

万能的prompt还能做可控文本生成
描述
可控文本生成,旨在让语言模型的输出带有我们想要的某种属性。比如情感、主题、三元组等。一般我们习惯采用 CTRL[1] 或者 PPLM[2] 等方式。但是,CTRL 是对整个语言模型进行 Finetuning, PPLM 因为需要在生成的过程中迭代更新 hidden activations,所以推理速度非常慢。
随着 Prompting 技术的大火,我们一直在思考,Prompt 究竟能够带来什么?我们都说,Prompt 本质上是一种激发语言模型中知识的手段。因此,它应该不仅仅局限于数据集或者说任务的层面,激发模型对于某个任务的“知识”,还应该扩展到范围更广的控制属性层面,激发模型对于某种输出属性的 sense !
于是,我们不妨把视角从 task scaling 挪开,更多地关注一下 Prompt 对于可控性的 buff 加成。
今天的这篇文章来自 UCSB 和微软,提出通过对比学习的方法找寻到了这个 buff 一般的 Prompt,能够“调教”我们的语言模型进行可控的生成。
论文标题:
Controllable Natural Language Generation with Contrastive Prefixes
论文作者:
Jing Qian, Li Dong, Yelong Shen, Furu Wei, Weizhu Chen
论文链接:
https://arxiv.org/abs/2202.13257
模型方法
首先明确一个概念:Prefix。读者可以简单看一下 Prefix-Tuning[3] 的方法图,就大概知道:Prefix 相当于一种控制指令,加在输入的最前面,以控制生成文本的属性。
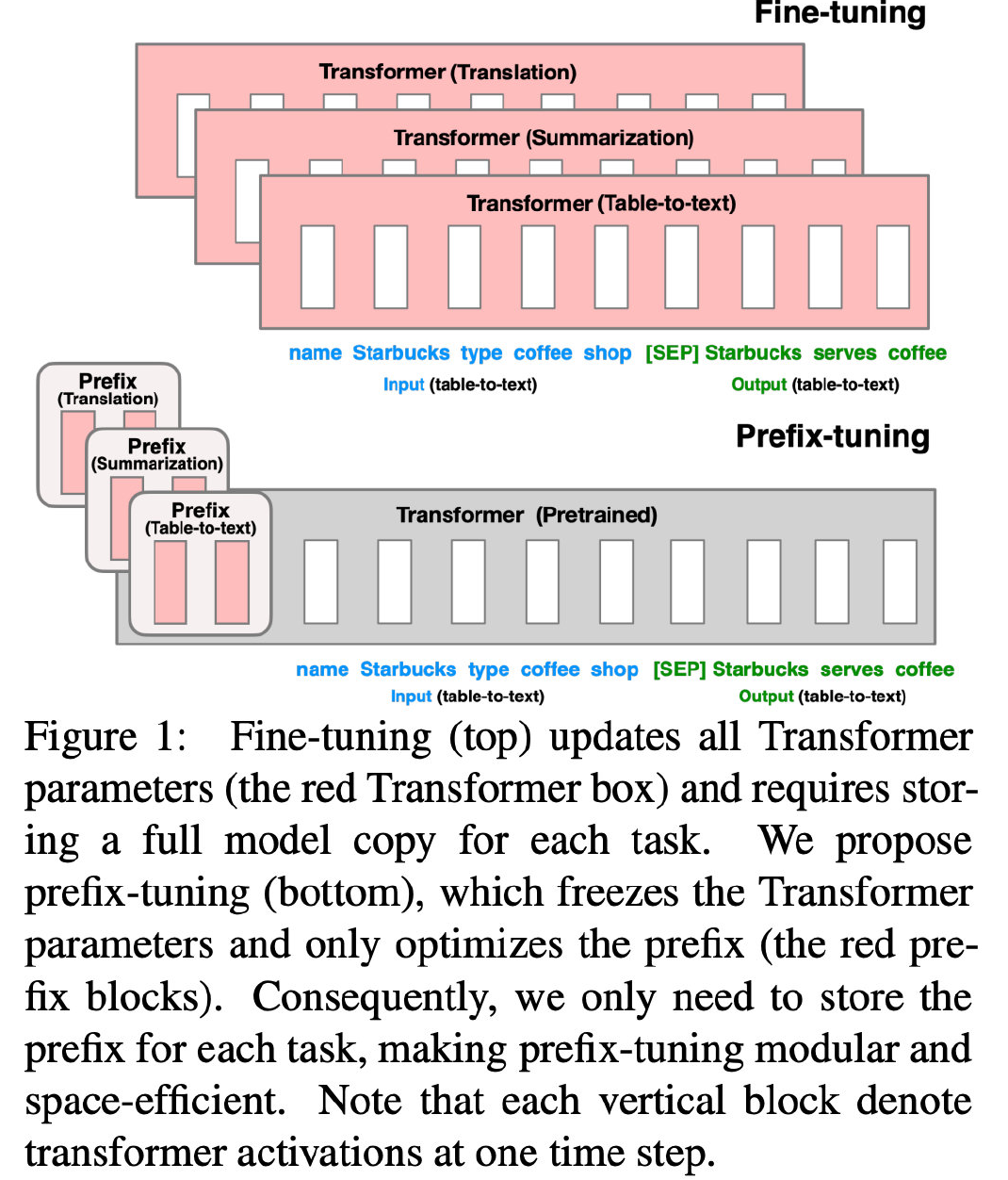
本文提出了两种方法,分别是监督方法和无监督方法。
下面的方法介绍以 Sentiment Control 为例(即生成给定带有情感的文本)。该任务要训练的,正是 positive 和 negative 的两种情感类别所对应的 prefix.
