

人工智能的透明度和可解释性义务
描述
2021 年 4 月 21 日,欧盟委员会向 h ARM 发布了一项法规提案,将 AI 系统的设计和营销规则称为人工智能法( AIA )。
监管机构认为人工智能系统存在风险。高风险人工智能系统将受到具体设计和实施义务的约束,以提高透明度。信用评分模型是高风险用例的一个例子。
在《人工智能法》出台之前,关于透明度的原则已经出现在一些欧洲人工智能准则中。例如,在可信人工智能的道德准则中,数据、系统设计和业务模型应该是透明的。与透明度相关的是,人工智能系统的技术过程和相关的人类决策都必须是可解释的。
欧盟 Horizon2020 研究与创新项目FIN-TECH中也讨论了人工智能的透明度和可解释性义务。
该项目开发了新的方法和用例,以管理风险,并在欧洲金融服务领域扩展数字金融和人工智能。 20 多所大学以及欧洲监管和金融服务界参与了研讨会、培训和用例演示,并对用例进行了反馈和评估。

图 1 :欧盟 Horizon2020 项目FIN-TECH(左)和欧盟委员会(右)的标志。根据第 825215 号赠款协议( ICT-35-2018 主题,行动类型: CSA ),该项目获得了欧盟地平线 2020 研究与创新计划的资助。内容仅反映了作者的观点,委员会不负责对其所含信息的任何使用。
该项目中评级最好的 AI 用例是用于信用风险管理的可解释 AI ( XAI )方法,该方法旨在克服 AI 模型的可解释性差距。该项目的评估系统根据欧洲监管当局、中央银行、金融服务公司和金融科技公司的结构化反馈确定了该案例。
该用例在 Springer 上以“可解释机器学习在信用风险管理中的应用”的形式发布,并使用夏普利值和SHAP( SHapley 加法解释)来确定已经训练过的 AI / ML 模型中决策的最重要变量。它的灵感来源于英格兰银行(“金融学中的机器学习可解释性:在违约风险分析中的应用”)发布的一个模型。
基础方法分析本地或全球解释性数据,分组或集群,其中每个集群由具有非常相似解释性数据的投资组合组成。通过这种方式,可以深入了解经过训练的模型的内部工作原理,从而对其进行潜在的调试和控制。该方法还可以在解释性数据中调查网络和复杂系统的影响。
这是一种非常简单的技术,工作流和算法组合可以应用于许多人工智能( AI )和机器学习( ML )应用程序。在描述该概念的好处和使用场景之前,我们将讨论该方法的计算挑战以及使用高性能计算( HPC )中使用的技术加速此类模型的需求。
加速建模、解释性和可视化
与实际数据相比, FIN-TECH 中使用的原始数据集相当小。由于有必要在更大的数据集上测试模型,以了解金融机构大规模生产环境的影响, NVIDIA 的一个团队在RAPIDS中实施了整个工作流,以快速处理大量数据。这种改进的性能允许更快的迭代,节省数据科学团队的时间,并允许更快地获得更好的结果。
RAPIDS 是一套开源 Python 库,可以使用 GPU 加速来加速端到端数据科学工作流。在本用例中,它加速了整个工作流:
数据加载与预处理
Training
解释(形状值)
对 SHAP 值进行聚类
降维
可视化与过滤
该团队处理了一组类似于解释和加速贷款拖欠的机器学习上相关博客中的数据集的房利美数据集,其中包含数百万个数据点。
SHAP 值被分组,但也可以通过网络图分析进行分析。 RAPIDS ‘ GPU – 加速库cuML(机器学习算法)和cuGraph(图形分析)非常适合此用例。这也适用于降维,以便以后在 2D 或 3D 中绘制形状点云。此外,可以使用 GPU – 加速Plotly和其他工具构建以下过滤和可视化步骤。
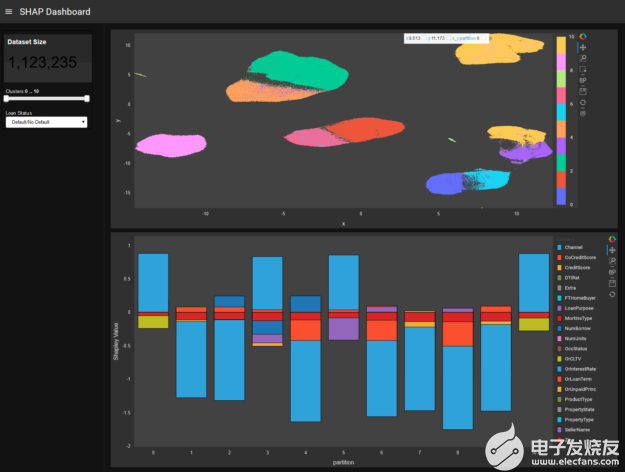
图 2 :仪表板用户可以与模型的 SHAP 值交互,并进一步分析模型级别的全貌或深入到模型的特定“区域”。为了便于解释,上图中的每一组点代表一组编号为 0 到 10 的类似贷款。每个簇在底部图中具有特征,簇编号沿 x 轴。对于给定的簇,矩形的高度对应于数据集中的 Shapley 值和 credit customer mortgage loan 特征的颜色。从正 Shapley 值或负 Shapley 值,可以看出集群的功能如何使贷款减少(负方向)或增加(正方向),可能会默认。
