

响应式编程在Android开发中的实践
描述
Flow 是一种基于流的编程模型,本文我们将向大家介绍响应式编程以及其在 Android 开发中的实践,您将了解到如何将生命周期、旋转及切换到后台等状态绑定到 Flow 中,并且测试它们是否能按照预期执行。
单向数据流
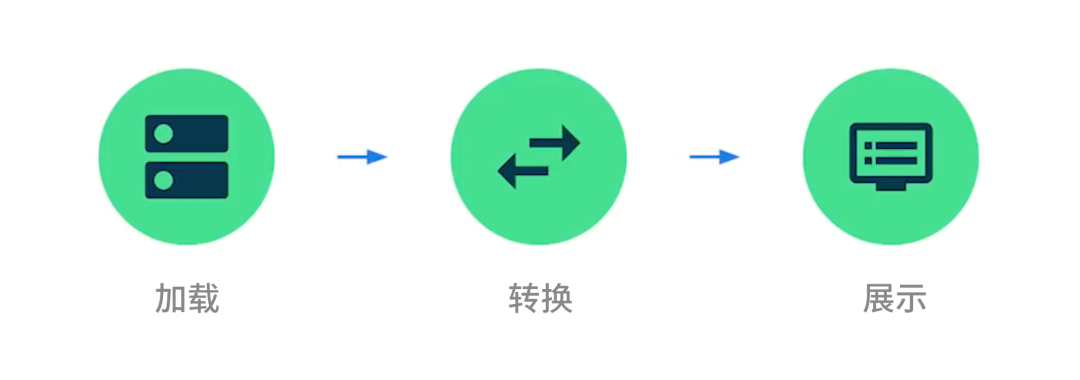
△ 加载数据流的过程
每款 Android 应用都需要以某种方式收发数据,比如从数据库获取用户名、从服务器加载文档,以及对用户进行身份验证等。接下来,我们将介绍如何将数据加载到 Flow,然后经过转换后暴露给视图进行展示。
为了大家更方便地理解 Flow,我们以 Pancho (潘乔) 的故事来展开。当住在山上的 Pancho 想从湖中获取淡水时,会像大多数新手一开始一样,拿个水桶走到湖边取水,然后再走回来。

△ 山上的 Pancho
但有时 Pahcho 不走运,走到湖边时发现湖水已经干涸,于是就不得不再去别处寻找水源。发生了几次这种情况后,Pancho 意识到,搭建一些基础设施可以解决这个问题。于是他在湖边安装了一些管道,当湖中有水时,只用拧开水龙头就能取到水。知道了如何安装管道,就能很自然地想到从多个水源地把管道组合,这样一来 Pancho 就不必再检查湖水是否已经干涸。

在 Android 应用中您可以简单地在每次需要时请求数据,例如我们可以使用挂起函数来实现在每次视图启动时向 ViewModel 请求数据,而后 ViewModel 又向数据层请求数据,接下来这一切又在相反的方向上发生。不过这样过了一段时间之后,像 Pancho 这样的开发者们往往会想到,其实有必要投入一些成本来构建一些基础设施,我们就可以不再请求数据而改为观察数据。观察数据就像安装取水管道一样,部署完成后对数据源的任何更新都将自动向下流动到视图中,Pancho 再也不用走到湖边去了。
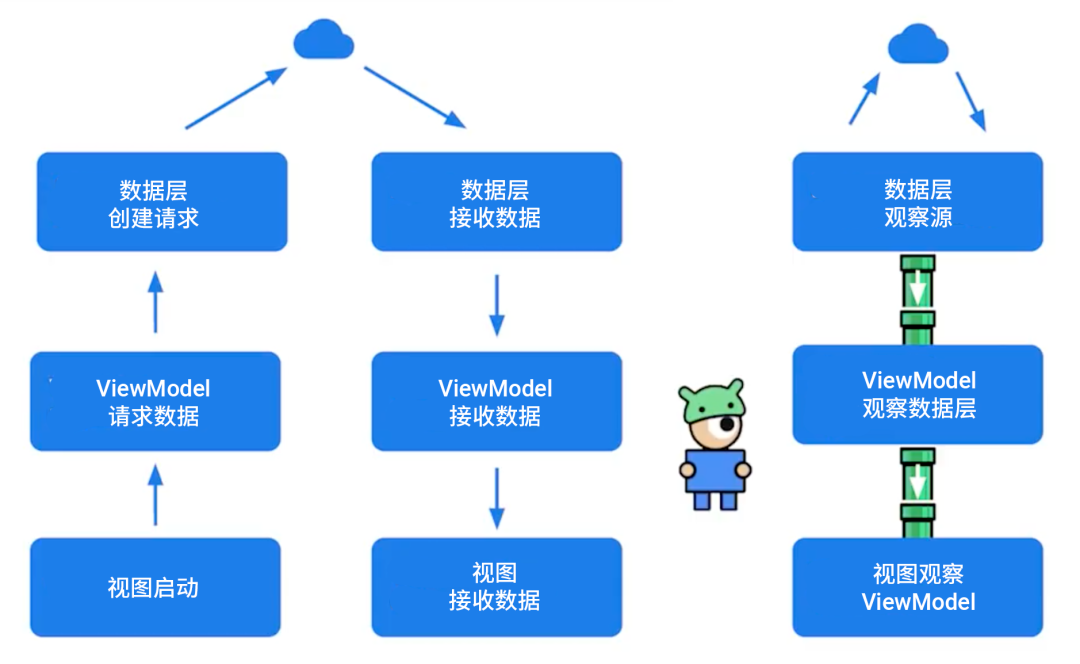
△ 传统的请求数据与单向数据流
响应式编程
我们将这类观察者会自动对被观察者对象的变化而作出反应的系统称之为响应式编程,它的另一个设计要点是保持数据只在一个方向上流动,因为这样更容易管理且不易出错。 某个示例应用界面的 "数据流动" 如下图所示,身份认证管理器会告诉数据库用户已登录,而数据库又必须告诉远程数据源来加载一组不同的数据;与此同时这些操作在获取新数据时都会告诉视图显示一个转圈的加载图标。对此我想说这虽然是可行的,但容易出现错误。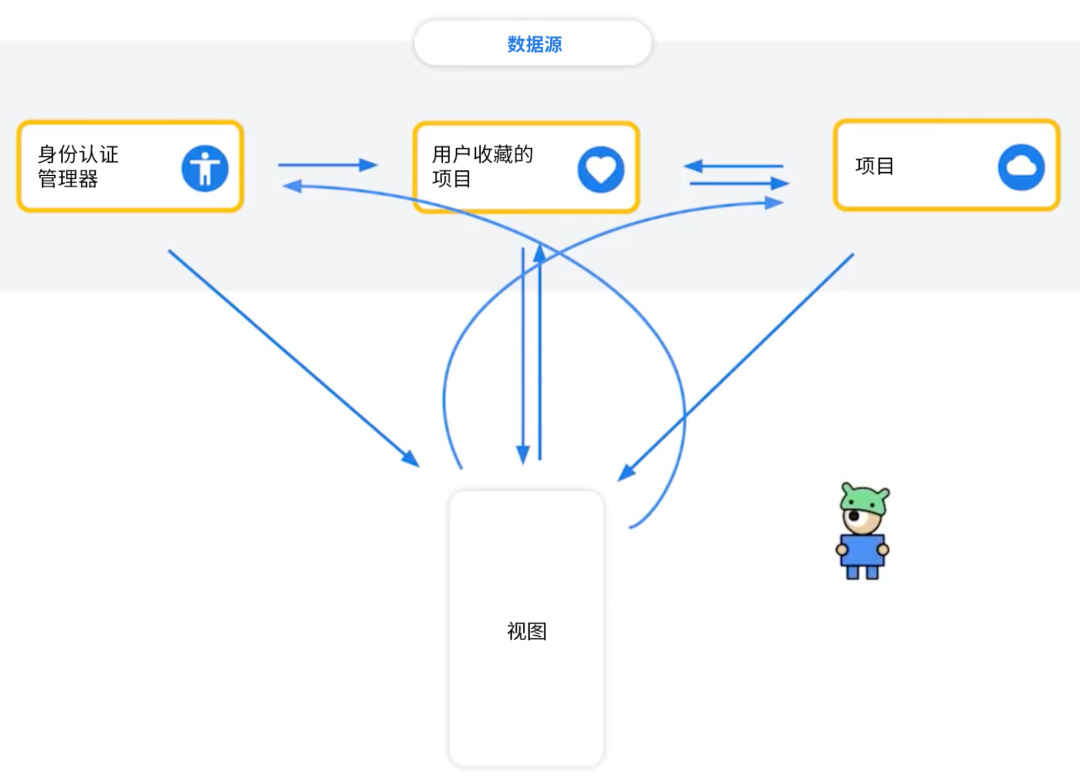
△ 错综复杂的 "数据流动"
更好的方式则是让数据只在一个方向上流动,并创建一些基础设施 (像 Pancho 铺设管道那样) 来组合和转换这些数据流,这些管道可以随着状态的变化而修改,比如在用户退出登录时重新安装管道。