监督方法

整个训练过程和 Prefix-Tuning[3] 相似,LM 的参数是冻结的,只调整 Prefix 相关联的参数。在训练的时候,除了LM loss 之外,新增一个判别损失:
其中, 代表生成文本, 代表控制信号的类别(positive 或 negative)。
无监督方法
在监督方法中,控制信号是已知的。实际场景中还会常常出现控制信号未知的情况,因此需要通过变分的无监督方法找到这个“虚拟的类别信号“并使用 latent variable 表征,即 VQ-VAE[4] 的思想。
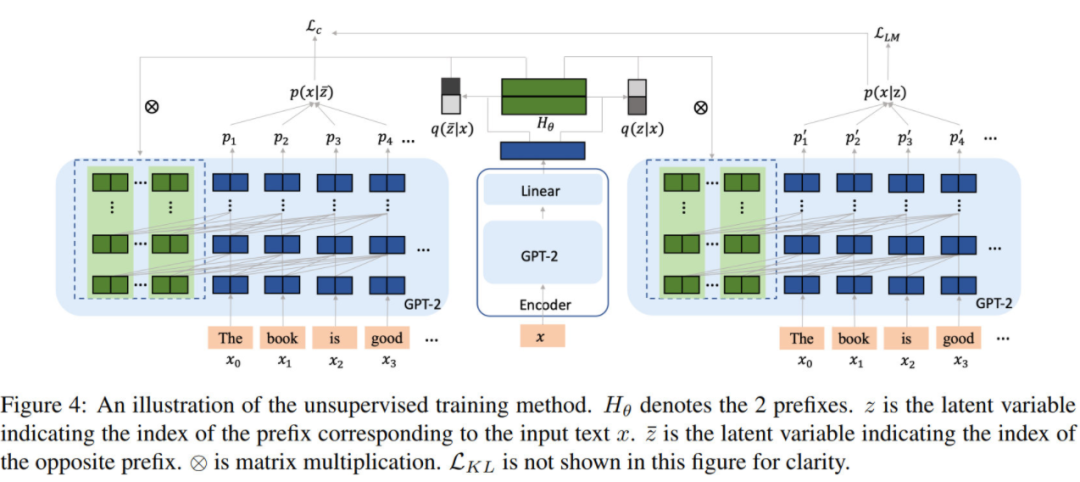
如图,需要先通过一个 encoder 预测相应输入对应的 latent variable 作为 prefix index(指代当前要使用哪个 prefix)。设 prefix index 为 ,则这个 encoder 就是要学习 这个分布。
一方面,除了 LM loss ,还需要保证后验概率 或 尽可能的准确,故引入 KL 散度:
这里的 假设是 uniform distribution。其中,
GS 表示 Gumbel Softmax, 是 GS 的 temperature 参数。
关于这块儿的详细原理,就是我们小学二年级就学过的 EM 算法啦~
帮读者回忆一下:
......
