fi组的同事排查过一个lwip随机数引发的问题,但是脑子里有些模糊,只记得好像会引发断线啥的。
果然找到对口的同事(还在隔离中),语音确认了一波,果然问题的现象我们这无比的相应,要知道他当时调的芯片平台和SDK都不是我现在用的这套,这就足以证明,这个问题是首次在我们的SDK和芯片平台上爆发,而且这个问题估计原厂还未同步发现。
4.5 知识点补缺
上面的思路,已经将疑点对准随机数了,但是为了能准确分析解决问题,我们需要将相关的理论知识恶补以下。
4.5.1 MQTT的心跳机制
这种纯理论知识,我想没有什么比MQTT的协议规范更有说服力,于是我查找了MQTT-V3.1.1的规范文档,找到了相关说明:
-
keepalive参数


-
PINGREQ报文和PINGRESP报文


简单总结下:
当客户端启动了keepalive特性之后,客户端至少应在keepalive间隔内发起一条PINGREQ,如果服务端在一点五倍的保持连接时间内没有收到客户端的控制报文,它必须断开客户端的网络连接,认为网络连接已断开。反之,如果服务器收到了PINGREQ,就必须响应PINGRESP以表示自己还活着。
4.5.2 lwip协议栈
lwip是一个非常轻量级的TCP/IP协议栈的C版本实现,它在有无操作系统的支持都可以运行。LwIP实现的重点是在保持TCP协议主要功能的基础上减少对RAM 的占用,它只需十几KB的RAM和40K左右的ROM就可以运行,这使LwIP协议栈适合在低端的嵌入式系统中使用。更多简要介绍,可以参考(百度百科)[https://baike.baidu.com/item/LwIP/10694326].
对于lwip的使用,我们已经很熟悉了,因为它兼容原生的BSD socket,很容易就可以基于socket API把网络程序给跑起来。同时,原厂已经帮忙把lwip在指定的RTOS系统(本案例是freeRTOS)中,但我们应该好好学一学lwip移植相关的内容,可以参考下这里。
我这里重点提及下它使用随机数的地方,关于它的初始化流程可以参见这里。
在它的初始化流程中,需要执行到一个tcp_init的函数,位于tcp.c中:
//init.c
void
lwip_init(void)
{
#ifndef LWIP_SKIP_CONST_CHECK
int a;
LWIP_UNUSED_ARG(a);
LWIP_ASSERT("LWIP_CONST_CAST not implemented correctly. Check your lwIP port.", LWIP_CONST_CAST(void*, &a) == &a);
#endif
#ifndef LWIP_SKIP_PACKING_CHECK
LWIP_ASSERT("Struct packing not implemented correctly. Check your lwIP port.", sizeof(struct packed_struct_test) == PACKED_STRUCT_TEST_EXPECTED_SIZE);
#endif
/* Modules initialization */
stats_init();
#if !NO_SYS
sys_init();
#endif /* !NO_SYS */
mem_init();
memp_init();
pbuf_init();
netif_init();
#if LWIP_IPV4
ip_init();
#if LWIP_ARP
etharp_init();
#endif /* LWIP_ARP */
#endif /* LWIP_IPV4 */
#if LWIP_RAW
raw_init();
#endif /* LWIP_RAW */
#if LWIP_UDP
udp_init();
#endif /* LWIP_UDP */
#if LWIP_TCP
tcp_init();
#endif /* LWIP_TCP */
#if LWIP_IGMP
igmp_init();
#endif /* LWIP_IGMP */
#if LWIP_DNS
dns_init();
#endif /* LWIP_DNS */
#if PPP_SUPPORT
ppp_init();
#endif
#if LWIP_TIMERS
sys_timeouts_init();
#endif /* LWIP_TIMERS */
}
//tcp.c
/**
* Initialize this module.
*/
void
tcp_init(void)
{
#if LWIP_RANDOMIZE_INITIAL_LOCAL_PORTS && defined(LWIP_RAND)
tcp_port = TCP_ENSURE_LOCAL_PORT_RANGE(LWIP_RAND()); //关键操作:初始化的时候随机取得tcp_port
os_printf("tcp_port:%d
", tcp_port);
#endif /* LWIP_RANDOMIZE_INITIAL_LOCAL_PORTS && defined(LWIP_RAND) */
}
OK,我们这里看到它使用了一个LWIP_RAND操作,而原厂适配lwip的时候并没有把这个LWIP_RAND切换到硬件的RAND,而是用了标准C库的rand函数,前面已经有迹象表明,它就不是随机的,这里还用?
tcp_init无非是取得一个tcp_port的基准偏移,后面在创建客户端的时候,对服务器发起TCP链接,本地的端口号就是根据这个tcp_port来计算出来的,代码如下:
//tcp.c
/**
* Allocate a new local TCP port.
