

如何用python爬取抖音app数据
描述
记录一下如何用python爬取app数据,本文以爬取抖音视频app为例。
编程工具:pycharm app
抓包工具:mitmproxy app
自动化工具:appium
运行环境:windows10
思路:
假设已经配置好我们所需要的工具
1、使用mitmproxy对手机app抓包获取我们想要的内容
2、利用appium自动化测试工具,驱动app模拟人的动作(滑动、点击等)
3、将1和2相结合达到自动化爬虫的效果
# mitmproxy/mitmdump抓包
确保已经安装好了mitmproxy,并且手机和PC处于同一个局域网下,同时也配置好了mitmproxy的CA证书,网上有很多相关的配置教程,这里我就略过了。
因为mitmproxy不支持windows系统,所以这里用的是它的组件之一mitmdump,它是mitmproxy的命令行接口,可以利用它对接我们的Python脚本,用Python实现监听后的处理。
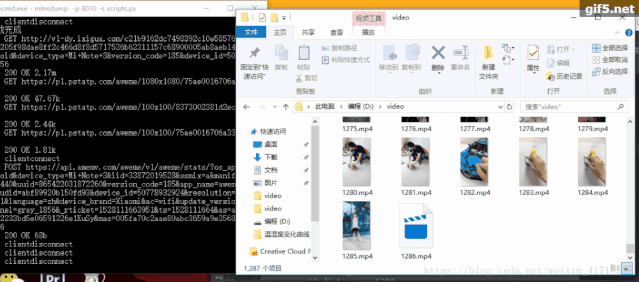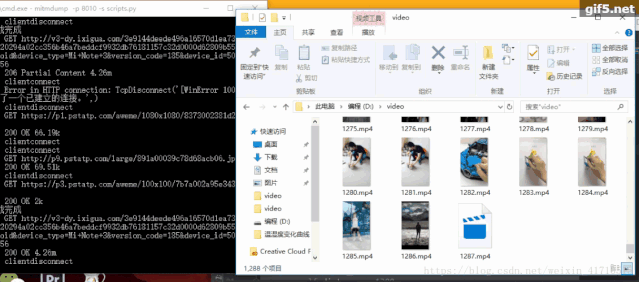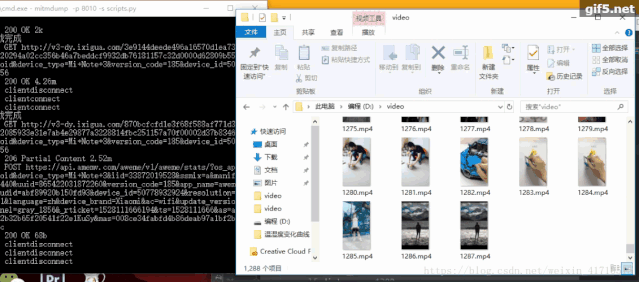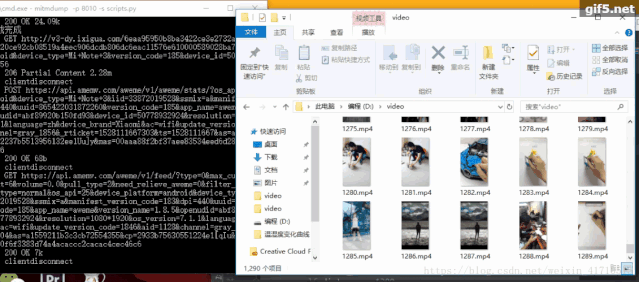
在配置好mitmproxy之后,在控制台上输入mitmdump并在手机上打开抖音app,mitmdump会呈现手机上的所有请求,如下图
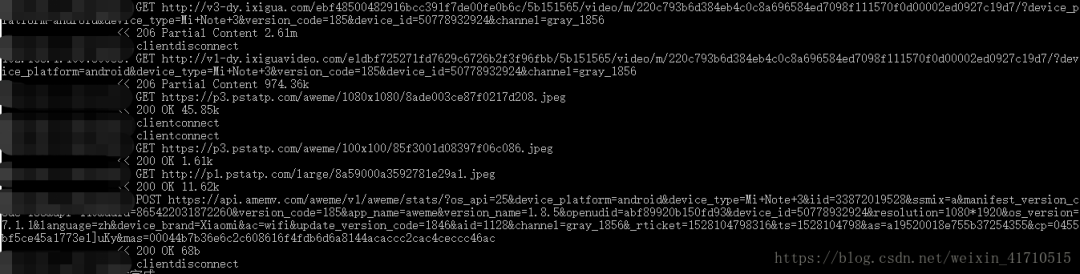
可以在抖音app一直往下滑,看mitmdump所展示的请求,会发现前缀分别为
http://v1-dy.ixigua.com/;http://v3-dy.ixigua.com/;http://v9-dy.ixigua.com/ 这3个类型前缀的url正是我们的目标抖音视频url。
那接下来就要编写python脚本将视频下载下来,需要使用 mitmdump -s scripts.py(此处为python文件名)来执行脚本。