另外,作者又提出了一个无监督对比损失:其中, 和 是根据 decoder 的文本生成概率得到的,具体计算方式如下:
最后总的损失函数为 ,, 的加权求和,
实验结果
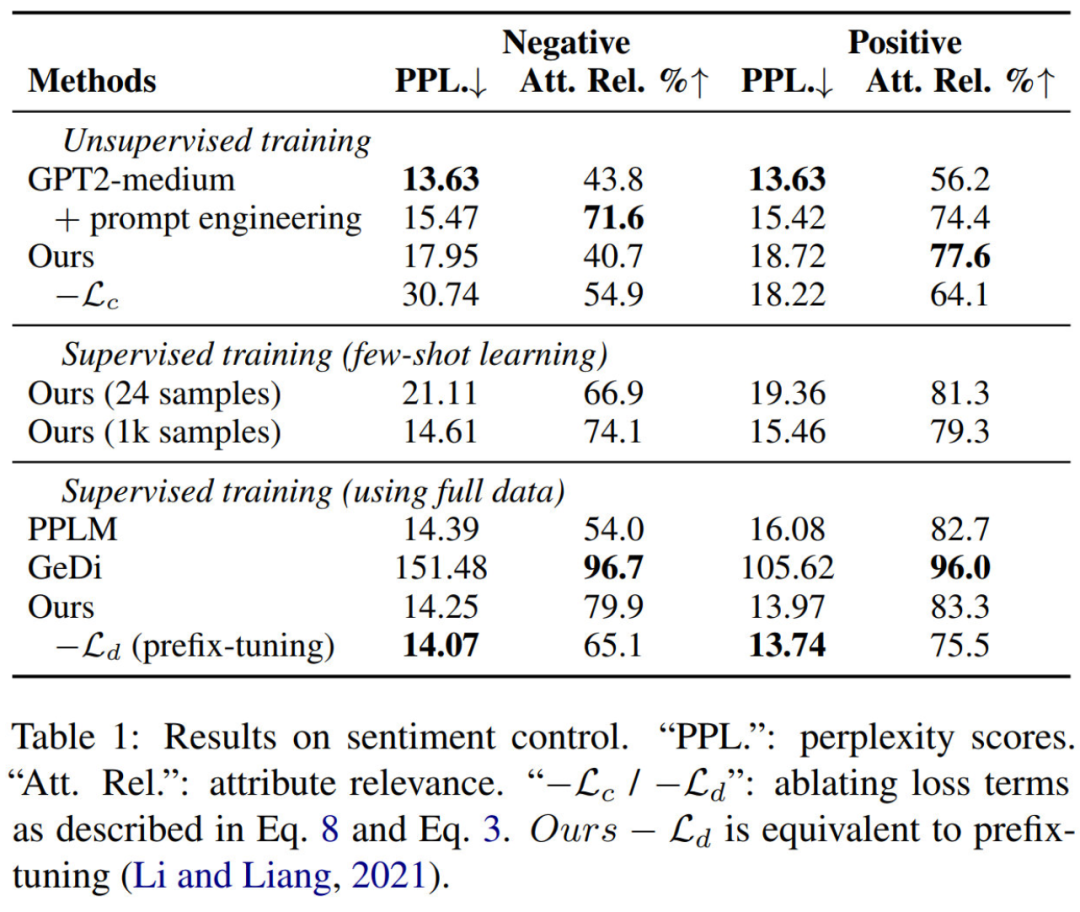
Sentiment Control
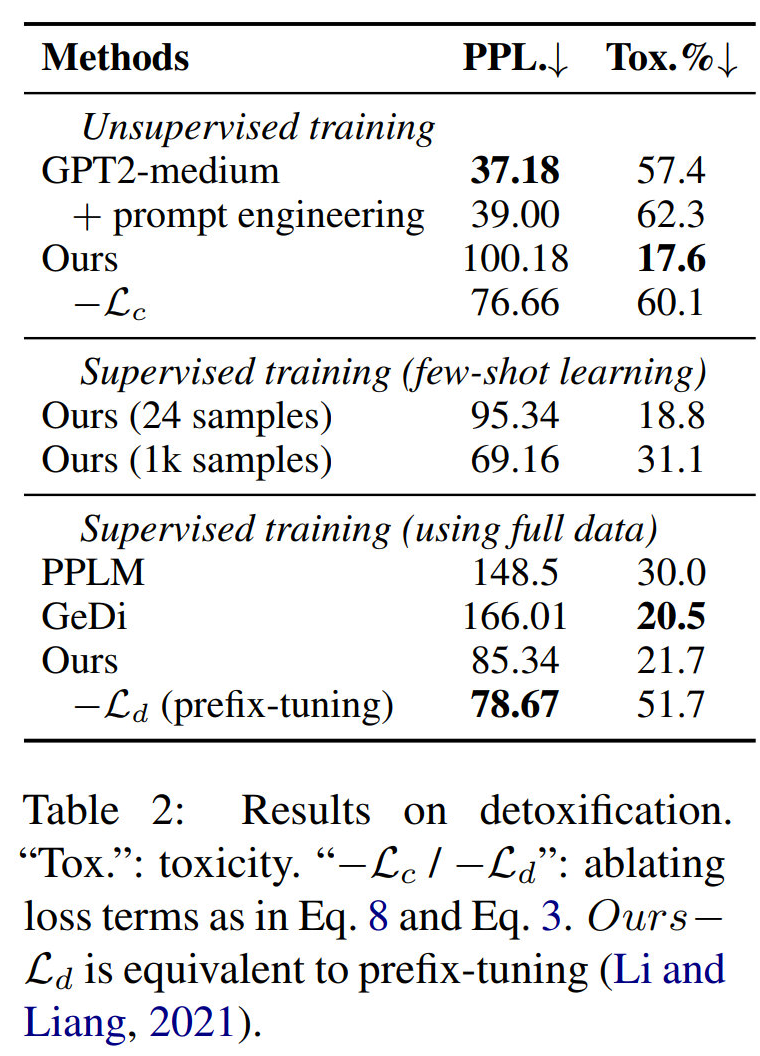
Detoxification
Topic Control
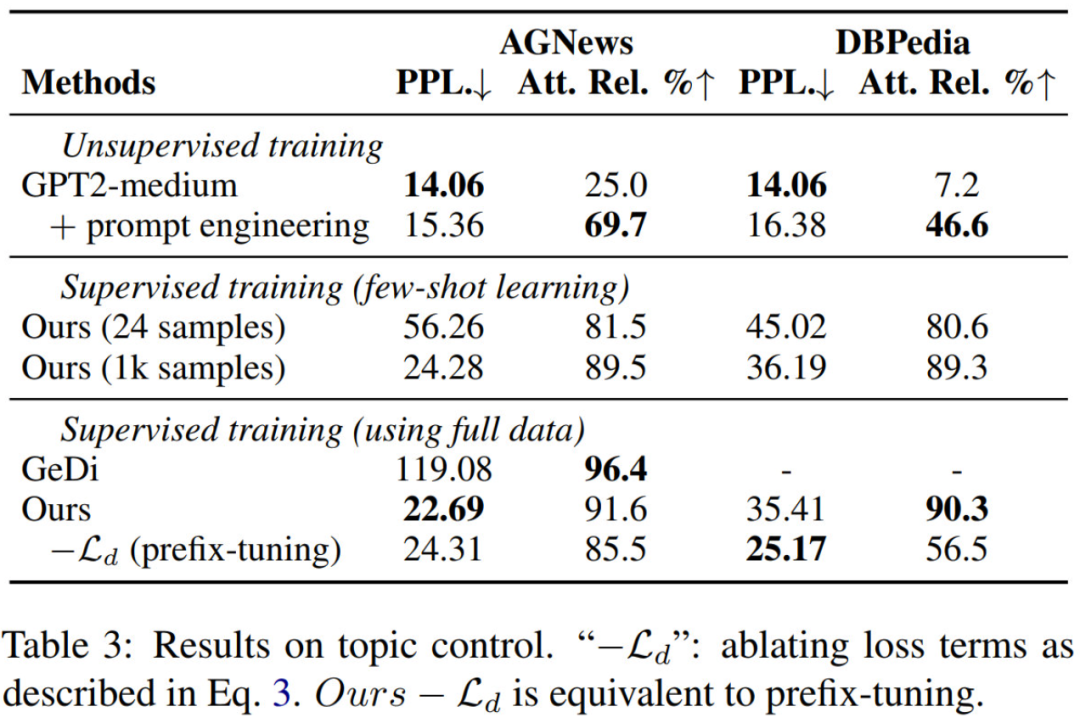
推理速度
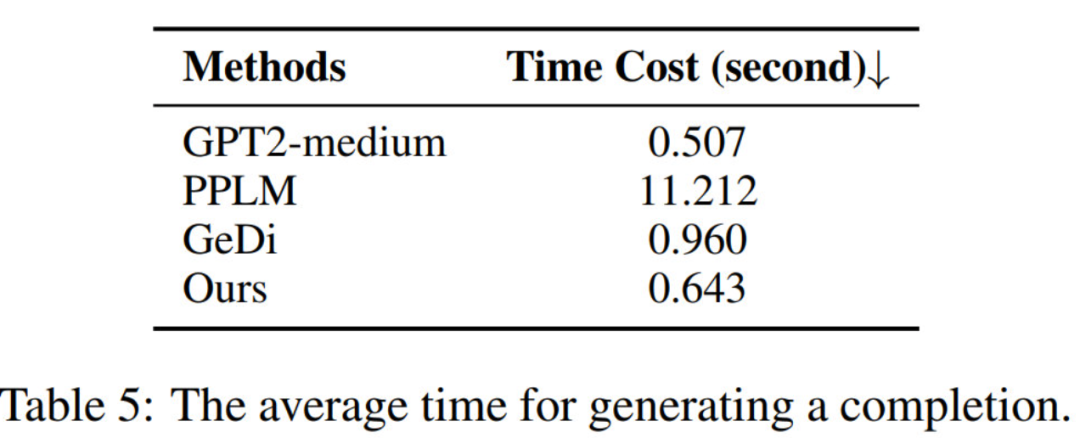
Multi-Aspect Control
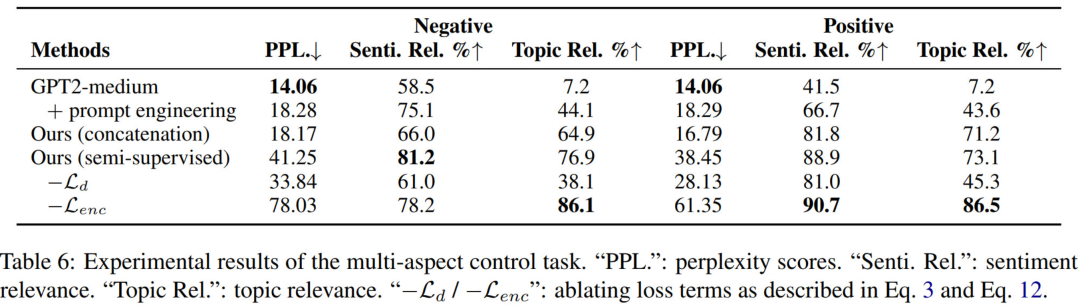
实际场景中,很少有 multi-aspect labeled data,只有 single-aspect labeled data.
本文使用了两种方式来解决多种属性的可控生成问题:
Ours (concatenation):使用 single-aspect labeled data 分别训练各自的 prefix, 然后在 multi-aspect control 任务中将其拼接起来。