*
* @return a new (free) local TCP port number
*/
static u16_t
tcp_new_port(void)
{
u8_t i;
u16_t n = 0;
struct tcp_pcb *pcb;
again:
//关键操作:tcp_port+1获得新的端口号
if (tcp_port++ == TCP_LOCAL_PORT_RANGE_END) {
tcp_port = TCP_LOCAL_PORT_RANGE_START;
}
/* Check all PCB lists. */
for (i = 0; i < NUM_TCP_PCB_LISTS; i++) {
for (pcb = *tcp_pcb_lists[i]; pcb != NULL; pcb = pcb->next) {
if (pcb->local_port == tcp_port) {
if (++n > (TCP_LOCAL_PORT_RANGE_END - TCP_LOCAL_PORT_RANGE_START)) {
return 0;
}
goto again;
}
}
}
return tcp_port;
}
所以,到这基本就解释了,重启后的那次TCP链接为何使用了前一次TCP链接的端口号,因为tcp_port两次(很有可能)是一样的。
4.5.3 TCP的状态图
要熟练地分析上面的各个场景,务必需要对TCP的各个状态非常了解。从网上找了一张关于TCP状态介绍稍全的图,供大家参考下:
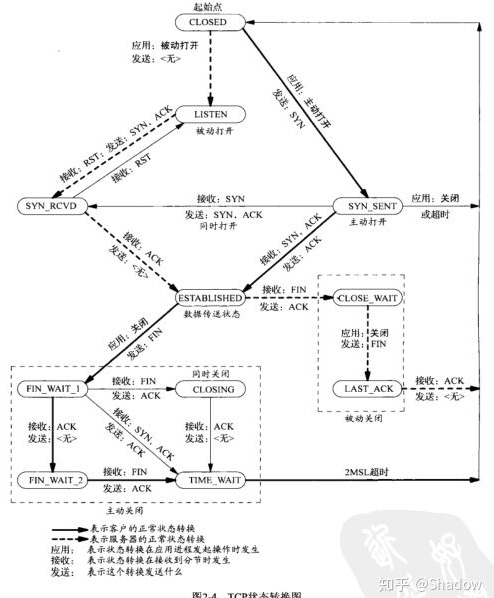
关于TCP的状态切换图,我也还在学习,期间我找大神(小林coding)讨论过这个有趣的问题,原来他之前写过这个场景的分析,那我就直接搬过来了,感兴趣的可以一看。
他的核心观点就是:
处于 establish 状态的服务端如果收到了客户端的 SYN 报文(注意此时的 SYN 报文其实是乱序的,因为 SYN 报文的初始化序列号其实是一个随机数),会回复一个携带了正确序列号和确认号的 ACK 报文,这个 ACK 被称之为 Challenge ACK。接着,客户端收到这个 Challenge ACK,发现序列号并不是自己期望收到的,于是就会回 RST 报文,服务端收到后,就会释放掉该连接。
结合我们抓的TCP报文,这不就是刚好验证了我们的复现场景吗?
4.5.4 TCP报文的标志位
TCP的报文中规定有6种重要的标志位:
-
URG:(Urgent Pointer field significant)紧急指针。用到的时候值为1,用来处理避免TCP数据流中断。【这个标志位很少见】
-
ACK:(Acknowledgment fieldsignificant)置1时表示确认号(AcknowledgmentNumber)为合法,为0的时候表示数据段不包含确认信息,确认号被忽略。
-
PSH:(Push Function),PUSH标志的数据,置1时请求的数据段在接收方得到后就可直接送到应用程序,而不必等到缓冲区满时才传送。
-
RST:(Reset the connection)用于复位因某种原因引起出现的错误连接,也用来拒绝非法数据和请求。如果接收到RST位时候,通常发生了某些错误。
-
SYN:(Synchronize sequence numbers)用来建立连接,在连接请求中,SYN=1,ACK=0,连接响应时,SYN=1,ACK=1。即,SYN和ACK来区分Connection Request和Connection Accepted。
-
FIN:(No more data from sender)用来释放连接,表明发送方已经没有数据发送了。
熟悉这几个标志位的基础含义,基本上就可以看懂一段TCP网络报文了。
4.6 深入分析:从理论分析到实战分析
有了上面的知识点补充,我们尝试着深入分析,看看把这些知识点结合实际的案例场景串起来?
