

MbedTLS纯软件实现和使用i.MX RT芯片里的硬件加速器实现性能差异
描述
近期有i.MX RT客户在集成OTASBL项目,实现产品的2nd bootloader时遇到了 MbedTLS库算法性能问题,客户想知道MbedTLS纯软件实现和使用i.MX RT芯片里的硬件加速器实现,在性能上差距有多大。
借着客户这个问题,我们今天就在i.MX RT上实测看一下两个方式的性能差异。
客户使用的是i.MX RT1170,这个型号上的硬件加速器是CAAM,相比前一代架构 i.MX RT10xx系列上的DCP有升级,我们今天把DCP和CAAM同时测一下。
一、MbedTLS算法库简介
MbedTLS(前身 PolarSSL)是一个开源的 SSL/TLS 算法库,最早由Arm公司开源和维护,现在已经移交 Trusted Firmware 社区维护。MbedTLS 开源仓库地址为:
项目地址:https://github.com/ARMmbed/mbedtls
MbedTLS代码由 C 语言写成,其以最小的编码占用空间实现了 SSL/TLS 功能及各种加密算法,易于理解、使用、集成和扩展,方便开发人员轻松地在嵌入式产品中使用 SSL/TLS 功能。
MbedTLS软件包主要提供了如下支持:
完整的SSL v3、TLSv1.0、TLSv1.1 和TLS v1.2 协议实现
X.509 证书处理
基于TCP 的TLS 传输加密
基于UDP 的DTLS(DatagramTLS)传输加密
其它加解密库实现
二、i.MX RT上的硬件加速器简介
1, i.MX RT10xx系列上的DCP
DCP 是 Data Co-Processor 的简称,从名字上看是个通用数据协处理器。
在 i.MX RT1060 Security Reference Manual 中有一张系统整体安全架构简图,这个简图中标出了 DCP 模块的主要功能:CRC-32算法、AES算法、Hash算法、类DMA数据搬移。关于进一步用法,见痞子衡两篇旧文《i.MX RT10xx DCP使用时密钥注意事项》、《i.MX RT10xx DCP使用时Cache注意事项》。
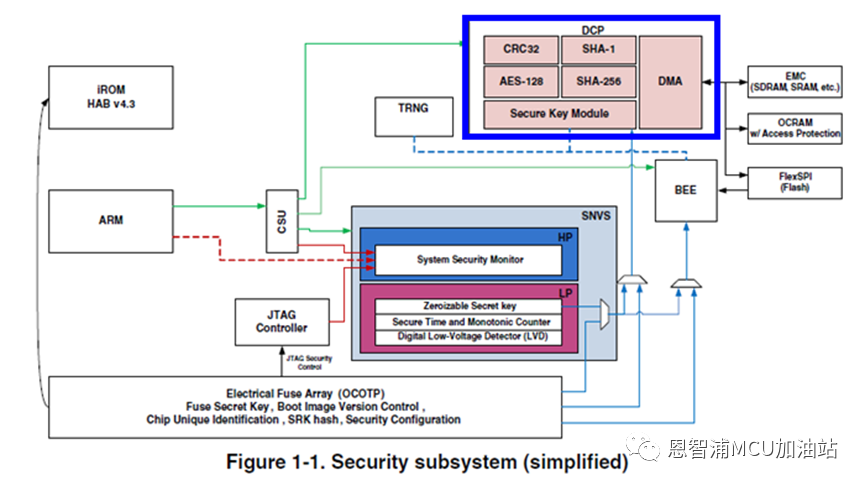
