

一种全新易用的基于Word-Word关系的NER统一模型
描述
总体说一下
NER任务大概分为三种:flat, overlapped, and discontinuousNER,如下图所示:
aching in legs 为flat NER
aching in shoulders为discontinuous NER
aching in legs和aching in shoulders这两个实体共同重复了aching in,为overlapped NER
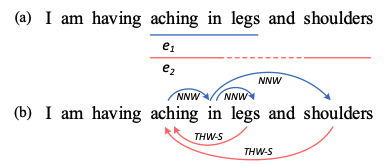
最近的研究都在考虑如何通过一个大一统模型一次性解决这三种问题。目前的最佳的方法基本都是基于span-based和seq2seq的,然而span-based方法主要倾向于通过枚举所有span组合来解决边界问题,时间复杂度上是个问题;而后者大家都知道,存在错误传播。 所以,本文提出了一种新颖的方式和框架来解决所有的NER问题:通过预测word-word之间的关系(这里称之为W2NER)。其中word与word之间的关系主要有三种:
NNW: Next-Neighboring-Word,预测与后面词的关系
THW-*: Tail-Head-Word-* ,预测与前面词的关系,其中*表示具体关系(ORG、PER等)
NONE:表示没有关系
其中,本文采用一个多粒度2D图来表示word之间的关系,如下图,其中为了解决图的稀疏性,而将这两种关系放到一个图里,一个在右上角,一个在左下角。
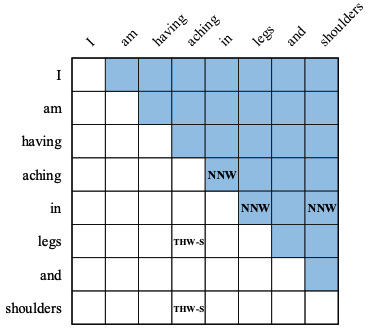
最终在14个公开数据集(包含中文和英文)上做了大量实验,并都取得了最佳值,也成为了最新的SoTA。
模型
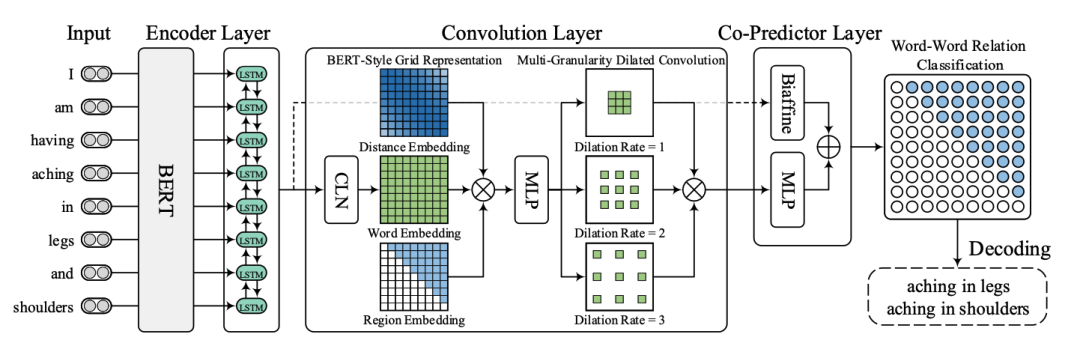
一下子看,感觉模型想是一堆模块堆积而成,其实细读论文会发现这些模型都是由NER的前人经验而来,有理有据。 具体来看,大概分为三个模块: Encoder Layer通过BERT获取表示信息,然后通过LSTM获取上下文信息。 Convolution Layer这里有一个CLN(Conditional Layer Normalization)层,主要用来获得word j在word i前提下的表示:
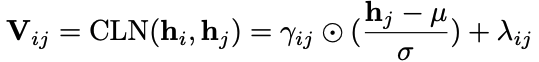
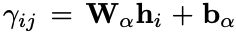
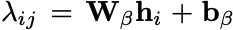
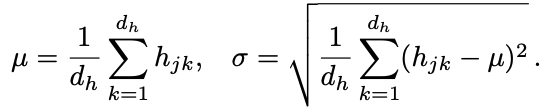
然后是BERT-Style Grid Representation层,这里主要是模型BERT的3个embedding层而来,这里的三个表示层为信息表示、关系位置信息表示和位置域表示组成,通过MLP融合到一起。 然后通过多粒度的空洞卷积(Multi-Granularity Dilated Convolution)采样不同的信息。 Co-Predictor Layer这里用了一个普通的MLP和一个专门用于变长标签预测的biaffine预测:
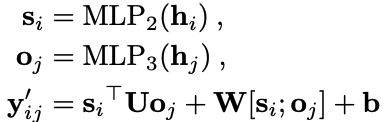
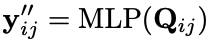 最后过一个softmax层:
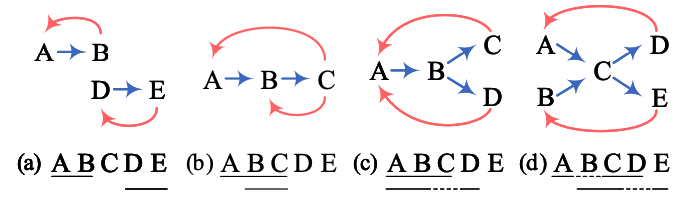
最后过一个softmax层: 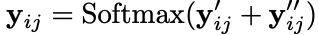 最后是一个Decoder层,这里主要就是通过NNW和HTW-*构成一个环的部分就是一个实体,比如下面这个例子就解释了所有情况:
最后是一个Decoder层,这里主要就是通过NNW和HTW-*构成一个环的部分就是一个实体,比如下面这个例子就解释了所有情况:
损失的话,就简单了:
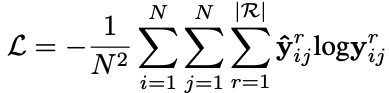
实验
英文flat数据集:
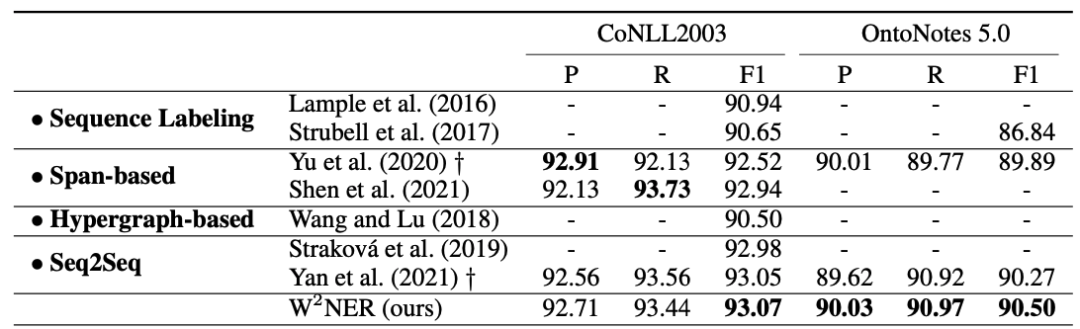
中文flat数据集:

英文overlapped数据集:
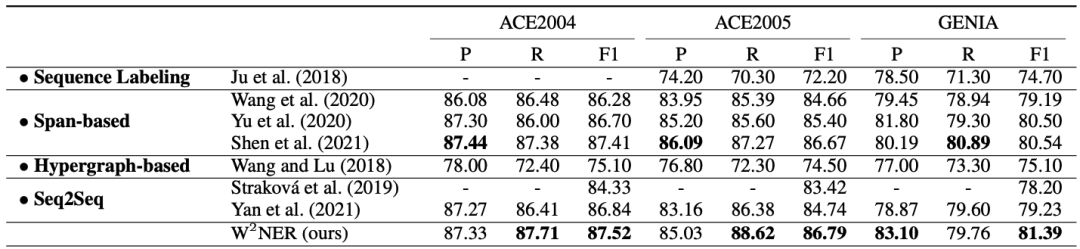
