

基于Python语言的RFM模型讲解
描述
背景
RFM(Recency Frequency Monetary)模型是衡量客户价值和客户创利能力的重要工具和手段。在众多的客户关系管理(CRM)的分析模式中,RFM模型是被广泛提到的。
RFM模型是属于业务分析方法与模型中的部分。它的本质是用户分类。本文将用现代最流行的编程语言---Python语言来实践课堂上讲解的RFM模型,将用户进行分类。
本文采用Anaconda进行Python编译,主要涉及的Python模块:
-
pandas
-
matplotlib
-
seaborn
-
datetime
本章分为三部分讲解:
1.RFM模型原理与步骤
2.Python分布实现RFM
3.总结
RFM模型原理与步骤
RFM模型的思路是:该模型是根据用户历史行为数据,结合业务理解选择划分维度,实现用户分类,助力用户精准营销。此外,还学习了构建RFM模型的步骤:
-
获取R、F、M三个维度下的原始数据
-
定义R、F、M的评估模型与判断阈值
-
进行数据处理,获取R、F、M的值
-
参照评估模型与阈值,对用户进行分层
-
针对不同层级用户制定运营策略
上面步骤可以知道,我们需要有RFM三个维度,根据我们在业务分析方法课程中学到的,业务分析模型离不开指标,而指标是对度量的汇总。因此,在找出RFM三个维度后,需要对每个维度下度量实现不同汇总规则。下面讲述对R、F、M三个维度下的度量如何进行汇总。
1.R代表最近一次消费,是计算最近一次消费时间点和当前时间点的时间差。因此,这里需要用到多维数据透视分析中的基本透视规则---最小值MIN求出最小的时间差。
2.F代表消费频次,是在指定区间内统计用户的购买次数。因此,这里需要用到多维数据透视分析中的基本透视规则---技术类COUNT(技术类不去重指标)统计用户的购买次数。
3.M代表消费金额,是指在指定区间内统计用户的消费总金额,因此,这里需要用到求和类指标,也即基本透视规则中的合计规则---SUM。
在对得到RFM模型中的指标值后最重要的一步就是分层,根据我们在课堂上学到的内容,大部分的用户分层是根据经验来分层的,本文在追求数据的客观性下采取统计学中的等距分箱方法来进行分层,对R、F、M三个维度分成两类。
综上,我们大致了解了如何构建RFM模型,下面以Python实现RFM模型,并对每一步进行详细的讲解。
03 Python实现RFM模型
数据准备
本文所需的数据是一家公司对2021年10月底至今的客户购买行为数据,(前十二行)如图下:
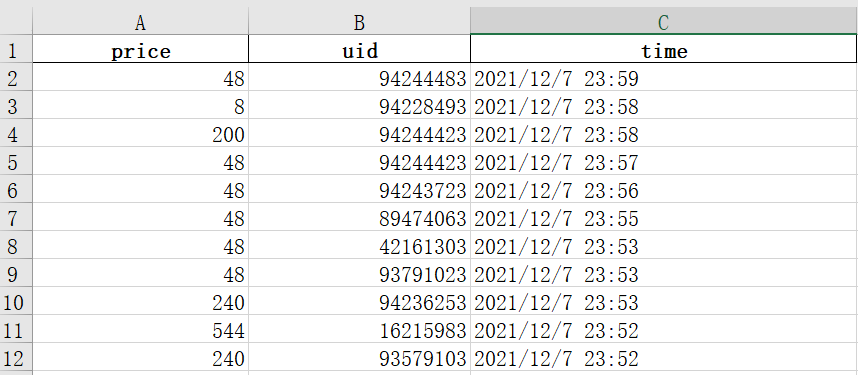
其中,uid代表客户的id,是存在重复情况的。prince维度代表客户每发生一次交易行为所花费的金额。time为客户发生交易行为的时间。
数据读取与理解
在得到一份数据之后,我们第一步就是要理解数据的业务意义,以及对数据表的EDA(探索性分析),这里通过如下代码,发现以下特征:

具体代码(包含Python导入包部分)如下:
# 导入相关包
import pandas as pd
import time
import numpy as np
import seaborn as sns
import matplotlib.pyplot as plt
plt.rcParams['font.sans-serif'] = ["SimHei"]
plt.rcParams["axes.unicode_minus"] = Falsesns.set(style="darkgrid")
# 数据读取与查看
data = pd.read_excel('data.xlsx')
data.head()
data.isnull().sum() #查看缺失值
data.duplicated().sum() #重复值,但是不删
data.dtypes #查看数据类型
data.describe()
# 创建dataframe,存放RFM各值
data_rfm = pd.DataFrame()
接下来进行R、F、M指标值构建。
时间维度处理
从上文可以知道time维度,即每笔交易行为发生的时间是字符串object的格式,而在Python中我们对时间作差需要的是datetime格式,因此利用pandas库中的pd.to_datetime函数将时间格式进行转换,代码如下:
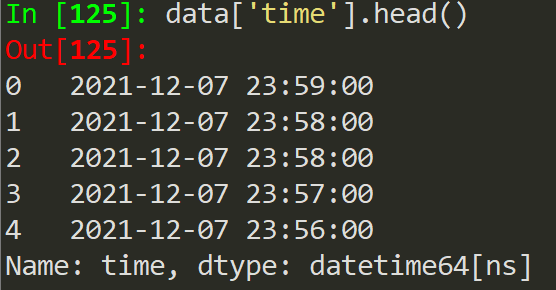
data['time'] = pd.to_datetime(data['time'])
得到的前五行数据如图下,可以看到数据类型变成了datetime64[ns]
统计每笔订单产生时间与当前时间的差(这里的当前时间是2021年12月11日),得到的差是timedelta64[ns]类型
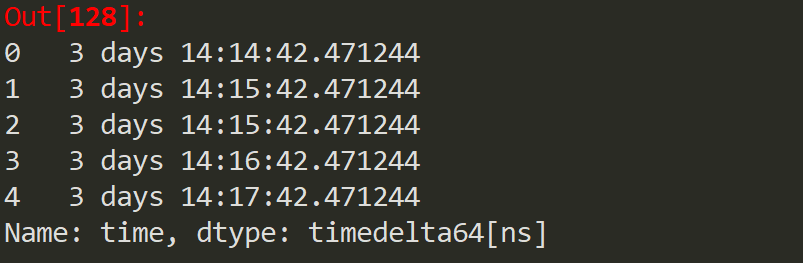
可以看到时间差中包含了day、时、分、秒4个维度,但是这里我们仅需要day维度,因此我们用astype()函数将类型转为仅含有day维度的timedelta64[D]类型。具体代码如下:
# 统计没条数据与当前日期的时间差
## 计算相差天数
data['R'] = (pd.datetime.now() - data['time'])
## 将时间差timedelta格式转化为需要的日格式
data['R'] = data['R'].astype('timedelta64[D]').astype('int')
(tips:这里可能会报警告:FutureWarning: The pandas.datetime class is deprecated and will be removed from pandas in a future version. Import from datetime module instead.读者无需理会,这是由于我们所用的pd.datetime.now()是一个比较旧的函数,以后将会废弃。)
统计R值
