

RISC架构的兴起
描述
编者按
John Hennessy和David Patterson是体系结构领域的权威,两人在其2017年图灵奖获奖演讲时说,未来十年是体系机构的黄金年代,在CPU性能达到瓶颈的情况下,需要针对特定的领域定制专用处理器,这也就是当前大家熟悉的DSA(Domain Specific Architecture,特定领域架构)。随后,还专门写了专业的论文详细论证此事(见参考文献)。 那么,反向的思考,是否存在足够“通用”的处理器,能够按照摩尔定律,在性能快速提升的同时,依然能够“包治百病”,尽可能满足众多客户的当前和未来一定时期的需求?
1 从历史中汲取灵感
1.1 RISC架构的兴起
在上世纪七十年代到八十年代初,因为流水线等技术的应用,CPU速度提升非常之快,而内存的容量和速度相对落后。通过不定长的指令格式能够提供更高的代码密度,同样大小内存空间能装载更多指令,从而间接的提高运行速度。并且,这时候的编译器能力比较有限,编译器很难做到CPU寄存器的合理利用,也无法针对微架构的具体特征进行深层次的性能优化,这就使得CPU的设计师们偏爱直接内存-内存以及寄存器-内存风格的指令执行模式。这些都是典型的复杂指令集(CISC)的特征。 这一时期,几乎所有的处理器设计都在按照CISC的路线发展,并且走向一个极端:不断加入新的指令,试图在指令集架构层面对高层编程语言提供更直接有效的支持,等等。这种发展路线使得硬件复杂度快速飞升,研发成本不断提高,研发周期变长,而编译器也难以利用这越来越复杂的指令集。 随后,RISC架构兴起。来自IBM的John Cocke认为,更加精简清爽的指令集设计将有助于减少硬件开发难度和成本,同时也有利于编译器进行代码优化工作。当时在在伯克利任教的David Patterson,与其学生们的成果在1983年国际固态电子电路大会(ISSCC)进行展示。尽管制造工艺老旧,主频比DEC、摩托罗拉、Intel等竞争对手同期制造的处理器慢上几乎一半,晶体管数量也只有几分之一,但是更加清爽的新式设计在编译器等其他工具的辅助下竟然将来自工业界的竞争对手们尽数击败。 RISC架构处理器提倡简化指令集设计、固定指令长度、统一指令编码格式、加速常用指令。这在当时来看,与占据主流的CISC设计风格背道而驰。但RISC阵营的David Patterson有了流片成功的芯片与硬件测试结果在手,加之1983年的ISSCC大会上聚集了几位与David Patterson观点相同的支持者,RISC流派开始逐步占据上风。 CISC ISA呈现出符合“二八定律”的特征:80%的指令很少被使用,只有20%的指令经常用到。RISC针对这20%的指令集,进行重组、优化和加速,另外80%指令通过这20%简单指令的组合来完成,性能反而高于CISC。 我们无意于介绍CISC和RISC的历史恩怨,之后的情况是:两种理念的ISA也是相互借鉴相互融合,逐步形成了现在的x86、ARM和RISC-v三强竞争的局面。
