

cosFormer:重新思考注意力机制中的Softmax
描述
导读:Transformer在自然语言处理、计算机视觉和音频处理方面取得了巨大成功。作为其核心组成部分之一,Softmax Attention模块能够捕捉长距离的依赖关系,但由于Softmax算子关于序列长度的二次空间和时间复杂性,使其很难扩展。
针对这点,研究者提出利用核方法以及稀疏注意力机制的方法来近似Softmax算子,从而降低时间空间复杂度。但是,由于误差的存在,效果往往不尽如人意。
商汤多模态研究组认为,近似操作本身存在的误差使得其效果很难超越Softmax Attention。我们的观点是,与其近似Softmax,不如设计一种方式代替Softmax,并且同时降低时间空间复杂度。
因此,本文提出了名为cosFormer的方法,在时间空间复杂度关于序列长度为线性复杂度的同时,其性能接近或者超越Softmax Attention,并在LRA benchmark上取得SOTA结果。我们的设计核心理念基于两点,首先是注意力矩阵的非负性,其次是对局部注意力的放大(非极大值抑制)。
本文主要介绍已收录于ICLR 2022的一篇文章 cosFormer : Rethinking Softmax in Attention。

Part 1
背景

1. Softmax Attention
为了引出我们的方法,对Softmax Attention的计算方式进行一定的推广:
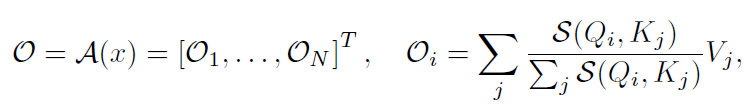
其中 表示相似度计算函数,如果 ,上式即变为Softmax Attention(不考虑除以 的缩放操作)。注意到计算 的时间复杂度为 , 的时间复杂度为 ,所以总时间复杂度为 ,即关于序列长度是二次的。
2. 线性 Attention
通过分析我们发现,性能瓶颈的主要原因是 操作,如果相似度函数可以表示为:
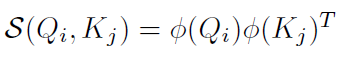
那么:
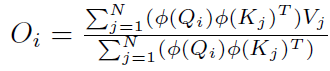
根据矩阵运算的结合律:
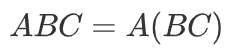
上式可以变换为(编者修正:下方公式未变换,请参照论文):
经过计算后可以得到该方法的时间复杂度为 ,即关于序列长度是一次的。
Softmax Attention和线性Attention的计算方式可以用下图概括:
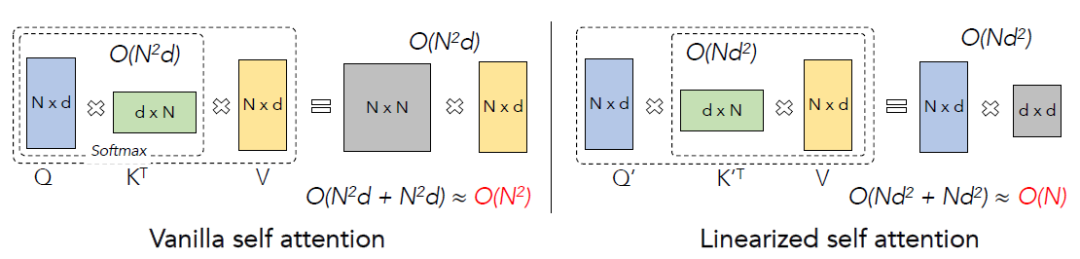
所以接下来将介绍 的选择,以及核心的reweighting操作。