4.6.1 理论分析:理论上的复现路径
从lwip的初始化分析,我们可以知道在设备重开机后,设备发起的第一笔TCP链接使用的端口是跟其初始化的tcp_port有直接的关系(tcp_port + 1);而我们的Wi-Fi设备都是连接的无线路由热点的,所以设备重启后,很大可能也是取到同一个子网IP。这样的话,重启前后的两次TCP链接使用的四元组就是完全相同的:(客户端端口号、客户端本地IP、服务端端口号、服务器IP)。
会发生什么事情,我直接用小林的一张图来说明:
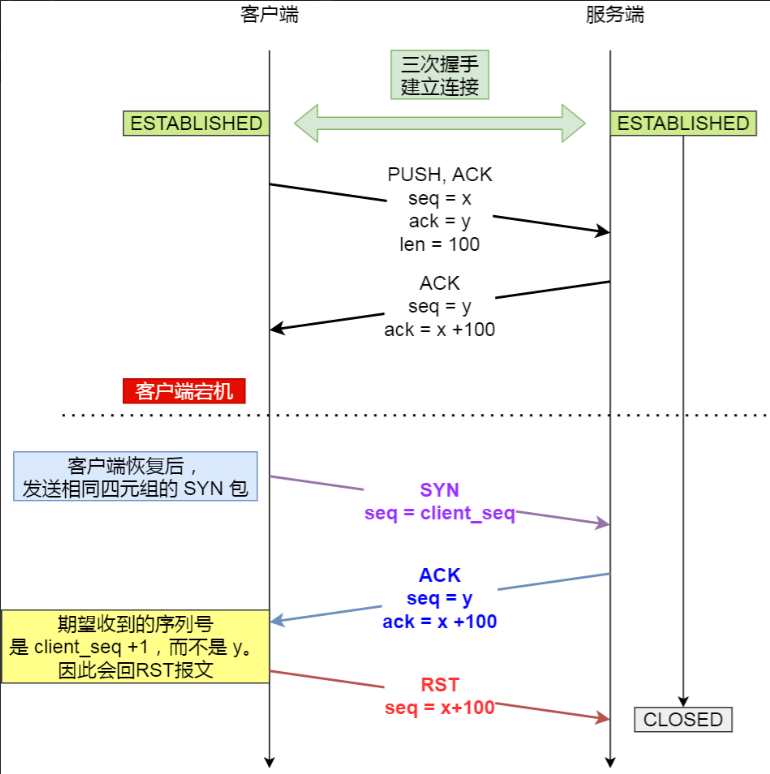
处于 establish 状态的服务端如果收到了客户端的 SYN 报文(注意此时的 SYN 报文其实是乱序的,因为 SYN 报文的初始化序列号其实是一个随机数),会回复一个携带了正确序列号和确认号的 ACK 报文,这个 ACK 被称之为 Challenge ACK。
接着,客户端收到这个 Challenge ACK,发现序列号并不是自己期望收到的,于是就会回 RST 报文,服务端收到后,就会释放掉该连接。
他的博文中是分析了linux系统下的TCP协议对这种场景的报文回复情况,那么我试着从lwip协议栈的实现中,找找相关的处理是怎么样的。
当客户端发起tcp connect的时候,调用的是lwip_connect,具体可以参考下面。
函数调用顺序:-> lwip_connect-> netconn_connect
-> netconn_apimsg
-> lwip_netconn_do_connect
-> tcp_connect
-> ...
err_t
tcp_connect(struct tcp_pcb *pcb, const ip_addr_t *ipaddr, u16_t port,
tcp_connected_fn connected)
{
err_t ret;
u32_t iss;
u16_t old_local_port;
// 省略部分实现
/* Send a SYN together with the MSS option. */
ret = tcp_enqueue_flags(pcb, TCP_SYN);
if (ret == ERR_OK) {
/* SYN segment was enqueued, changed the pcbs state now */
pcb->state = SYN_SENT;
if (old_local_port != 0) {
TCP_RMV(&tcp_bound_pcbs, pcb);
}
TCP_REG_ACTIVE(pcb);
MIB2_STATS_INC(mib2.tcpactiveopens);
tcp_output(pcb);
}
return ret;
}
通过tcp_connect这样就可以看到lwip在组一个带有SYN的TCP报文,通过底层的接口发送出去,同时将TCP的状态切换到SYN_SENT状态。
由于我们实现的lwip是异步模式,所以最终接收对方的响应报文在tcp_in.c里面,我们注意到有这么一个函数tcp_process,它就是TCP状态的状态机实现函数。
函数调用顺序:-> tcp_input-> tcp_process ...
/**
* Implements the TCP state machine. Called by tcp_input. In some
* states tcp_receive() is called to receive data. The tcp_seg
* argument will be freed by the caller (tcp_input()) unless the
* recv_data pointer in the pcb is set.
