

如何使用TensorRT 8.0进行实时自然语言处理
描述
大规模语言模型( LSLMs )如 BERT 、 GPT-2 和 XL-Net 为许多自然语言处理( NLP )任务带来了令人兴奋的精度飞跃。自 2018 年 10 月发布以来, BERT (来自变形金刚的双向编码器表示)及其众多变体仍然是最流行的语言模型之一, 仍然提供最先进的准确性 。
BERT 为 NLP 任务提供了准确度上的飞跃,为许多行业的公司提供了高质量、基于语言的服务。为了在生产中使用该模型,您必须考虑延迟和准确性等因素,这些因素影响最终用户对服务的满意度。 BERT 由于其 12 / 24 层堆叠、多头注意力网络,需要在推理过程中进行重要计算。这对公司部署 ZVK7]作为实时应用的一部分提出了挑战。
今天, NVIDIA 发布了 TensorRT 的第 8 版,在 NVIDIA A100 GPU 上, BERT-Large 的推理延迟降低到 1. 2 毫秒,并对基于 transformer 网络进行了新的优化。 TensorRT 中新的广义优化方法可以加速所有这些模型,将推理时间减少到 TensorRT 7 的一半。
TensorRT
TensorRT 是一个用于高性能、深入学习推理的平台,它包括一个优化程序和运行时,可以最大限度地减少延迟和提高生产中的吞吐量。使用 TensorRT ,您可以优化在所有主要框架中训练的模型,以高精度校准较低的精度,并最终部署到生产中。
在这个 NVIDIA/TensorRT GitHub repo 中,所有用 BERT 实现这一性能的代码都将作为开源发布,它是 BERT 编码器的一个基本构建块,因此您可以将这些优化应用于任何基于 BERT 的 NLP 任务。 BERT 应用于会话 AI 之外的一组扩展的语音和 NLP 应用程序,所有这些应用程序都可以利用这些优化。
问答( QA )或阅读理解是测试模型理解上下文能力的一种流行方法。团队 leaderboard 为他们提供的数据集和测试集跟踪此任务的最佳执行者。在过去的几年里,随着学术界和企业的全球性贡献, QA 能力得到了迅速的发展。
在本文中,我们将演示如何使用 Python 创建一个简单的 QA 应用程序,该应用程序由今天发布的 TensorRT 优化的 BERT 代码提供支持。该示例提供了一个 API 来输入段落和问题,并返回由 BERT 模型生成的响应。
下面简要回顾一下使用 TensorRT 对 BERT 执行训练和推理的步骤。
BERT 训练和推理管道
NLP 研究人员和开发人员面临的一个主要问题是缺乏高质量的标记训练数据。为了克服从零开始学习任务模型的问题, NLP 的突破使用了大量的未标记文本,并将 NLP 任务分为两部分:
学习表达单词的意义,它们之间的关系,即使用辅助任务和大量文本建立语言模型
通过使用一个相对较小的、特定于任务的、以有监督的方式训练的网络来扩充语言模型,从而将语言模型专门化为实际任务。
这两个阶段通常称为预训练和微调。这种范式允许使用预先训练的语言模型来处理广泛的任务,而不需要对模型架构进行任何特定于任务的更改。在本例中, BERT 提供了一个高质量的语言模型,该模型针对 QA 进行了微调,但适用于其他任务,如句子分类和情感分析。
您可以从在线提供的预训练检查点开始,也可以从您自己的定制语料库上的预训练 BERT 开始(图 1 )。您还可以从检查点初始化预训练,然后继续对自定义数据进行训练。
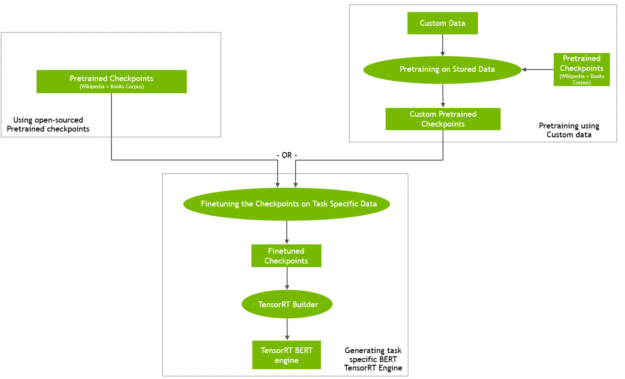
图 1 从预先训练的检查点生成 BERT TensorRT 引擎
使用自定义或特定领域的数据进行预训练可能会产生有趣的结果,例如 BioBert 。然而,它是计算密集型的,需要一个大规模的并行计算基础设施才能在合理的时间内完成。 GPU – 启用的多节点训练是此类场景的理想解决方案。有关 NVIDIA 开发人员如何在不到一小时的时间内培训 BERT 的更多信息,请参阅 使用 GPU s 培训 BERT 。
在微调步骤中,使用特定任务训练数据训练基于预训练 BERT 语言模型的特定任务网络。对于 QA ,这是(段落、问题、答案)三倍。与预训练相比,微调的计算要求通常要低得多。
使用 QA 神经网络进行推理:
通过将微调的权重和网络定义传递给 TensorRT 生成器来创建 TensorRT 引擎。
使用此引擎启动 TensorRT 运行时。
向 TensorRT 运行时提供一篇文章和一个问题,并接收网络预测的答案作为输出。
图 2 显示了整个工作流。

图 2 使用 TensorRT 运行时引擎对 BERT QA 任务执行推断的工作流
运行样本!