3. Softmax 的两大性质
我们经过分析以及实验,归纳出Softmax Attention中比较重要的性质,这两个性质可以指导我们的模型设计:
1. 注意力矩阵的非负性
2. 局部注意力的放大(非极大值抑制)
对于第一点,我们有如下实验进行验证(模型结构为RoBERTa):
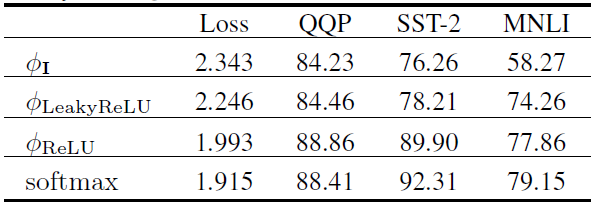
这里Loss表示验证集损失(越低越好),其余指标均为准确率(越高越好)。可以看到,当保证了注意力矩阵的非负性之后,可以达到较好的效果。基于该实验,我们选择 为ReLU函数。
对于第二点,我们的方式是在注意力矩阵中引入先验locality信息,观察Softmax注意力矩阵,如下图所示,我们发现其注意力矩阵的权重在对角线附近很集中:
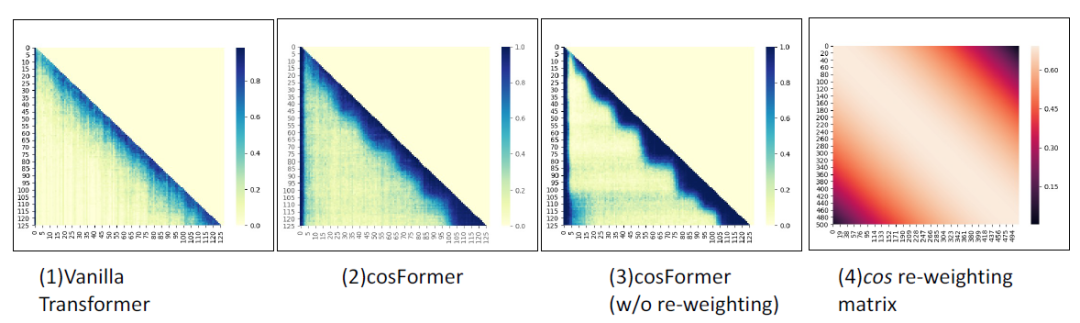
所以我们的方法需要在加了reweighting操作后也更加集中在对角线附近。注意并非所有的有类似权重的函数均适用,这个reweighting的函数需要跟前面的QK一样可以拆分成两个矩阵的乘法的形式。
至此,就可以引入我们的cosFormer了。
Part 2
cosFormer
1. 方法
我们的方法基于线性Attention,首先给出符号定义:
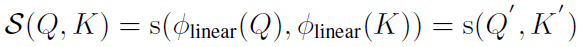
根据之前的分析,我们选择了:
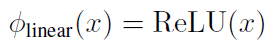
可得:
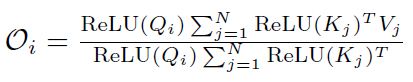
为了进行reweighting操作,并且同时保证线性Attention的计算方式依然成立,我们选择了cos函数:
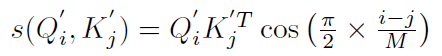
展开可得:
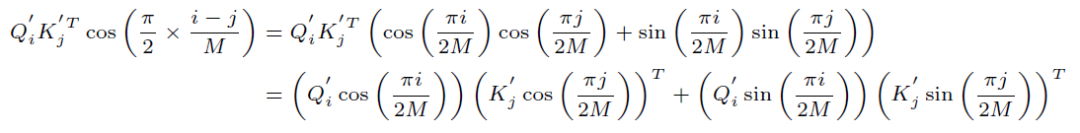
为了便于展示,我们把它记作:
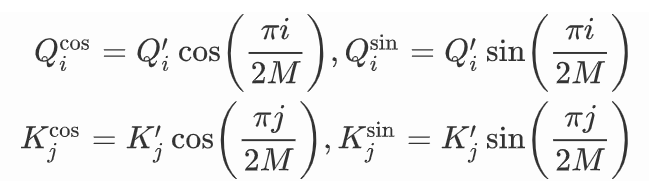
最终得到:
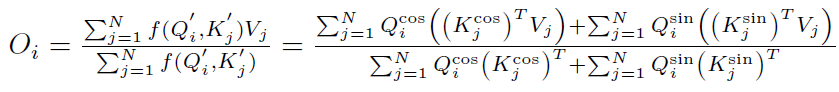
上式和线性Attention的计算方式一致,经过分析不难得出时间复杂度依然是 。
2. 实验结果
我们在单向模型、双向模型以及LRA benchmark上测试了我们的方法,均取得了非常不错的效果。
单向语言模型,指标表示困惑度(越低越好):
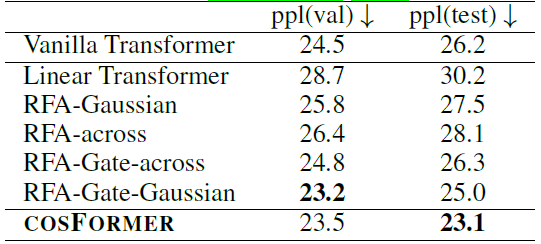
双向语言模型,指标表示准确率(越高越好):

