

使用NVIDIA TensorRT优化T5和GPT-2
描述
这个 transformer 体系结构 完全改变了(双关语)自然语言处理( NLP )的领域。近年来,在 transformer 构建块 BERT 、 GPT 和 T5 上构建了许多新颖的网络体系结构。随着品种的增加,这些型号的尺寸也迅速增加。
虽然较大的神经语言模型通常会产生更好的结果,但将它们部署到生产环境中会带来严重的挑战,尤其是对于在线应用程序,在这些应用程序中,几十毫秒的额外延迟可能会对用户体验产生显著的负面影响。
使用最新的 TensorRT 8.2 ,我们优化了 T5 和 GPT-2 模型,以实现实时推理。您可以将 T5 或 GPT-2 模型转换为 TensorRT 引擎,然后将此引擎用作推理工作流中原始 PyTorch 模型的插件替换。与 PyTorch GPU 推理相比,此优化导致延迟减少 3-6 倍,与 PyTorch CPU 推理相比,延迟减少 9-21 倍。
在这篇文章中,我们将向您详细介绍如何实现相同的延迟减少,使用我们最新发布的基于 Hugging Face transformers 的示例脚本和笔记本,使用 GPT-2 进行开放式文本生成,使用 T5 进行翻译和摘要。
T5 和 GPT-2 简介
在本节中,我们将简要介绍 T5 和 GPT-2 模型。
T5 用于回答问题、总结、翻译和分类
T5 或文本到文本传输 transformer 是谷歌最近创建的一种体系结构。它将所有自然语言处理( NLP )任务重新构造为统一的文本到文本格式,其中输入和输出始终是文本字符串。 T5 的体系结构允许将相同的模型、损失函数和超参数应用于任何 NLP 任务,如机器翻译、文档摘要、问答和分类任务,如情感分析。
T5 模式的灵感来源于迁移学习在 NLP 中产生了最先进的结果。迁移学习背后的原理是,基于大量可用的未经训练的数据和自我监督任务的模型可以在较小的任务特定标记数据集上针对特定任务进行微调。事实证明,这些模型比从头开始针对特定任务数据集训练的模型具有更好的结果。
基于迁移学习的概念, Google 在 用统一的文本到文本转换器探索迁移学习的局限性 中提出了 T5 模型。在本文中,他们还介绍了庞大的干净爬网语料库( C4 )数据集。在该数据集上预训练的 T5 模型在许多下游 NLP 任务上实现了最先进的结果。已发布的预训练 T5 车型的参数范围高达 3B 和 11B 。
GPT-2 用于生成优秀的类人文本
生成性预训练 transformer 2 ( GPT-2 )是 OpenAI 最初提出的一种自回归无监督语言模型。它由 transformer 解码器块构建,并在非常大的文本语料库上进行训练,以预测段落中的下一个单词。它生成优秀的类人文本。更大的 GPT-2 模型,最大参数达到 15 亿,通常能写出更好、更连贯的文本。
使用 TensorRT 部署 T5 和 GPT-2
使用 TensorRT 8.2 ,我们通过构建并使用 TensorRT 发动机作为原始 PyTorch 模型的替代品,优化了 T5 和 GPT-2 模型。我们将带您浏览 scripts 和 Jupyter notebooks ,并重点介绍基于拥抱面部变形金刚的重要内容。有关更多信息,请参阅示例脚本和笔记本以获取详细的分步执行指南。
设置
最方便的开始方式是使用 Docker 容器,它为实验提供了一个隔离、独立和可复制的环境。
构建并启动 TensorRT 容器:

这些命令启动 Docker 容器和 JupyterLab 。在 web 浏览器中打开 JupyterLab 界面: 在 JupyterLab 中,要打开终端窗口,请选择 File 、 New 、 Terminal 。编译并安装 TensorRT OSS 包:
在 JupyterLab 中,要打开终端窗口,请选择 File 、 New 、 Terminal 。编译并安装 TensorRT OSS 包:

现在,您已经准备好继续使用模型进行实验。在下面的顺序中,我们将演示 T5 模型的步骤。下面的代码块并不意味着可以复制粘贴运行,而是引导您完成整个过程。为了便于复制,请参阅 GitHub 存储库上的 notebooks 。
在高层次上,使用 TensorRT 优化用于部署的拥抱面 T5 和 GPT-2 模型是一个三步过程:
从 HuggingFace 模型动物园下载模型。
将模型转换为优化的 TensorRT 执行引擎。
使用 TensorRT 引擎进行推理。
使用生成的引擎作为 HuggingFace 推理工作流中原始 PyTorch 模型的插件替换。
从 HuggingFace 模型动物园下载模型
首先,从 HuggingFace 模型中心下载原始的 Hugging Face PyTorch T5 模型及其关联的标记器。

