

Turing网格着色器的使用介绍
描述
编程模型引入到图形管道中,因为协同使用线程在芯片上直接生成紧凑网格( meshlets ),供光栅化器使用。处理高几何复杂度的应用程序和游戏得益于两阶段方法的灵活性,该方法允许有效的剔除、详细程度的技术以及程序生成。
这篇文章介绍了新的管道,并给出了 GLSL 中用于 OpenGL 或 Vulkan 渲染的一些具体示例。新功能可以通过 OpenGL 和 Vulkan 中的扩展以及使用 DirectX 12 旗舰版 来访问。
以下大部分内容摘自此 录制的演示文稿 ,稍后将提供完整的幻灯片。
1网格着色管线
2网格和网格着色
3预计算网格
3.1数据结构
3.2呈现资源和数据流
3.3使用任务着色器进行簇消隐
4Conclusion
5References
动机
现实世界是一个视觉丰富、几何复杂的地方。尤其是室外场景可以由数十万种元素(岩石、树木、小植物等)组成。 CAD 模型在复杂形状的表面以及由许多小零件组成的机械上都存在类似的挑战。在视觉效果中,大型结构,例如宇宙飞船,通常都用“ greebles ”来详细说明。图 1 显示了几个例子,其中,具有顶点、细分和几何体着色器的图形管道、实例化和间接多重绘制虽然非常有效,但当全分辨率几何体达到数亿个三角形和数十万个对象时,仍然会受到限制。
上面未显示的其他用例包括在科学计算中发现的几何图形(粒子、字形、代理对象、点云)或程序形状( ele CTR ic 工程布局、 vfx 粒子、带状和轨迹、路径渲染)。
在这篇文章中,我们研究了 网格着色器 来加速重三角形网格的渲染。原始网格被分割成更小的 meshlets ,如图 2 所示。理想情况下,每个网格都可以优化其中的顶点重用。使用新的硬件阶段和这种分割方案,我们可以并行地绘制更多的几何图形,同时获取较少的总体数据。
例如, CAD 数据可以达到几千万到数亿个三角形。即使在 遮挡筛选 之后,也可以存在大量的三角形。在这种情况下,管道中的某些固定函数步骤可能会造成浪费的工作和内存负载:
通过硬件的 原始分配器 每次扫描 indexbuffer 来批量创建顶点,即使拓扑结构没有改变
获取不可见数据的顶点和属性(背面、视锥体或亚像素剔除)
网格着色器 为开发人员提供了避免此类瓶颈的新可能性。(例如,在第 4 个缓存中,与第 4 个缓存相对应)的方法(例如,在第 4 个缓存中,直接读取第 4 个三角形)。
网格着色器阶段为光栅化器生成三角形,但在内部使用协作线程模型,而不是使用单线程程序模型,类似于计算着色器。管道中网格着色器前面是任务着色器。任务着色器的操作类似于细分的控制阶段,因为它能够动态生成工作。但是,与网格着色器一样,它使用协作线程模型,而不是将面片作为输入,将细分决策作为输出,而是用户定义其输入和输出。
这简化了片上几何体的创建,与之前严格且有限的细分和几何体着色器相比,后者只需将线程用于特定任务。
网格着色管线
一个新的两阶段管道替代方案补充了经典的属性获取 顶点、细分、几何体着色器 管道。这条新管道由 任务着色器 和 网格着色器: 组成
任务着色器 :可编程单元,在工作组中工作,允许每个单元发射(或不发射)网格着色器工作组
网格着色器 :一种可编程单元,在工作组中运行,允许每个工作组生成原语
mesh shader stage 在内部使用上述协作线程模型为光栅化器生成三角形。任务着色器的操作类似于细分的外壳着色器阶段,因为它能够动态生成工作。但是,与网格着色器一样,任务着色器也使用协作线程模式。它的输入和输出是用户定义的,而不必将面片作为输入,将细分决策作为输出。
与 像素/片段着色器 的接口不受影响。传统的管道仍然可用,并且可以根据用例提供非常好的结果。图 4 突出显示了管道样式的差异。
新的网格着色器管道为开发人员提供了许多好处:
更高的可扩展性 通过着色器单元来减少原语处理中的固定函数影响。现代 GPUs 的通用用途有助于更多种类的应用程序添加更多内核,并提高着色器的通用内存和算术性能。
Bandwidth-reduction ,因为顶点的重复数据消除(顶点重用)可以预先完成,并且可以在多个帧上重复使用。当前的 API 模型意味着每次硬件都必须扫描索引缓冲区。较大的网格意味着更高的顶点重用率,也降低了带宽要求。此外,开发人员可以提出自己的压缩或过程生成方案。
通过 任务着色器 进行可选的扩展/筛选允许跳过完全获取更多数据。
Flexibility 定义网格拓扑和创建图形工作。以前的 细分着色器 仅限于固定的镶嵌模式,而 几何着色器 则存在线程效率低下、编程模型不友好的问题,每个线程都会创建三角形条带。
网格着色遵循 计算着色器 的编程模型,使开发人员可以自由地将线程用于不同的用途,并在线程之间共享数据。当光栅化被禁用时,这两个阶段还可以用于执行具有一个级别扩展的通用计算工作。
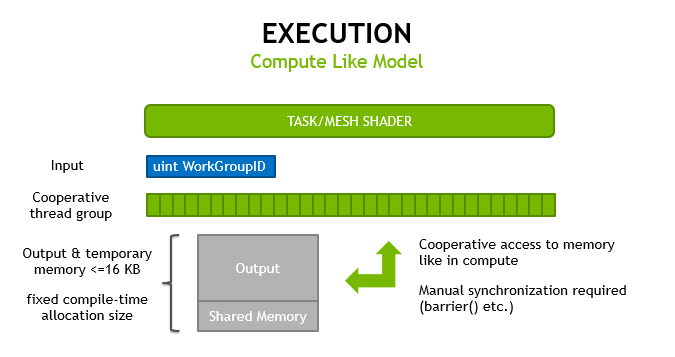
图 5 。网格着色器的行为类似于使用协作线程模型计算着色器。
这两个 网格和任务着色器 都遵循 计算着色器 的编程模型,使用协作线程组来计算结果,并有 除工作组索引外没有其他输入 。它们在图形管道上执行;因此硬件直接管理在级之间传递并保存在芯片上的内存。
我们将展示一个例子,说明如何使用它来进行基本体剔除,因为线程稍后可以访问工作组中的所有顶点。图 6 说明了任务着色器处理早期剔除的能力。
通过 任务着色器 进行的可选扩展允许对一组原语进行早期筛选或预先做出 LOD 决策。该机制在 GPU 上缩放,因此取代了小网格的实例化或多重绘制间接。此配置类似于 细分控制着色器 设置细分补丁(~ task workgroup )的数量,然后影响创建的 细分评估 调用(~ mesh workgroups )的数量。
单个 任务工作组 可以发射的 工作网格组 数量是有限制的。第一代硬件支持最多 64K 个子级,可以生成 每个任务 。在同一个绘制调用中,所有任务的网格子对象的总数没有限制。同样,如果不使用 任务着色器 ,则对 draw 调用生成的网格工作组的数量没有限制。图 7 说明了这是如何工作的。
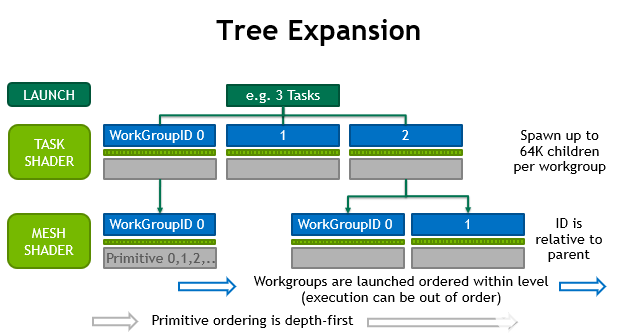
图 7 。网格着色器工作组流
任务 T 的子任务保证在任务 T-1 的子任务之后启动。但是, task 和 mesh 工作组是完全流水线的,因此不需要等待以前的子任务或任务的完成。
任务着色器 应用于动态工作生成或过滤。静态设置得益于单独使用 网格着色器 。
网格及其内部图元的栅格化输出顺序保持不变。禁用光栅化后,任务着色器和网格着色器都可以用于实现基本计算树。
网格和网格着色
每个网格单元表示数量可变的顶点和基本体。对于这些原语的连接性没有限制。但是,它们必须保持在着色器代码中指定的最大值以下。
我们建议最多使用 64 个顶点和 126 个基本体。 126 中的“ 6 ”不是打字错误。第一代硬件以 128 字节的粒度分配原始索引,并且需要为基元计数预留 4 个字节。因此 3 * 126 + 4 最大化了 3 * 128 = 384 字节块的大小。超过 126 个三角形将分配接下来的 128 个字节。 84 和 40 是其他适用于三角形的最大值。
在每个 GLSL mesh-shader 代码中,每个工作组在图形管道中为每个工作组分配固定数量的网格内存。
最大尺寸和原始输出定义如下:
每个网格单元的分配大小取决于编译时大小信息以及着色器引用的输出属性。分配越小,可以在硬件上并行执行的工作组越多。与 compute 一样,工作组共享他们可以访问的片上内存的公共部分。因此,我们建议您尽可能高效地使用所有输出或共享内存。对于当前着色器,这已经是正确的。但是,内存占用可能会更高,因为我们允许比当前编程中更多的顶点和基元。