通过以下步骤设置环境以执行 BERT 推断:
创建具有先决条件的 Docker 映像。
从微调的重量构建 TensorRT 引擎。
对给定的段落和问题进行推理。
我们使用脚本来执行这些步骤,您可以在 TensorRT BERT 样本回购 中找到这些步骤。虽然我们描述了可以传递给每个脚本的几个选项,但为了快速入门,您还可以运行以下代码示例:
# Clone the TensorRT repository and navigate to BERT demo directory git clone --recursive https://github.com/NVIDIA/TensorRT && cd TensorRT # Create and launch the Docker image # Here we assume the following: # - the os being ubuntu-18.04 (see below for other supported versions) # - cuda version is 11.3.1 bash docker/build.sh --file docker/ubuntu-18.04.Dockerfile --tag tensorrt-ubuntu18.04-cuda11.3 --cuda 11.3.1 # Run the Docker container just created bash docker/launch.sh --tag tensorrt-ubuntu18.04-cuda11.3 --gpus all # cd into the BERT demo folder cd $TRT_OSSPATH/demo/BERT # Download the BERT model fine-tuned checkpoint bash scripts/download_model.sh # Build the TensorRT runtime engine. # To build an engine, use the builder.py script. mkdir -p engines && python3 builder.py -m models/fine-tuned/bert_tf_ckpt_large_qa_squad2_amp_128_v19.03.1/model.ckpt -o engines/bert_large_128.engine -b 1 -s 128 --fp16 -c models/fine-tuned/bert_tf_ckpt_large_qa_squad2_amp_128_v19.03.1
最后一个命令使用混合精度( --fp16 )和 -s 128 大队 v2 FP16 序列长度 128 检查点( -c models/fine-tuned/bert_tf_ckpt_large_qa_squad2_amp_128_v19.03.1 )构建最大批大小为 1 ( BERT )、序列长度为 128 ( -s 128 )的引擎。
现在,给它一段话,通过问几个问题,看看它能破译多少信息。
python3 inference.py -e engines/bert_large_128.engine -p "TensorRT is a high performance deep learning inference platform that delivers low latency and high throughput for apps such as recommenders, speech and image/video on NVIDIA GPUs. It includes parsers to import models, and plugins to support novel ops and layers before applying optimizations for inference. Today NVIDIA is open-sourcing parsers and plugins in TensorRT so that the deep learning community can customize and extend these components to take advantage of powerful TensorRT optimizations for your apps." -q "What is TensorRT?" -v models/fine-tuned/bert_tf_ckpt_large_qa_squad2_amp_128_v19.03.1/vocab.txt
此命令的结果应类似于以下内容:
Passage: TensorRT is a high performance deep learning inference platform that delivers low latency and high throughput for apps such as recommenders, speech and image/video on NVIDIA GPUs. It includes parsers to import models, and plugins to support novel ops and layers before applying optimizations for inference. Today NVIDIA is open-sourcing parsers and plugins in TensorRT so that the deep learning community can customize and extend these components to take advantage of powerful TensorRT optimizations for your apps.