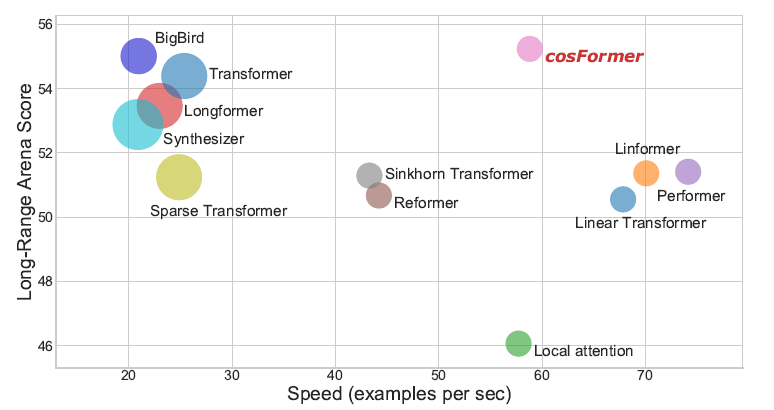
LRA benchmark:
1)性能实验,指标表示准确率(越高越好):
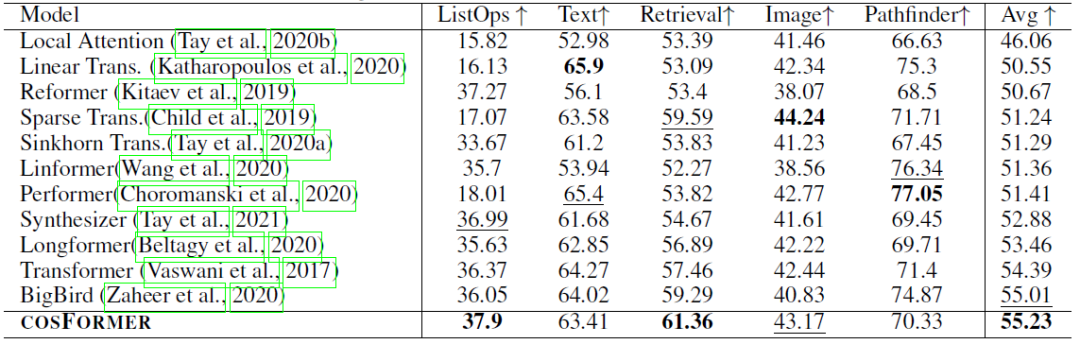
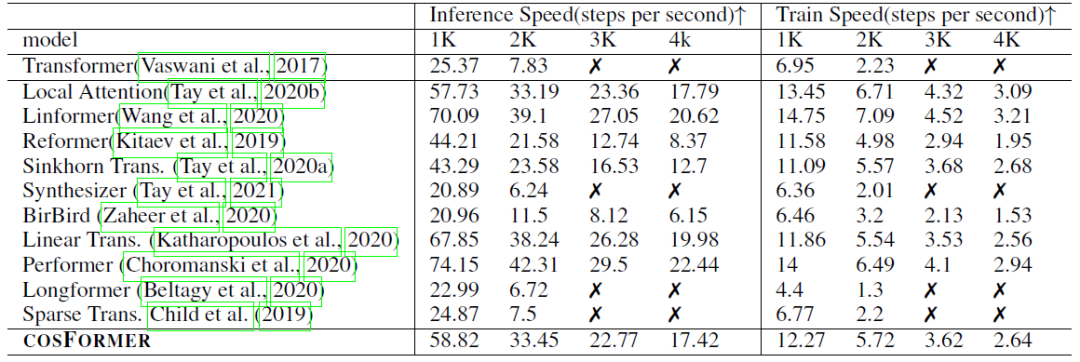
2)内存速度实验,指标表示速度(越高越好,如果内存溢出,则标记为叉):
审核编辑 :李倩
-
详细介绍注意力机制中的掩码2023-07-17 1731
-
PyTorch教程11.4之Bahdanau注意力机制2023-06-05 1027
-
计算机视觉中的注意力机制2023-05-22 763
-
基于非对称注意力机制残差网络的图像检测2021-07-05 1159
-
基于注意力机制的跨域服装检索方法综述2021-06-27 913
-
基于多通道自注意力机制的电子病历架构2021-06-24 1038
-
基于注意力机制等的社交网络热度预测模型2021-06-07 1167
-
结合注意力机制的跨域服装检索方法2021-05-12 1049
-
基于多层CNN和注意力机制的文本摘要模型2021-04-07 1229
-
基于注意力机制的深度学习模型AT-DPCNN2021-03-17 1287
-
注意力机制或将是未来机器学习的核心要素2020-05-07 1891
-
注意力机制的诞生、方法及几种常见模型2019-03-12 44462
-
深度分析NLP中的注意力机制2019-02-17 5025
-
浅谈自然语言处理中的注意力机制2019-01-25 7298
全部0条评论

快来发表一下你的评论吧 !
