

使用MIG和Kubernetes部署Triton推理服务器
描述
NVIDIA Triton 推理服务器是一款开源人工智能模型服务软件,可简化在生产中大规模部署经过培训的人工智能模型。对于服务器管理的任何模型,客户端可以远程向提供的 HTTP 或 gRPC 端点发送推断请求。
NVIDIA Triton 可以管理任意数量和混合型号(受系统磁盘和内存资源的限制)。它还支持多种深度学习框架,如 TensorFlow 、 PyTorch 、 NVIDIA TensorRT 等。这为开发者和数据科学家提供了灵活性,他们不再需要使用特定的模型框架。 NVIDIA Triton 旨在轻松与 Kubernetes 集成,以便在数据中心进行大规模部署。
多实例并行运行多个工作负载( MIG )可以最大化 A100 GPU 和新发布的 A30 GPU 的 GPU 利用率。它还可以让多个用户通过 GPU 共享一个 GPU ,就像有多个更小的 GPU 一样。 MIG 功能可以将单个 GPU 划分为多个 GPU 分区,称为 GPU 实例。每个实例都有专用的内存和计算资源,因此硬件级别的隔离可以确保同时执行工作负载,同时保证服务质量和故障隔离。
在本文中,我们分享以下最佳实践:
在 A100 上使用 MIG 并行部署多个 Triton 推理服务器
使用 Kubernetes 和 Prometheus 监控堆栈根据推理请求的数量自动调整 Triton 推理服务器的数量。
使用 NGINX Plus 负载平衡器在不同的 Triton 推理服务器之间均匀分配推理负载。
这一思想可以应用于单个节点或多个节点上的多个 A100 或 A30 GPU ,以便在生产中自动缩放 NVIDIA Triton 部署。例如, DGX A100 允许在 Kubernetes 吊舱上运行多达 56 个 Triton 推理服务器(每个 A100 最多有七个使用 MIG 的服务器)。
硬件和软件先决条件
要使用 MIG ,必须启用 MIG 模式并在A100或A30 GPU 上创建 MIG 设备。您可以使用nvidia-smi创建 GPU 实例并手动计算实例。或者,使用 NVIDIA 新的 MIG 分离工具nvidia-mig-parted,该工具允许管理员定义一组可能的 Clara 配置,以应用于节点上的所有 GPU 。
在运行时,将nvidia-mig-parted指向其中一个配置,nvidia-mig-parted负责应用它。通过这种方式,相同的配置文件可以分布在集群中的所有节点上,并且可以使用运行时标志来决定将哪些配置应用于节点。因为如果重新启动机器, MIG 配置将消失,nvidia-mig-parted还使重新启动后创建 MIG 实例变得更容易。
在 Kubernetes 环境中,必须安装 NVIDIA 设备插件和 GPU 功能发现插件才能使用 MIG 。您可以单独安装每个插件,或者使用云本机 NVIDIA GPU 运算符,它是一个包,包含在 Kubernetes 中启用 GPU 的所有内容。您还可以使用 NVIDIA 部署工具DeepOps,该工具负责安装和插件,以及普罗米修斯监控堆栈,包括kube-prometheus、普罗米修斯和普罗米修斯适配器,您应将其用于自动校准 Triton 推理服务器。
您可以在 Kubernetes 中使用 MIG 的单一策略或混合策略中的任意一个。在本文中,我们建议采用混合策略,因为一个 A100 GPU 有七个 MIG 设备,而另一个 A100 MIG 被禁用。
使用花卉演示,它使用 ResNet50 对花卉图像进行分类。 NVIDIA Triton 推理服务器容器映像可以从NGC中提取。为 Flower 演示准备服务器的模型文件(*.plan, config.pbtxt)和客户端。有关更多信息,请参阅使用 NVIDIA 多实例 GPU 最小化深度学习推理延迟。
库伯内特斯花卉演示
设置 flower 演示后,您希望将其扩展到 Kubernetes 环境中的部署。这样可以根据推理请求自动调整 Triton 推理服务器的数量,并在所有服务器之间分配推理负载。因为 A100 上最多允许七个 MIG 设备,所以您最多可以有七个 Kubernetes 吊舱,每个吊舱都有一个 Triton 推理服务器在 MIG 设备上运行。以下是部署具有自动缩放和负载平衡的 Triton 推理服务器的主要步骤:
为 Triton 推理服务器创建 Kubernetes 部署。
创建 Kubernetes 服务以将 Triton 推理服务器公开为网络服务。
使用 kube Prometheus 和 PodMonitor 向 Prometheus 公开 NVIDIA Triton 度量。
创建 ConfigMap 以定义自定义度量。
部署 Prometheus 适配器并将自定义度量公开为注册的 Kubernetes API 服务。
创建 HPA (水平吊舱自动缩放)以使用自定义度量。
使用 NGINX Plus 负载平衡器在所有 Triton 推理服务器之间分配推理请求。
以下各节提供了实现这些目标的分步指南。
为 Triton 推理服务器创建 Kubernetes 部署
第一步是为 Triton 推理服务器创建库伯内特斯部署。部署为Pods和ReplicaSets提供了动态更新。Kubernetes中的复制集同时启动同一Pod的多个实例。
