

在机器学习领域,数据和模型哪个更重要
描述
在机器学习领域,数据重要还是模型重要?这是一个很难回答的问题。
模型和数据是 AI 系统的基础,这两个组件在模型的开发中扮演着重要的角色。
人工智能领域最权威的学者之一吴恩达曾提出「80% 的数据 + 20% 的模型 = 更好的机器学习」,他认为一个团队研究 80% 的工作应该放在数据准备上,数据质量是重要的,但很少有人在乎。如果更多地强调以数据为中心而不是以模型为中心,机器学习会发展的更快。
我们不禁会问,机器学习的进步是模型带来的还是数据带来的,目前还没有一个明确的答案。
在本文中,Android 开发者和机器学习爱好者 Harshil Patel 介绍了「机器学习:以数据为中心 VS 以模型为中心」,通过对比以确定两者中哪个更重要,此外,Patel 还介绍了如何使用以数据为中心的基础设施。
以数据为中心的方法 VS 以模型为中心的方法
以模型为中心的方法意味着需要通过实验来提高机器学习模型性能,这涉及模型架构的选择、训练过程。而在以模型为中心的方法中,你需要保持数据相同,通过改进代码和模型架构来提高性能。此外,对代码的改进是以模型为中心的根本目标。
目前,大多数 AI 应用都是以模型为中心的,其中一个可能的原因是学术研究非常重视 AI 领域。根据吴恩达的说法,AI 领域 90% 以上的研究论文都是以模型为中心的,因为我们很难创建大型数据集,使其成为公认的标准。因此,AI 社区认为以模型为中心的机器学习更有前景。研究者在专注于模型的同时,往往会忽略数据的重要性。
对于研究者而言,数据是每个决策过程的核心,以数据为中心的公司通过使用其运营产生的信息,可以获得更准确、更有条理、更透明的结果,从而可以帮助公司组织更顺利地运行。以数据为中心的方法涉及系统地改进、改进数据集,以提高 ML 应用程序的准确性,对数据进行处理是以数据为中心的中心目标。
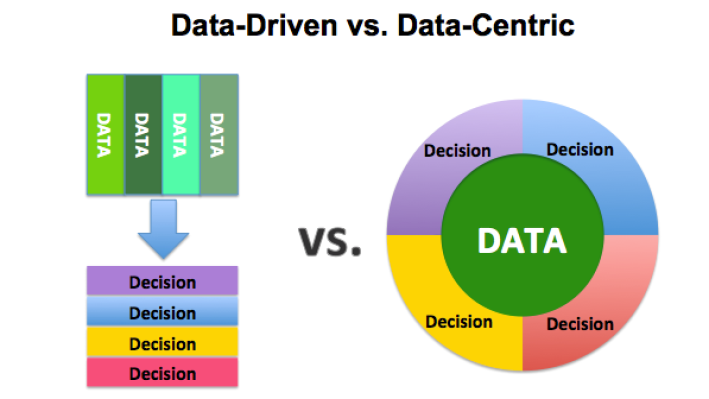
数据驱动 VS 以数据为中心
许多人经常混淆「以数据为中心」和「数据驱动」这两个概念。数据驱动是一种从数据中收集、分析和提取见解的方法,它有时被称为「分析」。另一方面,以数据为中心的方法侧重于使用数据来定义应该首先创建的内容;而以数据为中心的架构指的是一个系统,其中数据是主要和永久的资产。数据驱动架构意味着通过利用大量数据来创建技术、技能和环境。
对于数据科学家和机器学习工程师来说,以模型为中心的方法似乎更受欢迎。这是因为从业者可以利用自身知识储备来解决特定问题。另一方面,没有人愿意花大量时间去标注数据。
然而,在当今的机器学习中,数据至关重要,但在 AI 发展中却经常被忽视和处理不当。由于数据错误,研究者可能花费大量时间进行查错。模型精度较低的根本原因可能不是来自模型本身,而是来自错误的数据集。