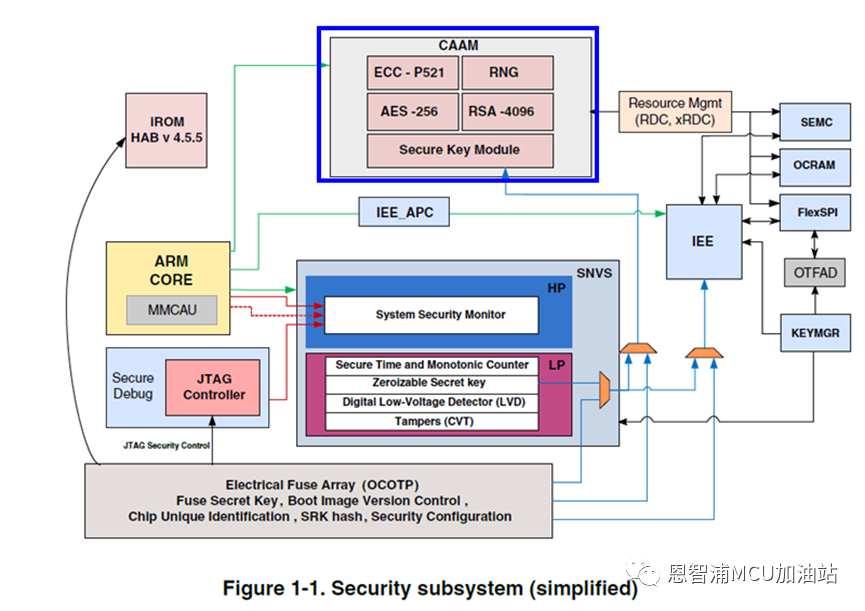
2, i.MX RT11xx系列上的CAAM
CAAM 是 Cryptographic Acceleration and Assurance Module 的简称,是个超全功能的安全算法加速器。在 i.MX RT1170 Security Reference Manual 中有一张系统整体安全架构简图,这个简图中标出了 CAAM 模块的主要功能,其在 DCP 已有功能上做了进一步扩展,丰富了算法支持。
三、对比常见算法的软硬件实现性能差异
1,官方SDK例程简介
想要在MCU 上跑 MbedTLS 算法,正常是需要先移植MbedTLS 源码的。但是恩智浦 i.MX RT官方SDK包里已经做好了移植,源码就放在 SDK_2.11.0_MIMXRT1xxx-EVKmiddlewarembedtls下面,所以我们省去了移植步骤。
注:在 SDK 2.11 版本里移植的是 MbedTLS 2.27.0。
此外官方SDK 里还提供给了如下两个关于 MbedTLS 的基础例程,其中 mbedtls_selftest 是遍历全部算法,检测算法执行正确性;mbedtls_benchmark则是提供全部算法的实际运行性能数据(编解码速率 KB/s)。
SDK_2.11.0_MIMXRT1xxx-EVKoardsevkmimxrt1xxxmbedtls_examplesmbedtls_selftest
SDK_2.11.0_MIMXRT1xxx-EVKoardsevkmimxrt1xxxmbedtls_examplesmbedtls_benchmark
2,在i.MX RT1060上实测
我们现在在 MIMXRT1060-EVK 板子上实测算法性能,就用mbedtls_benchmark 例程,选择 debug build,即让代码跑在 TCM 里,这样可以达到最好性能,不让存储器性能成瓶颈从而影响算法性能数据。此外i.MX RT1060 内核频率也是配到了最高 600MHz。