1.2 从微服务到云计算服务分层
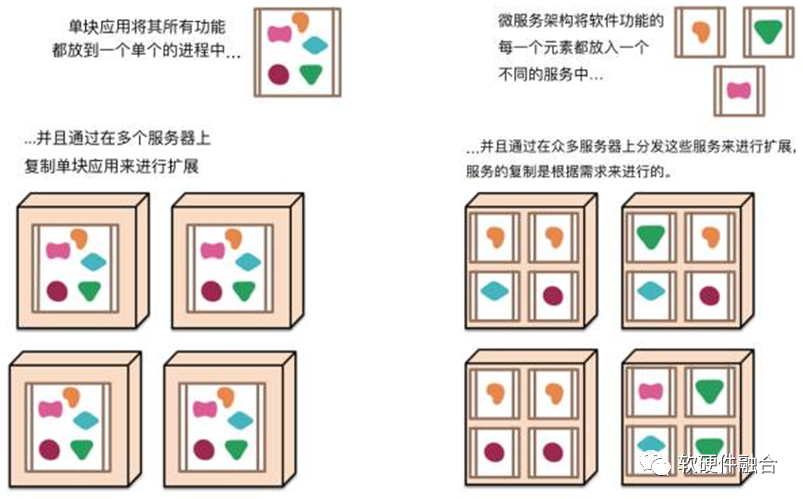
最开始,所有的应用都是单块“巨”应用系统。企业应用系统经常包含三个主要部分:客户端用户界面、数据库和服务端应用系统。渐渐地,特别是随着越来越多的应用系统正被部署到云端,软件变更受到了很大的限制:应用系统中一个很小部分的一处变更,也需要将整个单块应用系统进行重新构建和部署;单块应用逐渐难以保持一个良好的模块化结构,当对系统进行扩展时,不得不扩展整个应用系统,而不能仅扩展该系统中需要更多资源的那些部分。 这些问题催生出了微服务架构风格:以构建一组小型服务的方式来构建应用系统。除了这些服务能被独立地部署和扩展之外,每一个服务还能提供一个稳固的模块边界,甚至能允许使用不同的编程语言来编写不同的服务。并且,这些服务也能被不同的团队来管理。 微服务的方式,很好地把一个完整的应用系统拆分成用户关心的应用核心本身,以及其他一些辅助的服务,如:
基础设施服务,比如VM、容器、网络、存储、安全等;
中间件层服务,如负载均衡、数据库、文件系统、访问控制、消息队列、物联网接入平台等。
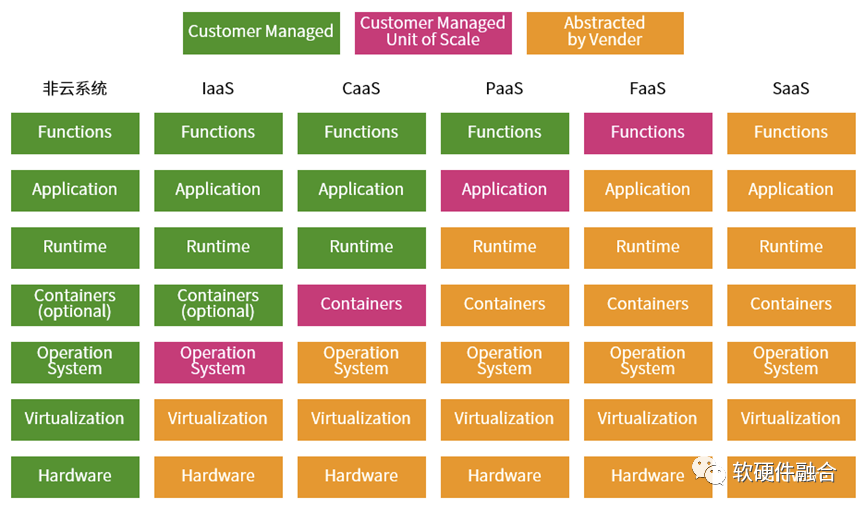
“一切皆服务”,当从微服务的视角,云计算是由不同的服务组成的分层服务体系:每一层就是一个服务族,然后不同层次的服务族组成整个云计算服务体系,这就是我们所熟悉的云计算三层服务IaaS、PaaS和SaaS。更详细的软件堆栈如上图所示,从非云系统所有的“服务”堆栈都需要用户自己拥有并维护,经过IaaS、CaaS、PaaS、FaaS,再到最后的SaaS,一切都由供应商运营维护。从左到右的过程,就是“服务”堆栈的下层layer不断的由云运营商接管的过程。 这也是一个鲜明的“二八定律”案例:80%的任务由云运营商负责,20%的任务由用户负责;站在用户的角度,20%自己负责的任务价值占到80%,而运营商负责的部分只占到到20%的价值。
1.3 结论:“二八定律”在发生作用