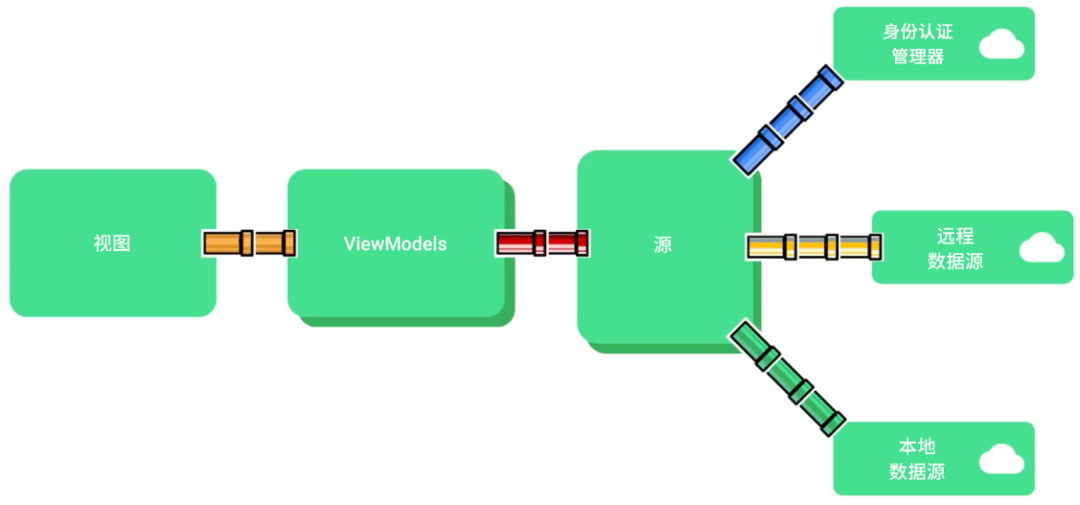
△ 单向数据绑定
使用 Flow可以想象对于这些组合和转换来说,我们需要一个成熟的工具来完成这些操作。在本文中我们将使用 Kotlin Flow 来实现。Flow 并不是唯一的数据流构建器,不过得益于它是协程的一部分并且得到了很好的支持。我们刚才一直用作比喻的水流,在协程库里称之为 Flow 类型,我们用泛形 T 来指代数据流承载的用户数据或者页面状态等任何类型。

△ 生产者和消费者
生产者会将数据 emit (发送) 到数据流中,而消费者则从数据流中 collect (收集) 这些数据。在 Android 中数据源或存储区通常是应用数据的生产者;消费者则是视图,它会把数据显示在屏幕上。
大多数情况下您都无需自行创建数据流,因为数据源中依赖的库,例如 DataStore、Retrofit、Room 或 WorkManager 等常见的库都已经与协程及 Flow 集成在一起了。这些库就像是水坝,它们使用 Flow 来提供数据,您无需了解数据是如何生成的,只需 "接入管道" 即可。
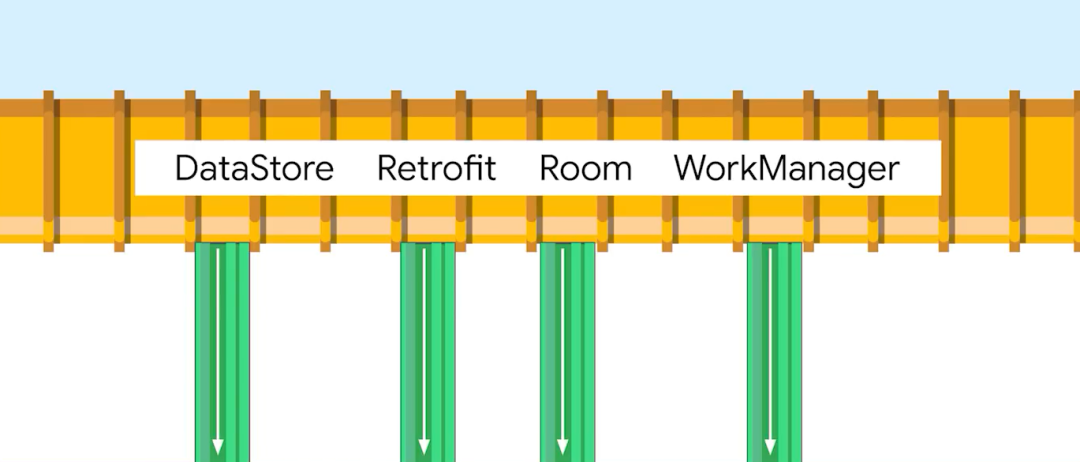
△ 提供 Flow 支持的库
我们来看一个 Room 的例子。您可以通过导出指定类型的数据流来获取数据库中发生变更的通知。在本例中,Room 库是生产者,它会在每次查询后发现有更新时发送内容。创建 Flowinterface CodelabsDAO {fun getAllCodelabs(): Flow>}
如果您要自己创建数据流,有一些方案可供选择,比如数据流构建器。假设我们处于 UserMessagesDataSource 中,当您希望频繁地在应用内检查新消息时,可以将用户消息暴露为消息列表类型的数据流。我们使用数据流构建器来创建数据流,因为 Flow 是在协程上下文环境中运行的,它以挂起代码块作为参数,这也意味着它能够调用挂起函数,我们可以在代码块中使用 while(true) 来循环执行我们的逻辑。
在示例代码中,我们首先从 API 获取消息,然后使用 emit 挂起函数将结果添加到 Flow 中,这将挂起协程直到收集器接收到数据项,最后我们将协程挂起一段时间。在 Flow 中,操作会在同一个协程中顺序执行,使用 while(true) 循环可以让 Flow 持续获取新消息直到观察者停止收集数据。传递给数据流构建器的挂起代码块通常被称为 "生产者代码块"。
class UserMessagesDataSource(private val messagesApi: MessagesApi,private val refreshIntervalMs: Long = 5000) {val latestMessages: Floa> = flow {white(true) {val userMessages = messagesApi.fetchLatestMessages()emit(userMessages) // 将结果发送给 Flowdelay(refreshIntervalMs) // 挂起一段时间}}}