Question: What is TensorRT? Answer: 'a high performance deep learning inference platform'
对同一篇文章提出不同的问题,你应该得到以下结果:
Question: What is included in TensorRT? Answer: 'parsers to import models, and plugins to support novel ops and layers before applying optimizations for inference'
该模型提供的答案基于所提供的文章的文本是准确的,样本使用 FP16 精度与 TensorRT 进行推理。这有助于在 NVIDIA GPU s 的张量核上实现尽可能高的性能。在我们的测试中,我们测量了 TensorRT 的精确度,与 FP16 精度的框架内推理相当。
脚本选项
以下是脚本可用的选项, docker/build.sh 脚本使用 docker 文件夹中提供的 docker 文件构建 docker 映像。它安装所有必需的包,具体取决于您选择作为 docker 文件的操作系统。在本文中,我们使用了 ubuntu-18 。 04 ,但也提供了 ubuntu-16 。 04 和 ubuntu-20 。 04 的 dockerfiles 。
按如下方式运行脚本:
bash docker/build.sh --file docker/ubuntu-xx.04.Dockerfile --tag tensorrt-tag --cuda cuda_version
创建并运行环境后,下载 BERT 的微调权重。请注意,创建 TensorRT 引擎不需要预先训练的权重(只需要微调的权重)。在微调权重的同时,使用相关的配置文件,该文件指定了注意头数、层数等参数,以及 vocab 。 txt 文件,该文件包含从训练过程中学习到的词汇表;使用 download _ model 。 sh 脚本下载它们。作为此脚本的一部分,您可以指定要下载的 BERT 模型的微调权重集。命令行参数控制精确的 BERT 模型,以便稍后用于模型构建和推断:
sh download_model.sh [tf|pyt] [base|large|megatron-large] [128|384] [v2|v1_1] [sparse] [int8-qat] tf | pyt tensorflow or pytorch version base | large | megatron-large - determine whether to download a BERT-base or BERT-large or megatron model to optimize 128 | 384 - determine whether to download a BERT model for sequence length 128 or 384 v2 | v1_1, fine-tuned on squad2 or squad1.1 sparse, download sparse version int8-qat, download int8 weights
Examples:
# Running with default parametersbash download_model.sh# Running with custom parameters (BERT-large, FP32 fine-tuned weights, 128 sequence length)sh download_model.sh large tf fp32 128
默认情况下,此脚本下载微调的 TensorFlow BERT -large ,精度为 FP16 ,序列长度为 128 。除了微调的模型外,还可以使用配置文件、枚举模型参数和词汇表文件将 BERT 模型输出转换为文本答案。
接下来,您可以构建 BERT 引擎并将其用于 QA 示例,即推理。脚本 builder.py 基于下载的 TensorRT 微调模型构建用于推理的 TensorRT 引擎。
确保提供给以下脚本的序列长度与下载的模型的序列长度匹配。
python3 builder.py [-h] [-m CKPT] [-x ONNX] [-pt PYTORCH] -o OUTPUT [-b BATCH_SIZE] [-s SEQUENCE_LENGTH] -c CONFIG_DIR [-f] [-i] [-t] [-w WORKSPACE_SIZE] [-j SQUAD_JSON] [-v VOCAB_FILE] [-n CALIB_NUM] [-p CALIB_PATH] [-g] [-iln] [-imh] [-sp] [-tcf TIMING_CACHE_FILE]
以下是可选参数:
-h, --help show this help message and exit -m CKPT, --ckpt CKPT The checkpoint file basename, e.g.: basename(model.ckpt-766908.data-00000-of-00001) is model.ckpt-766908 (default: None) -x ONNX, --onnx ONNX The ONNX model file path. (default: None) -pt PYTORCH, --pytorch PYTORCH The PyTorch checkpoint file path. (default: None) -o OUTPUT, --output OUTPUT The bert engine file, ex bert.engine (default: bert_base_384.engine) -b BATCH_SIZE, --batch-size BATCH_SIZE Batch size(s) to optimize for. The engine will be usable with any batch size below this, but may not be optimal for smaller sizes. Can be specified multiple times to optimize for more than one batch size.