mbedtls_benchmark例程默认是启用硬件加速器 DCP 来实现算法的,因为我们要对比 MbedTLS 纯软件实现和 DCP 硬件实现性能差异,所以在测试纯软件方式时需要在工程源文件 MIMXRT1062_features.h 里将下面这个宏临时设为 0,这时候工程可能会编译不通过(代码链在 128KB ITCM 里),因为纯软件方式代码相比硬件驱动方式代码要大得多,此时可以在benchmark.c 或者 ksdk_mbedtls_config.h 注释掉一些算法执行来减少最终代码体(保留你感兴趣的算法)。
/* @brief DCP availability on the SoC. */
#define FSL_FEATURE_SOC_DCP_COUNT (0)
算法性能数据跟 IDE 以及编译优化选项也有关系,我们这里选择了 IAR,优化选项分别测试了 None 以及 High Speed,NoSize constraints 两种,因为算法特别多,我们就摘比较常用的 SHA 和 AES,其对比结果如下:
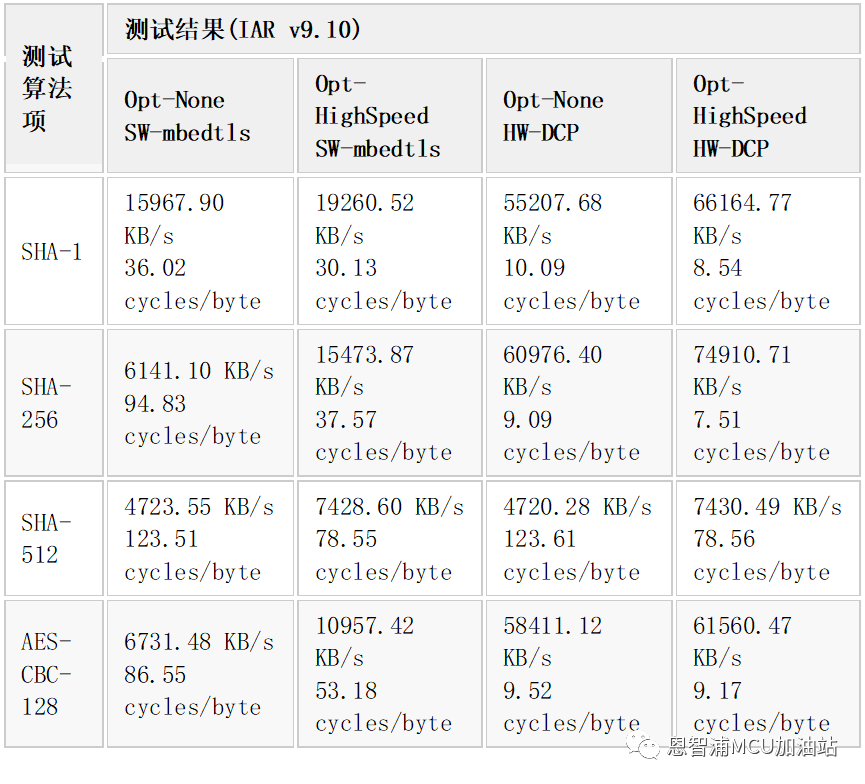
3,在i.MX RT1170上实测
与上一节同样的方法,在 MIMXRT1170-EVK 板子上也测一下,同样 mbedtls_benchmark 例程 debug build,注意 i.MX RT1170 是双核芯片,我们在 Cortex-M7 下做测试,将内核频率配到最高 996MHz。
测试i.MX RT1170 上纯软件方式时仅需要在工程选项预编译宏里将 CRYPTO_USE_DRIVER_CAAM去掉即可,当然也可以在 MIMXRT1176_cm7_features.h 里将下面这个宏临时设为 0,这时候没有代码空间顾虑,i.MX RT1170 上默认 ITCM 是 256KB。最终测试结果如下:
/* @brief CAAM availability on the SoC. */
#define FSL_FEATURE_SOC_CAAM_COUNT (0)
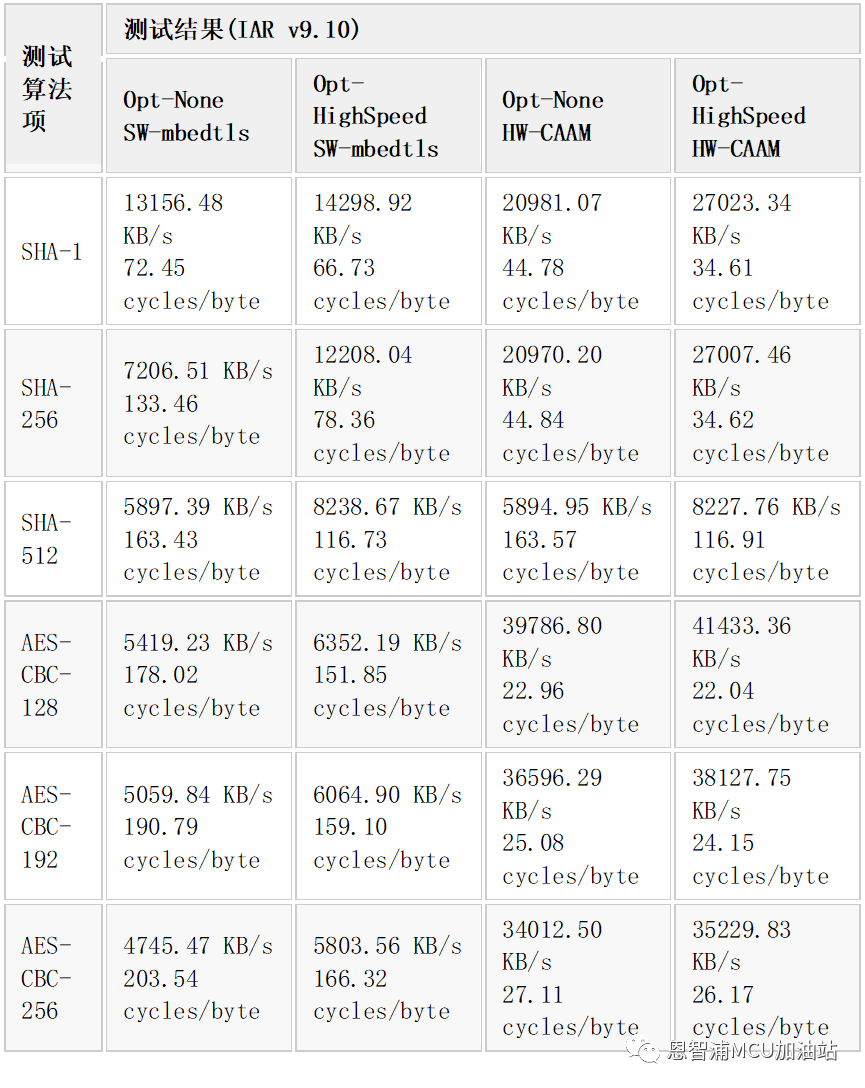
四、性能测试总结
结论1:使用硬件加速器CAAM模块/DCP模块,相比MbedTLS 纯软件实现,对于大部分算法性能都会有提升,但具体提升比例因算法本身复杂度而异。