*
* @param pcb the tcp_pcb for which a segment arrived
*
* @note the segment which arrived is saved in global variables, therefore only the pcb
* involved is passed as a parameter to this function
*/
static err_t
tcp_process(struct tcp_pcb *pcb)
{
struct tcp_seg *rseg;
u8_t acceptable = 0;
err_t err;
err = ERR_OK;
//忽略部分代码
/* Do different things depending on the TCP state. */
switch (pcb->state) {
case SYN_SENT:
LWIP_DEBUGF(TCP_INPUT_DEBUG, ("SYN-SENT: ackno %"U32_F" pcb->snd_nxt %"U32_F" unacked %"U32_F"
", ackno,
pcb->snd_nxt, lwip_ntohl(pcb->unacked->tcphdr->seqno)));
/* received SYN ACK with expected sequence number? */
if ((flags & TCP_ACK) && (flags & TCP_SYN)
&& (ackno == pcb->lastack + 1)) {
pcb->rcv_nxt = seqno + 1;
pcb->rcv_ann_right_edge = pcb->rcv_nxt;
pcb->lastack = ackno;
pcb->snd_wnd = tcphdr->wnd;
pcb->snd_wnd_max = pcb->snd_wnd;
pcb->snd_wl1 = seqno - 1; /* initialise to seqno - 1 to force window update */
pcb->state = ESTABLISHED;
#if TCP_CALCULATE_EFF_SEND_MSS
pcb->mss = tcp_eff_send_mss(pcb->mss, &pcb->local_ip, &pcb->remote_ip);
#endif /* TCP_CALCULATE_EFF_SEND_MSS */
pcb->cwnd = LWIP_TCP_CALC_INITIAL_CWND(pcb->mss);
LWIP_DEBUGF(TCP_CWND_DEBUG, ("tcp_process (SENT): cwnd %"TCPWNDSIZE_F
" ssthresh %"TCPWNDSIZE_F"
",
pcb->cwnd, pcb->ssthresh));
LWIP_ASSERT("pcb->snd_queuelen > 0", (pcb->snd_queuelen > 0));
--pcb->snd_queuelen;
LWIP_DEBUGF(TCP_QLEN_DEBUG, ("tcp_process: SYN-SENT --queuelen %"TCPWNDSIZE_F"
", (tcpwnd_size_t)pcb->snd_queuelen));
rseg = pcb->unacked;
if (rseg == NULL) {
/* might happen if tcp_output fails in tcp_rexmit_rto()
in which case the segment is on the unsent list */
rseg = pcb->unsent;
LWIP_ASSERT("no segment to free", rseg != NULL);
pcb->unsent = rseg->next;
} else {
pcb->unacked = rseg->next;
}
tcp_seg_free(rseg);
/* If there's nothing left to acknowledge, stop the retransmit
timer, otherwise reset it to start again */
if (pcb->unacked == NULL) {
pcb->rtime = -1;
} else {
pcb->rtime = 0;
pcb->nrtx = 0;
}
/* Call the user specified function to call when successfully
* connected. */
TCP_EVENT_CONNECTED(pcb, ERR_OK, err);
if (err == ERR_ABRT) {
return ERR_ABRT;
}
tcp_ack_now(pcb);
}
/* received ACK? possibly a half-open connection */
else if (flags & TCP_ACK) {
/* send a RST to bring the other side in a non-synchronized state. */
tcp_rst(ackno, seqno + tcplen, ip_current_dest_addr(),
ip_current_src_addr(), tcphdr->dest, tcphdr->src);
/* Resend SYN immediately (don't wait for rto timeout) to establish
connection faster, but do not send more SYNs than we otherwise would
have, or we might get caught in a loop on loopback interfaces. */
if (pcb->nrtx < TCP_SYNMAXRTX) {
pcb->rtime = 0;
tcp_rexmit_rto(pcb);
}
}
break;
//忽略其他代码
return ERR_OK;
}
函数比较长,我们抓重点,它这里就是根据当前TCP的不同状态做不同的处理。我们看到第80行,这里:
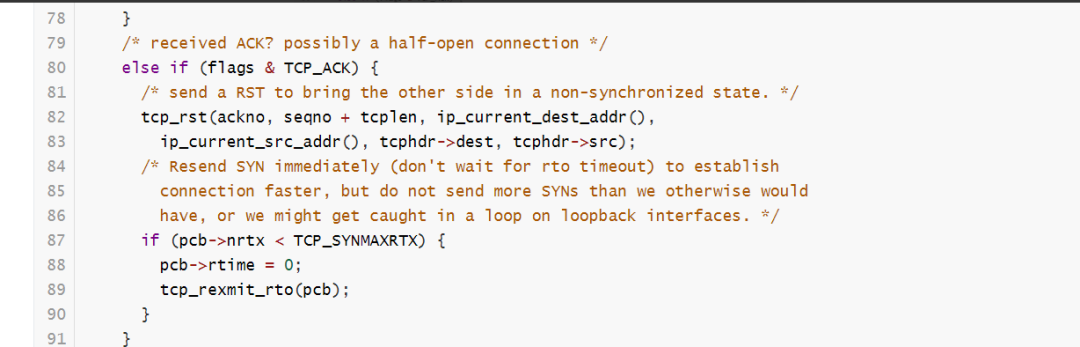
看注释很清晰,当TCP的状态是SYN_SENT状态的时候,收到一个只带ACK的报文,那么它就会回应一个RST报文,同时快速重传一个SYN报文。
接着这个函数,我们看下服务器端的处理,如果TCP链接已经处于ESTABLISHED状态,当它收到SYN报文时,它会怎么处理呢?