(default: []) -s SEQUENCE_LENGTH, --sequence-length SEQUENCE_LENGTH Sequence length of the BERT model (default: []) -c CONFIG_DIR, --config-dir CONFIG_DIR The folder containing the bert_config.json, which can be downloaded e.g. from https://github.com/google-research/bert#pre-trained-models (default: None) -f, --fp16 Indicates that inference should be run in FP16 precision (default: False) -i, --int8 Indicates that inference should be run in INT8 precision (default: False) -t, --strict Indicates that inference should be run in strict precision mode (default: False) -w WORKSPACE_SIZE, --workspace-size WORKSPACE_SIZE Workspace size in MiB for building the BERT engine (default: 1000) -j SQUAD_JSON, --squad-json SQUAD_JSON squad json dataset used for int8 calibration (default: squad/dev-v1.1.json) -v VOCAB_FILE, --vocab-file VOCAB_FILE Path to file containing entire understandable vocab (default: ./pre-trained_model/uncased_L-24_H-1024_A-16/vocab.txt) -n CALIB_NUM, --calib-num CALIB_NUM calibration batch numbers (default: 100) -p CALIB_PATH, --calib-path CALIB_PATH calibration cache path (default: None) -g, --force-fc2-gemm Force use gemm to implement FC2 layer (default: False) -iln, --force-int8-skipln Run skip layernorm with INT8 (FP32 or FP16 by default) inputs and output (default: False) -imh, --force-int8-multihead Run multi-head attention with INT8 (FP32 or FP16 by default) input and output (default: False) -sp, --sparse Indicates that model is sparse (default: False) -tcf TIMING_CACHE_FILE, --timing-cache-file TIMING_CACHE_FILE Path to tensorrt build timeing cache file, only available for tensorrt 8.0 and later (default: None)
Example:
python3 builder.py -m models/fine-tuned/bert_tf_ckpt_large_qa_squad2_amp_128_v19.03.1/model.ckpt -o engines/bert_large_128.engine -b 1 -s 128 --fp16 -c models/fine-tuned/bert_tf_ckpt_large_qa_squad2_amp_128_v19.03.1
现在您应该有一个 TensorRT 引擎 engines/bert_large_128.engine ,用于 QA 的 inference.py 脚本。
在本文后面,我们将描述构建 TensorRT 引擎的过程。现在,您可以向 inference.py 提供一篇文章和一个查询,并查看模型是否能够正确回答您的查询。
与推理脚本交互的方法很少:
段落和问题可以使用 –通道 和 –问题 标志作为命令行参数提供。
它们可以使用 – U 文件 和 –问题文件 标志从给定的文件传入。
如果在执行过程中没有给出这两个标志,则在执行开始后,系统会提示您输入段落和问题。
以下是 inference.py 脚本的参数:
Usage: inference.py [-h] [-e ENGINE] [-b BATCH_SIZE] [-p [PASSAGE [PASSAGE ...]]] [-pf PASSAGE_FILE] [-q [QUESTION [QUESTION ...]]] [-qf QUESTION_FILE] [-sq SQUAD_JSON] [-o OUTPUT_PREDICTION_FILE] [-v VOCAB_FILE] [-s SEQUENCE_LENGTH] [--max-query-length MAX_QUERY_LENGTH] [--max-answer-length MAX_ANSWER_LENGTH] [--n-best-size N_BEST_SIZE] [--doc-stride DOC_STRIDE]
这个脚本使用一个预先构建的 TensorRT BERT QA 引擎来根据提供的文章回答问题。
以下是可选参数:
-h, --help show this help message and exit -e ENGINE, --engine ENGINE Path to BERT TensorRT engine -b BATCH_SIZE, --batch-size BATCH_SIZE Batch size for inference. -p [PASSAGE [PASSAGE ...]], --passage [PASSAGE [PASSAGE ...]] Text for paragraph/passage for BERT QA -pf PASSAGE_FILE, --passage-file PASSAGE_FILE File containing input passage -q [QUESTION [QUESTION ...]], --question [QUESTION [QUESTION ...]] Text for query/question for BERT QA -qf QUESTION_FILE, --question-file QUESTION_FILE File containing input question -sq SQUAD_JSON, --squad-json SQUAD_JSON SQuAD json file -o OUTPUT_PREDICTION_FILE, --output-prediction-file OUTPUT_PREDICTION_FILE Output prediction file for SQuAD evaluation -v VOCAB_FILE, --vocab-file VOCAB_FILE Path to file containing entire understandable vocab -s SEQUENCE_LENGTH, --sequence-length SEQUENCE_LENGTH The sequence length to use. Defaults to 128 --max-query-length MAX_QUERY_LENGTH The maximum length of a query in number of tokens. Queries longer than this will be truncated --max-answer-length MAX_ANSWER_LENGTH The maximum length of an answer that can be generated --n-best-size N_BEST_SIZE Total number of n-best predictions to generate in the nbest_predictions.json output file --doc-stride DOC_STRIDE When splitting up a long document into chunks, what stride to take between chunks
BERT 与 TensorRT 的推理
有关推理过程的逐步描述和演练,请参见示例文件夹中的 Python script inference 。 py 和详细的 Jupyter notebook inference 。 ipynb 。下面是使用 TensorRT 执行推理的几个关键参数和概念。
BERT 或更具体地说,编码器层使用以下参数来控制其操作:
批量大小
序列长度
注意头数
这些参数的值取决于所选的 BERT 模型,用于设置 TensorRT 计划文件(执行引擎)的配置参数。
对于每个编码器,还指定隐藏层的数量和注意头的大小。您还可以从 TensorFlow 检查点文件中读取所有早期参数。
由于我们正在使用的 BERT 模型已经针对 SQuAD 数据集上 QA 的下游任务进行了微调,因此网络的输出(即输出完全连接层)是一段文本,其中答案出现在文章中,在示例中称为 h ï U 输出。生成 TensorRT 引擎之后,您可以序列化它,稍后在 TensorRT 运行时使用它。
在推理过程中,异步执行从 CPU 到 GPU 的内存复制和反向操作,分别将张量放入和移出 GPU 内存。异步内存复制操作通过与设备和主机之间的内存复制操作重叠计算来隐藏内存传输的延迟。图 3 显示了异步内存拷贝和内核执行。
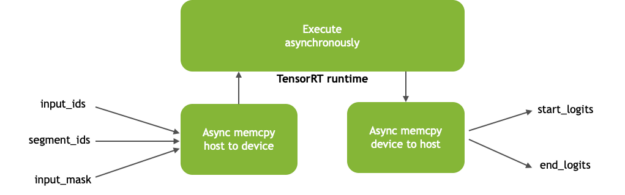
图 3 。 TensorRT 运行时流程
BERT 模型(图 3 )的输入包括:
input_ids :带有段落标记 ID 的张量与用作推理输入的问题串联在一起
segment_ids :区分段落和问题
input_mask :指示序列中哪些元素是标记,哪些是填充元素
输出( start_logits 和 end_logits )表示答案的范围,网络根据问题在文章中预测答案的范围。
