

openGauss数据库在可计算存储CSD上探索
描述
最近在可计算存储 CSD 2000上使用 BenchmarkSQL 和 sysbench 测试了一下 openGauss 数据库,主要观察在大数据量下 openGauss 在 CSD 2000 上数据存储空间和性能相比普通SSD 的变化。这里分享一些测试数据和原理的思考,供对openGauss 和可计算存储 CSD 感兴趣的朋友参考。
CSD 测试效果
测试场景简介
测试场景选择了数据库厂商经常用的两种标准场景。
§BenchmarkSQL TPC-C场景
TPC-C是衡量联机事务处理(OLTP,OnlineTransaction Processing)系统的工业标准,是行业中公认的权威和最为复杂的在线事务处理基准测试。它通过模拟仓库和订单管理系统,测试广泛的数据库功能,包括查询、更新和 mini-batch事务(队列式小批量事务)。
TPC-C基准测试模拟订单录入与销售环境,测量每分钟商业事务(tpmC)吞吐量。TPC-C 测试数据集规模由仓库数决定,本次测试指定10000仓。一共有9张业务表,最大的表数据量是仓库数*300K ,这里有30亿。
开源的 TPC-C 测试工具有 BenchmarkSQL 和 sysbench。这里选择BenchmarkSQL,官方下载地址:https://sourceforge.net/projects/benchmarksql/ 。测试方法参考openGauss 官方文档。
§sysbench OLTP 场景
sysbench 是一个开源的、模块化的、跨平台的多线程性能测试工具,可以用来进行CPU、内存、磁盘I/O、线程、数据库的性能测试。目前支持的数据库有 MySQL 、Oracle和Postgre SQL 。
sysbench oltp 基准测试指定场景脚本(lua文件),输出相应的平均每秒事务数TPS、平均每秒请求数QPS、平均延时RT、99百分位延时等。sysbench 数据量是可以指定表的数量和每个表的数据量。本次测试指定100张表,每张表1亿记录。
sysbench 从开源网站github.com 下载,版本1.1.0 。
存储空间压缩效果
为了让 SSD 读写能进入稳态,降低数据库内存和操作系统内存对磁盘测试的影响,两种测试场景的数据量都非常大。
§Benchmarksql TPC-C 场景:数据规模在 10000 仓库,表的填充因子(FILLFACTOR)设置为 50,数据库文件大小总计约 1882 GB,CSD 内部实际使用空间约 602 GB 。CSD 压缩比为 3.12 (压缩比=压缩前物理空间 / 压缩后物理空间)。
§sysbench 场景:100表,每表 1 亿数据,表的填充因子设置为 100 ,数据库文件大小总计为 2565 GB,CSD 内部实际使用空间约 810 GB 。CSD 压缩比为 3.16 。
§sysbench 场景:100表,每表 1 亿数据,表的填充因子设置为 75 ,数据库文件大小总计为 3300 GB,CSD 内部实际使用空间约 874 GB 。CSD 压缩比为 3.77 。
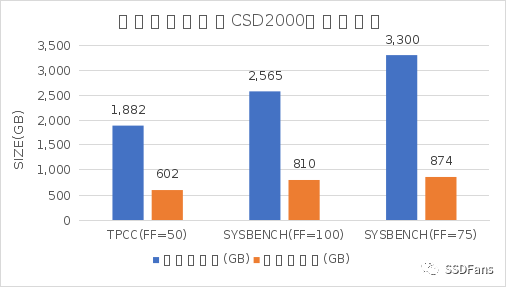