转换 Flow
在 Android 中,生产者和消费者之间的层可以使用中间运算符修改数据流来适应下一层的要求。
在本例中,我们将 latestMessages 流作为数据流的起点,则可以使用 map 运算符将数据转换为不同的类型,例如我们可以使用 map lambda 表达式将来自数据源的原始消息转换为 MessagesUiModel,这一操作可以更好地抽象当前层级,每个运算符都应根据其功能创建一个新的 Flow 来发送数据。我们还可以使用 filter 运算符过滤数据流来获得包含重要通知的数据流。而 catch 运算符则可以捕获上游数据流中发生的异常,上游数据流是指在生产者代码块和当前运算符之间调用的运算符产生的数据流,而在当前运算符之后生成的数据流则被称为下游数据流。catch 运算符还可以在有需要的时候再次抛出异常或者发送新值,我们在示例代码中可以看到其在捕获到 IllegalArgumentExceptions 时将其重新抛出,并且在发生其他异常时发送一个空列表:
收集 Flowval importantUserMessages: Flow<MessageUiModel> =userMessageDataSource.latestMessages.map { userMessage ->userMessages.toUiModel()}.filter { messageUiModel ->messagesUiModel.containsImportantNotifications()}.catch { e ->analytics.log("Error loading reserved event")if (e is IllegalArgumentException) throw eelse emit(emptyList())}
现在我们已经了解过如何生成和修改数据流,接下来了解一下如何收集数据流。收集数据流通常发生在视图层,因为这是我们想要在屏幕上显示数据的地方。
在本例中,我们希望列表中能够显示最新消息以便 Pancho 能够了解最新动态。我们可以使用终端运算符 collect 来监听数据流发送的所有值,collect 接收一个函数作为参数,每个新值都会调用该参数,并且由于它是一个挂起函数,因此需要在协程中执行。
在 Flow 中使用终端运算符将按需创建数据流并开始发送值,而相反的是中间操作符只是设置了一个操作链,其会在数据被发送到数据流时延迟执行。每次对 userMessages 调用 collect 时都会创建一个新的数据流,其生产者代码块将根据自己的时间间隔开始刷新来自 API 的消息。在协程中我们将这种按需创建并且只有在被观察时才会发送数据的数据流称之为冷流 (Cold Stream)。userMessages.collect { messages ->listAdapter.submitList(messages)}
