

使用Trace View对对Kernel进行性能仿真分析
描述
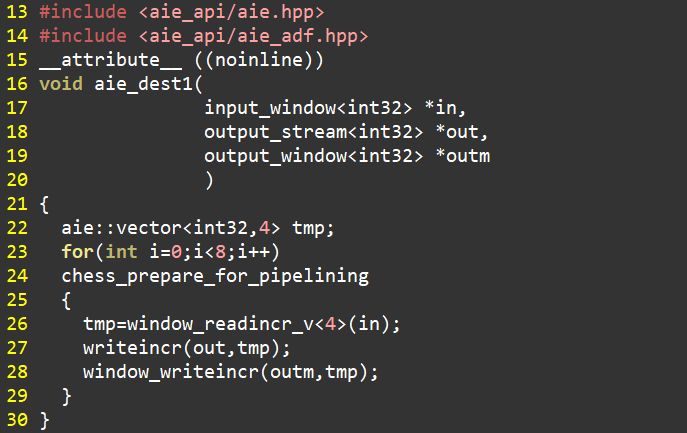
对Kernel进行性能分析需要对其进行仿真,同时还要用到Vitis Analyzer。为便于说明,我们以一个简单的Vitis工程为例。这个工程中有两个kernel,相应的代码如下图所示。 kernel 1有一个输入两个输出。输入使用window访问方式。读取数据后将数据分别写入到stream和window(本地Memory)。事实上,写入到stream和window的数据是相同的。代码第15行通过noinline使得工具在编译过程中保持当前kernel层次。
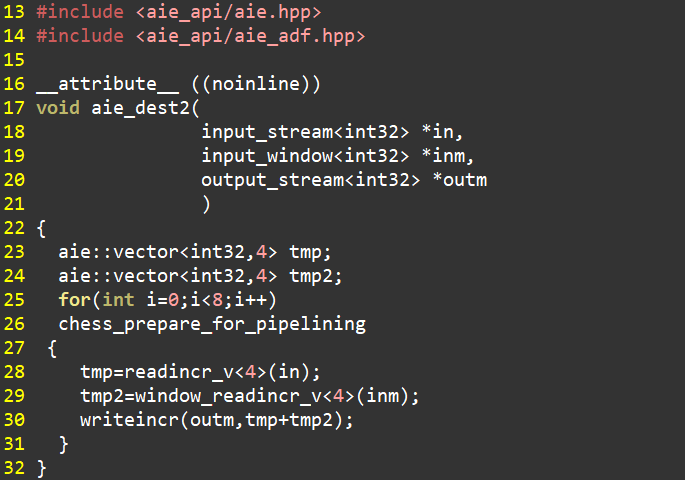
kernel 2有两个输入和一个输出。两个输入均来自于kernel 1的两个输出。由于kernel 1输出采用了stream和window,因此,这里的输入也对应使用stream和window访问方式。然后将读取的数据相加,再把结果写入到window。
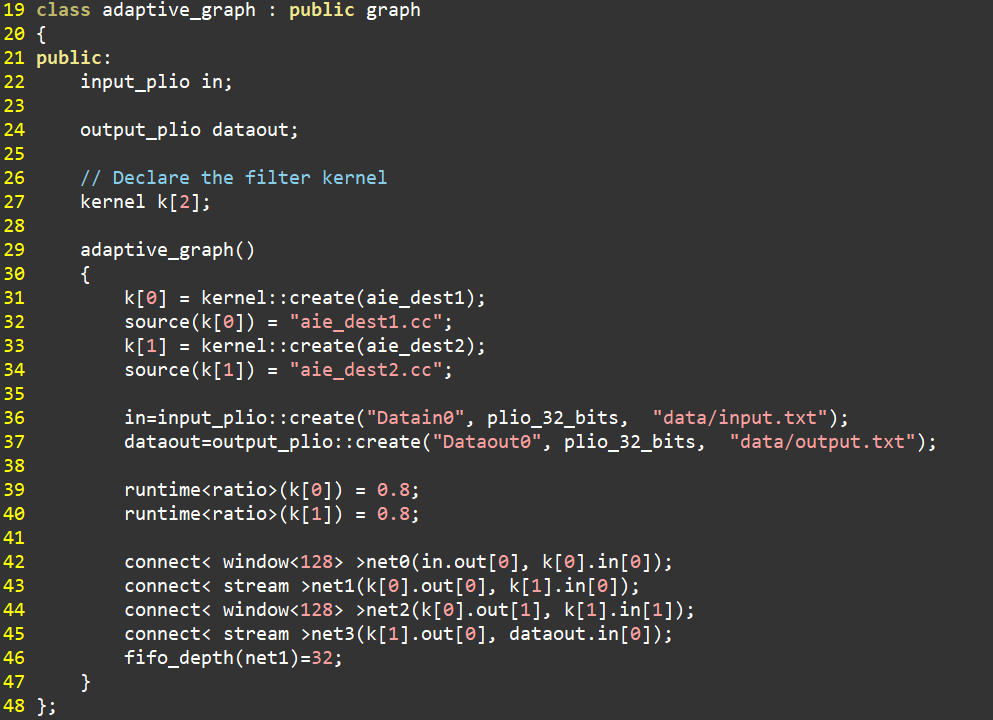
kernel之间的连接关系体现在graph中,如下图所示。代码第22行和第24行分别声明了输入和输出端口,plio表明端口在PL侧。换言之,若为输入,则输入数据由PL侧提供,若为输出,则输出数据会到达PL侧。代码第27行使用了数组方式声明了两个kernel。