

使用迁移学习定制人工智能深度学习模型
描述
从头开始创建一个新的人工智能深度学习模型是一个非常耗费时间和资源的过程。解决这个问题的一个常见方法是采用迁移学习。为了使这一过程更加简单,NVIDIA TAO Toolkit,它可以将工程时间框架从 80 周缩短到 8 周。 TAO 工具包支持计算机视觉和对话 AI ( ASR 和 NLP )用例。
在本文中,我们将介绍以下主题:
- 安装 TAO 工具包并访问预训练模型
- 微调预训练语音转录模型
- 将微调模型导出到 NVIDIA Riva
跟随 download the Jupyter notebook。
安装 TAO 工具包并下载预训练模型
在安装 TAO 工具包之前,请确保您的系统上安装了以下组件:
- Python [3 . 6 . 9]
- docker ce > 19 . 03 . 5
- nvidia-DOCKR2 3 . 4 . 0-1
有关安装 nvidia docker 和 docker 的更多信息,请参阅Prerequisites。您可以使用 pip 安装 TAO 工具包。我们建议使用virtual environment以避免版本冲突。
pip3 install nvidia-pyindex pip3 install nvidia-tao
安装完成后,下一步是获得一些经过预训练的模型。 NVIDIA 提供了许多人工智能或机器学习模型,不仅在对话人工智能领域,而且在 NGC 或 NVIDIA GPU 云上的广泛领域。 NGC 目录是一套精心策划的 GPU 优化软件,用于 AI 、 HPC 和可视化。
要从 NGC 下载资源,请使用NGC API key登录注册表。您可以免费创建和使用一个。
图 1 。获取 NGCAPI 密钥
CitriNet是由 NVIDIA 构建的最先进的自动语音识别( ASR )模型,可用于生成语音转录。您可以从Speech to Text English Citrinet型号卡下载此型号。
wget https://api.ngc.nvidia.com/v2/models/nvidia/tao/speechtotext_english_citrinet/versions/trainable_v1.7/files/speechtotext_english_citrinet_1024.tlt
为了提供流畅的体验,工具包在后台下载并运行 Docker 容器,使用前面提到的规范文件。所有细节都隐藏在 TAO 启动器中。您可以通过定义 JSON 文件~/.tao_mounts.json来指定装载 Docker 容器的首选位置。您可以在Jupyter notebook中找到装载文件。
{ "Mounts":[ { "source": "~/tao/data", "destination": "/data" # The location in which to store the dataset }, { "source": "~/tao/specs", "destination": "/specs" # The location in which to store the specification files }, { "source": "~/tao/results", "destination": "/results" # The location in which to store the results }, { "source": "~/.cache", "destination": "/root/.cache" } ], "DockerOptions":{ "shm_size": "16G", "ulimits": { "memlock": -1, "stack": 67108864 } } }
这样,您就安装了 TAO 工具包,下载了一个经过预训练的 ASR 模型,并指定了 TAO 工具包启动器的安装点。在下一节中,我们将讨论如何使用 TAO 工具包在您选择的数据集上微调此模型。
微调模型
使用 TAO 工具包微调模型包括三个步骤:
- 下载规范文件。
- 预处理数据集。
- 使用超参数进行微调。
图 3 显示了微调模型所需的步骤。
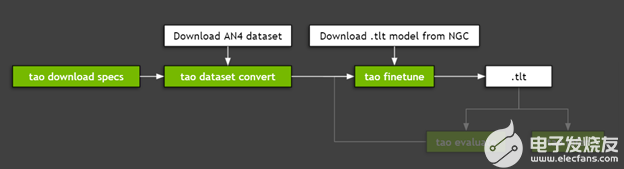
图 2 。 TAO 工具包工作流
步骤 1 :下载规范文件
NVIDIA TAO Toolkit 是一种低代码或无代码的解决方案,通过规范文件简化模型的培训或微调。通过这些文件,您可以自定义特定于模型的参数、培训师参数、优化器和所用数据集的参数。可以将这些规范文件下载到先前装载的文件夹:
tao speech_to_text_citrinet download_specs \ -r /speech_to_text_citrinet \ -o < path to specs dir>/speech_to_text_citrinet
以下是 TAO 工具包附带的 YAML 文件。有关更多信息,请参阅Downloading Sample Spec Files。
-
create_tokenizer.yaml -
dataset_convert_an4.yaml -
dataset_convert_en.yaml -
dataset_convert_ru.yaml -
evaluate.yaml -
export.yaml -
finetune.yaml -
infer_onnx.yaml -
infer.yaml -