除了关注数据外,模型和代码也很重要。但研究者往往倾向于在关注模型的同时忽略数据的重要性。最好的方法是同时关注数据和模型的混合方法。根据应用程序的不同,研究者应该兼顾数据和模型。
以数据为中心的基础架构
以模型为中心的机器学习系统主要关注模型架构优化及其参数优化。
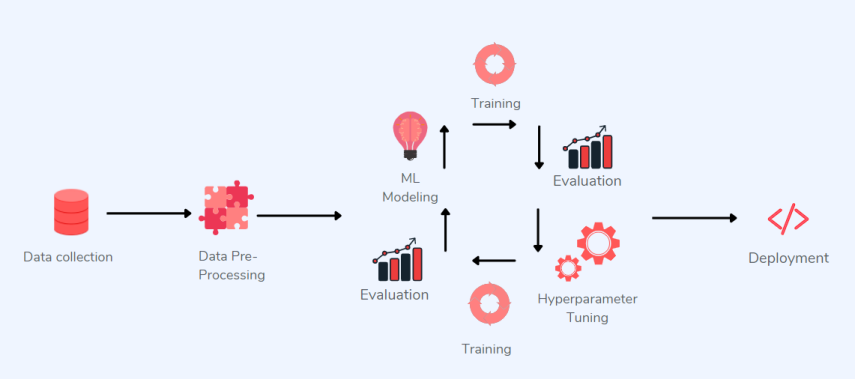
以模型为中心的 ML 应用程序
上图中描述的是以模型为中心的工作流适用于少数行业,如媒体、广告、医疗保健或制造业。但也可能面临如下挑战:
需要高级定制系统:不同于媒体和广告行业,许多企业无法使用单一的机器学习系统来检测其产品的生产故障。虽然媒体公司可以负担得起有一个完整的 ML 部门来处理优化问题,但需要多个 ML 解决方案的制造企业不能按照这样的模板进行实施;
大型数据集的重要性:在大多数情况下,公司没有大量数据可供使用。相反,他们经常被迫处理微小的数据集,如果他们的方法是以模型为中心的,那么这些数据集很容易产生令人失望的结果。
吴恩达曾在他的 AI 演讲中解释了他如何相信以数据为中心的 ML 更有价值,并倡导社区朝着以数据为中心的方向发展。他曾经举了一个「钢铁缺陷检测」的例子,其中以模型为中心的方法未能提高模型的准确率,而以数据为中心的方法将准确率提高了 16%。
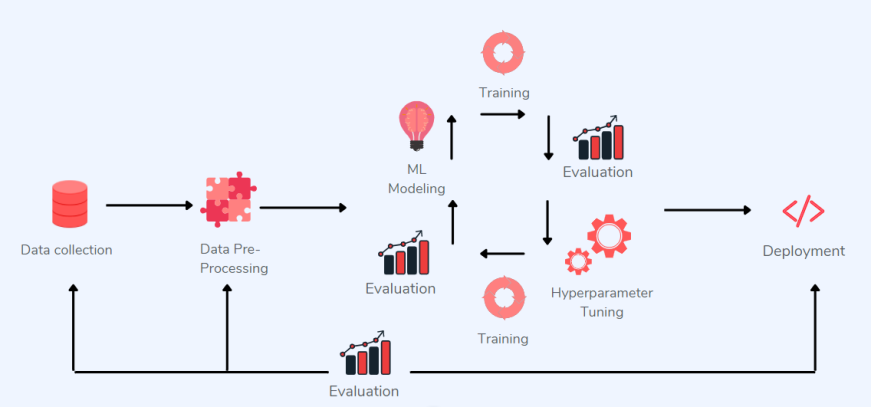
以数据为中心的 ML 应用程序
在实施以数据为中心的架构时,可以将数据视为比应用程序和基础架构更耐用的基本资产。以数据为中心的 ML 使数据共享和移动变得简单。那么,在以数据为中心的机器学习到底涉及什么?在实现以数据为中心的方法时,我们应该考虑以下因素:
数据标签质量:当大量的图像被错误标记时,会出现意想不到的错误,因此需要提高数据标注质量;
数据增强:让有限的数据产生更多的数据,增加训练样本的数量以及多样性(噪声数据),提升模型稳健性;
特征工程:通过改变输入数据、先验知识或算法向模型添加特征,常被用于机器学习,以帮助提高预测模型的准确性;
数据版本控制:开发人员通过比较两个版本来跟踪错误并查看没有意义的内容,数据版本控制是维护数据中最不可或缺的步骤之一,它可以帮助研究者跟踪数据集的更改(添加和删除),版本控制使代码协作和数据集管理变得更加容易;
领域知识:在以数据为中心的方法中,领域知识非常有价值。领域专家通常可以检测到 ML 工程师、数据科学家和标注人员无法检测到的细微差异,ML 系统中仍然缺少涉及领域专家的内容。如果有额外的领域知识可用,ML 系统可能会表现得更好。
应该优先考虑哪一个:数据数量还是数据质量?