代码第36行和第37行分别创建了graph输入/输出端口,指定其位宽为32位(plio_32_bits)。代码第42行至45行将graph输入/输出端口以及两个kernel连接起来。代码第46行表明在net1(stream)上使用FIFO,其深度为32。实际上这个FIFO就在AXI Interconnect上。

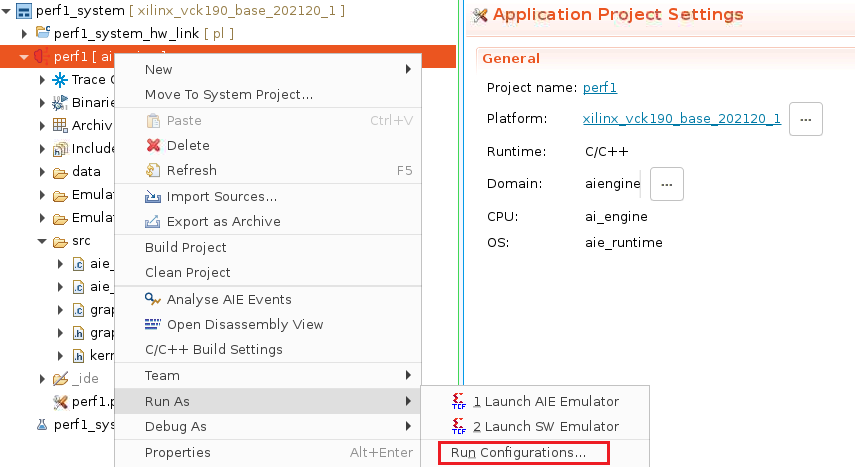
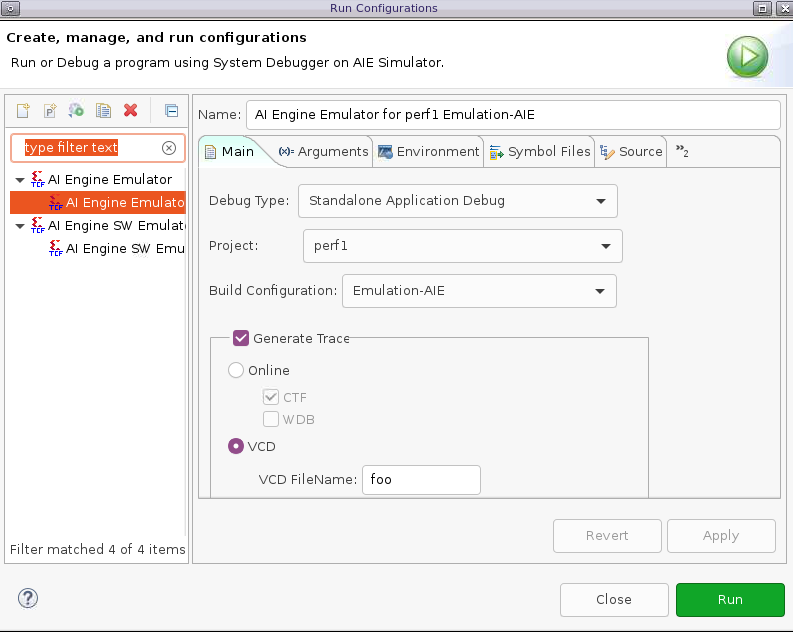
我们可以借助Trace View观察每个kernel的执行状况,这就需要在仿真时生成vcd文件。生成vcd文件需要两部设置,如下图所示。
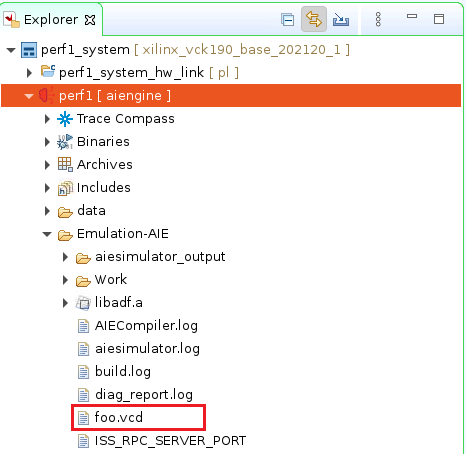
最终会生成vcd文件,其文件目录如下图所示。
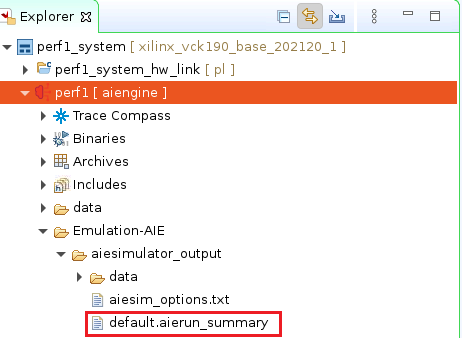
点击default.aierun_summary,将会打开Vitis Analyzer,在这个视图下选择Trace即可看到kernel的执行情况。
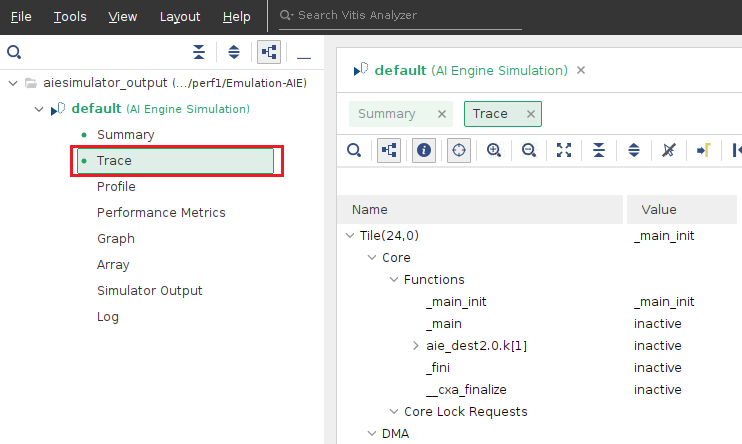
Trace view如下图所示。从图中可以看到一些具体的事件。
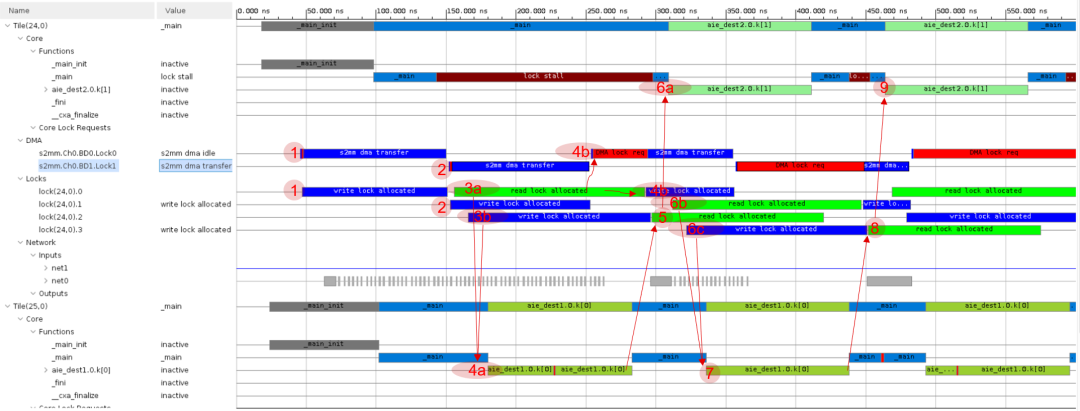
标记1:
Tile 24_0 DMA s2mm 通道0启动。获取buf0(ping)的lock信号,将数据由PL传送给buf0。
标记2:
Tile 24_0 DMA s2mm通过1启动。获取buf0d(pong)的lock信号,将数据由PL传送给buf0d。
标记3a:
kernel aie_dest1获取输入buffer buf0的lock信号(在图中显示为read lock allocated)。
标记3b:
kernel aie_dest1获取输出buffer buf1的lock信号。
标记4a:
aie_dest1获取了buf0和buf1的lock信号,开始启动工作。
标记4b:
一旦Tile 24_0 DMA s2mm通道1完成,则切换到通道0。这时aie_dest1仍然在读buf0,只有当其释放了buf0的lock信号,Tile 24_0 DMA s2mm通道0才可以启动数据传输。
标记5:
一旦aie_dest1执行结束,它就会释放buf1,这样kernel aie_dest2就会捕获buf1的lock信号。
标记6a:
aie_dest2获取buf1的lock信号之后就开始启动工作。
标记6b:
aie_dest1获取buf0d的lock信号。
标记6c:
aie_dest1获取buf1d的lock信号。
标记7:
aie_dest1在获取buf0d和buf1d的lock信号之后开始启动工作。
标记8:
aie_dest1完成执行,释放buf1d。aie_dest2获取buf1d的lock信号。
标记9:
aie_dest2获取buf1d的lock信号之后,开始启动工作。