在 Android 视图上收集数据流
在 Android 的视图中收集数据流要注意两点,第一是在后台运行时不应浪费资源,第二是配置变更。安全收集
假设我们在 MessagesActivity 中,如果希望在屏幕上显示消息列表,则应该当界面没有显示在屏幕上时停止收集,就像是 Pancho 在刷牙或者睡觉时应该关上水龙头一样。我们有多种具有生命周期感知能力的方案,来实现当信息不在屏幕上展示就不从数据流中收集信息的功能,比如 androidx.lifecycle:lifecycle-runtime-ktx 包中的 Lifecycle.repeatOnLifecycle(state) 和 Flow.flowWithLifecycle(lifecycle, state)。您还可以在 ViewModel 中使用 androidx.lifecycle:lifecycle-livedata-ktx 包里的 Flow.asLiveData(): LiveData 将数据流转换为 LiveData,这样就可以像往常一样使用 LiveData 来实现这件事情。不过为了简单起见,这里推荐使用 repeatOnLifecycle 从界面层收集数据流。
repeatOnLifecycle 是一个接收 Lifecycle.State 作为参数的挂起函数,该 API 具有生命周期感知能力,所以能够在当生命周期进入响应状态时自动使用传递给它的代码块启动新的协程,并且在生命周期离开该状态时取消该协程。在上面的例子中,我们使用了 Activity 的 lifecycleScope 来启动协程,由于 repeatOnLifecycle 是挂起函数,所以它需要在协程中被调用。最佳实践是在生命周期初始化时调用该函数,就像上面的例子中我们在 Activity 的 onCreate 中调用一样:
import androidx.lifecycle.repeatOnLifecycleclass MessagesActivity : AppCompatActivity() {val viewModel: MessagesViewModel by viewModels()override fun onCreate(savedInstanceState: Bundle?) {lifecycleScope.launch {repeatOnLifecycle(Lifecycle.State.STARTED)viewModel.userMessages.collect { messages ->listAdapter.submitList(messages)}}// 协程将会在 lifecycle 进入 DESTROYED 后被恢复}}}