图灵支持另一个新的 GLSL 扩展, NV_fragment_shader_barycentric ,它使片段着色器能够获取构成一个基本体的三个顶点的原始数据,并手动对其进行插值。这种原始访问意味着我们可以输出“ uint ”顶点属性,但是使用各种 pack / unpack 函数将浮点存储为 fp16 、 unorm8 或 snorm8 。这可以大大减少法线、纹理坐标和基本颜色值的逐顶点占用空间,并有利于标准和网格着色管道。
顶点和基本体的其他属性定义如下:

一个目标是拥有最小数量的网格,从而最大限度地提高网格中顶点的重用率,从而减少分配的浪费。在生成 meshlet 数据之前,在 indexbuffer 上应用顶点缓存优化器是有益的。例如, Tom Forsyth 的线性速度优化器 可用于此。优化顶点位置和索引缓冲区也是有益的,因为使用 网格着色器 时,原始三角形的顺序将保持不变。 CAD 模型通常是用条带“自然”生成的,因此可以具有良好的数据局部性。更改索引缓冲区可能会对此类数据的 meshlet 的簇剔除属性产生负面影响(请参见任务级消隐)。
预计算网格
例如,我们呈现静态内容,其中 索引缓冲区 在许多帧中没有变化。因此,在将顶点/索引上载到设备内存期间,生成网格数据的成本可以隐藏起来。当 vertex 数据也是静态的(没有逐顶点动画;顶点位置没有变化)时,还可以获得额外的好处,允许预先计算对快速剔除整个网格单元有用的数据。
数据结构
在以后的示例中,我们将提供一个 meshlet 构建器,它包含一个基本实现,该实现扫描所提供的索引,并在每次遇到大小限制(顶点或基元计数)时创建一个新的 meshlet 。
对于输入三角形网格,它将生成以下数据:

为什么有两个索引缓冲区?
以下原始三角形索引缓冲区序列

一旦达到适当的大小限制(要么是唯一顶点太多,要么是基本体太多),就会启动一个新的网格单元。随后的网格将创建自己的唯一顶点集。
呈现资源和数据流
在渲染期间,我们使用原始顶点缓冲区。但是,我们使用了三个新的缓冲区,而不是原来的三角形索引缓冲区,如下图 8 所示:
顶点索引缓冲区 如上所述。每个网格单元引用一组唯一的顶点。这些顶点的索引按顺序存储在所有网格单元的缓冲区中。
原始索引缓冲区 如上所述。每个网格单元表示不同数量的基本体。每个三角形需要三个原始索引,这些索引存储在一个缓冲区中。 Note :可以在每个 meshlet 之后添加额外的索引以获得四字节对齐。
Meshlet Desc 缓冲区。 存储每个网格单元的工作负载和缓冲区偏移信息,以及集群剔除信息。
这三个缓冲区实际上比原始索引缓冲区小,因为网格着色允许更高的顶点重用。我们注意到,通常会将索引缓冲区大小减少到原始索引缓冲区大小的 75% 左右。
网格顶点: vertexBegin 存储开始获取顶点索引的起始位置。 vertexCount 存储所涉及的连续顶点的数量。顶点在网格单元中是唯一的;没有重复的索引值。
网格元素: primBegin 存储原始索引的起始位置,我们将从那里开始获取索引。 primCount 存储 meshlet 中涉及的基本体数量。注意,索引的数量取决于基本体类型(这里: 3 表示三角形)。请注意,索引引用的是相对于 vertexBegin 的顶点,这意味着索引“ 0 ”将引用位于 vertexBegin 的顶点索引。
下面的伪代码描述了每个 网格着色器 工作组在原则上执行的操作。它是串行的,仅用于说明目的。