二八定律(也称80/20法则、关键少数法则、帕累托法则),起源于意大利经济学家维弗雷多·帕累托在洛桑大学注意到了80/20的联系,于他的文章《政治经济学》中说明了该现象,例如:意大利约有80%的土地由20%的人口所有、80%的豌豆产量来自20%的植株等等。该原则在现今企业管理中广泛运用。 回到计算机领域,二八定律也是一个常见的规律:
CISC指令太过冗繁,只有20%的指令经常用到,而另外80%的指令则较少用到。所以,RISC就只保留常见的20%的简单指令。
一个应用系统,完全不同的只是应用的核心部分(大约占20%),其他的如网络访问、存储盘、文件系统,也包括数据库、负载均衡、消息队列等(大约占80%)其实都是用户相对不关心,并且是众多应用系统都会用到的组件。
云计算,是一个由众多服务组成服务分层体系,随着不断的抽象封装,云运营商不断接管了80%的众多服务分层,而用户只需要关注20%的应用和函数即可。
等等。
2 分析一下各类处理引擎
2.1 从单位计算复杂度的视角
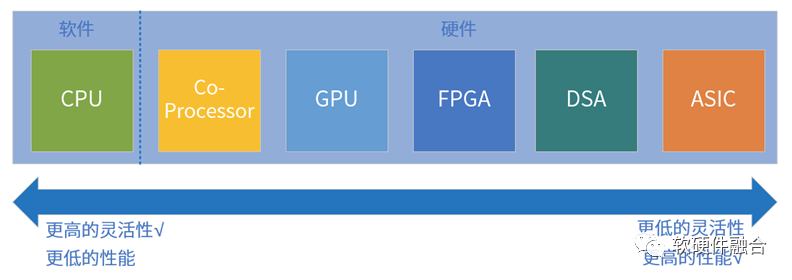
指令是软件和硬件的媒介,指令的复杂度(单位计算密度)决定了系统的软硬件解耦程度。按照指令的复杂度,典型的处理器引擎大致分为CPU、协处理器、GPU、FPGA、DSA、ASIC。任务在CPU运行,则定义为软件运行;任务在协处理器、GPU、FPGA、DSA或ASIC运行,则定义为硬件加速运行。 鱼和熊掌不可兼得,指令复杂度和编程灵活性是两个互反的特征:指令越简单,编程灵活性越高,因此我们才说软件有更高的灵活性;指令越复杂,性能越高,因此而受到的限制越多,只能用于特定领域或场景的应用,其软件灵活性越差。
2.2 从处理器引擎类型数量的视角
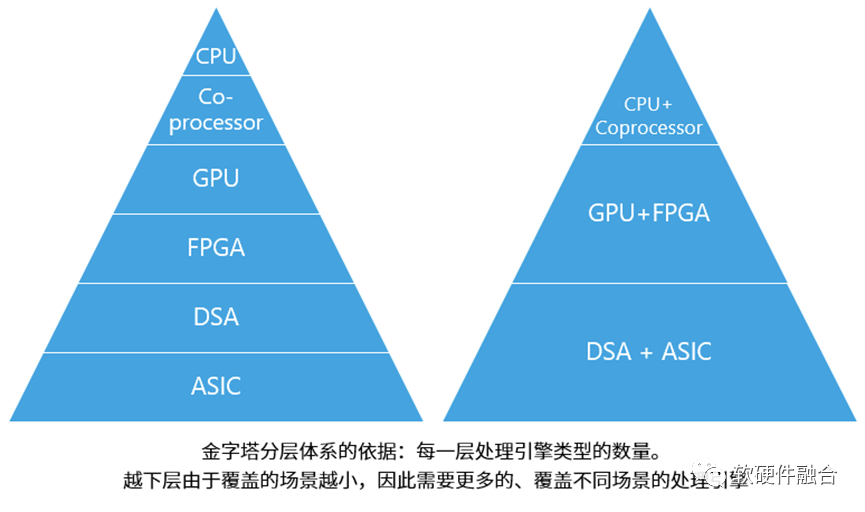
常见有六个主要的处理器引擎类型,依据不同类型处理引擎的数量不同,形成了金字塔形的处理器层次结构(Hierarchy):
CPU,是最通用的处理器引擎,CPU指令是最基础的,因此具有最好的灵活性。这一层级的只有CPU一个形态的处理器。
Coprocessor,是基于CPU的扩展指令集的运行引擎,如ARM的NEON、Intel的AVX、AMX扩展指令集和相应的协处理器。
GPU,本质上是很多小CPU核的并行,因此NP、Graphcore的IPU等都和GPU处于同一层次的处理器类型。
FPGA,从架构上来说,可以用来实现定制的ASIC引擎,但因为硬件可编程的能力,可以切换到其他ASIC引擎,具有一定的弹性可编程能力。
DSA,是接近于ASIC的设计,但具有一定程度上的可编程。覆盖的领域和场景比ASIC要大,但依然存在太多的领域需要特定的DSA去覆盖。