repeatOnLifecycle 的可重启行为充分考虑了界面的生命周期,不过需要注意的是,直到生命周期进入 DESTROYED,调用 repeatOnLifecycle 的协程都不会恢复执行,因此如果您需要从多个数据流中进行收集,则应在 repeatOnLifecycle 代码块内多次使用 launch 来创建协程:
{{launch {{ … }}launch {{ … }}}}
如果只需从一个数据流中进行收集,则可使用 flowWithLifecycle 来收集数据,它能够在生命周期进入目标状态时发送数据,并在离开目标状态时取消内部的生产者:
lifecycleScope.launch {viewModel.userMessages.flowWithLifecycle(lifecycle, State.STARTED).collect { messages ->listAdapter.submitList(messages)}}
为了能够直观地展示具体的运作过程,我们来探索一下此 Activity 的生命周期,首先是创建完成并向用户可见;接下来用户按下了主屏幕按钮将应用退到后台,此时 Activity 会收到 onStop 信号;当重新打开应用时又会调用 onStart。如果您调用 repeatOnLifecycle 并传入 STARTED 状态,界面就只会在屏幕上显示时收集数据流发出的信号,并且在应用转到后台时取消收集。
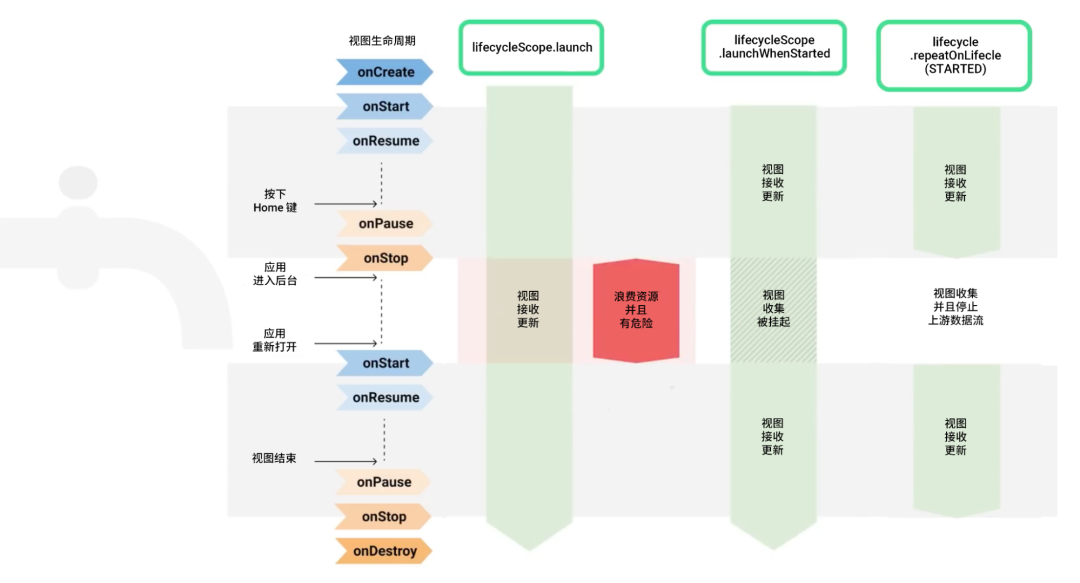
△ Activity 的生命周期
repeatOnLifecycle 和 flowWithLifecycle 是 lifecycle-runtime-ktx 库在 2.4.0 稳定版中新增的 API,在没有这些 API 之前您可能已经以其他方式从 Android 界面中收集数据流,例如像上面的代码一样直接从 lifecycleScope.launch 启动的协程中收集,虽然这样看起来也能工作但不一定安全,因为这种方式将持续从数据流中收集数据并更新界面元素,即便是应用退出到后台时也一样。如果使用 launchWhenStarted 替代它的话,情况会稍微好一些,因为它会在处于后台时将收集挂起。但这样会在让数据流生产者保持活跃状态,有可能会在后台持续发出不需要在屏幕上显示的数据项,从而将内存占满。由于界面并不知道数据流生产者的实现方式,所以最好谨慎一些,使用 repeatOnLifecycle 或 flowWithLifecycle 来避免界面在处于后台时收集数据或保持数据流生产者处于活跃状态。 