在上面我们已经创建了名为data_rfm的表结构的数据框,因此,将下面统计的R值放入其中。R值得统计是找客户最近发生交易行为日期与当前日期的差。换一种思路就是找所有时间差中的最小值。
因此利用pandas中的groupby函数对每个用户以上一步统计的R值作为分组依据进行分组,并求出最小值。具体代码如下:
data_rfm = pd.merge(data_rfm,data.groupby('uid')['R'].min(),
left_on = 'user_id',right_on='uid')
统计F值
F值得统计就是统计指定区间内的消费频次,而指定区间一般为人为设定,这里我们取全部数据,即2021年10月底至今作为指定区间。
本文利用value_counts()函数对uid进行统计即为每个用户得消费频次,同时将结果合并到data_rfm数据框中。
# 统计指定区间内的消费频次
data_rfm['user_id'] = data['uid'].value_counts().index
data_rfm['F'] = data['uid'].value_counts().values
统计M值
本文以uid作为分组依据对price字段进行求和,得到求和类指标M值。此外,将结果合并到data_rfm数据框中。
data_rfm = pd.merge(data_rfm,data.groupby('uid')['price'].sum(),
left_on = 'user_id',right_on='uid')
data_rfm.rename(columns={'price':'M'},inplace = True)
上述代码中出现了pandas库中得合并语法merge(),merge()函数采取的是横向合并,不同于MYSQL,不需要指定左表还是右表为主表,只需要提供左表与右表的公共字段在各表中的名称即可。
由于data_rfm数据表中的user_id是去重的,因此将其作为主键。而data.groupby('uid')['price'].sum()得到的表格也是去重的,因此我们可以采取多维数据模型中的连接对应关系---一对一对两表进行合并。公共字段为:左表的uid,右表的user_id。
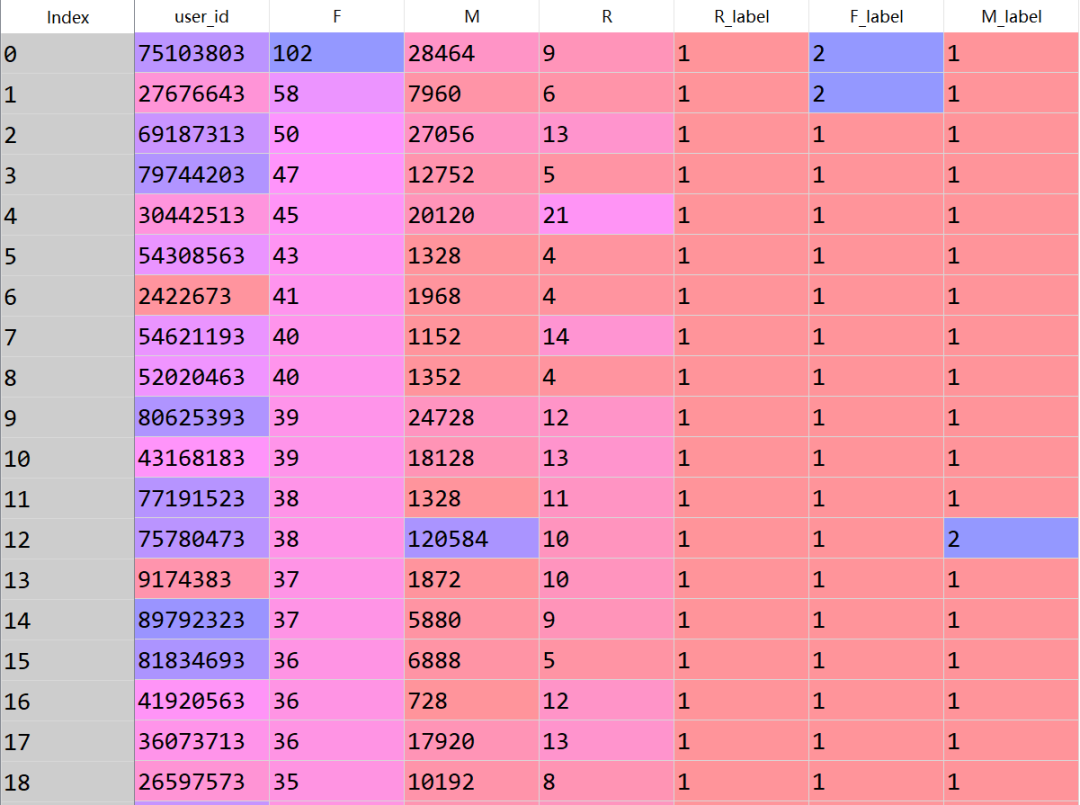
最终表格结果如下,展现前18行:
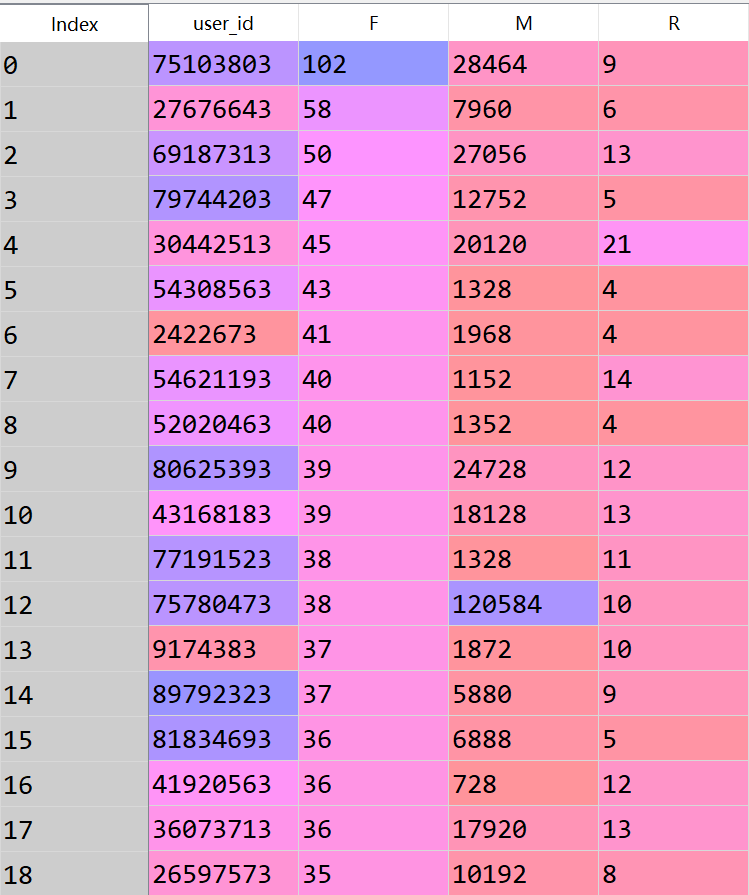
数据分箱
在得到R、F、M三个指标值后,我们需要对这三个指标进行分类,并将每个用户进行分层。
本文不采取人为主观性的经验法则划分,而是采取等距分箱的方式划分,等距分箱的原理较简单,这里写出步骤:
-
从最小值到最大值之间,均分为$N$等份(这里$N$取为2)。
-
如果 $A$,$B$ 为最小最大值, 则每个区间的长度为 $W=(B−A)/N$ ,.
-
则区间边界值为$A+W$,$A+2W$,….$A+(N−1)W$ 。这里只考虑边界,采用左闭右开的方式,即每个等份的实例数量不等。