普通的 SSD 没有透明压缩能力,内部实际存储空间也就等于上面“压缩前大小”。CSD 2000 的透明压缩能力显著降低数据在 SSD 内部的物理存储空间,极大的降低了 存储介质NAND 消耗速度,降低 SDD GC 频率,所以在 SSD 进入稳态后高并发读写时,性能也有明显提升。
性能对比
两种测试场景,在固定数据量的前提下,分别使用不同的客户端并发数进行测试,每次测试时间在10分钟。
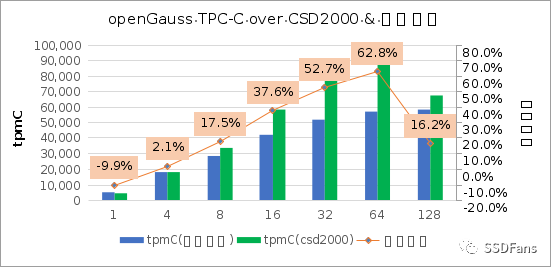
§TPC-C 性能,在 64 并发时提升幅度最大。
§SYSBENCH (FF=100)性能
注:FF,FILLFACTOR 的简称,填充因子,用于控制数据库块里 INSERT 的最大空间使用比例。
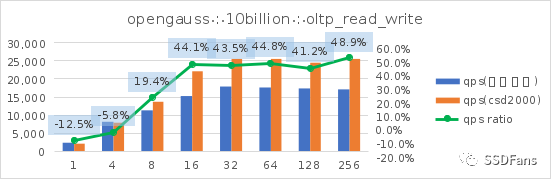
读写混合场景的每秒请求数QPS:
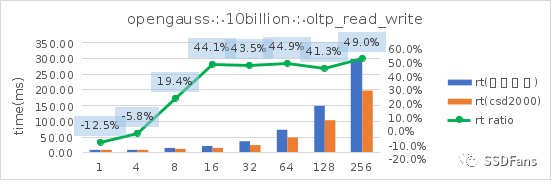
读写混合场景的平均延时 RT:
§SYSBENCH (FF=75)性能
读写混合场景的每秒请求数QPS:
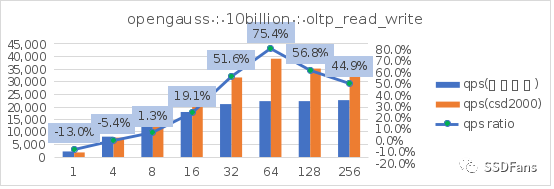
读写混合场景的平均延时 RT:
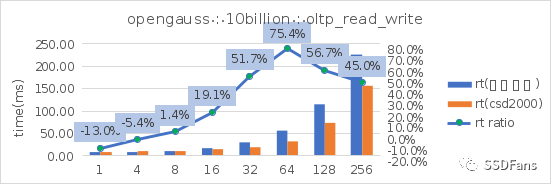
上面只是取了 TPCC 和 sysbench oltp 读写混合场景。更多场景的测试信息请查看文末链接。从上图可以看出:
§sysbench 相同的数据量(100亿),不同的填充因子(FILLFACTOR)从 100 降到 75 时,不管是在普通 SSD 还是 CSD 上,性能都会提升。在普通盘上的代价就是存储空间的增长(从 2565G 涨到 3300G),但是在 CSD 上实际存储空间的增长却很小(从 810G 涨到 874G )。
§不管是 TPC-C 还是 sysbench 的读写混合场景,当并发超过 10 后,CSD 上的 QPS 或平均延时都会呈现优势并且逐步扩大,直到到达一个拐点。
备注:这次性能测试场景数据量造的非常大(1.5T 以上),并且数据库内存不是很大(80G),同时开启了openGauss 的 full_page_writes ,没有刻意对 openGauss 做深入优化。所以数据库压测的时候加在 SSD 上的读写压力很大,整体呈现 IO Bound 特点。 这是为了模拟这种情形,即客户生产业务应用的数据库并不一定总是很优化,在性能出现问题的时候可能存储的读写压力很大,SSD 往往成为性能瓶颈。所以这里测试的结果值跟数据库单纯的做性能测试取得的峰值会有一定差异。我们重点关注相同的数据量相同的数据库软硬件配置在不同的 SSD 上的性能差异。
openGauss 存储特性简介
openGauss v2.1 的内核是 Postgres 9.2.4 。openGauss 的存储引擎支持三种类型:
§行存储引擎:面向 OLTP 场景设计。如订单、物流、金融交易系统。
§列存储引擎:面向 OLAP 场景设计。如数据统计分析报表。
§内存引擎:面向一些特殊场景对性能有极致要求。如银行风控等。
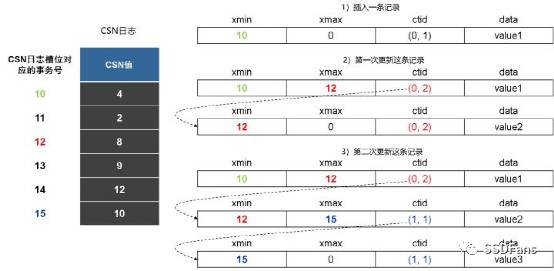