/**
* Implements the TCP state machine. Called by tcp_input. In some
* states tcp_receive() is called to receive data. The tcp_seg
* argument will be freed by the caller (tcp_input()) unless the
* recv_data pointer in the pcb is set.
*
* @param pcb the tcp_pcb for which a segment arrived
*
* @note the segment which arrived is saved in global variables, therefore only the pcb
* involved is passed as a parameter to this function
*/
static err_t
tcp_process(struct tcp_pcb *pcb)
{
struct tcp_seg *rseg;
u8_t acceptable = 0;
err_t err;
err = ERR_OK;
/* Process incoming RST segments. */
if (flags & TCP_RST) {
/* First, determine if the reset is acceptable. */
if (pcb->state == SYN_SENT) {
/* "In the SYN-SENT state (a RST received in response to an initial SYN),
the RST is acceptable if the ACK field acknowledges the SYN." */
if (ackno == pcb->snd_nxt) {
acceptable = 1;
}
} else {
/* "In all states except SYN-SENT, all reset (RST) segments are validated
by checking their SEQ-fields." */
if (seqno == pcb->rcv_nxt) {
acceptable = 1;
} else if (TCP_SEQ_BETWEEN(seqno, pcb->rcv_nxt,
pcb->rcv_nxt + pcb->rcv_wnd)) {
//在接收窗口内的RST报文,最终是在这里处理!!!
/* If the sequence number is inside the window, we only send an ACK
and wait for a re-send with matching sequence number.
This violates RFC 793, but is required to protection against
CVE-2004-0230 (RST spoofing attack). */
tcp_ack_now(pcb);
}
}
if (acceptable) {
LWIP_DEBUGF(TCP_INPUT_DEBUG, ("tcp_process: Connection RESET
"));
LWIP_ASSERT("tcp_input: pcb->state != CLOSED", pcb->state != CLOSED);
recv_flags |= TF_RESET;
pcb->flags &= ~TF_ACK_DELAY;
return ERR_RST;
} else {
LWIP_DEBUGF(TCP_INPUT_DEBUG, ("tcp_process: unacceptable reset seqno %"U32_F" rcv_nxt %"U32_F"
",
seqno, pcb->rcv_nxt));
LWIP_DEBUGF(TCP_DEBUG, ("tcp_process: unacceptable reset seqno %"U32_F" rcv_nxt %"U32_F"
",
seqno, pcb->rcv_nxt));
return ERR_OK;
}
}
//当服务器端收到一个处于ESTABLISHED状态的连接收到一个SYN报文,就直接回复ACK报文了。
if ((flags & TCP_SYN) && (pcb->state != SYN_SENT && pcb->state != SYN_RCVD)) {
/* Cope with new connection attempt after remote end crashed */
tcp_ack_now(pcb);
return ERR_OK;
}
//忽略部分代码
结合下面的实际抓包,我们再仔细分析分析。
4.6.2 实战分析:实战中的场景路劲
文不如图,针对真实的场景路径,我想我直接从所抓到的TCP报文来入手分析可能会效果更好。
下面几张图,是从复现问题的报文中截取出来的,我分为了以下三部分:(完整报文戳[这里]())
-
开机正常连上服务器,正常收到报文,PING包能发能收
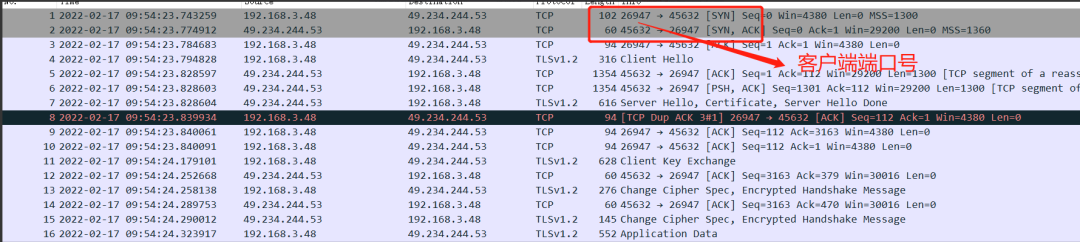
这里可以看到报文序号#1使用端口号26947去连接服务器,一切正常,后面交互PING包也非常正常。
-
设备重启后,连接服务器,后面开始出现掉线
![]()
这里我们注意报文序号#41-#47,这个时间节点,就是设备重启后首次发起(第一次)TCP连接,我们可以清晰地看到,它使用的端口号仍然是26947,与重启前的端口号是一样的,这不就进入到前一小节的理论分析中了吗?