以下flower-replicas3.yml文件创建了三个复制的 POD ,由.spec.replicas字段指示,该字段可以是 1 到 7 之间的任意数字。.spec.selector字段定义部署如何查找要管理的 POD 。每个 Pod 运行一个名为 flower 的容器,该容器运行版本为 20 。 12-py3 的 Triton 推理服务器映像。与 NVIDIA Triton 端口号相同,集装箱端口 8000 、 8001 、 8002 分别保留用于 HTTP 、 gRPC 和 NVIDIA Triton 度量。
.resources.limits字段使用混合策略为每个 Pod 指定具有 5 GB 内存的 MIG 设备。符号nvidia.com/mig-1g.5gb特定于混合策略,必须根据 Kubernetes 集群进行相应调整。在本例中, NVIDIA Triton 的模型使用 NFS 协议存储在共享文件系统上。如果没有共享文件系统,则必须确保将模型加载到所有工作节点,以便 Kubernetes 启动的 POD 可以访问。
apiVersion: apps/v1
kind: Deployment
metadata:
name: flower
labels:
app: flower
spec:
replicas: 3
selector:
matchLabels:
app: flower
template:
metadata:
labels:
app: flower
spec:
volumes:
- name: models
nfs:
server:
path:
readOnly: false
containers:
- name: flower
ports:
- containerPort: 8000
name: http-triton
- containerPort: 8001
name: grpc-triton
- containerPort: 8002
name: metrics-triton
image: "nvcr.io/nvidia/tritonserver:20.12-py3"
volumeMounts:
- mountPath: /models
name: models
command: ["/bin/sh", "-c"]
args: ["cd /models /opt/tritonserver/bin/tritonserver --model-repository=/models --allow-gpu-metrics=false --strict-model-config=false"]
resources:
limits:
nvidia.com/mig-1g.5gb: 1
使用命令kubectl apply创建 Kubernetes 部署:
$ kubectl apply -f flower-replicas3.yml deployment.apps/flower created
确认创建了三个吊舱:
$ kubectl get pods NAME READY STATUS RESTARTS AGE flower-5cf8b78894-2qqz8 1/1 Running 0 5s flower-5cf8b78894-g679c 1/1 Running 0 5s flower-5cf8b78894-xswwj 1/1 Running 0 5s
因为在这一步中部署了 ReplicaSet ,所以可以使用命令kubectl scale手动向上或向下缩放 Pod 编号:
$ kubectl scale deployment flower --replicas=7 deployment.apps/flower scaled $ kubectl get pods NAME READY STATUS RESTARTS AGE flower-5cf8b78894-2qqz8 1/1 Running 0 69s flower-5cf8b78894-5znzt 1/1 Running 0 5s flower-5cf8b78894-g679c 1/1 Running 0 69s flower-5cf8b78894-gwgm6 1/1 Running 0 5s flower-5cf8b78894-shm2s 1/1 Running 0 5s flower-5cf8b78894-wrn9p 1/1 Running 0 5s flower-5cf8b78894-xswwj 1/1 Running 0 69s
为 Triton 推理服务器创建 Kubernetes 服务
第二步是创建一个库伯内特斯服务,将 Triton 推理服务器作为网络服务公开,以便客户端可以向服务器发送推理请求。创建服务时,选择自动创建外部负载平衡器的选项,如.type字段所示。这提供了一个外部可访问的 IP 地址,可将流量发送到节点上的正确端口。以下代码示例是flower-service.yml文件:
apiVersion: v1
kind: Service
metadata:
name: flower
labels:
app: flower
spec:
selector:
app: flower
ports:
- protocol: TCP
port: 8000
name: http
targetPort: 8000
- protocol: TCP
port: 8001
name: grpc
targetPort: 8001
- protocol: TCP
port: 8002
name: metrics
targetPort: 8002
type: LoadBalancer
类似地,使用以下命令创建 Kubernetes 服务:
$ kubectl apply -f flower-service.yml service/flower created
确认已创建服务:
$ kubectl get svc NAME TYPE CLUSTER-IP EXTERNAL-IP PORT(S) AGE flower LoadBalancer 10.233.24.1698000:31268/TCP,8001:32231/TCP,8002:30499/TCP 69s
创建服务的另一种方法是使用命令kubectl expose。可通过kubectl edit svc metrics命令编辑服务文件:
$ kubectl expose deployment flower --type=LoadBalancer --name=metrics service/metrics exposed
现在, Triton 推理服务器已准备好接收来自远程客户端的推理请求(图 1 )。如果客户端发送推断请求,客户端可以查看花卉图像的分类结果以及每个推断请求的吞吐量和端到端延迟。
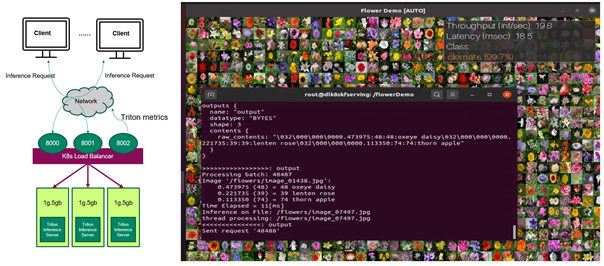
图 1 。(左)向 Kubernetes 中 MIG 设备上运行的 Triton 推理服务器发送推理请求的客户端 ( 右)获得分类结果和性能编号的客户。
到目前为止,您在 Kubernetes 环境中的 MIG 设备上运行多个 Triton 推理服务器,对客户端发送的花朵图像进行推理,您可以手动更改服务器数量。在接下来的部分中,您将对其进行改进,以便可以根据客户机请求自动调整服务器的数量。
使用普罗米修斯刮取 NVIDIA Triton 指标
要自动更改 Kubernetes 吊舱上运行的 Triton 推理服务器的数量,请首先收集可用于定义自定义度量的 NVIDIA Triton 度量。因为多个 Kubernetes 吊舱中有多组 NVIDIA Triton 度量,所以您应该部署一个PodMonitor,告诉Prometheus从所有吊舱中获取度量。
Prometheus 是一个开源的系统监控和警报工具包,提供由度量名称和键/值对标识的时间序列数据。PromQL,一种灵活的查询语言,用于从 Prometheus 查询度量。
为普罗米修斯创建 PodMonitor
PodMonitor定义了一组吊舱的监控,用于普罗米修斯发现目标。在flower-pod-monitor.yml文件中,您可以定义一个 PodMonitor 来监视服务器的 pod ,如.spec.selector字段所示。您还需要kube-prometheus,它包括普罗米修斯的部署,并将普罗米修斯链接到各种度量端点的目标配置刮取,如.spec.podMetricsEndpoints字段所示。普罗米修斯每 10 秒从这些端点刮取 NVIDIA Triton 度量,这些度量由.interval字段定义。
apiVersion: monitoring.coreos.com/v1
kind: PodMonitor
metadata:
name: kube-prometheus-stack-tritonmetrics
namespace: monitoring
labels:
release: kube-prometheus-stack
spec:
selector:
matchLabels:
app: flower
namespaceSelector:
matchNames:
- default
podMetricsEndpoints:
- port: metrics-triton
interval: 10s
path: /metrics
与普罗米修斯的 PodMonitor 标识相关的一个常见问题与不符合普罗米修斯自定义资源定义范围的错误标记有关。要匹配 NVIDIA Triton 部署的标签,请确保.spec.selector.matchLabels字段为app:flower,而.spec.namespaceSelector.matchNames字段为-default。两者都应与 NVIDIA Triton 部署位于同一命名空间下。这可以通过检查flower-replicas3.yml文件中的相关标签来确认。要匹配kube-prometheus的标签,还要确保.metadata.labels字段为release: kube-prometheus-stack。使用以下命令检查标签:
$ kubectl get Prometheus -n monitoring
NAME VERSION REPLICAS AGE
kube-prometheus-stack-prometheus v2.21.0 1 56d
$ kubectl describe Prometheus kube-prometheus-stack-prometheus -n monitoring
Name: kube-prometheus-stack-prometheus
Namespace: monitoring
Labels: app=kube-prometheus-stack-prometheus
chart=kube-prometheus-stack-10.0.2
heritage=Helm
release=kube-prometheus-stack
Annotations:
API Version: monitoring.coreos.com/v1
Kind: Prometheus
Metadata:
……
Pod Monitor Namespace Selector:
Pod Monitor Selector:
Match Labels:
Release: kube-prometheus-stack
使用命令kubectl apply -f flower-pod-monitor.yml部署 PodMonitor 并确认:
$ kubectl get PodMonitor -n monitoring
NAME AGE
kube-prometheus-stack-tritonmetrics 20s
自动缩放 Triton 推理服务器
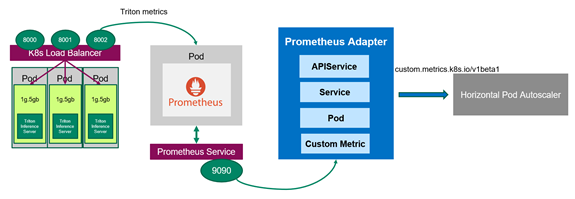
图 3 普罗米修斯适配器与库伯内特斯和普罗米修斯通信
既然普罗米修斯在监视服务器,那么应该部署普罗米修斯适配器,它知道如何与库伯内特斯和普罗米修斯通信(图 3 )。适配器帮助您使用普罗米修斯收集的指标来做出缩放决策。适配器定期从普罗米修斯收集可用度量的名称,然后只公开遵循特定形式的度量。这些度量由 API 服务公开, HPA 可以轻松使用。
可选:启用许可绑定
在 Kubernetes 集群中,基于角色的访问控制( RBAC )是调节对不同对象访问的常用方法。对于本例,必须允许在不同命名空间中运行的 HPA 访问 metrics API 提供的度量。 RBAC 的配置与 Kubernetes 集群的配置有很大不同。有关如何使用基于角色的访问控制的更多信息,请参阅使用 RBAC 授权。
在演示中,您可以通过发出以下命令创建一个具有许可绑定的ClusterRoleBinding对象,以允许 kubelet 用户访问所有 POD 。这将有效地禁用 Kubernetes 集群中的任何类型的安全性,并且不得用于生产环境。
$kubectl create clusterrolebinding permissive-binding --clusterrole=cluster-admin --user=admin --user=kubelet --group=system:serviceaccounts
创建 ConfigMap 以定义自定义度量
首先,告诉普罗米修斯适配器如何收集特定指标。您使用两个 NVIDIA Triton 度量来定义ConfigMap中的自定义度量avg_time_queue_us,其中HPA执行自动缩放。ConfigMap有一个键,该值看起来像配置格式的片段。在ConfigMap文件custom-metrics-server-config.yml中,使用以下值:
-
nv_inference_request_success[30]是过去 30 秒内成功的推理请求数。 -
nv_inference_queue_duration_us是以微秒为单位的累计推理排队持续时间。
自定义度量是指过去 30 秒内每个推断请求的平均队列时间, HPA 根据该时间决定是否更改副本号。
在配置 Prometheus 适配器时,重要的是这些指标要有一个命名端点,例如要寻址的 Pod 。以后无法从 metrics API 查询未寻址的度量。添加.overrides字段以强制要求pod和namespace稍后在 API 中公开。
apiVersion: v1
kind: ConfigMap
metadata:
name: adapter-config
namespace: monitoring
data:
triton-adapter-config.yml: |
rules:
- seriesQuery: 'nv_inference_queue_duration_us{namespace="default",pod!=""}'
resources:
overrides:
namespace:
resource: "namespace"
pod:
resource: "pod"
name:
matches: "nv_inference_queue_duration_us"
as: "avg_time_queue_us"
metricsQuery: 'avg(delta(nv_inference_queue_duration_us{<<.LabelMatchers>>}[30s])/
(1+delta(nv_inference_request_success{<<.LabelMatchers>>}[30s]))) by (<<.GroupBy>>)'
Create the ConfigMap and confirm it:
$ kubectl apply -f custom-metrics-server-config.yml
configmap/adapter-config created
$ kubectl get configmap -n monitoring
NAME DATA AGE
adapter-config 1 22s
为 Kubernetes metrics API 创建 Prometheus 适配器
要使 HPA 对该自定义指标作出反应,必须为 Prometheus 适配器创建 Kubernetes 部署、服务和APIService。下面的代码示例是部署文件custom-metrics-server-deployment.yml。它使用上一步中的ConfigMap,它告诉适配器收集自定义度量。它还创建了一个部署,生成适配器盒,从普罗米修斯那里获取自定义度量。.containers.config字段必须与.mountPath字段和上一步ConfigMap中创建的文件名triton-adapter-configl.yml匹配。