然后,您可以将此模型用于各种 NLP 任务,例如,从英语翻译为德语:

TensorRT 8.2 支持 GPT-2 至“ xl ”版本( 1.5B 参数)和 T5 至 11B 参数,这些参数可在 HuggingFace model zoo 上公开获得。根据 GPU 内存可用性,也可支持较大型号。
将模型转换为优化的 TensorRT 执行引擎。
在将模型转换为 TensorRT 引擎之前,请将 PyTorch 模型转换为中间通用格式。 ONNX 是机器学习和深度学习模型的开放格式。它使您能够将 TensorFlow 、 PyTorch 、 MATLAB 、 Caffe 和 Keras 等不同框架中的深度学习和机器学习模型转换为单一的统一格式。
转换为 ONNX
对于 T5 型号,使用实用功能分别转换编码器和解码器。

转换为 TensorRT
现在,您已经准备好解析 T5 ONNX 编码器和解码器,并将它们转换为优化的 TensorRT 引擎。由于 TensorRT 执行了许多优化,例如融合操作、消除转置操作和内核自动调优,以在目标 GPU 体系结构上找到性能最佳的内核,因此此转换过程可能需要一些时间。

使用 TensorRT 引擎进行推理
最后,您现在有了一个针对 T5 模型的优化 TensorRT 引擎,可以进行推断。

类似地,对于 GPT-2 模型,您可以按照相同的过程生成 TensorRT 引擎。优化的 TensorRT 引擎可作为 HuggingFace 推理工作流中原始 PyTorch 模型的插件替代品。
TensorRT transformer 优化细节
基于转换器的模型是 transformer 编码器或解码器块的堆栈。编码器(解码器)块具有相同的结构和参数数量。 T5 由 transformer 编码器和解码器的堆栈组成,而 GPT-2 仅由 transformer 解码器块组成(图 1 )。
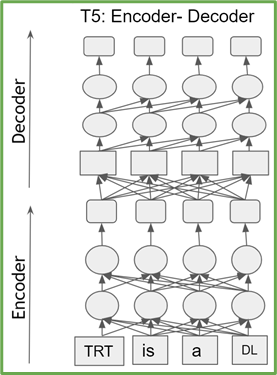
图 1a 。 T5 架构
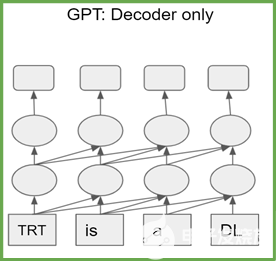
图 1b 。 GPT-2 体系结构
每个 transformer 块,也称为自我注意块,通过使用完全连接的层将输入投影到三个不同的子空间,称为查询( Q )、键( K )和值( V ),由三个投影组成。然后将这些矩阵转换为 QT和 KT用于计算标准化点积注意值,然后与 V 组合T生成最终输出(图 2 )。
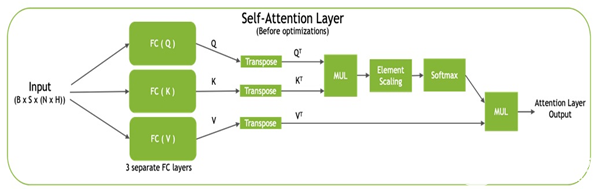
图 2 。自我注意块
TensorRT 通过逐点层融合优化自我注意块:
还原与电源操作相融合(用于图层模板和剩余添加图层)。
电子秤与 softmax 融合在一起。
GEMM 与 ReLU / GELU 激活融合。
此外, TensorRT 还优化了推理网络:
消除转置操作。
将三个 KQV 投影融合为一个 GEMM 。
当指定 FP16 模式时,控制逐层精度以保持精度,同时运行 FP16 中计算最密集的运算。
TensorRT 对 PyTorch CPU 和 GPU 基准
通过 TensorRT 进行的优化,我们看到 PyTorch GPU 推理的加速比高达 3-6 倍,而 PyTorch CPU 推理的加速比高达 9-21 倍。
图 3 显示了批量为 1 的 T5-3B 模型的推理结果,该模型用于将短短语从英语翻译成德语。 A100 GPU 上的 TensorRT 引擎与在双插槽 Intel Platinum 8380 CPU 上运行的 PyTorch 相比,延迟减少了 21 倍。
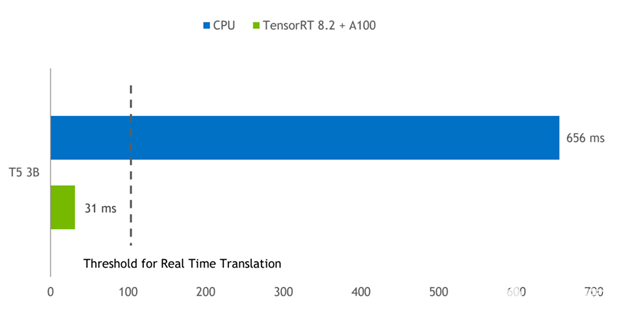
图 3 。 A100 GPU 上的 T5-3B 模型推断比较 TensorRT 提供的延迟比 PyTorch CPU 推断小 21 倍。
CPU :英特尔白金 8380 , 2 个插槽。
GPU:NVIDIA A100 PCI Express 80GB 。软件: PyTorch 1.9 , TensorRT 8.2.0 EA 。
任务:“将英语翻译成德语:这很好。”
结论