这里我主要测试的是行存储引擎。行存储引擎的特性很多,这里这聊它的数据存储模型。openGauss 跟 PostgreSQL 一样都是使用 B-Tree 模型。openGauss行存储表支持多版本元组机制,即为同一条记录保留多个历史版本的物理元组,以应对同一条记录的读、写并发冲突(读事务和写事务工作在不同版本的物理元组上)。这种设计叫 astore 元组多版本机制。
astore存储格式为追加写优化设计,其多版本元组产生和存储方式如下图所示。当一个更新操作将v0版本元组更新为v1版本元组之后,如果v0版本元组所在页面仍然有空闲空间,则直接在该页面内插入更新后的v1版本元组,并将v0版本的元组指针指向v1版本的元组指针。在这个过程中,新版本元组以追加写的方式和被更新的老版本元组混合存放,这样可以减少更新操作的I/O开销。然而,需要指出的是,由于新、老版本元组是混合存放的,因此在清理老版本元组时需要的清理开销会比较大。因此,astore存储格式比较适合频繁插入、少量更新的业务场景。
引用来源:《openGauss数据库源码解析系列文章——存储引擎源码解析(二)》
openGauss 表有个存储参数填充因子(FILLFACTOR)可以指定每个页里在插入数据时使用的最大空间比例。表默认是 100% ,索引默认是 90%。大量的 insert 可能会导致页基本写满从而后期更新操作时就需要另外找新的页存放新元组。适当的预留一些空间能提升表的更新(update 和 delete)性能。PostgreSQL 或者 openGauss 用户可能不会过多降低这个参数值,因为这会导致表和索引的存储空间增加。但是如果数据库存储是带透明压缩的可计算型存储 CSD 时,这个空间担心就是多余的。
可计算型存储 CSD 简介
常用压缩方案
常用的数据压缩方案有好几种,业务根据自己需求和方案特点选择。这里简单介绍一下各种方案特点:
§应用(指数据库)自己开启压缩,占用一定主机 CPU 资源,损失一些性能。损失多少取决于压缩算法和数据库工程实现能力。随着数据量增长,性能损耗会加大,不具备线性扩展能力。CPU 压缩也会导致 CPU Cache Miss 事件增多。简单来说是牺牲CPU性能换存储空间。
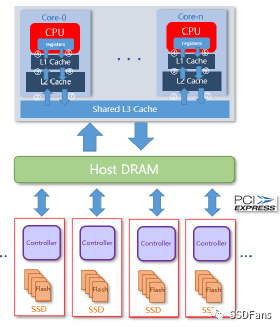
§使用 FPGA 加速卡压缩。FPGA 卡自带计算引擎,能减轻主机 CPU 负载,在不少场景里很适合。不过 FPGA 卡会占用一个 PCIe 插槽,且数据读写传输会占用内存资源。数据链路也变长。同样受限于压缩卡算力和带宽,无法线性扩展。
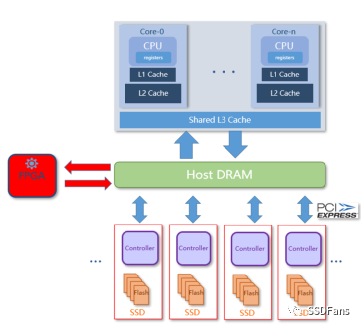
§CSD 透明压缩。在 SSD 内部引入计算引擎,数据按常规方法写入 SSD,然后盘内计算引擎对数据压缩,写入存储物理介质(NAND)。透明压缩,应用不需要修改。zero-copy技术,不需要额外数据传输。数据量增长时,可以增加多块 CSD 盘实现压缩能力线性扩展。
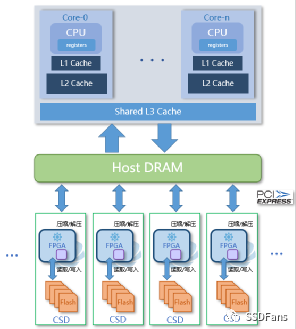
CSD 的透明压缩做到应用完全不用修改就可以用。传统的关系型数据库(使用B-Tree数据模型,如 ORACLE/MySQL/SQL Server/PostgreSQL)可以直接部署在 CSD 上使用,通常业务数据压缩比能在 2.0 以上。虽然这些数据库自身也有压缩方案,但考虑到性能,客户核心应用在生产上不会开启压缩。一些 NewSQL 数据库使用 LSM Tree 模型的,也自带压缩能力。如果数据库强行开启压缩,那么数据文件在 CSD 上压缩比还要根据实际情况看。这涉及到 CSD 压缩的原理。
