

PyTorch显存机制分析
描述
作者最近两年在研究分布式并行,经常使用PyTorch框架。一开始用的时候对于PyTorch的显存机制也是一知半解,连蒙带猜的,经常来知乎上来找答案,那么我就吸收大家的看法,为PyTorch的显存机制做个小的总结吧。
01 理论知识1.1 深度学习训练过程
开门见山的说,PyTorch在进行深度学习训练的时候,有4大部分的显存开销,分别是模型参数(parameters),模型参数的梯度(gradients),优化器状态(optimizer states)以及中间激活值(intermediate activations) 或者叫中间结果(intermediate results)。为了后面显存分析阐述的方便,我将深度学习的训练定义4个步骤:- 模型定义:定义了模型的网络结构,产生模型参数;
- 前向传播:执行模型的前向传播,产生中间激活值;
- 后向传播:执行模型的后向传播,产生梯度;
- 梯度更新:执行模型参数的更新,第一次执行的时候产生优化器状态。
1.2 前向传播
拿Linear层(或者叫Dense层,前馈神经网络,全连接层等等...)举例:假设他的权重矩阵为W,偏置向量为b,那么他的前向计算过程就是: ,这里的X为该层的输入向量,Y为输出向量(中间激活值)1.3 后向传播(反向传播)
参考了这篇文章《神经网络反向传播的数学原理》https://zhuanlan.zhihu.com/p/22473137后向传播回来了一个第l+1层的输出误差矩阵 ,用以计算该层的梯度和输入误差1.4 梯度更新
接下来就是利用 W_diff 和 b_diff 进行更新了: 当然使用 Adam 优化器的时候,实际的更新过程并没有上面的这么简单。目前用的最多的是 AdamW ,可以看看这篇文章《当前训练神经网络最快的方式:AdamW优化算法+超级收敛》https://zhuanlan.zhihu.com/p/38945390)但是使用这一类优化器,也会带来额外的显存开销。对于每一个参数,Adam都会为它准备对应的2个优化器状态,分别是动量(momentum)和方差(variance),用以加速模型的训练。02 显存分析方法与Torch机制2.1 分析方法
(1) No Nvidia-smi我看很多人现在还在用 nvidia-smi 来看 pytorch 的显存占用,盯着跳来跳去的torch缓存区分析真的不累吗。(贴一个Torch为什么不用Nvidia-smi看的图)。而且PyTorch是有缓存区的设置的,意思就是一个Tensor就算被释放了,进程也不会把空闲出来的显存还给GPU,而是等待下一个Tensor来填入这一片被释放的空间。有什么好处?进程不需要重新向GPU申请显存了,运行速度会快很多,有什么坏处?他不能准确地给出某一个时间点具体的Tensor占用的显存,而是显示的已经分配到的显存和显存缓冲区之和。这也是令很多人在使用PyTorch时对显存占用感到困惑的罪魁祸首。(2) torch.cuda is all you need在分析PyTorch的显存时候,一定要使用torch.cuda里的显存分析函数,我用的最多的是torch.cuda.memory_allocated()和torch.cuda.max_memory_allocated(),前者可以精准地反馈当前进程中Torch.Tensor所占用的GPU显存,后者则可以告诉我们到调用函数为止所达到的最大的显存占用字节数。还有像torch.cuda.memory_reserved()这样的函数则是查看当前进程所分配的显存缓冲区是多少的。memory_allocated+memory_reserved就等于nvidia-smi中的值啦。非~常~好~用chao da sheng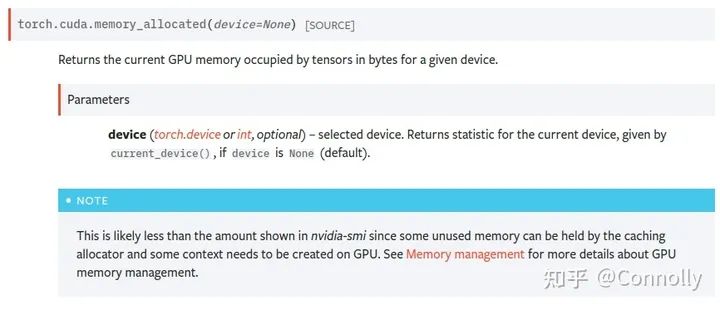 Torch 官方文档2.2 PyTorch context开销-----之前没有提到PyTorch context的开销,做个补充...我注意到有很多同学在做显存分析的时候是为了在训练的时候可以把卡的显存用满,这个之前没有考虑到呢。其实PyTorch context是我们在使用torch的时候的一个大头开销。主要参考的是论坛里的这篇讨论:How do I create Torch Tensor without any wasted storage space/baggage?https://discuss.pytorch.org/t/how-do-i-create-torch-tensor-without-any-wasted-storage-space-baggage/131134什么是PyTorch context? 其实官方给他的称呼是CUDA context,就是在第一次执行CUDA操作,也就是使用GPU的时候所需要创建的维护设备间工作的一些相关信息。如下图所示这个值跟CUDA的版本,pytorch的版本以及所使用的设备都是有关系的。目前我在ubuntu的torch1.9上测过RTX 3090和V100的context 开销。其中3090用的CUDA 11.4,开销为1639MB;V100用的CUDA 10.2,开销为1351MB。感兴趣的同学可以在shell中执行下面这两行代码,然后用nvidia-smi去看看自己的环境里context的大小。然后用总大小减去context的大小再做显存分析。