下面是一段不安全的使用方式示例:class MessagesActivity : AppCompatActivity() {val viewModel: MessagesViewModel by viewModels()override fun onCreate(savedInstanceState: Bundle?) {// 危险的操作lifecycleScope.launch {viewModel.userMessage.collect { messages ->listAdapter.submitList(messages)}}// 危险的操作LifecycleCoroutineScope.launchWhenX {flow.collect { … }}}}
配置变更
当您向视图暴露数据流时,必须要考虑到您正在尝试在具有不同生命周期的两个元素之间传递数据,并不是所有生命周期都会出现问题,但在 Activity 和 Fragment 的生命周期里会比较棘手。当设备旋转或者接收到配置变更时,所有的 Activity 都可能会重启但 ViewModel 却能被保留,因此您不能把任意数据流都简单地从 ViewModel 中暴露出来。
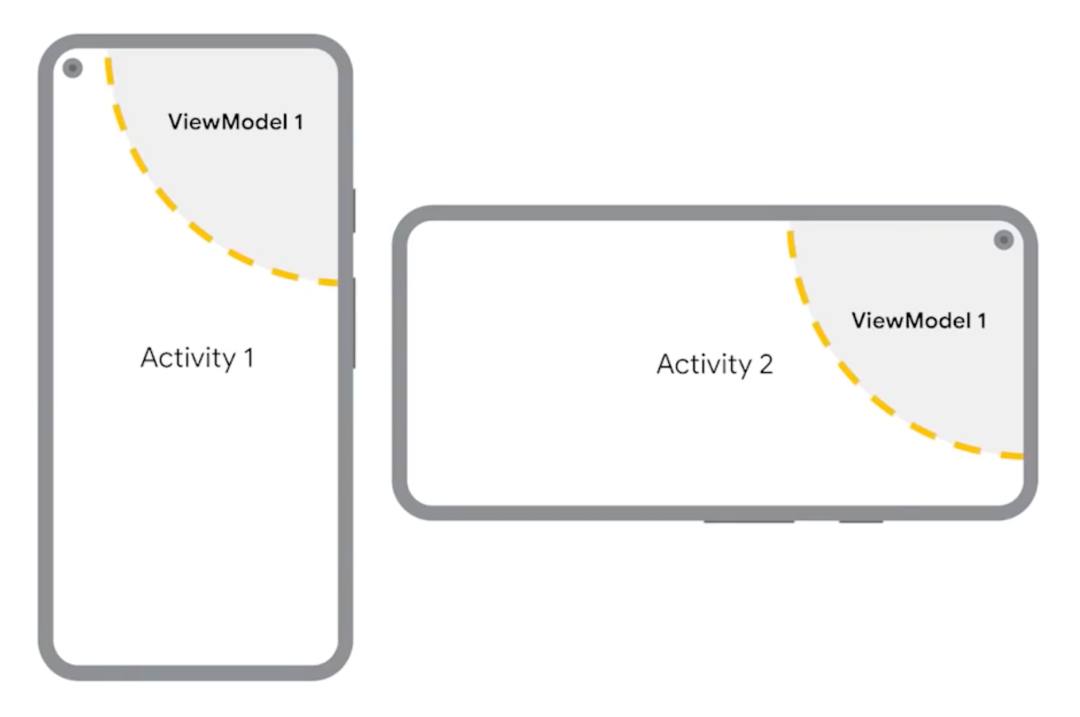
△ 旋转屏幕会重建 Activity 但能够保留 ViewModel
以如下代码中的冷流为例,由于每次收集冷流时它都会重启,所以在设备旋转之后会再次调用 repository.fetchItem()。我们需要某种缓冲区机制来保障无论重新收集多少次都可以保持数据,并在多个收集器之间共享数据,而 StateFlow 正是为了此用途而设计的。在我们的湖泊比喻中,StateFlow 就好比水箱,即使没有收集器它也能持有数据。因为它可以多次被收集,所以能够放心地将其与 Activity 或 Fragment 一起使用。
val result: Flow>> = flow {emit(repository.fetchItem())}
您可以使用 StateFlow 的可变版本,并随时根据需要在协程中更新它的值,但这样做可能不太符合响应式编程的风格,如下代码所示:
private val _myUiState = MutableStateFlow()val myUiState: StateFlow = _myUiStateinit {viewModelScope.launch {_muUiState.value = Result.Loading_myUiState.value = repository.fetchStuff()}}
Pancho 会建议您将各种类型的数据流都转换为 StateFlow 来改进这个问题,这样 StateFlow 将接收来自上游数据流的所有更新并存储最新的值,并且收集器的数量可以是 0 至任意多个,因此非常适合与 ViewModel 一起使用。当然,除此之外还有一些其他类型的 Flow,但推荐您使用 StateFlow,因为我们可以对它进行非常精确的优化。