apiVersion: apps/v1
kind: Deployment
metadata:
name: triton-custom-metrics-apiserver
namespace: monitoring
labels:
app: triton-custom-metris-apiserver
spec:
replicas: 1
selector:
matchLabels:
app: triton-custom-metrics-apiserver
template:
metadata:
labels:
app: triton-custom-metrics-apiserver
spec:
containers:
- name: custom-metrics-server
image: quay.io/coreos/k8s-prometheus-adapter-amd64:v0.4.1
args:
- --cert-dir=/tmp
- --prometheus-url=
- --metrics-relist-interval=30s
- --v=10
- --config=/etc/config/triton-adapter-config.yml
- --secure-port=6443
ports:
- name: main-port
containerPort: 6443
volumeMounts:
- name: config-volume
mountPath: /etc/config
readOnly: false
volumes:
- name: config-volume
configMap:
name: adapter-config
为 Prometheus 适配器创建 Kubernetes 服务。在以下文件custom-metrics-server-service.yml中,.spec.selector。字段必须与部署中的标签app: triton-custom-metris-apiserver匹配,以指定提供服务的 Pod 。
apiVersion: v1
kind: Service
metadata:
name: triton-custom-metrics-api
namespace: monitoring
spec:
selector:
app: triton-custom-metrics-apiserver
ports:
- port: 443
targetPort: 6443
接下来,创建一个 APIService ,以便 Kubernetes 可以访问 Prometheus 适配器。然后,可以通过 HPA 获取自定义度量。以下代码块是 APIService 文件custom-metrics-server-apiservice.yml。.spec.service字段必须与服务文件的. metadata 字段匹配。要允许 autoscaler 访问自定义度量,您应该向API 聚合器注册度量。这里需要使用的 API 是custom.metrics.k8s.io/v1beta1。
apiVersion: apiregistration.k8s.io/v1beta1
kind: APIService
metadata:
name: v1beta1.custom.metrics.k8s.io
spec:
insecureSkipTLSVerify: true
group: custom.metrics.k8s.io
groupPriorityMinimum: 100
versionPriority: 5
service:
name: triton-custom-metrics-api
namespace: monitoring
version: v1beta1
在部署 Prometheus 适配器之前,您可以看到在 API 点没有可用的指标:
$ kubectl get --raw "/apis/custom.metrics.k8s.io/v1beta1" | jq Error from server (NotFound): the server could not find the requested resource
使用命令kubectl apply在前面提到的三个. yml 文件中应用配置。为 Prometheus 适配器创建 APIService 后,您可以看到自定义指标可用:
$ kubectl get --raw /apis/custom.metrics.k8s.io/v1beta1 | jq .
{
"kind": "APIResourceList",
"apiVersion": "v1",
"groupVersion": "custom.metrics.k8s.io/v1beta1",
"resources": [
{
"name": "namespaces/avg_time_queue_us",
"singularName": "",
"namespaced": false,
"kind": "MetricValueList",
"verbs": [
"get"
]
},
{
"name": "pods/avg_time_queue_us",
"singularName": "",
"namespaced": true,
"kind": "MetricValueList",
"verbs": [
"get"
]
}
]
}
$ kubectl get --raw /apis/custom.metrics.k8s.io/v1beta1 | jq .