我们再仔细看下,这个时候,报文交互上发生了什么?
41号报文,使用带SYN=1且Seq为0(相对值为0)的的报文发起TCP连接,紧接着#42报文,服务器端回应了一个ACK报文(Seq=4670,ACK=1284),随后#43报文,设备端认为服务器回复的不对,从而发出了带RST的链接重置的报文。
熟悉TCP链接的三次握手,我们都知道,正常的握手流程应该是:SYN(seq=0,ACK=0) -> SYN,ACK(seq=0,ACK=1) -> ACK(seq=1,ACK=1);而我们看到的这次三次握手却不是我们的期望的。
我们重点看看,服务器端在回应客户端SYN报文回复的这个报文,究竟是啥意思。Seq=4670,ACK=1284,意味着服务器还认为客户端给过去的报文交互,还是重启前那一次的呢;ACK=1284表示服务器对前1284个字节都已经收到了,所以呢wireshark也很聪明,直接把客户端的SYN报文标记为TCP Retransmission(报文重传:它认为#41报文时#1报文的重传),而服务端回应SYN的报文标记为TCP Dup ACK #39-1(重复ACK确认:它认为服务器对#39号报文重复确认了,因为它们都是ACK=1284)。
接下来是最重要的一条报文#42号RST报文:根据TCP的标志位介绍,我们可以知道这条报文客户端是想重置这个链接,也就是它要废弃这个服务器认为正常的TCP链接,但似乎服务器并不买单,我们继续看下面的报文。
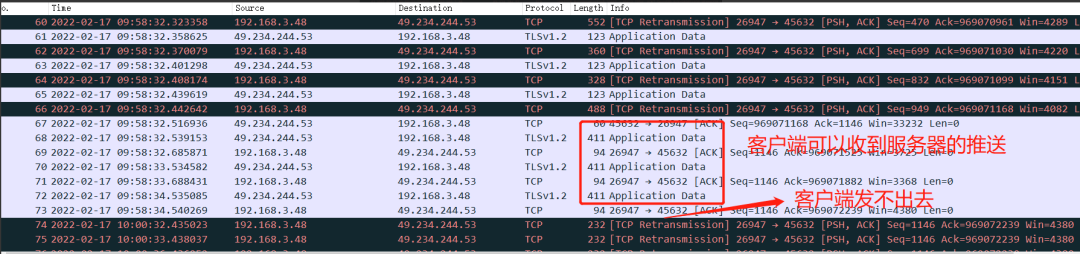
期间能正常收到服务器的推送(设备收到MQTT推送arrived的log也可以佐证这一点),直到#73 #74报文客户端需要发PING包的时候,发现掉线了。
-
触发掉线重连机制,重新连上服务器
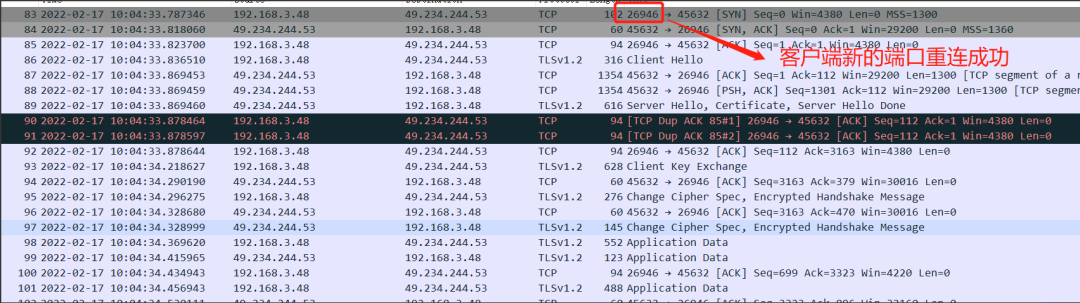
看着三次握手多顺利,同时我们留意到这次的客户端端口不再是26947了,而是一个新的端口号26946;这是因为抓包方式的原因,这个端口号并不完全体现是设备端lwip的tcp_port,但至少是能反映它是在变化的。
重连成功后,设备重新在线,PING包交互正常,恢复了。
4.6.3 解决疑惑:为何偶现而不必现
既然上面分析得头头是道,照这么说应该是一个必现的问题呀?为何在实际生产案例中,却是偶现的呢?难道还有什么因素我们没考虑进去?
首先,在上面的分析中,我们得出一个很重要的结论,当服务器端还处于连接状态的TCP链接,收到一个由相同的四元组组成的SYN报文,最终就会触发设备端产生RST报文,从而使得通讯链接发生“假链接”,影响实际通讯!