例如,可以显示整个模型的形状簇,并进一步分析特定簇和数据点,在更细粒度的级别上查看特征贡献和交互。此外,颜色代码可以从形状视图切换到高亮显示真实和预测的类标签,并显示特征。
此外,最近的Captum和Captum软件包中提供的 GPU 解释程序加速了任何 cuML 或 scikit 学习模型的预测后解释。对于基于树的模型,如 XGBoost , SHAP Explainer 可以计算输入特征的 Shapley 值。深度学习模型可以使用 SHAP GradientExplainer 或 Captum GradientShap 方法来计算 Shapley 值,方法是计算关于输入特征和添加高斯随机噪声的特征的梯度。 SHAP 和 Captum 都使用 GPU s 来加速 Shapley 值的计算。
对模型的深入研究
本文介绍的基于机器学习的可视化过程处理另一个任意 AI / ML 模型的结果。它为已经训练过的、可能不透明的机器学习模型提供了更多的 i NSight 、控制和透明度。
它采用了一种模型不可知的方法,旨在以可变重要性(个人输入变量贡献)的形式确定人工智能系统的决策标准,并应用于信用风险评估和管理以及投资组合构建等其他金融领域。
关键概念是模型的夏普里值分解,这是合作博弈论中的一个收益分配概念。到目前为止,它是唯一植根于经济基础的 XAI (可解释 AI )方法。它提供了对预测概率的变量贡献的细分,从 0 到 1 。这意味着每个数据点(例如,投资组合中的信贷或贷款客户)不仅由输入特征(机器学习模型的输入)表示,而且还由这些输入特征对经过训练的机器学习模型的二进制预测的贡献 0 或 1 表示。
Shapley 解释值可用于基于降维技术(如 PCA 、 MDS 、 t-SNE )的可视化映射,或用于表示学习(如聚类和图形分析)(如社区检测和网络中心度测量)。这些数据驱动的学习表示揭示了数据点的分段(客户)其中每个集群包含非常相似的决策标准,而其他集群中的数据点显示非常不同的决策标准。
层次聚类,尤其是图论和网络分析非常适合研究复杂系统,如信贷组合的 Shapley 解释值。这些系统具有突发性、自组织性的特点。该方法将(可能不透明的) AI / ML 模型的可变贡献结果视为一个复杂系统,并通过图论和聚类分析进一步分析其性质。通过这种方式,用户可以更好、更深入地了解 AI / ML 模型到底学到了什么,因为不同的解释数据点被分组(集群)或作为具有特定链接结构的网络进行排列。
可以分析和理解集群和网络结构内部的以下现象:趋势、异常、热点、紧急效应和引爆点。由于该方法是模型不可知的,因此它可以应用于任何 AI / ML 模型。这还可以对基于相同数据训练的多个模型进行比较。
在下文中,我们描述了基于 SHAP 集群和交互式可解释性仪表板的拟议方法的一些用例场景:
数据点的组或簇表示 AI / ML 模型的类似决策。
聚类间相交处的数据点指向模糊决策,可进一步研究。
对默认和非默认的预测量几乎相等的集群可能会指出机器学习模型中的错误或问题。
客户细分:数据点不仅可以通过其输入变量(代表客户相似性的聚类)进行聚类,还可以通过其在决策中的变量贡献进行聚类。
提出的可解释性模型的目标是传统银行以及 P2P 贷款/众筹的“ fintech ”平台中信贷组合的风险管理、评估和评分功能。
指导方针和法规需要模型解释
AI HLEG 起草的道德准则提出了一种以人为中心的 AI 方法,并列出了 AI 系统应满足的几个关键要求,以便被认为是可信的。
提出的 SHAP 聚类有助于缩小人工智能的解释鸿沟。监管人员将调整其方法和技能,以支持在银行业引入 AI / ML 。银行需要弄清楚人类在模型监管中的位置,并且必须向监管人员合理解释其 AI / ML 系统的实际功能以及目的。
决策必须是知情的,而且必须有人参与监督。 SHAP 聚类方法使用户能够理解做出决策的原因。“为什么”不是因果关系,而是表示为输入变量的数值贡献。用户可以查看特定的数据点或集群,并查看输入变量、变量对预测的贡献以及预测本身。
一个看似合理的解释可能会出现,使基于机器的决策与“有意义”的人类叙事相协调。模型可以更好地控制,因为它提供了关于如何在全局层面(全局变量重要性)和局部层面(数据点)上做出所有决策的反馈。集群步骤甚至为特定集群的成员提供了可变的贡献,对于一组客户也是如此。用户可以根据输入变量识别这组客户的属性,以便了解这组客户的决策过程。所有这些分析功能和工具加上交互式视觉探索,使用户能够更好地理解完全黑盒模型的结果。更好的理解导致更有效的控制。