结论2:硬件加速器方式提升比例较大的是3DES/DES(近10倍)、AES/ECDSA/ECDHE(近7倍)、RSA(3-5倍)、SHA-1/256(近2倍)。
结论3:硬件加速器方式对于部分算法,测试数据长度越大(默认1KB buffer,比如调到10KB),性能提升更明显。
结论4:编译器优化等级设置对 MbedTLS 纯软件和硬件加速器方式都有一定影响。
最后需要强调一点,这些测试数据仅作为参考,不代表硬件模块的真实能力,仅仅是基于当前软件环境的测试结果。
审核编辑 :李倩
-
PSoC 6 MCUBoot和mbedTLS是否支持加密硬件加速?2024-05-29 3264
-
H.264解码器中CABAC硬件加速器怎么实现?2021-06-07 1890
-
利用硬件加速器提高处理器的性能2017-12-04 1939
-
i.MX RT1052芯片的核心板,性能和代码详细资料概述2018-06-10 26675
-
01:i.MX RT的市场应用和参考解决方案2019-01-21 4536
-
i.MX RT开发笔记-08 | i.MX RT1062嵌套中断向量控制器NVIC(按键中断检测)2021-12-01 1151
-
RT-Thread & NXP 发布 i.MX RT 系列 BSP 新框架2021-12-07 1244
-
基于i.MX RT单芯片实现的GUI图形显示和语音控制解决方案2021-12-31 8529
-
移植Arm-2D到i.MX RT1050-EVKB并绘制图形界面2022-07-12 3813
-
适用于i.MX RT500和i.MX RT600 MCU的Xtensa音频框架介绍2022-11-10 4306
-
在i.MX RT10xx使用FlexIO实现XY2-100振镜控制协议2023-05-18 8242
-
i.MX RT的FlexRAM配置问题2023-10-24 1902
-
在i.MX RT1050上如何实现双大容量存储(MSC)设备2023-10-30 1480
-
在i.MX RT处理器上使用PXP实现缩放和旋转组合操作2025-02-20 2090
-
探索i.MX RT1180:高性能处理器的技术剖析与应用指南2025-12-24 1367
全部0条评论

快来发表一下你的评论吧 !