ASIC,是完全不可编程的定制处理引擎,理论上最复杂的“指令”以及最高的性能效率。因为覆盖的场景非常小,因此需要数量众多的ASIC处理引擎,才能覆盖各类场景。

为了更加简洁的理解六类常见的处理引擎的定位和作用,我们两两合并,定义三大类处理引擎类型:
基础设施层任务。基础设施层的任务都相对确定,适合DSA和ASIC处理引擎处理。
应用层可加速部分任务。基础设施层是Vendor负责提供,而应用层则是给到用户应用。用户的应用多种多样,因此应用层的加速也需要一定程度的弹性。这样,GPU和FPGA就相对比较合适。
应用层的不可加速部分。主要是一些通用的处理,如控制以及一些细粒度的计算。协处理器在具体实现上,是CPU的一部分。因此,CPU(包含协处理器)可以兼顾常规的控制处理以及一些计算任务。
2.3 从处理器覆盖场景的视角

“尺有所长,寸有所短”,每个类型的处理器都有自己的优势,也都有自己的劣势:
CPU及协处理器,最好的灵活可编程性,可以用在任何领域和场景。但性能却是最低。
GPU及FPGA,较好的软件或硬件编程能力,覆盖领域和场景较多,但性能居中无法极致。
DSA及ASIC,性能最好。但DSA的可编程性较少,可以覆盖特定领域;ASIC完全不可编程,只能覆盖特定领域里的某个具体场景。

“专业的人做专业的事”,通过CPU + Coprocessor + GPU + FPGA + DSA + ASIC等各种类型处理引擎的混合架构,能够兼顾性能和灵活性:
从宏观的看,绝大部分计算是通过加速完成的,性能有显著的提升;
而从用户应用的角度,应用依然是运行在CPU上,跟之前没有变化,依然是自己“掌控一切”。
3 设计一个理想的宏处理器
因为二八定律的存在,在整个系统堆栈里,用户关心的那20%的相对不确定的任务,仍然需要用户通过软件编程实现;而用户不关心的、每个用户应用系统都会存在的、占80%的这些相对确定的任务,则适合通过硬件加速的方式来实现。
3.1 当前的处理器芯片基本都是“单兵作战”
处理器芯片是由各类处理器引擎组成的,在云计算数据中心,主要有三类同构处理器芯片。分析如下表所示。
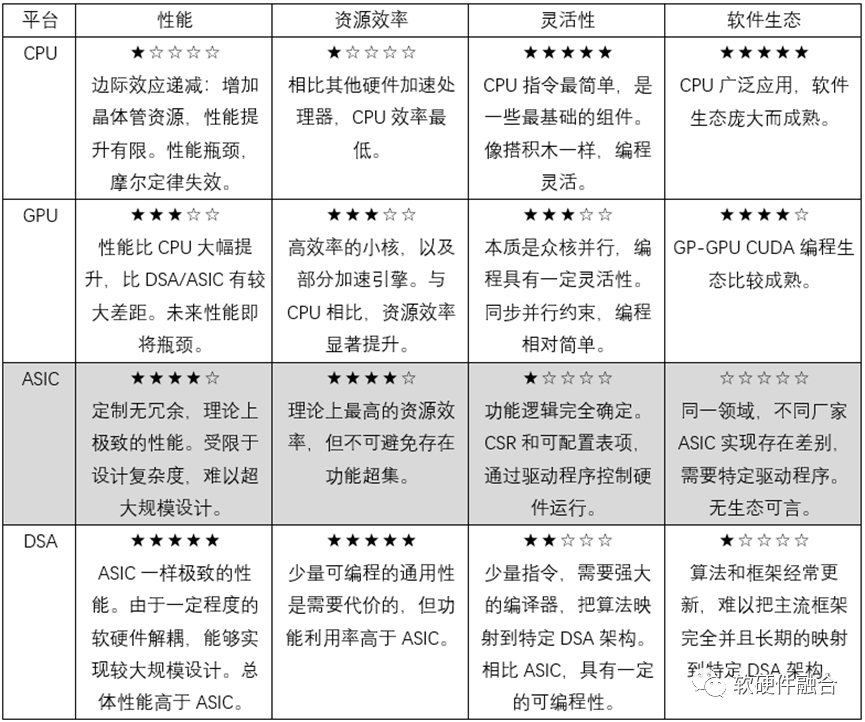
这里我们对三类引擎组成的同构处理器进行分析:
CPU是数据中心最常见的处理器,但受限于性能瓶颈的原因,目前大家都在“八仙过海,各显神通”,通过各种各样的优化手段,来努力提升整个服务器和数据中心的算力。
GPU在HPC、图形图形等领域,有非常大的优势。近些年,随着AI的兴起,与此同时AI算法更新很快,这就使得GPU成为AI最合适的处理器,GPU因此大放光彩。