CSD 原理特性
§定长块 IO
当给 SSD 盘做文件系统格式化时,默认块大小是 4KB(这个也可以改,具体要看操作系统是否支持)。应用写入数据时,每个 IO 里实际有效数据大小可能小于或等于 4KB,不足 4KB 时会用空(0x0)补齐。文件系统上层的应用(数据库),为了减少 I/O 次数,数据库的块(或叫页Page)大小通常都比 4KB 大。如 ORACLE 和 PostgreSQL 默认是 8KB ,MySQL 是 16KB ,openGauss 是 8KB 。数据库软件在管理数据存储的时候,会有按块大小补齐逻辑。此外,使用 B-Tree 模型管理数据的数据库的块通常有预留空间设计,以提升记录更新的性能,减少数据块或者索引块不必要的页分裂带来的性能下降。这是用存储空间换性能的做法。比如说 ORACLE 建表的 storage 参数的 PCTFREE,PostgreSQL 、openGauss的 storage 参数 FILLFACTOR 。预留空间的比例需要在空间和性能之间权衡。这个在以前是个难题,不过数据放在 CSD 上后就不是问题了。因为所有用于补齐的空数据、数据库块里的预留空间(空数据),在 CSD2000 内部都会被压缩掉,没有实际存储成本。
§压缩算法
当然,压缩收益还有一部分来自于业务数据和压缩算法自身。以 TPC-C 产生的10000仓的数据为例,如果全部导出为 csv 文件,在 CSD2000 上大小有 729 GB,实际占用物理空间为 457 GB,压缩比约 1.59 。当将数据导入到 openGauss并设置 openGauss 表的 fillfactor 为 50 时,这份数据在 openGauss 的数据文件总计 1882 GB,该数据文件在 CSD 2000 上实际占用物理空间 602 GB,压缩比约 3.13 。CSD 2000 内部使用的压缩算法是 zlib (gzip)。
除了 gzip/zlib 还有些常见的压缩算法,如 lz4、snappy、zstd 。每个压缩算法还有不同的压缩 level。就默认 level 而言,实际经验是 lz4、snappy压缩比较快,对 CPU 占用低,自然压缩比也是很低。zstd、gzip 压缩比较慢,对 CPU 占用高,压缩比很高。CSD 的透明压缩是靠 SSD 内部的计算引擎实现的(在 CSD 2000 内部是有一个 FPGA;在 CSD 3000 内部是 ARM 芯片),不占用主机 CPU 。下面表格是 sysbench 表导出 csv 文件后的压缩比测试。
| 原始大小 | 压缩算法 | 压缩后大小 | 应用压缩比 | CSD压缩后大小 | CSD压缩比 |
| 1.1GB | none | 1.1GB | none | 533 MB | 2.11 |
| 1.1GB | lz4-1.8.3 | 919 MB | 1.26 | 598 MB | 1.54 |
| 1.1GB | gzip-1.5 | 476 MB | 2.37 | ||
| 1.1GB | zstd-1.3.8 | 494 MB | 2.37 | 494 MB | 1.00 |
