

利用NVIDIA安培结构和TensorRT部署神经网络
描述
在部署神经网络时,考虑如何使网络运行更快或占用更少的空间是很有用的。一个更高效的网络可以在有限的时间预算内做出更好的预测,对意外的输入做出更快的反应,或者适应受限的部署环境。
稀疏性是一种有希望达到这些目标的优化技术。如果网络中有零,则不需要对其进行存储或操作。稀疏的好处似乎很简单。要实现承诺的收益,长期以来存在三个挑战。
Acceleration – 细粒度、非结构化、权重稀疏缺乏结构,无法使用高效硬件中可用的向量和矩阵指令来加速常见的网络操作。标准稀疏格式对于除高稀疏以外的所有格式都是低效的。
Accuracy – 为了实现具有细粒度、非结构化稀疏性的有用加速,必须使网络稀疏,这通常会导致精度损失。尝试使加速更容易的替代修剪方法,例如去除权重块、通道或整个层的粗粒度修剪,可能更快地遇到精度问题。这限制了潜在的性能优势。
Workflow – 当前在网络修剪方面的许多研究都可以作为有用的存在性证明。研究表明,网络 A 可以实现稀疏性 X 。当您尝试将稀疏性 X 应用于网络 B 时,麻烦就来了。由于网络、任务、优化器或任何超参数的不同,它可能无法工作。
在本文中,我们将讨论 NVIDIA 安培体系结构如何应对这些挑战。今天, NVIDIA 发布了 TensorRT 版本 8 。 0 ,它引入了对 NVIDIA 安培体系结构 GPU 上可用的稀疏张量核的支持。
TensorRT 是一个用于高性能深度学习推理的 SDK ,它包括一个优化器和运行时,可以最大限度地减少延迟和提高生产中的吞吐量。稀疏张量核通过一个简单的训练流程和 TensorRT 8 。 0 部署,可以消除神经网络中不必要的计算,与密集网络相比,可以获得 30% 以上的性能/瓦特增益。
稀疏张量核加速了 2 : 4 细粒度结构稀疏性
NVIDIA A100 GPU 为其张量核增加了对细粒度结构稀疏性的支持,稀疏张量核加速了 2 : 4 的稀疏模式。在四个值的每个连续块中,两个值必须为零。这自然会导致 50% 的稀疏度,这是细粒度的。没有矢量或块结构修剪在一起。这样的规则模式易于压缩,并且元数据开销较低(图 1 )。
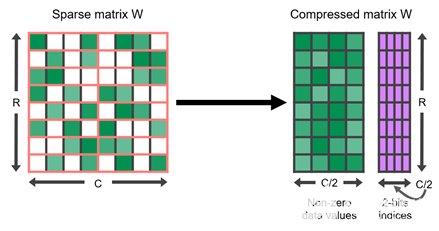
图 1 。 2 : 4 结构稀疏矩阵 W 及其压缩表示
稀疏张量核通过只对压缩矩阵中的非零值进行运算来加速这种格式。它们使用与非零一起存储的元数据仅从另一个未压缩的操作数中提取必要的值。因此,对于 2x 的稀疏性,它们可以在一半的时间内完成相同的有效计算。表 1 显示了稀疏张量核支持的各种数据类型的详细信息。
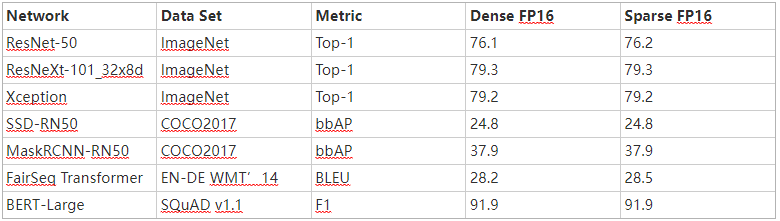
表 1 。稀疏张量核在 NVIDIA 安培结构中的性能。
2 : 4 结构化稀疏网络保持精度
当然,没有良好的准确性,性能是毫无意义的。我们开发了一个简单的培训工作流程,可以轻松生成 2 : 4 结构化稀疏网络,匹配密集网络的精度:
从密集的网络开始。我们的目标是从一个已知的好模型开始,该模型的权重已经收敛,从而得到有用的结果。
在稠密网络上,对权值进行剪枝以满足 2 : 4 的结构稀疏性准则。在每四个元素中,只删除两个。
重复原来的培训程序。
此工作流在步骤 2 中使用一次修剪。在修剪阶段之后,稀疏模式被修复。有很多方法可以做出修剪的决定。哪些权重应该保留,哪些权重应该强制为零?我们发现一个简单的答案很有效:重量大小。我们更喜欢删减已经接近零的值。
正如您所料,突然将网络中的一半权重变为零会影响网络的精度。第三步通过足够多的权重更新步骤来恢复精度,让权重收敛,并且有足够高的学习率让权重充分移动。在广泛的网络中,它生成一个稀疏模型,从步骤 1 开始保持密集网络的精度。
表 2 是我们使用 PyTorch 库 自动稀疏( ASP ) 中实现的此工作流获得的 FP16 精度结果示例。有关 FP16 和 INT8 的完整结果的更多信息,请参阅 加速稀疏深度神经网络 白皮书。
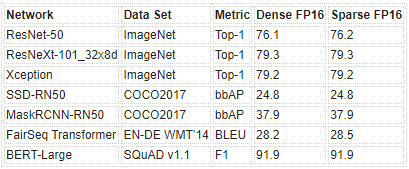
表 2 。用我们的配方训练的 2 : 4 结构化稀疏网络的样本精度。
案例研究: ResNeXt-10132x8d
以下是以 ResNeXt-10132x8d 为目标使用工作流的简单程度。
生成稀疏模型
您使用 torchvision 预训练的 model ,因此步骤 1 已经完成。因为您使用的是 ASP ,所以第一个代码更改是导入库:

加载此训练运行的预训练模型。不过,与其训练密集权重,不如在训练循环之前修剪模型并准备优化器(工作流的步骤 2 ):

就这样。训练循环正常进行,默认命令从预训练模型开始,该模型重用原始超参数和优化器设置进行再训练:

当训练完成(第 3 步)时,网络精度应恢复到与预训练模型的精度相匹配,如表 2 所示。通常,性能最好的检查点可能不是来自最后一个历元。
准备推理
对于推理,使用 TensorRT 8 。 0 导入训练模型的稀疏检查点。在导入 TensorRT 之前,需要将模型从本机框架格式转换为 ONNX 格式。可以按照 quickstart/IntroNotebooks GitHub repo 中的笔记本进行转换。
我们已经将稀疏 ResNeXt-10132x8d 转换为 ONNX 格式。你可以从 NGC 下载这个模型。如果没有安装 NGC ,请使用以下命令安装 NGC :

安装 NGC 后,通过运行以下命令下载 ONNX 格式的稀疏 ResNeXt-10132x8d :

要将 ONNX 模型导入到 TensorRT ,请克隆 TensorRT repo 并设置 Docker 环境,如 NVIDIA / TensorRT 自述 中所述。
进入 trtexec 根目录后,使用 TensorRT 将稀疏 ONNX 模型转换为 TensorRT 引擎。创建一个目录以存储模型和引擎:

将下载的 ResNext ONNX 模型复制到 /workspace/TensorRT/model 目录,然后执行 trtexec 命令,如下所示:

名为 resnext101 _ engine 。 trt 的新文件创建于/ workspace / TensorRT / model /。 resnext101 _ engine 。 trt 文件现在可以通过以下方法之一序列化以执行推断:
TensorRT 运行时的 C ++或 Python ,如在这个 示例笔记本 中所示
NVIDIA Triton ®声波风廓线仪推断服务器
TensorRT 8 。 0 中的性能
将 TensorRT 8 。 0 中的稀疏模型在 A100 GPU 上以不同批量大小进行基准测试显示了两个重要趋势:
性能优势随着 A100 所做的工作量的增加而增加。更大的批量通常会带来更大的改进,在高端接近 20% 。
在较小的批处理规模下, A100 时钟速度可以保持在较低的水平,使用稀疏性可以将它们推到更低的水平,以获得相同的性能,从而导致比性能本身更大的功率效率改进,从而获得高达 36% 的性能/瓦增益。
别忘了,这个网络和密集基线的精确度是一样的。这种额外的效率和性能不需要惩罚的准确性。
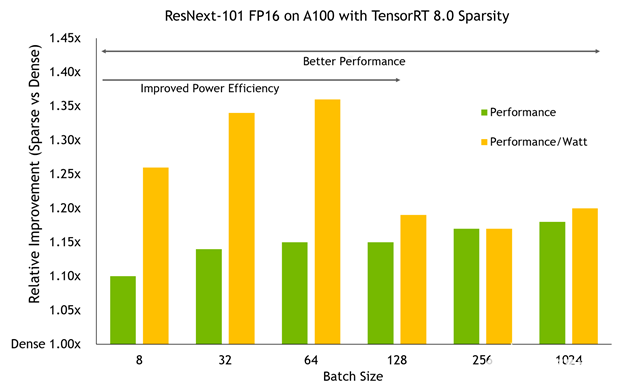
图 2 。性能和能效方面的稀疏性改进(以密集为基准)
概括
稀疏性是神经网络压缩和简化研究的热点。不过,到目前为止,细粒度稀疏性还没有兑现其性能和准确性的承诺。我们开发了 2 : 4 细粒度结构稀疏性,并将支持直接构建到 NVIDIA 安培结构稀疏张量核中。通过这个简单的三步稀疏再训练工作流,您可以生成与基线精度匹配的稀疏神经网络, TensorRT 8 。 0 在默认情况下对其进行加速。
关于作者
About Jeff Pool
Jeff Pool 是深入学习体系结构团队的高级架构师,负责研究高效的 DL 方法。在 2012 年加入 NVIDIA 之后,他对各种体系结构的许多领域做出了贡献,但最近他一直在使用稀疏神经网络。 Jeff 拥有计算机科学博士学位,专注于高效图形硬件。
About Abhishek Sawarkar
Abhishek Sawarkar 责在 NVIDIA Jarvis 框架上开发和展示以深度学习为重点的内容。他的背景是计算机视觉和机器学习,但目前他正致力于整个 Jarvis 多模式管道,包括 ASR 、 NLP 、 TTS 和 CV 。他是卡内基梅隆大学的一名应届毕业生,具有电气和计算机工程硕士学位。
About Jay Rodge
Jay Rodge 是 NVIDIA 的产品营销经理,负责深入学习和推理产品,推动产品发布和产品营销计划。杰伊在芝加哥伊利诺伊理工学院获得计算机科学硕士学位,主攻计算机视觉和自然语言处理。在 NVIDIA 之前,杰伊是宝马集团的人工智能研究实习生,为宝马最大的制造厂使用计算机视觉解决问题。
审核编辑:郭婷
-
【案例分享】ART神经网络与SOM神经网络2019-07-21 3324
-
人工神经网络实现方法有哪些?2019-08-01 3543
-
卷积神经网络的层级结构和常用框架2020-12-29 2900
-
如何构建神经网络?2021-07-12 2024
-
基于BP神经网络的PID控制2021-09-07 2748
-
如何使用stm32cube.ai部署神经网络?2021-10-11 4827
-
轻量化神经网络的相关资料下载2021-12-14 2140
-
卷积神经网络一维卷积的处理过程2021-12-23 2101
-
卷积神经网络模型发展及应用2022-08-02 13391
-
神经网络分类2009-03-01 1925
-
创造新的分子结构,利用神经网络研发新的药物2018-07-16 756
-
NVIDIA GPU加快深度神经网络训练和推断2022-02-18 3038
-
使用NVIDIA TensorRT部署实时深度学习应用程序2022-04-18 3353
-
卷积神经网络层级结构 卷积神经网络的卷积层讲解2023-08-21 11203
-
递归神经网络和循环神经网络的模型结构2024-07-10 2320
全部0条评论

快来发表一下你的评论吧 !