import requests# 文件路径path = 'D:/video/'num = 1788 def response(flow): global num # 经测试发现视频url前缀主要是3个 target_urls = ['http://v1-dy.ixigua.com/', 'http://v9-dy.ixigua.com/', 'http://v3-dy.ixigua.com/'] for url in target_urls: # 过滤掉不需要的url if flow.request.url.startswith(url): # 设置视频名 filename = path + str(num) + '.mp4' # 使用request获取视频url的内容 # stream=True作用是推迟下载响应体直到访问Response.content属性 res = requests.get(flow.request.url, stream=True) # 将视频写入文件夹 with open(filename, 'ab') as f: f.write(res.content) f.flush() print(filename + '下载完成') num += 1 代码写得比较粗糙,不过基本的逻辑还是比较清晰的,这样我们就可以把抖音的视频下载下来,不过这个方法有个缺陷,就是获取视频需要人来不断地滑动抖音的下一个视频,这时候我们可以用一个强大的appium自动化测试工具来解决。
# Appium对手机进行模拟操作
确保已经配置好appium所依赖的环境Android和SDK,网上也有许多教程,这里我就不说了。 appium的用法很简单,首先我们先打开appium,启动界面如下

点击Start Server按钮即可启动appium服务
将Android手机通过数据线与PC相连,同时打开USE调试功能,可以输入adb命令(具体可以去网上查找)测试连接情况,若出现以下结果,则说明连接成功

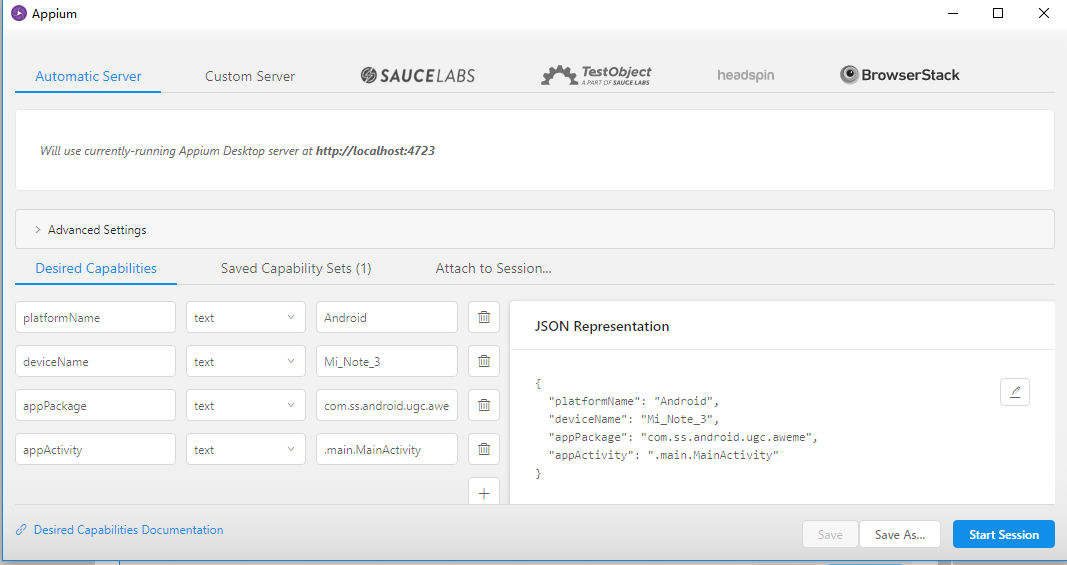
model是设备名,后面配置需要用到。之后点击下图箭头所指的按钮就会出现一个配置页面
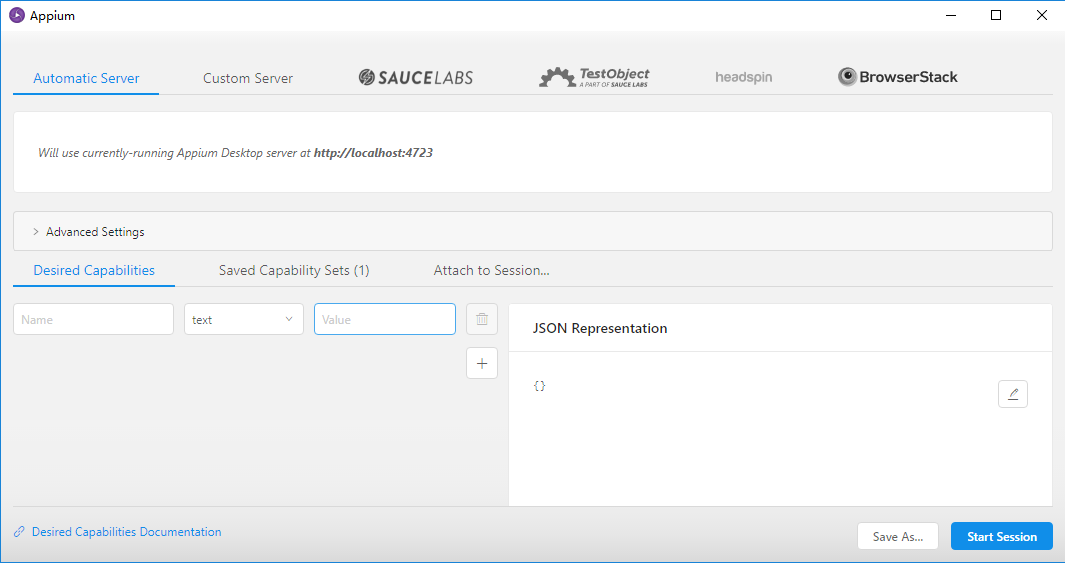
在右下角的JSON Representation配置启动app的Desired Capabilities参数,分别是paltformName、deviceName、appPackage、appActivity。
platformName:平台名称,一般是Android或iOS.
deviceName:设备名称,手机的具体类型
appPackage:App程序包名
appActivity:入口Activity名,通常以.开头