在这篇文章中,我们向您介绍了如何将拥抱脸 PyTorch T5 和 GPT-2 模型转换为优化的 TensorRT 推理引擎。 TensorRT 推理机用作原始 HuggingFace T5 和 GPT-2 PyTorch 模型的替代品,可提供高达 21x CPU 的推理加速比。要为您的模型实现此加速, 从 TensorRT 8.2 开始今天的学习 .
关于作者
About Vinh Nguyen是一位深度学习的工程师和数据科学家,发表了 50 多篇科学文章,引文超过 2500 篇。在 NVIDIA ,他的工作涉及广泛的深度学习和人工智能应用,包括语音、语言和视觉处理以及推荐系统。
About Nikhil Srihari是 NVIDIA 的深入学习软件技术营销工程师。他在自然语言处理、计算机视觉和语音处理领域拥有广泛的深度学习和机器学习应用经验。 Nikhil 曾在富达投资公司和 Amazon 工作。他的教育背景包括布法罗大学的计算机科学硕士学位和印度苏拉斯卡尔卡纳塔克邦国家理工学院的学士学位。
About Parth Chadha是 NVIDIA 的深度学习软件工程师。他在 TensorRT 上工作,这是一个高性能的深度学习推理 SDK 。 Parth 在卡内基梅隆大学获得电气和计算机工程硕士学位,主要研究机器学习和并行计算机体系结构。
About Charles Chen20 岁时在加州大学圣地亚哥分校获得计算机科学硕士学位后, Charles Chen 专注于为尖端人工智能框架、发展中国家的计算机教育和人机交互做出贡献。在 NVIDIA , Charles 是一名深度学习软件工程师,致力于 TensorRT ,一款高性能的深度学习推理 SDK 。
About Joohoon Lee领导 NVIDIA 的汽车深度学习解决方案架构师团队。他专注于将深度学习研究转化为用于生产部署的真实世界自主驾驶软件。他的团队使汽车客户能够使用英伟达驱动平台进行 DNN 培训、微调、优化和部署。在加入 NVIDIA 之前,他曾担任 GPU 软件架构师,负责加速 DNN 算法。 Joohoon 在卡内基梅隆大学获得电气和计算机工程学士和硕士学位。
About Jay Rodge是 NVIDIA 的产品营销经理,负责深入学习和推理产品,推动产品发布和产品营销计划。杰伊在芝加哥伊利诺伊理工学院获得计算机科学硕士学位,主攻计算机视觉和自然语言处理。在 NVIDIA 之前,杰伊是宝马集团的人工智能研究实习生,为宝马最大的制造厂使用计算机视觉解决问题。
审核编辑:郭婷
-
GPT2模块的相关资料推荐2022-02-22 828
-
解析T5荧光灯在照明应用2010-04-20 1848
-
T5和T8、T10LED灯管的区别2016-01-15 3118
-
荧光灯t5和t8的区别2018-01-17 78182
-
OpenAI宣布,发布了7.74亿参数GPT-2语言模型2019-09-01 3725
-
和AI聊天,自然语言模型 GPT-2可能会推出个人信息2021-01-02 3317
-
T5硬件设计指南V1.1.22022-03-08 760
-
基于OpenAI的GPT-2的语言模型ProtGPT2可生成新的蛋白质序列2022-09-08 3660
-
使用FasterTransformer和Triton推理服务器部署GPT-J和T52022-10-10 8504
-
GPT/GPT-2/GPT-3/InstructGPT进化之路2023-03-03 5628
-
NVIDIA TensorRT与Apache Beam SDK的集成2023-07-05 1265
-
即刻报名第三届 NVIDIA TensorRT Hackathon 生成式 AI 模型优化赛2023-07-17 1419
-
学习资源 | NVIDIA TensorRT 全新教程上线2023-08-04 2372
-
现已公开发布!欢迎使用 NVIDIA TensorRT-LLM 优化大语言模型推理2023-10-27 2327
-
NVIDIA TensorRT LLM 1.0推理框架正式上线2025-10-21 1635
全部0条评论

快来发表一下你的评论吧 !