当以并行方式编写时,网格着色器可能看起来如下所示:
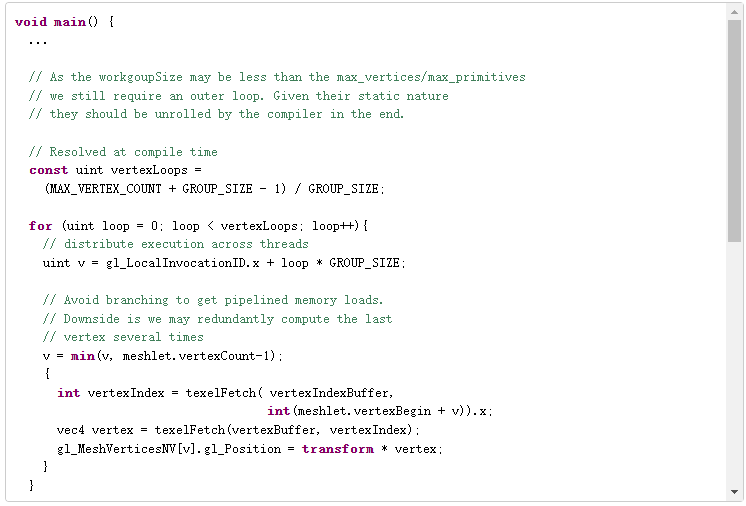
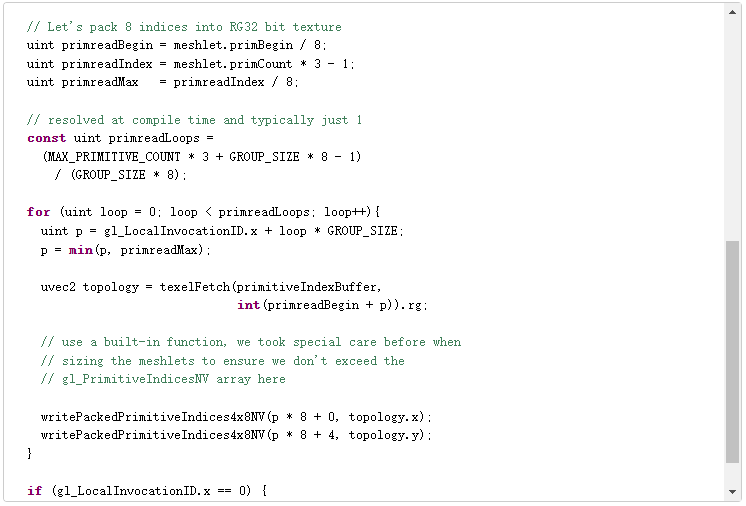