在这个结论中,有几个前提必须要满足:
-
相同的四元组构成的SYN报文;
-
前一个链接在TCP服务端还处于TCP状态中的已链接状态。
短时间内连接同一个无线路由,很大概率获取同一个本地IP,由于随机数的问题,本地端口也是同一个,所以第一条相同四元组是很容易满足的,第二条需要满足前一链接还保持在已链接状态,这就要求两次间隔重启不能间隔时间太长,否则就会触发服务器端的掉线检测机制,从而被识别到设备端已掉线,那么这种情况下,肯定不能复现如题的问题。
但是,我们在复测的过程,发现有时紧挨着时间重启,也没有发生类似的掉线问题,也就是说重启后的链接一样是好好的。
通过抓包来看,唯一不同的是没有出问题的这个重启,客户端发起SYN报文,最后并没有触发客户端发送RST报文,如下图所示:
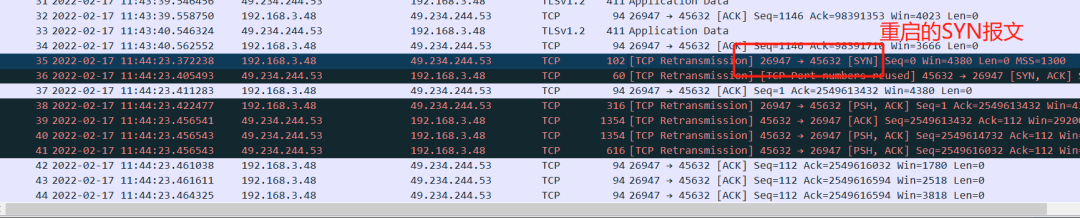
而异常的场景下,报文如下:

这个的确令我百思不得解,看来TCP理论知识还不够扎实,还要再去恶补恶补。有分析思路的朋友,也欢迎在评论席与我一同讨论。
5 问题修复
当一切的分析都站稳了脚跟的时候,修复问题便是水到渠成的事情。
这里的修复,其实主要是两个方面:
5.1 解决链接标准C库的rand函数的问题
在原生的lwip组件代码中,随机数的适配本身就是移植的一部分,很遗憾,在我们出问题的芯片上看到的随机数还是原生态的rand函数。
要想解决掉这个问题,有两个思路:
一个是直接在lwip组件中的arch.h里宏定义LWIP_RAND的地方直接切换成芯片的硬随机数接口xxx_rand,这种是在预编译阶段就完成的;
还有一种就是在链接阶段处理的,把原本链接rand函数直接替换链接成芯片平台的硬随机数接口xxx_rand,gcc编译就一个这样的链接选项支持这样的功能。
为了最大化保持lwip组件的代码完整,我们不想改它一行代码,所以我们采用第二种解决思路,只需要在编译构建的全局链接参数中加上以下参数即可:
# enable hal-rand
GLOBAL_LDFLAGS += -Wl,--wrap=rand
同时在hal层的C文件中,添加实现一个叫__warp_rand的函数即可。
/* wrap hal TRNG function */
int __wrap_rand(void)
{
extern int xxx_trng_rand(void);
int ret = (int)xxx_trng_rand(); //call TRNG API
return ret;
}
经以上修改之后,lwip组件中调用的rand函数,最终就会调到xxx_trng_rand接口了,基本就解决了随机数的问题。
5.2 解决芯片硬件随机数不随机的问题
但是,上面的分析部分,我们也提到了,这个芯片居然还出现了硬件随机数不随机的问题,准确说,它获取的不是随机数,而是一个无序的存储序列,这无疑是一个重大bug。
就像这样:
第一次开机:随便获取8个随机数,初步得到 12345 2345 3456 6789 5678 9867 234 567第二次开机:随便获取8个随机数,还是得到 12345 2345 3456 6789 5678 9867 234 567
第三次开机:随便获取8个随机数,依然得到 12345 2345 3456 6789 5678 9867 234 567
这显然是不随机的,是会出问题的。由于我们没有芯片的datasheet以及不能完全掌握其TRNG的工作原理,我们把问题抛给了原厂,幸运的是,原厂很快给我们打了个小patch。
这个小patch说简单是真的简单,就仅仅是加了一个延时;但是这个延时,代价有点大!!!
以下是伪代码,但足以展示这个代价的威力!
uint32_t xxx_trng_rand(void)
{
//enable TRNG register
//patch here msleep(10); //dealy 10ms
//read TRNG register data
uint32_t ret = read_TRNG();
//disable TRNG register
return ret;
}
what???每获取一个随机数都要延时10ms?那我在某次网络通讯中,可能要获取成百上千个随机数啊?这积累的延时简直不能接受啊!
按理说,芯片不能“弱”成这样,也没有这么不合理的设计!看它这个延时,无非的意思就是说,我的TRNG寄存器不是一上电就可以工作的,你得先给它预热下,稍后再来取嘛。
OK,既然你是这样的特性,那么我们可不可以在驱动初始化的时候就给你预热呢?获取随机数的时候就不预热了哇?