需要强调的是,数据量多并不等同于数据质量好。当然,训练神经网络不能只用几张图就能完成,数据数量是一个方面,但现在的重点是质量而不是数量。
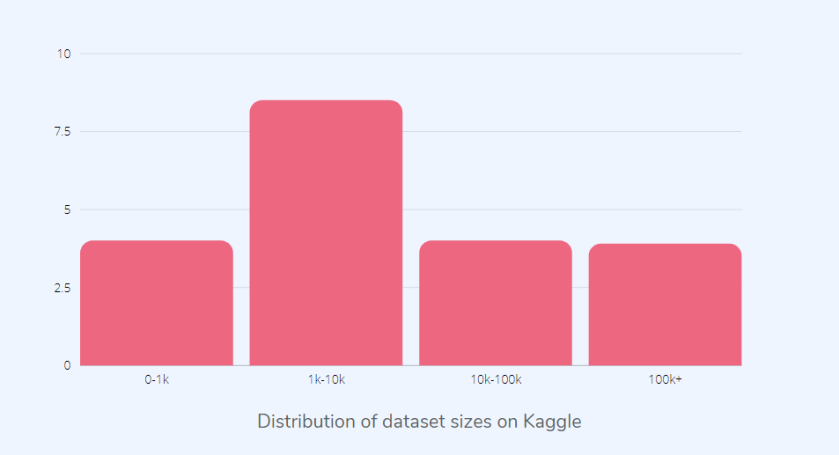
如上图所示,大多数 Kaggle 数据集并没有那么大。在以数据为中心的方法中,数据集的大小并不那么重要,并且可以使用质量较小的数据集完成更多的工作。不过需要注意的是,数据质量高且标注正确。
上图中是另一种标注数据的方式,单独或组合标注。例如,如果数据科学家 1 单独标注菠萝,而数据科学家 2 将其组合标注,则两者标注的数据不兼容,导致学习算法变得混乱。因此,需要将数据标签保持一致;如果需要单独标注,请确保所有标注都以相同的方式进行。

上图为吴恩达解释了小数据集一致性的重要性
到底需要多少数据?
数据质量不可忽视,但数据量也是至关重要的,研究者必须有足够的数据支撑才能解决问题。深度网络具有低偏差、高方差特性,我们可以预见更多的数据可以解决方差问题。但是多少数据才够呢?目前这个问题还很难回答,不过我们可以认为拥有大量的数据是一种优势,但也不是必须的。
如果你采用以数据为中心的方法,请记住以下几点:
确保在整个 ML 项目周期中数据保持一致;
数据标注保持一致;
要及时反馈结果;
进行错误分析;
消除噪声样本。
那么,我们哪里可以找到高质量的数据集?这里推荐几个网站,首先是 Kaggle:在 Kaggle 中,你会找到进行数据科学工作所需的所有代码和数据,Kaggle 拥有超过 50,000 个公共数据集和 400,000 个公共 notebook,可以快速完成任务。
其次是 Datahub.io:Datahub 是一个主要专注于商业和金融的数据集平台。许多数据集,例如国家、人口和地理边界列表,目前在 DataHub 上可用。
最后是 Graviti Open Datasets:Graviti 是一个新的数据平台,主要为计算机视觉提供高质量的数据集。个人开发人员或组织可以轻松访问、共享和更好地管理开放数据。
原文标题:90%论文都是以模型为中心,AI领域,数据和模型到底哪个重要?
文章出处:【微信公众号:智能感知与物联网技术研究所】欢迎添加关注!文章转载请注明出处。
审核编辑:汤梓红
-
在移动电源应用中,电容的高容值和低ESR,哪个对抑制纹波更重要?2025-12-06 4402
-
cmp在机器学习中的作用 如何使用cmp进行数据对比2024-12-17 1844
-
鲁棒性在机器学习中的重要性2024-11-11 3018
-
机器学习模型评估指标2023-09-06 2379
-
gpu和cpu哪个更重要?2023-08-09 10068
-
部署基于嵌入的机器学习模型2022-11-02 3647
-
什么是机器学习? 机器学习基础入门2022-06-21 3103
-
浅谈模拟在机器学习领域的重要性2022-03-15 3878
-
什么是计算机系统?硬件和软件哪个更重要?2021-07-26 2031
-
六个构建机器学习模型需避免的错误2021-05-05 1923
-
手机的处理器和内存哪个更重要2020-05-25 7001
-
CPU和显卡到底哪个更重要2020-05-18 7606
-
PCB设计性能还是制造输出哪个更重要2019-10-28 3308
-
【下载】《机器学习》+《机器学习实战》2017-06-01 199987
全部0条评论

快来发表一下你的评论吧 !