注:stream接口不需要lock信号。每个lock的获取和释放都需要一些时钟周期的开销。
责任编辑:gt
-
c6678使用Hardware trace analyzer的问题2018-08-06 1453
-
IAR EWARM的SWO Trace调试功能2020-11-10 2049
-
使用IAR ETM Trace调试功能的要求2021-03-05 3307
-
怎样通过trace生成系统cpu的loading图2021-06-28 1699
-
SYSTEM VIEW教材2010-04-10 764
-
trace32仿真器使用教程2010-05-17 1952
-
ADAMS/view虚拟样机仿真分析资料下载2018-03-30 1333
-
如何使用Systemview实现对QPSK系统进行仿真与分析2019-01-17 1849
-
如何使用System view数字调制进行眼图分析2019-01-23 2992
-
关于Trace32forRT-Thread的简述与使用2021-04-28 5413
-
Linux ftrace工具抓 i2c trace2023-07-20 2603
-
如何对基于μTrace和Trace32的LPC86x进行边界扫描2023-08-17 668
-
使用Percepio View免费跟踪工具分析Zephyr应用2025-05-27 1161
-
Linux性能分析实战:用trace揪出卡顿、高CPU的“真凶”2026-02-03 828
全部0条评论

快来发表一下你的评论吧 !