train_citrinet_256.yaml -
train_citrinet_bpe.yaml
这些规范文件可供自定义和使用。从预处理和模型评估到推理和导出模型,都有相应的功能。这使您能够完成开发或定制模型的过程,而无需构建复杂的代码库。下载等级库文件后,现在可以继续预处理数据。
步骤 2 :预处理数据集
在本演练中,您将使用CMU’s AN4 Dataset,这是一个小型普查数据集,其中包含地址、数字和其他个人信息的记录。这与客户支持对话中对话的初始步骤所需的转录类型类似。具有类似内容的较大自定义数据集可用于实际应用程序。
您可以直接下载和解压缩 AN4 数据集,或使用以下命令:
wget
http://www.speech.cs.cmu.edu/databases/an4/an4_sphere.tar.gz
tar -xvf an4_sphere.tar.gz
TAO 工具包培训和微调模块期望数据以特定格式呈现。可以使用 dataset _ convert 命令完成此预处理。我们将 AN4 和 Mozilla 的通用语音数据集的规范文件与 TAO 启动器一起打包。您可以在步骤 1 中定义的目录中找到这些规范文件。
这些清单文件(图 3 )包含在后面的步骤中使用的以下信息:
- 音频文件的路径
- 每个文件的持续时间
- 每个文件的文字内容
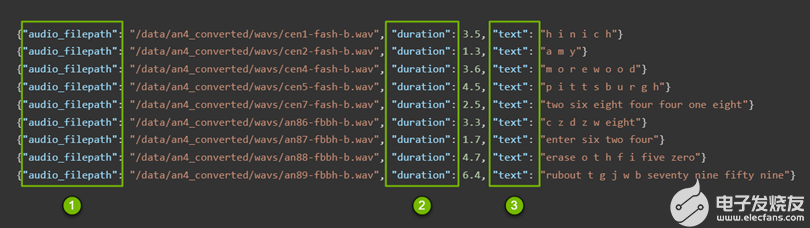
图 3 。已处理清单文件的结构
tao speech_to_text_citrinet dataset_convert \ -e /speech_to_text_citrinet/dataset_convert_an4.yaml \ -r /citrinet/dataset_convert \ source_data_dir= /an4 \ target_data_dir=/an4_converted
此命令将音频文件转换为 WAV 文件,并生成训练和测试清单文件。有关更多信息,请参阅Preparing the Dataset。
在大多数情况下,您都会进行预处理,但 CitriNet 模型是一个特例。它需要以子词标记化的形式进行进一步处理,为文本创建子词词汇表。这与 Jasper 或 QuartzNet 不同,因为在它们的情况下,词汇表中只有单个字符被视为元素。在 CitriNet 中,子字可以是一个或多个字符。这可以使用以下命令完成:
tao speech_to_text_citrinet create_tokenizer \ -e /speech_to_text_citrinet/create_tokenizer.yaml \ -r /citrinet/create_tokenizer \ manifests=/an4_converted/train_manifest.json \ output_root=/an4 \ vocab_size=32
到目前为止,您已经建立了一个工具,为诸如迁移学习之类的复杂问题提供低代码或无代码解决方案。您已经下载了一个预训练的模型,将音频文件处理为必要的格式,并执行了标记化。您使用的命令不到 10 个。现在,所有必要的细节都已散列出来,您可以继续微调模型。
步骤 3 :使用超参数进行微调
正如在前面的步骤中所做的那样,您正在与规范文件交互。有关更多信息,请参阅Creating an Experiment Spec File。如果要调整 FFT 窗口大小的大小,可以指定几乎所有内容,从特定于训练的参数(如优化器)到特定于数据集的参数,再到模型配置本身。
是否要更改学习速率和调度程序,或者在词汇表中添加新字符?无需打开代码库并对其进行扫描以进行更改。所有这些定制都很容易获得,并可在整个团队中共享。这减少了在尝试新想法和分享结果以及模型配置方面的摩擦,从而提高了准确性。
以下是如何微调培训师:
trainer: max_epochs: 3 # This is low for demo purposes tlt_checkpoint_interval: 1 change_vocabulary: true
以下是如何微调标记器:
tokenizer: dir: /path/to/subword/vocabulary type: "bpe" # Can be either bpe or wpe
以下是如何微调优化器:
optim: name: novograd lr: 0.01 betas: [0.8, 0.5] weight_decay: 0.001 sched: name: CosineAnnealing warmup_steps: null warmup_ratio: null min_lr: 0.0 last_epoch: -1
以下是如何微调数据集:
# Fine-tuning settings: validation dataset validation_ds: manifest_filepath: /path/to/manifest/file/ sample_rate: 16000 labels: [" ", "a", "b", "c", "d", "e", "f", "g", "h", "i", "j", "k", "l", "m", "n", "o", "p", "q", "r", "s", "t", "u", "v", "w", "x", "y", "z", "'"] batch_size: 32 shuffle: false finetuning_ds: manifest_filepath: ??? sample_rate: 160000 labels: [" ", "a", "b", "c", "d", "e", "f", "g", "h", "i", "j", "k", "l", "m", "n", "o", "p", "q", "r", "s", "t", "u", "v", "w", "x", "y", "z", "'"] batch_size: 32 trim_silence: true max_duration: 16.7 shuffle: true is_tarred: false tarred_audio_filepaths: null
最后,要继续,请根据需要修改规范文件并运行以下命令。此命令使用先前下载的数据集微调下载的模型。有关更多信息,请参阅Fine-Tuning the Model。
tao speech_to_text_citrinet finetune \ -e $SPECS_DIR/speech_to_text_citrinet/finetune.yaml \ -g 1 \ -k \ -m /speechtotext_english_citrinet_1024.tlt \ -r $RESULTS_DIR/citrinet/finetune \ finetuning_ds.manifest_filepath=$DATA_DIR/an4_converted/train_manifest.json \ validation_ds.manifest_filepath=$DATA_DIR/an4_converted/test_manifest.json \ trainer.max_epochs=1 \ finetuning_ds.num_workers=1 \ validation_ds.num_workers=1 \ trainer.gpus=1 \ tokenizer.dir=$DATA_DIR/an4/tokenizer_spe_unigram_v32
在对模型进行微调或培训后,自然会评估模型并评估是否需要进一步微调。为此, NVIDIA 为evaluate your model和run inference提供了功能。
将微调模型导出到 Riva
在生产环境中部署模型会带来一系列挑战。为此,您可以使用NVIDIA Riva,一种 GPU 加速 AI 语音 SDK 来开发实时转录和虚拟助理等应用程序。
Riva 使用其他 NVIDIA 产品:
- NVIDIA Triton Inference Server用于简化大规模生产中模型的部署。
- NVIDIA TensorRT用于通过优化 NVIDIA GPU s 的模型来加速模型并提供更好的推理性能。
如果您对使用本演练中微调的模型感兴趣,可以使用以下命令将其导出到 Riva 。有关更多信息,请参阅Model Export。
tao speech_to_text_citrinet export \ -e /speech_to_text_citrinet/export.yaml \ -g 1 \ -k \ -m /citrinet/train/checkpoints/trained-model.tlt \ -r /citrinet/riva \ export_format=RIVA \ export_to=asr-model.riva
在下一篇文章中,我们将介绍如何安装 NVIDIA Riva 在生产环境中部署这些模型,以及如何使用NGC Catalog中的众多模型之一。
关于作者
About Tanay Varshney
Tanay Varshney 是 NVIDIA 的一名深入学习的技术营销工程师,负责广泛的 DL 软件产品。他拥有纽约大学计算机科学硕士学位,专注于计算机视觉、数据可视化和城市分析的横断面。
About Sirisha Rella
Sirisha Rella 是 NVIDIA 的技术产品营销经理,专注于计算机视觉、语音和基于语言的深度学习应用。 Sirisha 获得了密苏里大学堪萨斯城分校的计算机科学硕士学位,是国家科学基金会大学习中心的研究生助理。
审核编辑:符乾江
-
菜鸟如何学习人工智能2016-06-03 11841
-
人工智能和机器学习的前世今生2018-08-27 3623
-
人工智能深度学习发展迅速,智能科技公司都已经涉足人工智能产品的研发!2018-09-05 3331
-
史上最全AI人工智能入门+进阶学习视频全集(200G)【免费领取】2019-11-27 6315
-
人工智能、数据挖掘、机器学习和深度学习的关系2020-03-16 2896
-
人工智能AI-深度学习C#&LabVIEW视觉控制演示效果2020-11-27 3199
-
人工智能基本概念机器学习算法2021-09-06 2816
-
基于RK3399ProD的人工智能开发板深度学习课程分享2022-02-11 2928
-
什么是人工智能、机器学习、深度学习和自然语言处理?2022-03-22 4738
-
迁移学习2022-04-21 11481
-
嵌入式人工智能学习路线2022-09-16 4565
-
使用迁移学习定制人工智能深度学习模型2022-04-01 1597
-
人工智能学习 迁移学习实战进阶2022-04-28 2625
-
人工智能与机器学习、深度学习的区别2023-03-29 2751
-
人工智能深度学习的五大模型及其应用领域2024-07-03 8537
全部0条评论

快来发表一下你的评论吧 !