这就是一个直接的例子。由于所有数据获取都是由开发人员完成的,自定义编码、通过子组内部函数或共享内存进行解压缩,或者暂时使用顶点输出,都可以节省额外的带宽。
使用任务着色器进行簇消隐
我们尝试将更多的信息压缩到一个 meshlet 描述符中以执行早期剔除。我们已经尝试使用 128 位描述符对前面提到的值进行编码,以及 G.Wihlidal 提出的用于背面聚类剔除的相对 bbox 和一个圆锥体。在生成网格时,需要在良好的簇剔除特性和改进的顶点重用之间取得平衡。一方可能对另一方产生负面影响。
下面的任务着色器最多可剔除 32 个网格。
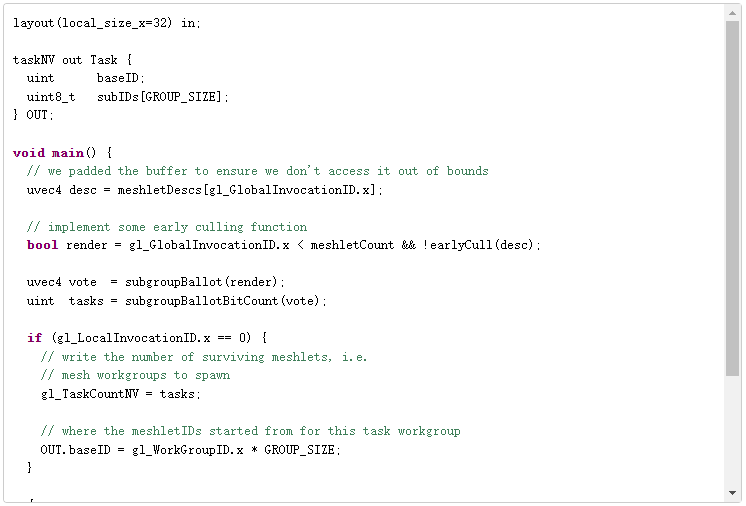

相应的网格着色器现在使用来自任务着色器的信息来标识要生成的网格。

我们只在渲染大三角形模型的上下文中剔除任务着色器中的网格。其他场景可能涉及到根据细节决策的级别选择不同的 meshlet 数据,或者完全生成几何体(粒子、色带等)。下面的图 9 来自一个使用任务着色器进行详细级别计算的演示。
Conclusion
一些关键的收获:
通过扫描索引缓冲区一次,可以将三角形网格转换为网格。顶点缓存优化器有助于经典渲染,也有助于提高网格填充效率。更复杂的聚类允许改进任务着色器阶段的早期拒绝(更紧密的边界框、一致的三角形法线等)。
在硬件需要为片上 网格着色器 调用分配顶点/基元内存之前, 任务着色器 允许提前跳过一组原语。如果需要,它还可以生成多个子调用。
顶点在工作组的线程中并行处理,就像原始的 顶点渲染 一样。
顶点着色器 可以与 网格着色器 兼容,并带有一些预处理器插入。
由于更高的顶点重用,需要提取的数据更少(经典顶点着色器的操作限制为 max _ vertices = 32 , max _ primitives = 32 )。平均三角形网格价意味着使用两倍数量的三角形作为顶点是有益的。
所有数据加载都是通过着色器指令来处理的,而不是经典的固定函数原语 fetch ,因此使用更多的 流式多处理器 可以更好地伸缩。它还允许更容易地使用自定义顶点编码来进一步减少带宽。
对于顶点属性的大量使用,同样并行操作的基本消隐阶段可能是有益的。我们可以剔除掉顶点数据。然而,最好的收获是在任务级别进行有效的筛选。
关于作者
Christoph Kubisch 是 NVIDIA 公司的高级开发技术工程师,专注于 OpenGL 和 Vulkan 实时渲染技术,适用于 CAD / DCC 和科学应用。他与外部合作伙伴和 NVIDIA 的内部团队合作,优化当前和未来的渲染算法。在加入 NVIDIA 之前, Christoph 是马格德堡 Otto von Guericke 大学医学数据集硬件加速可视化技术的研究人员。此外,他还作为技术艺术家创作游戏艺术、技术和 DCC 插件开发。
审核编辑:郭婷
- 相关推荐
- 热点推荐
- NVIDIA
-
如何使用马里脱机编译器来分析着色器程序的性能2023-08-28 652
-
实时3D艺术最佳实践-材料和着色器用户指南2023-08-02 735
-
IMX OpenGL着色器问题如何解决?2023-04-20 626
-
网格着色器的最佳实践2022-04-01 2364
-
从零开始学3D着色器编程2019-05-16 4503
-
NVIDIA宣布推出面向游戏笔记本电脑的GeForce® GTX® 1660 Ti 和1650 Turing GPU2019-04-28 7737
-
GPU光栅化阶段和几何阶段的术语介绍2018-05-07 3405
-
地形网格细分的层次细节LOD地形渲染算法2018-01-09 1887
全部0条评论

快来发表一下你的评论吧 !