Ours (semi-supervised):同时训练 multi-aspect prefixes, 在训练时把 single-aspect labeled example 当做 partially labeled. 此外,multi-aspect prefixes 经过了 trained single-aspect prefixes 的初始化。
Ours (semi-supervised) 是上述监督方法和无监督方法的组合,因此架构图和无监督方法的图是一样的。
写在最后
这里也推荐读者品读一下 DeepMind & ICL 的相似工作:Control Prefixes [5].
古人云:“君子生非异也,善假于物也”。我们把语言模型比作“人”,把可控性比作“物”,也许,大大小小的语言模型在能力的本质上并没有什么不同,但是如果可以通过不同的 Control Prefixes,假之以物,则语言模型可成“君子”也!(哈哈,搞一个俏皮的比喻~)
无论是本文介绍的 Contrastive Prefixes 也好,还是 Control Prefixes 也好,我们都可以从中发现 Prompt 对于”调教“语言模型的伟大能力。从 task 到 controllability, 可能会是 prompt 向前发展的又一个新阶段吧~
审核编辑 :李倩
-
万里红文本生成算法通过国家网信办备案2025-11-14 899
-
HarmonyOSAI编程万能卡片生成(一)2025-09-08 141
-
效率大升!AI赋能鸿蒙万能卡片开发2025-01-13 1999
-
如何使用 Llama 3 进行文本生成2024-10-27 1940
-
面向结构化数据的文本生成技术研究2023-06-26 1675
-
基于文本到图像模型的可控文本到视频生成2023-06-14 2066
-
基于VQVAE的长文本生成 利用离散code来建模文本篇章结构的方法2022-12-01 2900
-
基于GPT-2进行文本生成2022-04-13 5954
-
受控文本生成模型的一般架构及故事生成任务等方面的具体应用2021-10-13 4932
-
文本生成任务中引入编辑方法的文本生成2021-07-23 2708
-
万能转换开关原理_万能转换开关结构2019-12-09 11804
-
万能钥匙字典生成工具.exe2014-04-09 1191
-
电子万能试验机与液压万能试验机的区别2013-07-04 3469
-
万能遥控器设置方法_万能遥控器代码2012-09-14 192648
全部0条评论

快来发表一下你的评论吧 !