在Python中可以利用pandas库中的cut()函数轻松实现上述等距分箱,同时将结果R_label,F_label,M_label合并到data_rfm数据框中具体代码如下:
# 分箱 客观 左闭右开
cut_R = pd.cut(data_rfm['R'],bins = 2,right = False,labels = range(1,3)).astype('int')
data_rfm['R_label'] = cut_R
cut_F = pd.cut(data_rfm['F'],bins = 2,right = False,labels = range(1,3)).astype('int')
data_rfm['F_label'] = cut_F
cut_M = pd.cut(data_rfm['M'],bins = 2,right = False,labels = range(1,3)).astype('int')
data_rfm['M_label'] = cut_M
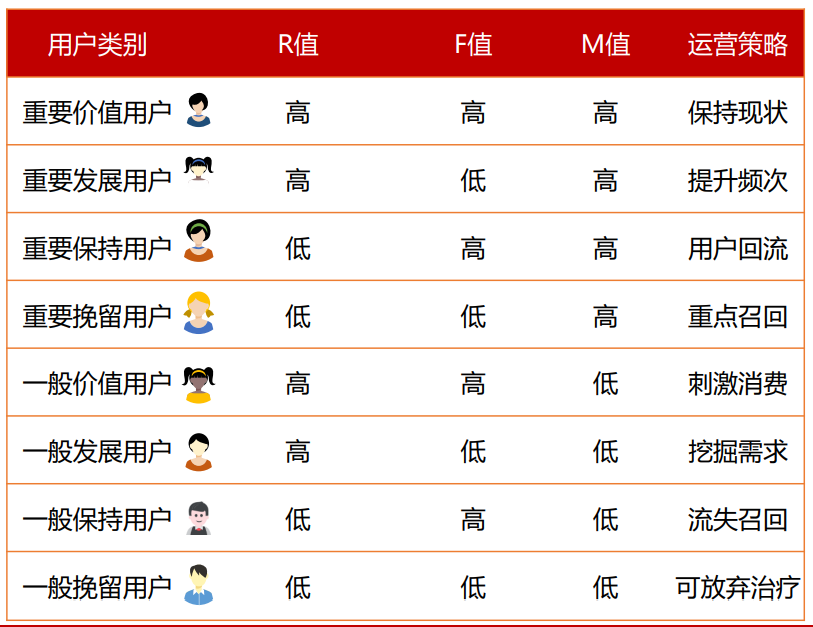
由于利用cut()函数得到的是区间形式的值,因此需要赋予label值进行虚拟变量引用。label值使用1和2,对应的区间为从小到大。具体代表意思如下表:

得到最终的表格形式如下:
用户分类
在得到每个用户的R、F、M三个维度的label值后,最后就是需要对用户进行分类,分类的原则如图下:
利用pandas库中的·terrows()函数循环遍历每个用户行为记录,将符合上述条件的划分对应的类,具体代码如下:
for i,j in data_rfm.iterrows():
if j['R_label'] == 2 and j['F_label'] == 2 and j['M_label'] == 2:
data_rfm.loc[i,'用户类别'] = '重要价值用户'
if j['R_label'] == 2 and j['F_label'] == 1 and j['M_label'] == 2:
data_rfm.loc[i,'用户类别'] = '重要发展用户'
if j['R_label'] == 1 and j['F_label'] == 2 and j['M_label'] == 2:
data_rfm.loc[i,'用户类别'] = '重要保持用户'
if j['R_label'] == 1 and j['F_label'] == 1 and j['M_label'] == 2:
data_rfm.loc[i,'用户类别'] = '重要挽留用户'
if j['R_label'] == 2 and j['F_label'] == 2 and j['M_label'] == 1:
data_rfm.loc[i,'用户类别'] = '一般价值用户'
if j['R_label'] == 2 and j['F_label'] == 1 and j['M_label'] == 1:
data_rfm.loc[i,'用户类别'] = '一般发展用户'
if j['R_label'] == 1 and j['F_label'] == 2 and j['M_label'] == 1:
data_rfm.loc[i,'用户类别'] = '一般保持用户'
if j['R_label'] == 1 and j['F_label'] == 1 and j['M_label'] == 1:
data_rfm.loc[i,'用户类别'] = '一般挽留用户'
条形图可视化用户类别
利用seaborn画图库对已划分类别的用户进行技术统计与可视化,得到如下图表
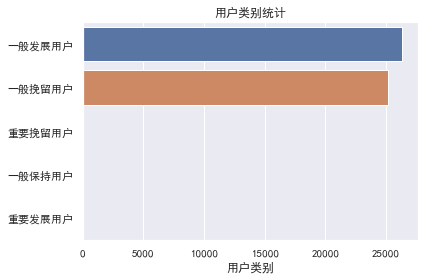
可以看出,大部分的用户属于一般发展用户与一般挽留用户。而对于一般发展用户而言采取的策略为挖掘需求,后者则是放弃治疗。因此,可以看出该公司在10月底至今的时间段内,用户流失较多,但是可发展的用户同样是非常多的,想要提高收入,对一般发展用户入手是成本少,效率高的选择。
总结
RFM模型同时还利用了多维数据透视分析和业务分析方法两个模块的内容。所以说实践是检验和巩固学到的东西的最好方法。
例如一级的常考题上,我们常碰到一个模拟题,包含RFM模型划分规则和一张帕累托图,问题是在公司有限成本下提高公司收入,需要针对哪种用户营销最好,答案是一般发展用户。相信大家一开始都很疑惑为什么选这个,这时候如果像本文一样对一份数据进行实践,这样你就会更加理解为什么是这个答案。
审核编辑:郭婷
- 相关推荐
- 热点推荐
- python
-
【大语言模型:原理与工程实践】大语言模型的评测2024-05-07 1941
-
python自然语言2018-05-02 6441
-
实例讲解Python的特性2017-09-28 775
-
RI-RFM-007B RI-RFM-007B, RI-RFM-008B, RI-ACC-008B2018-08-20 744
-
Python语言为什么可以得到广泛的应用2020-01-10 2146
-
Python编程入门讲解PPT2020-07-08 1615
-
详谈Python的数据模型和对象模型2021-02-10 3436
-
python的经典实例相关讲解2021-03-02 1087
-
快速找出高价值用户,3分钟学会RFM模型分析2021-09-04 2571
-
Python非常详细编程笔记讲解2021-04-19 1017
-
python实验指导书模板讲解2021-05-25 1287
-
CRM客户关系管理分析模型——RFM模型2022-08-10 2526
-
如何用python实现RFM建模2023-11-02 1991
-
Python编程语言属于什么语言2023-11-22 3598
-
python语言特点有哪些2023-11-29 3266
全部0条评论

快来发表一下你的评论吧 !