应用(指数据库)如果开启压缩,除了要消耗一部分 CPU 资源外,还会带来一个问题就是数据读写过程中的压缩和解压缩会降低 CPU cache 的命中率。此外,当一个 16K 的数据块被压缩后可能就不是 4KB 的整数了,在写到文件系统里还是很可能有不少空数据,所以在数据库压缩后在 CSD 内部还可以继续压缩一部分(还有一个原因就是压缩算法之间的差异)。
这次没有对比测试 openGauss 数据库的压缩效果。根据其他数据库的测试经验。如果数据库使用 lz4 压缩,在 CSD2000 内部还会有 1.54 的压缩比。有些数据库使用 LSM Tree 模型,数据是分层压缩的,不同层的压缩算法还可以不一样,这些数据在 CSD 内部的压缩效果就取决于数据库里使用用不同压缩算法的数据占比了。
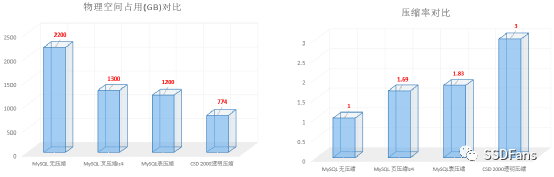
§压缩比
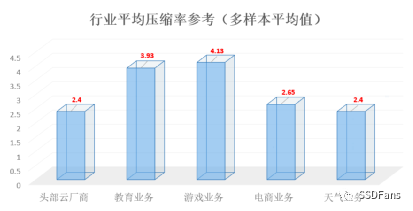
CSD 2000 提供了命令可以直接看具体的文件的实际物理空间和压缩比,以及整个 SSD 盘的实际物理空间和压缩比。当业务数据是变化的时候,CSD 2000 上观察到的压缩比是浮动的,每个业务都不一样。下图是客户的业务数据压缩比经验。
大部分数据库的数据存储是即时分配,这些数据库的压缩比观察数据比较直接。少数数据库有自己的空间管理策略。如 ORACLE数据库有表空间概念,可以预分配(初始化)一定大小的数据文件。同时也可以后期文件自动扩展。以前在存储资源很宝贵的时候, DBA 会习惯自己控制文件的增长。一点点用,像挤牙膏似的。预分配的空间里都是用空数据(0x0)初始化,对压缩比的结果会有一定影响,影响的比例就取决于这部分数据占总大小的比例。然后表空间还有自己的空间管理(复用)策略,在表被删除后,其对应的空间很有可能只是数据库内部复用,并不会归还给磁盘。尽管数据库认为某一段空间是无效的,在 CSD 眼里,其原数据还是在的,压缩比也是存在的。
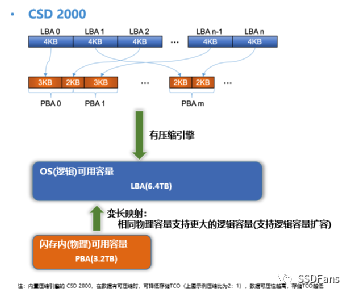
压缩比浮动可能会让人担心。为了放心,运维可以监控 SSD 的可用物理空间。正如 ORACLE 数据库管理员要监控磁盘可用空间,也要监控数据库内部表空间的可用空间,使用 CSD 2000 还要监控 SSD 内部可用物理空间。CSD 2000 的透明压缩没有修改文件系统的接口,所以用户在看数据文件大小看到的都是压缩前的大小,也叫逻辑空间大小(其访问地址对应为 LBA,Logical Block Address)。这点是CSD透明压缩区别于文件系统(如zfs)压缩方案。在 SSD 内部还有个物理空间地址 PBA (Physical Block Address)。
§OP 空间
对于普通的 HDD 而言,LBA 和 PBA 地址映射是 1:1 的。SSD 比 HDD 不一样的地方是 SSD 内部有一定比例的保留空间对用户是不可见的,又称为 Over Provision 空间(简称 OP)。OP 空间的存在原因是 SSD 的写是对闪存空的Page 进行编程(Program),每个 Page 只能编程一次(除非后期擦除再次变为空 Page了)。所以 SSD 可以写入新的空 Page 但是不能修改老的 Page 。