基准测试 BERT 推理性能
BERT 可以应用于在线和离线用例。在线 NLP 应用程序,如会话人工智能,在推理过程中占用了紧张的延迟预算。为了响应单个用户的查询,需要按顺序执行多个模型。当用作服务时,客户体验的总时间包括计算时间以及输入和输出网络延迟。时间越长,性能越差,客户体验越差。
虽然单个模型的准确延迟可能因应用程序而异,但一些实时应用程序需要在 10 毫秒内执行语言模型。
使用 NVIDIA 安培架构 A100 GPU , BERT – 用 TensorRT 8 优化的大可以在 1 。 2ms 内对 QA 任务执行推断,类似于批大小为 1 、序列长度为 128 的团队中可用的任务。
使用 TensorRT 优化样本,您可以在 10ms 延迟预算内为 BERT -base 或 BERT -large 执行不同的批处理大小。例如,在 TensorRT 8 的 A30 上,序列长度= 384 批大小= 1 的 BERT 大型模型的推断延迟为 3 。 62ms 。同样的模型,序列长度= 384 ,在 CPU 平台上高度优化代码(**),批量大小= 1 是 76ms 。
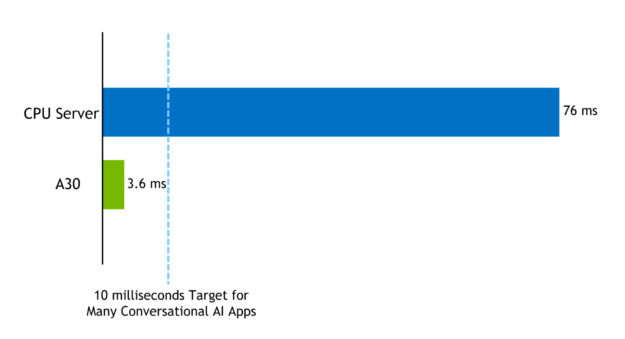
图 4 。在 NVIDIA A30 GPU 服务器上执行 BERT -large 与仅 CPU 服务器上执行 BERT -large 的计算延迟(毫秒)
性能度量在将张量作为输入传递和将 logit 作为输出收集之间,在 QA 任务上执行网络的纯计算延迟时间。您可以在 repo 中的 scripts / inference \ u benchmark 。 sh 脚本中找到用于对示例进行基准测试的代码。
概括
NVIDIA 正在发布 TensorRT 8 。 0 ,这使得在 A30 GPU s 上以 0 。 74ms 的时间执行 BERT 推断成为可能。 BERT 上的基准测试推断代码在 TensorRT 开源 repo 中作为示例提供。
本文概述了如何使用 TensorRT 示例和性能结果。我们进一步描述了如何将 BERT 示例作为简单应用程序和 Jupyter 笔记本的一部分来使用的工作流,您可以在其中传递一个段落并提出与之相关的问题。新的优化和可实现的性能使 BERT 在生产中用于延迟预算紧张的应用程序(如会话人工智能)变得切实可行。
关于作者
Purnendu Mukherjee 是一名高级深度学习软件工程师,在 NVIDIA 的人工智能应用小组工作。他的主要工作是将最先进的、基于深度学习的语音和自然语言处理模型作为开发 Jarvis 平台的一部分投入生产。在加入 NVIDIA 之前, PurnNuu 毕业于佛罗里达大学,拥有计算机科学硕士学位,专门从事基于自然语言的深度学习。
Eddie Weill 是 NVIDIA 的解决方案架构师,专门帮助企业客户开发深度学习和加速计算解决方案。在担任当前职务之前,他曾在智能视频分析集团 NVIDIA 从事智能城市深度学习模型开发工作。作为博士学位的一部分,他专注于计算机视觉和嵌入式系统应用的深度学习。在克莱姆森大学的研究生学习期间,他专注于深度学习以及一些高性能计算应用。
Rohit Taneja 是 NVIDIA 的解决方案架构师,专注于机器学习和推理相关的部署。在加入 NVIDIA 之前,他曾在 IBM 的系统实验室担任性能架构师和工程师,以支持数据中心环境中的机器学习工作负载加速。他获得了北卡罗来纳州立大学的硕士学位,论文的主题是“ ELD CTR ”电路的自动软控制,以提高能效。
Davide Onofrio 是 NVIDIA 的高级深度学习软件技术营销工程师。他在 NVIDIA 专注于深度学习技术开发人员关注内容的开发和演示。戴维德在生物特征识别、虚拟现实和汽车行业担任计算机视觉和机器学习工程师已有多年经验。他的教育背景包括米兰理工学院的信号处理博士学位。
About Young-Jun Ko
Young-Jun Ko 是 NVIDIA 的 AI 开发技术工程师,目前正在 GPU 上加速 NLP 推理工作负载。此前,他曾在 HPC 和 AI 领域工作,并为 RAPIDS 开源项目做出了贡献。在加入 NVIDIA 之前,杨军获得了 EPFL 的计算机科学博士学位,并在一家 adtech 初创公司担任机器学习工程师。
About Siddharth Sharma
Siddharth Sharma 是NVIDIA 加速计算的高级技术营销经理。在加入NVIDIA 之前, Siddharth 是 Mathworks Simulink 和 Stateflow 的产品营销经理,与汽车和航空航天公司密切合作,采用基于模型的设计来创建控制软件。
审核编辑:郭婷
-
自然语言处理包括哪些内容2024-07-03 3102
-
自然语言处理的概念和应用 自然语言处理属于人工智能吗2023-08-23 2868
-
什么是自然语言处理2021-09-08 2775
-
自然语言处理(NLP)的学习方向2020-07-06 14302
-
求自然语言处理笔记2020-06-04 2874
-
自然语言处理的词性标注方法2020-04-21 2279
-
自然语言处理的语言模型2020-04-16 2805
-
自然语言处理的分词方法2020-03-19 1502
-
【推荐体验】腾讯云自然语言处理2019-10-09 2942
-
多个视角对自然语言处理领域进行全面梳理2019-05-19 4677
-
采用深度学习对自然语言处理进行分类2018-11-05 4434
-
python自然语言2018-05-02 6428
-
什么是自然语言处理_自然语言处理常用方法举例说明2017-12-28 18821
全部0条评论

快来发表一下你的评论吧 !