中文overlapped数据集,F1性能:
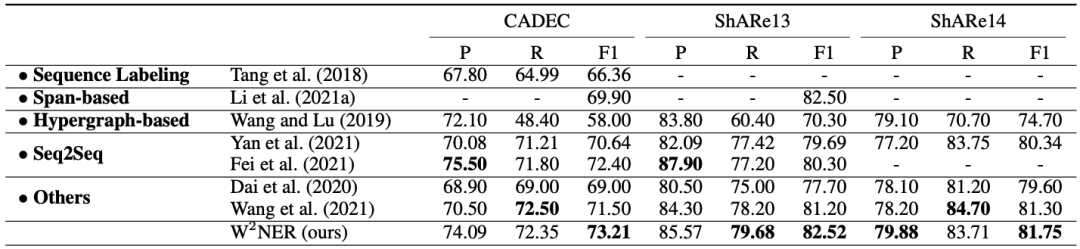
英文discontinuous数据集:
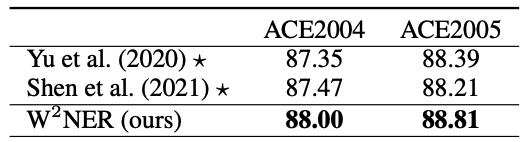
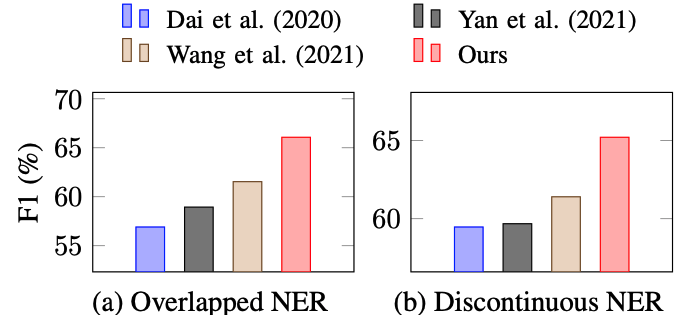
和前沿最佳论文作对比:
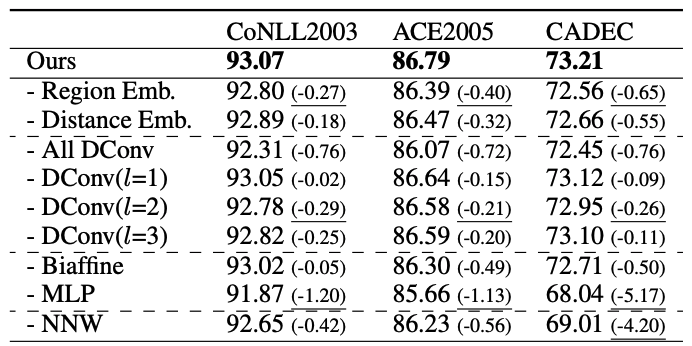
消融实验,F1性能:
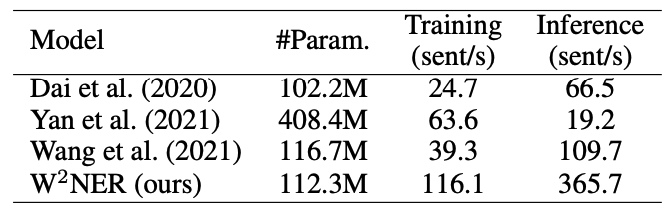
训练速度和推理速度都得到了极大提升:
这篇文章还是非常不错的,是一个简单有效的NER新框架,可以较为轻松的应用于线下。
审核编辑 :李倩
-
Spire.Cloud.Word云端Word文档处理SDK介绍2025-02-11 1299
-
如何使用Python读取写入Word文件2023-09-27 3367
-
一些常见的Word应用试卷输入方法2020-12-08 4962
-
复制Simulink中的仿真模型到word的方法小结2018-07-06 8789
-
VC上机指导WORD文档2017-03-04 792
-
Office Word、Excel和PowerPoint 文2010-07-06 1598
-
如何用Word调用Protel For DOS绘制的图形2010-03-09 1798
-
一种快速Word编程接口的设计与实现2010-02-21 677
-
Word人工双面打印2009-12-29 2516
-
《微机原理及应用》课程教程 (word文档)2009-09-16 1096
-
一种基于Word文档的数字密写设计与实现2009-08-04 616
-
word/word2003上次启动失败,以安全模式启动的解决2009-08-03 4409
-
Microsoft Office Word、Excel 和2009-02-12 1369
-
word如何去删除水印2008-01-26 6532
全部0条评论

快来发表一下你的评论吧 !