DSA目前最主要的领域也是在AI,第一款经典的DSA处理器是谷歌TPU。目前,受限于AI算法的快速迭代,仍然没有DSA处理器的大范围落地的案例。即使强大如谷歌能从芯片、框架到服务统统协同优化,但严格来说,TPU也仍然没有大范围落地。
3.2 CPU+xPU的异构处理仍然不够
另外,对单个处理器引擎来说,性能和灵活性是一对矛盾,如果只考虑同构计算,则很难达到方方面面兼顾。可以通过板级集成或者芯片内集成异构的方式,实现CPU+GPU/FPGA/DSA的架构,但也是存在一些问题。
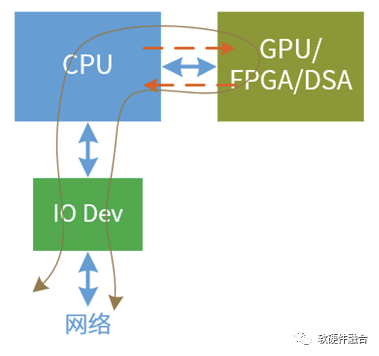
传统异构计算的架构,是以CPU为中心,这种架构本身就存在一些问题:
IO路径。CPU+xPU架构IO路径太长,IO成为整个算力的瓶颈。
输入输出损耗。CPU+xPU加速增加了额外的CPU和xPU之间的数据输入输出损耗。
系统复杂度。异构计算是显式的,CPU侧软件知道在做加速,CPU侧需要处理与加速器侧的数据和消息交互。
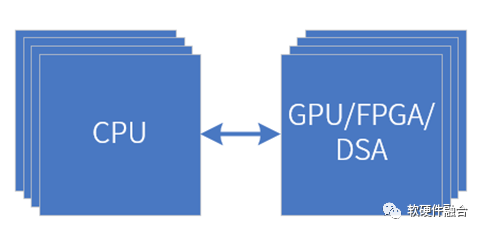
仍然受限于硬件加速处理器的特点,异构计算仍无法兼顾性能和灵活性:
GPU异构加速架构。虽然GPU具有非常好的弹性加速能力,覆盖非常多的领域,但受限于GPU的性能效率,无法做到极致性能的加速。
FPGA异构加速架构。FPGA可以做到硬件可编程,可以通过FaaS(此处FaaS为FPGA as a Service)机制实现弹性加速。FPGA的问题在于成本和功耗过高,以及设计规模的约束,只能做非常少量并且规模较小的加速引擎。
DSA异构加速架构。DSA可以做到极致的性能加速能力,但受限于其只针对某个特定领域,所以使用范围受限。
3.3 团队协作成就通用的超异构处理器
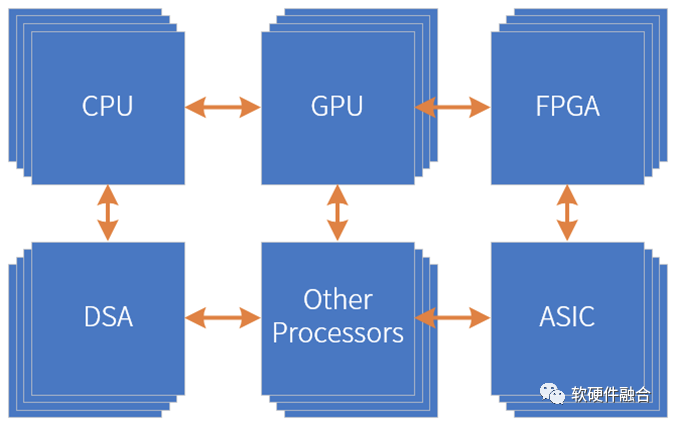
随着CPU、GPU等常见处理引擎的成熟,也随着工艺和Chiplet技术的进步,我们可以在单个芯片集成更多的处理器引擎,使得在单芯片超越2个形态处理引擎成为了可能,超异构处理器(Hyper-heterogeneous Processing Unit,HPU)开始逐步成为现实。
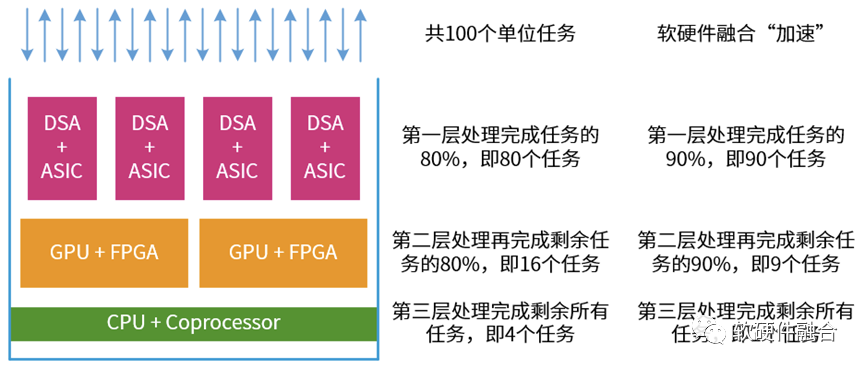
如上图所示,有点像塔防游戏,我们设置了三层“防御”,然后待处理的任务就像是“需要消灭的敌人”:
我们假设,待处理的有100个单位任务;
第一层“防御”,DSA+ASIC能够覆盖80%的任务(即80个任务)的性能加速,可以很快“消灭”。但受限于覆盖的领域和场景,会有20%(即20个任务)的“漏网之鱼”;