试试看,于是有了这样的伪代码:
void sys_driver_init(void)
{
//normal driver init
//special for TRNG warm up
//step1. enable TRNG register
//step2. msleep(10); //dealy 10ms
//step3. disable TRNG register
}
uint32_t xxx_trng_rand(void)
{
//enable TRNG register
//read TRNG register data
uint32_t ret = read_TRNG();
//disable TRNG register
return ret;
}
这样代码一测试,完美!至少不需要每次获取随机数都dealy啊!其实在写这段热身代码的时候,也踩了些坑的,比如没有先enable TRNG寄存器就去delay,这无疑是delay了个寂寞啊?
至少,所以需要修正的代码已经修正完成。值得注意的是,我们没有改一行应用层及组件层的代码,那么修复后的情况究竟如何,下一章节我们来验证验证。
6 问题验证
6.1 随机数的问题验证
这里的验证,其实是要一层层来验证,由于问题的根源在于随机数的不随机导致,那么我们有限要验证的应该是芯片TRNG的随机性。
幸运的是,通过第5部分的patch代码,我们有效地看到了TRNG的随机性基本满足了我们的要求,我们的验证方法很简单,就是开机完成初始化之后就获取一组随机数,然后就重启;不断地测试,观察1000左右的数据。
从1000的数据,初步是可以看出去随机性的,但如果需要过随机数认证的话,还得使用NIST专门的测试工具做更进一步的验证测试,这里就不展开论述了,有兴趣的可以自行去了解下,像金融领域的PCI安全认证,随机数的测试是非常关键的一环。
6.2 偶发的网络掉线问题验证
这个验证就要回到issue本身了,虽然我们在上面的分析阶段,其实也做了部分边分析边修正边验证的工作,但上面的场景更加侧重的是在不清楚稳定的复现路径的情况下不停地试错。
所以,回归验证这个issue还是需要根据稳定的复现路径,做一些控制变量来单项验证,比如每次重启后就固定使用12345端口发起MQTT链接,观察其复现情况;恢复正常修复后的随机端口号,观测其情况。
同时,还得把压测环境搭建好,同步进行压力测试,观测其情况。
只有以上几点都通过验证后,我们才有扎实的信心说:“这个issue可以close了”!
7 经验总结
-
当你对一个网络问题靠逻辑思考解决不了的时候,第一要想到的方法就是抓包分析;
-
抓包分析有方法,优先排查上层网络协议的报文,比如TCP/TLS等;当上层协议包分析不出问题的时候,尝试抓空口包;
-
TCP链接的状态切换是所有基于TCP/IP协议的网络通讯的基础,重点分析它有助于打开你的分析思路;
-
所有偶现的问题,一定有复现路劲;如果你还没出现,仅仅是你的测试次数还不够多;
-
嵌入式里面的C库,往往不是标准的,不能太轻易相对传统意义上的C标准接口,多持怀疑的态度;
-
随机数的随机性在网络通讯中非常重要,当你的网络通讯超出你的想象的时候,不妨想想随机数的可能性;
-
lwip协议栈的实现在嵌入式设备中太常用了,关于它的移植不能简单的”拿来主义“,需要系统地、全面地了解其工作原理、代码架构和适配的基本工作,了解其可能出问题的点和常规的解决方法;
-
技术偷懒使不得,技术债迟早都是要还的;
-
疑难bug的解决要及时总结和复盘,形成一定的分析方法论,指不定哪天就帮助你解决其他相关的疑难问题。
原文标题:【网络通讯与网络安全】网络通讯中的随机数如果不随机会怎么样!
文章出处:【微信公众号:RTThread物联网操作系统】欢迎添加关注!文章转载请注明出处
-
如何在LTspice仿真中实现伪随机数和真随机数的生成2026-01-09 5004
-
产生随机数的方法有哪些2021-07-15 1915
-
什么是随机数2021-07-22 1870
-
基于FPGA的随机数性能检测设计2013-07-24 1144
-
产生随机数2016-12-01 1315
-
神经网络的伪随机数生成方法2018-02-02 1335
-
伪随机数生成算法2018-04-03 901
-
如何在C语言中使用随机数2018-11-09 6023
-
单片机产生随机数的方法2019-02-23 23061
-
单片机产生随机数的两种方法2019-03-01 2942
-
DApp的随机数为什么会被黑客破解2019-10-18 3215
-
Python随机数模块的随机函数使用2020-01-18 3324
-
单片机C语言如何产生随机数2022-02-08 1265
-
FPGA的伪随机数发生器学习介绍2023-09-12 3391
-
真随机数和伪随机数的区别2025-08-27 3074
全部0条评论

快来发表一下你的评论吧 !