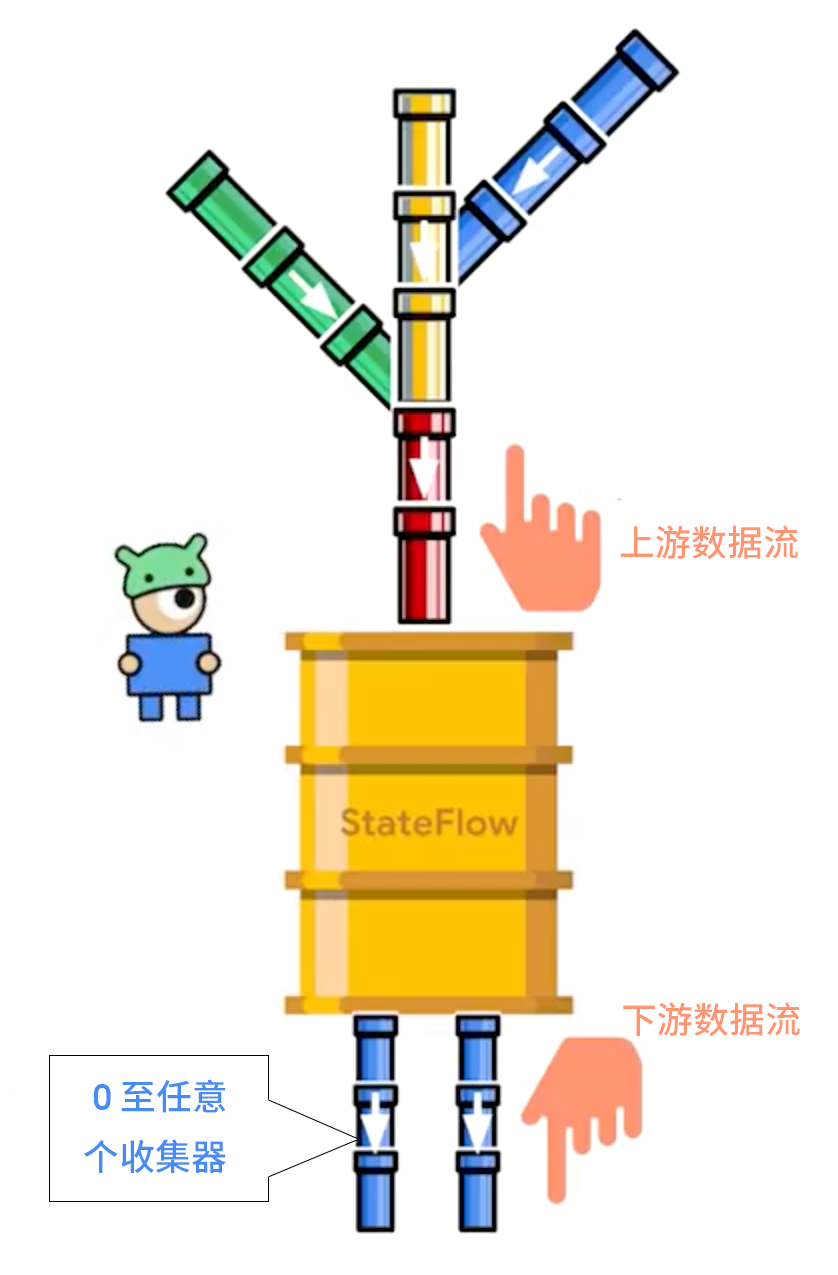
要将数据流转换为 StateFlow 可以使用 stateIn 运算符,它需要传入三个参数: initinalValue、scope 及 started。其中 initialValue 是因为 StateFlow 必须有值;而协程 scope 则是用于控制何时开始共享,在上面的例子中我们使用了 viewModelScope;最后的 started 是个有趣的参数,我们后面会聊到 WhileSubscribed(5000) 的作用,先看这部分的代码:
val result: StateFlow> = someFlow.stateIn(initialValue = Result.Loadingscope = viewModelScope,started = WhileSubscribed(5000),)
我们来看看这两个场景: 第一种场景是旋转,在该场景中 Activity (也就是数据流收集器) 在短时间内被销毁然后重建;第二个场景是回到主屏幕,这将会使我们的应用进入后台。在旋转场景中我们不希望重启任何数据流以便尽可能快地完成过渡,而在回到主屏幕的场景中我们则希望停止所有数据流以便节省电量和其他资源。
我们可以通过设置超时时间来正确判断不同的场景,当停止收集 StateFlow 时,不会立即停止所有上游数据流,而是会等待一段时间,如果在超时前再次收集数据则不会取消上游数据流,这就是 WhileSubscribed(5000) 的作用。当设置了超时时间后,如果按下主屏幕按钮会让视图立即结束收集,但 StateFlow 会经过我们设置的超时时间之后才会停止其上游数据流,如果用户再次打开应用则会自动重启上游数据流。而在旋转场景中视图只停止了很短的时间,无论如何都不会超过 5 秒钟,因此 StateFlow 并不会重启,所有的上游数据流都将会保持在活跃状态,就像什么都没有发生一样可以做到即时向用户呈现旋转后的屏幕。
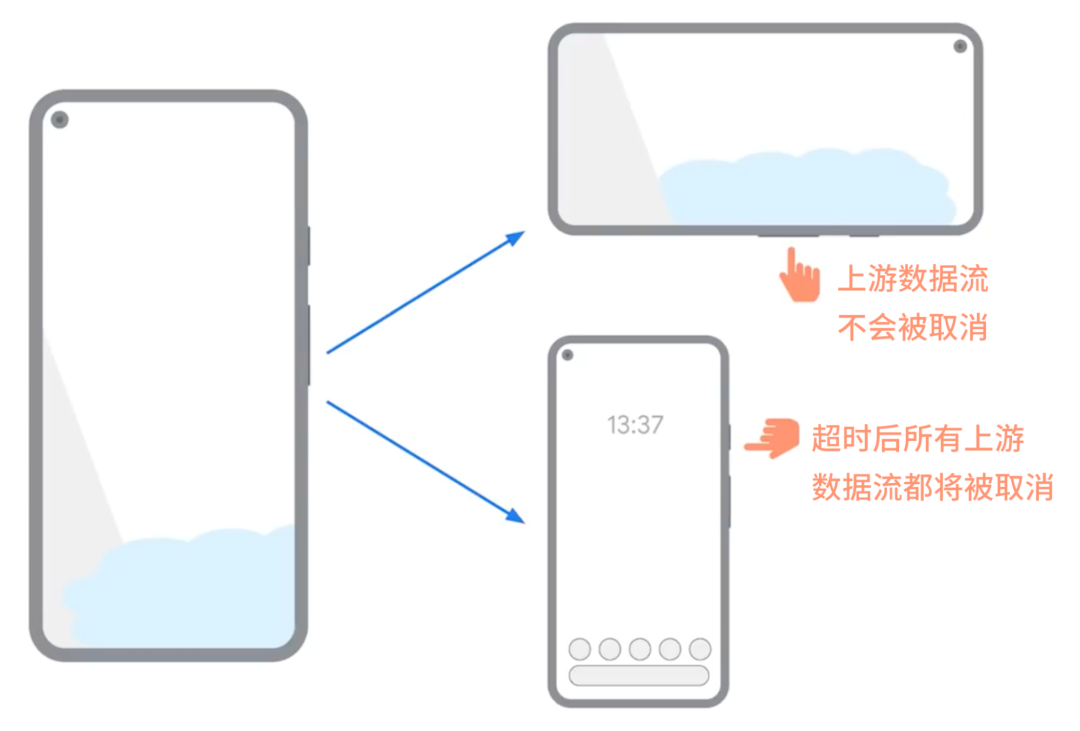
总的来说,建议您使用 StateFlow 来通过 ViewModel 暴露数据流,或者使用 asLiveData 来实现同样的目的,关于 StateFlow 或其父类 SharedFlow 的更多详细信息,请参阅: StateFlow 和 SharedFlow。
测试数据流
测试数据流可能会比较复杂,因为要处理的对象是流式数据,这里介绍在两个不同的场景中有用的小技巧: 首先是第一个场景,被测单元依赖了数据流,那对此类场景进行测试最简单的方法就是用模拟生产者替代依赖项。在本例中,您可以对这个模拟源进行编程以对不同的测试用例发送其所需要的内容。您可以像上面的例子一样实现一个简单的冷流,测试本身会对受测对象的输出进行断言,输出的内容可以是数据流或其他任何类型。
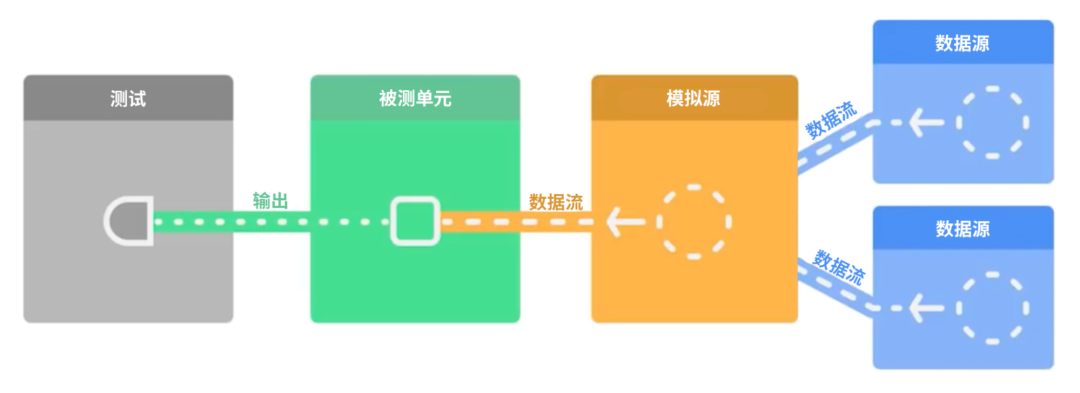