如果要改写只能将老的 Page 数据复制到新的 Page,期间经过 SSD Cache 的时候在 Cache 里修改数据,然后写入到新的 Page。这就需要 OP 空间来容纳数据。所以 SSD 内 LBA 和 PBA 的映射不是 1:1 , PBA 的地址容量大于 LBA 的地址容量。当改写数据时,原 LBA 会映射到新的 PBA,那么老的 PBA 在 SSD 内部就属于“无主数据”或者“脏数据”。当 SSD 内没有剩余的空 Page 用于写时,SSD 就会回收“脏数据” 所在的 Page,这个操作叫 GC, “脏数据”所在 Page 变为空 Page 操作叫擦除(Erase)。由于 SSD 电路设计特点,擦除的单位是 BLOCK ,并且每个 BLOCK 被擦除的次数还有限。一个 BLOCK 大小现在可能有几MB 或者几十 MB(跟产品型号、容量有关)。所以为了擦除某几个“脏数据” 所在的 BLOCK,需要先把该 BLOCK 上有效数据所在的 Page 迁移到空的 BLOCK 上。当剩余空 PAGE 比例很低触发GC时,就是SSD进入稳态了。GC 操作并不会等空 Page全部写完了才做,可能是定时做或者空闲期自动做,或者空余 Page比例不足某个值时做。当 GC 发生时,很多数据搬迁,会占用 SSD 内部 CPU 和 NAND 通道带宽,所以对性能会有一定影响。这也就是普通 SSD 使用一段时间后写性能会变慢的主要原因。当把数据搬迁的量也算作 SSD 存储介质(NAND) 的消耗时,相比业务写入 SSD 的数据量,前者可能远远大于后者,这就是 SSD 的写放大特点。
但在 CSD 产品,GC 的概率会非常低。由于内置透明压缩能力,业务写入 CSD 的数据量跟 CSD 内部 NAND 实际写入量的比例是 N:1 的关系(N 就是数据压缩比,N>1),也就是 CSD 产品的写放大是小于 1 的。这是跟普通 SSD 最大的区别。这样导致 CSD 内部实际有效 OP 空间远大于产品标称的能力(一般 SSD 的 OP 比例是 7% 或者 28%)。OP 空间越大,GC 自然越少。对于 QLC CSD 而言,这个特性能极大提升 SSD 寿命。
§CSD 容量扩容
不过有部分客户业务数据压缩比很高(大于3),业务数据量很大的时候(几十甚至几百TB 以上)这部分多出的 OP 空间就非常可观,客户希望能使用这部分 OP 空间。所以 CSD 2000 还有一个用法就是“扩容”。默认一个 4TB 的 CSD 2000 可以提供 3.2T 的空间。根据实际业务数据特点,可以对盘做一个初始化设置,允许提供 6.4 T 的空间(这是举例)。具体来说就是提供 6.4 TB 的 LBA 地址容量。对业务来说,使用方法还是不变。将 CSD 2000 格式化文件系统后,就能看到盘有 6.4 T 的剩余空间。只要后期业务写入的数据平均压缩比高于 2:1, 那么这块盘的容量和性能还是可能比普通的盘要好。
§原子写
CSD 2000 还有个特殊的能力,能在硬件层面提供 8K~256K 的 IO 原子写能力。只要上层应用(数据库)需要 4K 整数倍 IO的原子写,可以完全交给 CSD 2000 来实现。前提是数据库写是 direct IO。