Torch 官方文档2.2 PyTorch context开销-----之前没有提到PyTorch context的开销,做个补充...我注意到有很多同学在做显存分析的时候是为了在训练的时候可以把卡的显存用满,这个之前没有考虑到呢。其实PyTorch context是我们在使用torch的时候的一个大头开销。主要参考的是论坛里的这篇讨论:How do I create Torch Tensor without any wasted storage space/baggage?https://discuss.pytorch.org/t/how-do-i-create-torch-tensor-without-any-wasted-storage-space-baggage/131134什么是PyTorch context? 其实官方给他的称呼是CUDA context,就是在第一次执行CUDA操作,也就是使用GPU的时候所需要创建的维护设备间工作的一些相关信息。如下图所示这个值跟CUDA的版本,pytorch的版本以及所使用的设备都是有关系的。目前我在ubuntu的torch1.9上测过RTX 3090和V100的context 开销。其中3090用的CUDA 11.4,开销为1639MB;V100用的CUDA 10.2,开销为1351MB。感兴趣的同学可以在shell中执行下面这两行代码,然后用nvidia-smi去看看自己的环境里context的大小。然后用总大小减去context的大小再做显存分析。import torch temp = torch.tensor([1.0]).cuda()我估计会有人问怎么去减小这个开销...官方也给了一个办法,看看自己有哪些cuda依赖是不需要的,比如cuDNN,然后自己重新编译一遍PyTorch。编译的时候把对应的包的flag给设为false就好了。我是还没有试过,要搭编译的环境太难受了,而且还要经常和库做更新。
2.3 Torch显存分配机制
在PyTorch中,显存是按页为单位进行分配的,这可能是CUDA设备的限制。就算我们只想申请4字节的显存,CUDA也会为我们分配512字节或者1024字节的空间。2.4 Torch显存释放机制
在PyTorch中,只要一个Tensor对象在后续不会再被使用,那么PyTorch就会自动回收该Tensor所占用的显存,并以缓冲区的形式继续占用显存。要是实在看缓冲区不爽的话,也可以用torch.cuda.empty_cache()把它归零,但是程序速度会变慢哦03 训练过程显存分析为了让大家方便理解,我这里用torch.nn.Linear(1024, 1024, bias=False) 来做例子。为了省事,loss函数则直接对输出的样本进行求和得到。没办法,想直接执行loss.backward()的话,loss得是标量才行呢。示例代码:import torch model = torch.nn.Linear(1024,1024, bias=False).cuda() optimizer = torch.optim.AdamW(model.parameters()) inputs = torch.tensor([1.0]*1024).cuda() # shape = (1024) outputs = model(inputs) # shape = (1024) loss = sum(outputs) # shape = (1) loss.backward() optimizer.step()
3.1 模型的定义
结论:显存占用量约为参数量乘以4import torch model = torch.nn.Linear(1024,1024, bias=False).cuda() print(torch.cuda.memory_allocated())打印出来的数值为4194304,刚好等于1024×1024×4。
3.2 前向传播过程
结论:显存增加等于每一层模型产生的结果的显存之和,且跟batch_size成正比。inputs = torch.tensor([1.0]*1024).cuda() # shape = (1024) memory + 4096 outputs = model(inputs) # memory + 4096代码中,outputs为产生的中间激活值,同时它也恰好是该模型的输出结果。在执行完这一步之后,显存增加了4096字节。(不算inputs的显存的话)。