模拟被测单元所依赖的数据流:
class MyFakeRepository : MyRepository {fun observeCount() = flow {emit(ITEM_1)}}
如果受测单元暴露一个数据流,并且您希望验证该值或一系列值,那么您可以通过多种方式收集它们。您可以对数据流调用 first() 方法以进行收集并在接收到第一个数据项后停止收集。您还可以调用 take(5) 并使用 toList 终端操作符来收集恰好 5 条消息,这种方法可能非常有帮助。
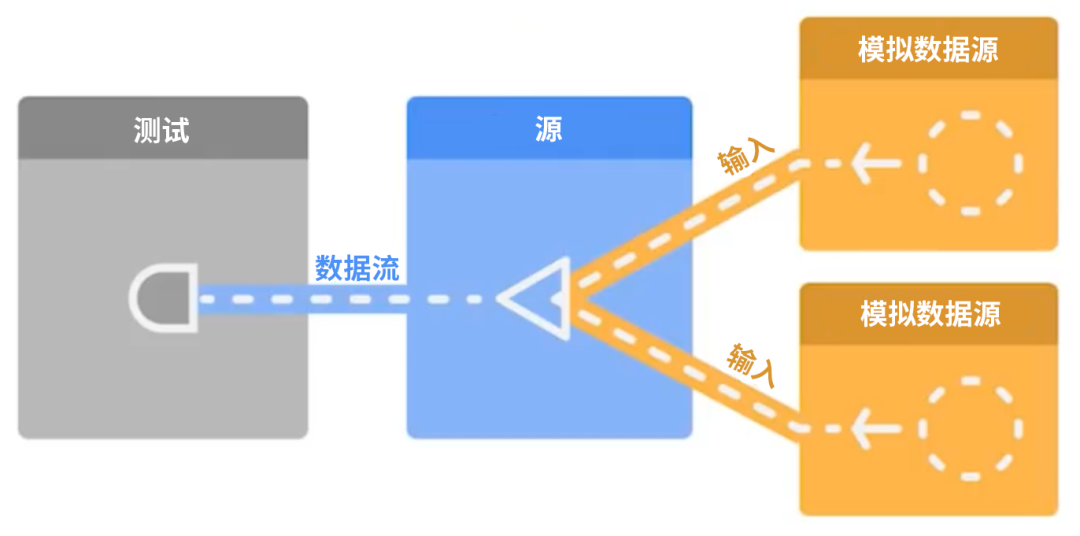
△ 测试数据流的技巧
测试数据流:
回顾fun myTest() = runBlocking {// 收集第一个数据然后停止收集val firstItem = repository.counter.first()// 收集恰好 5 条消息val first = repository.messages.take(5).toList()}
感谢阅读本文,希望您通过本文内容已经了解到为什么响应式架构值得投资,以及如何使用 Kotlin Flow 构建您的基础设施。文末提供了有关这方面的资料,包括涵盖基础知识的指南以及深入探讨某些主题的文章。另外您还可以通过 Google I/O 应用了解这些内容的详细信息,我们在早些时候为其更新了很多有关数据流的内容。
原文标题:实战 | 使用 Kotlin Flow 构建数据流 "管道"
文章出处:【微信公众号:谷歌开发者】欢迎添加关注!文章转载请注明出处。
-
前端开发之函数式编程实践2023-06-05 950
-
基于Android开发的ADT获取内存中的敏感信息2022-09-06 2366
-
将Android操作系统移植到嵌入式平台的最佳实践2022-07-01 3055
-
从实践中学嵌入式Linux应用程序开发2021-11-04 1587
-
第二章 Android系统与嵌入式开发2021-11-02 1011
-
《从实践中学嵌入式Linux应用程序开发》pdf完整版资源分享2021-11-01 1472
-
ARM嵌入式系统开发_Android应用开发入门(基础版)2021-08-04 2461
-
《从实践中学习嵌入式Linux操作系统》高清PDF资源分享!2019-11-01 2939
-
从实践中学嵌入式linux应用程序开发2017-12-08 3216
-
Android开发中的经验教学2017-10-10 510
-
在嵌入式开发中,你是如何理解嵌入式C编程的?2016-03-22 3877
-
Google+Android开发与实践代码大全2011-09-07 1428
-
Android开发宝典之Android程序员入门2011-09-05 1801
全部0条评论

快来发表一下你的评论吧 !