为确保可追溯性,应纳入符合最佳标准的文件编制机制。除其他外,这包括用于模型培训和验证的数据集文档、任何数据标签的过程和输出,以及人工智能系统所做决策的明确记录。
SHAP 聚类方法允许追溯和记录对决策的可变贡献。形状信息的聚类是该方法添加的新信息之一,因此可用于丰富可追溯性和文档。此外,可以记录基于新信息改进模型的步骤。
有关该方法及其用例的更多阅读,请参见出版物“财务风险管理和可解释、可信、负责任的人工智能’。
结论
SHAP 聚类提供了机器学习模型的局部、全局和组级决策的解释。这里提供的扩展允许对解释进行进一步分析。这允许从业者为基于机器学习的决策构建一个叙述和解释,以满足业务、监管和客户需求。
也许解释性最重要的方面是受众。模型解释的受众中有许多类型的人和角色:模型构建者、模型检查者、合规和治理官、风险经理、产品所有者、高级经理、主管、客户和监管机构。数据科学团队可以理解原始和聚集的 SHAP 信息,银行或金融科技公司中的大多数其他人都可以通过培训理解。这同样适用于监事。对于客户/和客户而言,提及哪些变量最重要(可能应告知客户决策/拒绝的原因)或客户可以做些什么来改进某些变量以获得积极决策,这一切都可以从 SHAP 数据中得出。形状信息提供了一个通用、一致和准确的视图和语言来描述 AI 模型。
关于作者
Jochen Papenbrock 位于德国法兰克福,在过去的15年中,Jochen一直在金融服务业人工智能领域担任各种角色,担任思想领袖、实施者、研究者和生态系统塑造者。
Mark J. Bennett 是 NVIDIA 的高级数据科学家,他专注于金融机器学习的加速。他拥有南加州大学计算机科学硕士学位和博士学位。来自加州大学洛杉矶分校的计算机科学,并为爱荷华大学和芝加哥大学教授研究生业务分析。
Emanuel Scoullos 是 NVIDIA 金融服务和技术团队的数据科学家,他专注于 FSI 内的 GPU 应用。此前,他在反洗钱领域的一家初创公司担任数据科学家,应用数据科学、分析和工程技术构建机器学习管道。他获得了博士学位。普林斯顿大学化学工程硕士和罗格斯大学化学工程学士学位。
Miguel Martinez 是 NVIDIA 的高级深度学习数据科学家,他专注于 RAPIDS 和 Merlin 。此前,他曾指导过 Udacity 人工智能纳米学位的学生。他有很强的金融服务背景,主要专注于支付和渠道。作为一个持续而坚定的学习者, Miguel 总是在迎接新的挑战。
John Ashley 目前领导 NVIDIA 的全球金融服务和技术团队。在此之前,他启动并领导了 NVIDIA 的专业服务深度学习实践和 NVIDIA 深度学习专业服务合作伙伴计划,致力于帮助客户和合作伙伴采用并提供深度学习解决方案。
审核编辑:郭婷
-
如何实现前面板由透明度0到隐藏透明度100的变化2014-12-17 6129
-
如何设置某一控件的透明度2015-09-17 16480
-
神经网络可解释性研究的重要性日益凸显2019-06-27 6220
-
什么是“可解释的”? 可解释性AI不能解释什么2020-05-31 9406
-
如何加强和扩大人工智能的透明度?2020-07-16 1977
-
如何实现可解释的人工智能?2020-09-20 4475
-
机器学习模型可解释性的介绍2020-12-10 1603
-
关于机器学习模型的六大可解释性技术2022-02-26 3184
-
机器学习模型的可解释性算法详解2022-02-16 6474
-
人工智能可解释性规制面临的问题分析2022-08-09 3295
-
可以提高机器学习模型的可解释性技术2023-02-08 2465
-
文献综述:确保人工智能可解释性和可信度的来源记录2023-04-28 2925
-
可信人工智能研究方向与算法探索2023-05-24 1489
-
机器学习模型可解释性的结果分析2023-09-28 1860
-
加州立法推动AI透明度,生成式人工智能迎来数据披露新纪元2024-08-28 1728
全部0条评论

快来发表一下你的评论吧 !