第二层“防御”,GPU+FPGA能够覆盖接下来任务的80%,性能依然强劲,可以搞定剩下任务的80%(即16个任务)。但仍然有一些不是那么适合硬件加速的“顽固敌人”(剩余的4个任务)。
第三层“防御”,CPU和协处理器作为“定海神针”,能够覆盖所有场景。由它们负责“消灭”最后的“顽固敌人”(即处理最后4个任务)。
在没有硬件加速的情况下,所有的100个任务都需要CPU来处理;而有了加速之后,CPU只需要处理4个任务。当整个设计足够均衡(各类加速引擎不成为性能的瓶颈)的时候,反过来我们可以说,通过超异构处理器HPU可以实现25倍的性能提升。 受宏观超大规模数据中心的影响,也受软硬件深度融合的加持,可以继续优化这里的“二八定律”,假设我们可以把不同层次处理引擎可处理的任务比例再增强10%。这样:DSA+ASIC完成90个任务,GPU+FPGA完成9个任务,最终CPU只需要完成1个任务。或者反过来说,可以通过软硬件融合,实现通用的超异构处理器GP-HPU,实现100倍的性能提升。
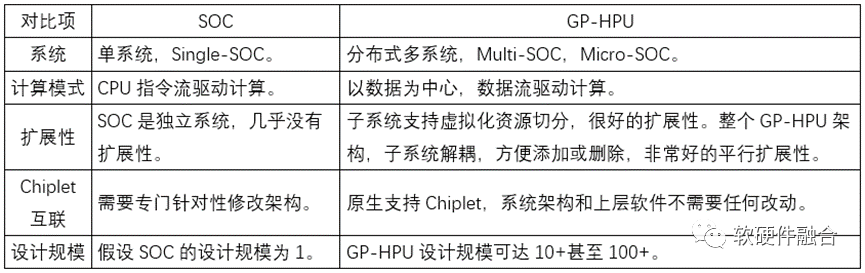
3.4 超越传统SOC
通用超异构处理器GP-HPU,可以算是SOC,但又跟传统的SOC有很大的不同。如果无法认识到这些不同,就无法理解到HPU的本质。下表是一些典型的区别对比。
审核编辑 :李倩
-
RISC-V架构的目标和特点2024-08-23 750
-
RISC-V架构的特点2024-05-24 1087
-
RISC-V强势崛起为芯片架构第三极2023-08-30 833
-
谈一谈RISC-V架构的优势和特点2023-05-14 2027
-
RISC-V架构2023-04-03 2066
-
什么是RISC架构?RISC架构的优点与缺点2023-02-27 780
-
精简指令集架构RISC与复杂指令集架构CISC有何区别2021-12-23 2998
-
RISC-V架构简介2021-07-28 3893
-
分析RISC-V架构的不同之处2021-07-26 1841
-
ARM与RISC-V架构的区别是什么?2021-04-25 6592
-
科普RISC-V生态架构(认识RISC-V)2020-08-02 7036
-
简单就是美——RISC-V架构的设计哲学2020-07-27 2355
-
RISC-V 生态架构浅析2020-06-22 3134
-
RISC架构服务器简介2009-11-13 7154
全部0条评论

快来发表一下你的评论吧 !