3.3 后向传播过程
后向传播会将模型的中间激活值给消耗并释放掉掉,并为每一个模型中的参数计算其对应的梯度。在第一次执行的时候,会为模型参数分配对应的用来存储梯度的空间。loss = sum(outputs) # memory + 512(torch cuda分配最小单位) temp = torch.cuda.memory_allocated() loss.backward() print(torch.cuda.memory_allocated() - temp) # 第一次增加4194304第一次执行时显存增加:4194304字节 - 激活值大小;第二次以后执行显存减少:激活值大小;Note:由于这个中间激活值被赋给了outputs,所以后面在后向传播的时候会发现,这个outputs的显存没有被释放掉。但是当层数变深的时候,就能明显看到变化了。为了让大家看到变化,再写一段代码~
import torch # 模型初始化 linear1 = torch.nn.Linear(1024,1024, bias=False).cuda() # + 4194304 print(torch.cuda.memory_allocated()) linear2 = torch.nn.Linear(1024, 1, bias=False).cuda() # + 4096 print(torch.cuda.memory_allocated()) # 输入定义 inputs = torch.tensor([[1.0]*1024]*1024).cuda() # shape = (1024,1024) # + 4194304 print(torch.cuda.memory_allocated()) # 前向传播 loss = sum(linear2(linear1(inputs))) # shape = (1) # memory + 4194304 + 512 print(torch.cuda.memory_allocated()) # 后向传播 loss.backward() # memory - 4194304 + 4194304 + 4096 print(torch.cuda.memory_allocated()) # 再来一次~ loss = sum(linear2(linear1(inputs))) # shape = (1) # memory + 4194304 (512没了,因为loss的ref还在) print(torch.cuda.memory_allocated()) loss.backward() # memory - 4194304 print(torch.cuda.memory_allocated())
3.4 参数更新
optimizer.step() # 第一次增加8388608,第二次就不增不减了哦第一次执行时,会为每一个参数初始化其优化器状态,对于这里的AdamW而言,每一个参数需要4*2=8个字节。第二次开始,不会再额外分配显存。显存开销:第一次: 增加8388608字节第二次及以后: 无增减3.5 Note由于计算机计算的特性,有一些计算操作在计算过程中是会带来额外的显存开销的。但是这种开销在torch.memory_allocated中是不能被察觉的。比如在AdamW在进行某一层的更新的时候,会带来2倍该层参数量大小的临时额外开销。这个在max_memory_allocated中可以看到。在本例中就是8388608字节。
审核编辑 :李倩
声明:本文内容及配图由入驻作者撰写或者入驻合作网站授权转载。文章观点仅代表作者本人,不代表电子发烧友网立场。文章及其配图仅供工程师学习之用,如有内容侵权或者其他违规问题,请联系本站处理。
举报投诉
-
PyTorch 中RuntimeError分析2026-03-06 1218
-
TorchFix:基于PyTorch的代码静态分析2023-12-18 2003
-
PyTorch教程16.1之情绪分析和数据集2023-06-05 803
-
PyTorch 的 Autograd 机制和使用2022-08-15 1994
-
一篇非常新的介绍PyTorch内部机制的文章2020-12-26 3397
-
PyTorch如何入门2020-06-01 1991
-
一文解构PyTorch:深入了解PyTorch内部机制2019-03-01 4959
-
Pytorch模型训练实用PDF教程【中文】2018-12-21 5207
-
什么是显存频率2010-02-05 1248
-
显卡显存时钟周期2009-12-25 909
-
显存容量2009-12-17 1044
全部0条评论

快来发表一下你的评论吧 !