前面提到很多关系数据库数据块大小都是 4K 的倍数,在发生机器故障时,有可能出现数据块写到文件里部分成功部分失败的情形下。即使数据库开启了 WAL(Write Ahead Logging)机制,也不一定能保证数据库恢复后该数据块也能正确恢复。在 MySQL 里,通过先同步顺序写一个共享表空间文件,然后再写数据文件的方式来规避问题。在故障发生后如果发现数据块校验有问题,就直接用该共享表空间的内容覆盖数据文件上的数据块进行恢复。这个机制叫双写。在 PostgreSQL里使用的是在 Redo 日志里记录数据块完整的内容(通过参数 full_page_writes 控制)(传统 WAL 日志记录的是数据块的变化内容)。openGauss 2.1版本两种方案都支持(参数 enable_double_write 和 full_page_writes),默认使用的是双写方案。双写方案跟开启增量检查点一起使用(参数 enable_incremental_checkpoint )。
不管选哪个,这两个原子写方案都有一个特点,就是数据库层面的写放大,对性能的影响也是很明显。openGauss 可以关闭这个机制,代价就是数据安全。由于 openGauss 不支持 direct IO,所以没有办法使用 CSD 2000 的原子写能力。在 MySQL 数据库上,我们成功验证了关闭 MySQL 双写机制和使用 CSD 2000 的原子写能力,sysbench 写性能得到极大的提升(200%~350%)。
其他
openGauss 2. 1版本也提供了 IN-Place 更新机制,名为 Ustore 存储引擎。应该还在试用状态,具体使用效果还待官方客户案例分享。这里没有测试,Ustore 跟 ORACLE、MySQL的更新模型一致了,对使用CSD后压缩和性能提升影响应该不会太大。
审核编辑 :李倩
-
2017双11技术揭秘—阿里数据库计算存储分离与离在线混布2018-01-02 3237
-
创建新的数据库和更改SQL Server CE数据库中的数据操作教程免费下载2019-09-19 1482
-
华为正式宣布开源数据库能力,开放openGauss数据库源代码2020-07-25 5589
-
企业级开源数据库openGauss荣获“2020年度最热开源数据库奖”2021-01-18 2973
-
专业数据库厂商快立方正式加入openGauss社区2021-04-19 2740
-
openGauss作为开源数据库领域的新兴力量首次亮相ICDE2021-04-26 2538
-
沐融科技正式加入openGauss社区,打造企业级开源关系型数据库2021-06-04 2665
-
openGauss开源社区打造全球领先的开源数据库技术生态2022-07-21 2074
-
使用可计算SSD加速云原生数据库2023-05-25 1814
-
数据库知识2023-06-09 696
-
数据库建立|数据库创建的方法?2023-07-14 2430
-
数据库应用及其特点 数据库数据的基本特点2023-08-28 4331
-
常见的存储Idea数据库的地方2023-12-06 2212
-
数据库数据恢复—通过拼接数据库碎片恢复SQLserver数据库2024-10-31 1715
-
云数据库是哪种数据库类型?2025-01-07 1376
全部0条评论

快来发表一下你的评论吧 !