platformName和deviceName比较容易获得,而appPackage和appActivity这两个可以通过以下方法获取到。 在控制台上输入 adb logcat>D:log.log 命令,并且在手机打开抖音app,然后在D盘中打开log.log文件,查找Displayed关键字
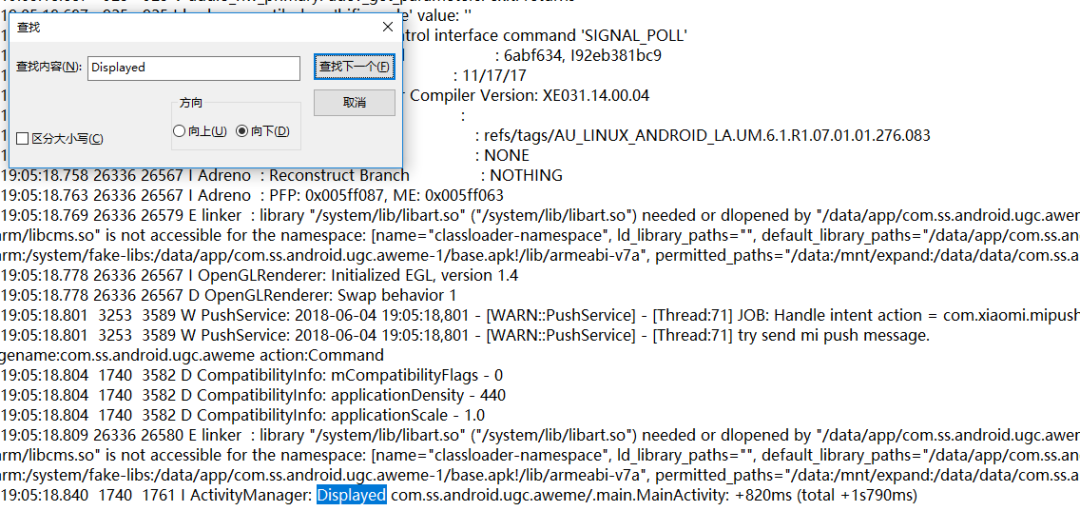
由上图可以知道Displayed后面的 com.ss.android.ugc.aweme对应的是appPackage,.main.MainActivity对应的是appActivity,最后我们的配置结果如下:
{ "platformName": "Android", "deviceName": "Mi_Note_3", "appPackage": "com.ss.android.ugc.aweme", "appActivity": ".main.MainActivity"} 再点击Start Session即可启动Android手机上的抖音app并进入到启动页面,同时PC上会弹出一个调试窗口,从这个窗口可以预览当前手机页面,还可以对手机模拟各种操作,在本文不是重点,所以略过。
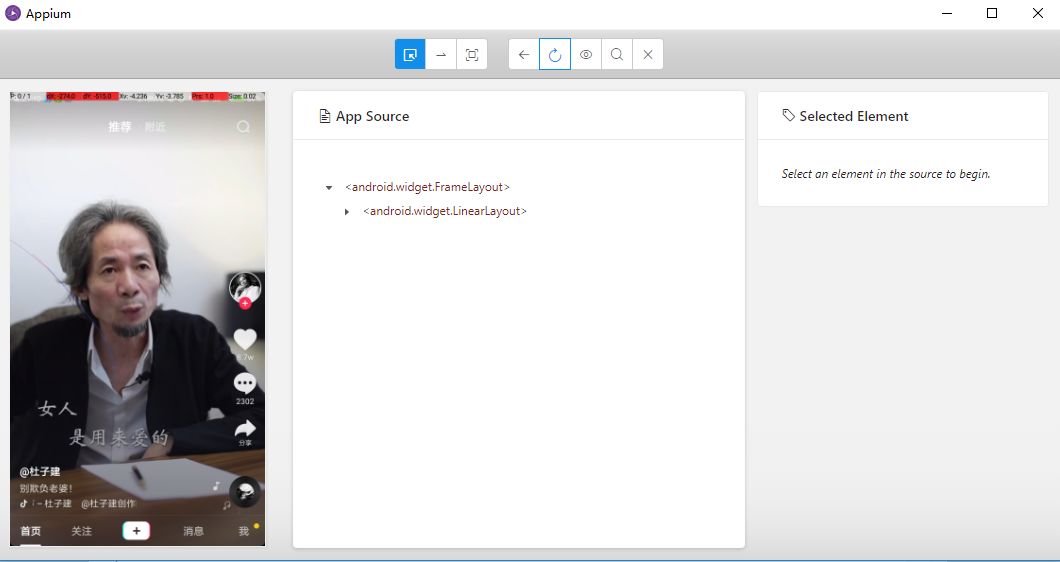
在下面我们将使用python脚本来驱动app,直接在pycharm运行即可
from appium import webdriverfrom time import sleep class Action(): def __init__(self): # 初始化配置,设置Desired Capabilities参数 self.desired_caps = { "platformName": "Android", "deviceName": "Mi_Note_3", "appPackage": "com.ss.android.ugc.aweme", "appActivity": ".main.MainActivity" } # 指定Appium Server self.server = 'http://localhost:4723/wd/hub' # 新建一个Session self.driver = webdriver.Remote(self.server, self.desired_caps) # 设置滑动初始坐标和滑动距离 self.start_x = 500 self.start_y = 1500 self.distance = 1300 def comments(self): sleep(2) # app开启之后点击一次屏幕,确保页面的展示 self.driver.tap([(500, 1200)], 500) def scroll(self): # 无限滑动 while True: # 模拟滑动 self.driver.swipe(self.start_x, self.start_y, self.start_x, self.start_y-self.distance) # 设置延时等待 sleep(2) def main(self): self.comments() self.scroll() if __name__ == '__main__': action = Action() action.main()下面是爬虫的过程。ps:偶尔会爬取到重复的视频
原文标题:实战:带你用Python爬取抖音app视频
文章出处:【微信公众号:马哥Linux运维】欢迎添加关注!文章转载请注明出处。
声明:本文内容及配图由入驻作者撰写或者入驻合作网站授权转载。文章观点仅代表作者本人,不代表电子发烧友网立场。文章及其配图仅供工程师学习之用,如有内容侵权或者其他违规问题,请联系本站处理。
举报投诉
-
python2018-09-21 2185
-
基于Python3对携程网页上北京五星级酒店列表的爬取2019-04-19 2750
-
基于Python实现一只小爬虫爬取拉勾网职位信息的方法2019-05-17 3087
-
python爬取音频文件的步骤2019-08-22 1720
-
Python爬取豆瓣电影信息和存储数据库2020-03-11 3286
-
Python 爬取CSDN的极客头条2018-03-21 5702
-
《2018抖音大数据报告》见证国民娱乐短视频APP诞生2019-07-29 3909
-
抖音对数据造假等各类违规行为进行实时拦截2020-12-01 6724
-
抖音支付在抖音APP内正式上线2021-01-19 5811
-
Python怎么玩转JS脚本2023-02-23 2469
-
Scrapy怎么爬取Python文件2023-02-24 1522
-
抖音电商 API 接口:开启抖音小店直播带货数据新洞察2025-08-20 1690
全部0条评论

快来发表一下你的评论吧 !