{
"kind": "APIResourceList",
"apiVersion": "v1",
"groupVersion": "custom.metrics.k8s.io/v1beta1",
"resources": [
{
"name": "namespaces/avg_time_queue_us",
"singularName": "",
"namespaced": false,
"kind": "MetricValueList",
"verbs": [
"get"
]
},
{
"name": "pods/avg_time_queue_us",
"singularName": "",
"namespaced": true,
"kind": "MetricValueList",
"verbs": [
"get"
]
}
]
}
您还可以检查此自定义度量的当前值,即 0 ,因为当前没有来自客户端的推断请求。在这里,您将从default命名空间中选择所有 POD , flower 演示部署在该命名空间中:
$ kubectl get --raw /apis/custom.metrics.k8s.io/v1beta1/namespaces/default/pods/*/avg_time_queue_us | jq .
{
"kind": "MetricValueList",
"apiVersion": "custom.metrics.k8s.io/v1beta1",
"metadata": {
"selfLink": "/apis/custom.metrics.k8s.io/v1beta1/namespaces/default/pods/%2A/avg_time_queue_us"
},
"items": [
{
"describedObject": {
"kind": "Pod",
"namespace": "default",
"name": "flower-5cf8b78894-jng2g",
"apiVersion": "/v1"
},
"metricName": "avg_time_queue_us",
"timestamp": "2021-03-25T15:49:10Z",
"value": "0"
}
]
}
部署 HPA
HPA 根据观察到的指标自动缩放复制控制器、部署、复制集或有状态集中的 POD 数量。现在,您可以创建使用自定义度量的 HPA 。 HPA 根据以下等式控制部署在 Kubernetes 中的副本数量。它根据所需度量值和当前度量值之间的比率进行操作,并返回所需副本的数量:

在该公式中,使用以下公式:



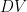
When
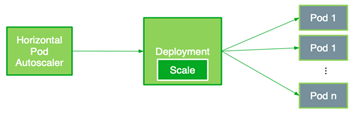
图 4 。 HPA 比例 NVIDIA Triton 部署
以下 HPA 文件flower-hpa.yml自动缩放 Triton 推理服务器的部署。它使用由.sepc.metrics字段指示的 Pods 度量,该字段获取自动缩放目标控制的所有 Pods 中给定度量的平均值。.spec.metrics.targetAverageValue字段是通过考虑来自所有 POD 的自定义度量的值范围来指定的。该字段触发 HPA 定期调整副本的数量,以使观察到的自定义度量与目标值相匹配。
apiVersion: autoscaling/v2beta1
kind: HorizontalPodAutoscaler
metadata:
name: flower-hpa
spec:
scaleTargetRef:
apiVersion: apps/v1beta1
kind: Deployment
name: flower
minReplicas: 1
maxReplicas: 7
metrics:
- type: Pods
pods:
metricName: avg_time_queue_ms
targetAverageValue: 50
使用命令kubectl apply -f flower-hpa.yml创建 HPA 并确认:
$ kubectl get hpa NAME REFERENCE TARGETS MINPODS MAXPODS REPLICAS AGE flower-hpa Deployment/flower 0/50 1 7 1 22s
如果客户端开始向服务器发送推断请求,新的 HPA 可以获取部署的自定义指标并确定所需的 POD 数量。例如,当推理请求增加时, HPA 会将 POD 的数量从 1 增加到 2 ,然后逐渐增加到 7 ,这是 A100 GPU 上的最大 POD 数量。最后,当客户端停止发送推断请求时, HPA 将副本数减少到仅 1 (图 5 )。
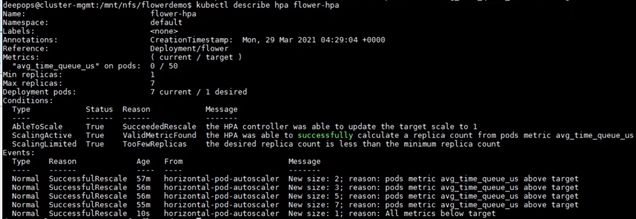
图 5 使用命令 kubectl 描述 hpa 花 hpa 检查 HPA 如何增加或减少 Pod 数量 s 。
使用 NGINX Plus 实现负载平衡
负载平衡用于将来自客户端的负载以最佳方式分布在可用服务器上。在前面,您选择了 Kubernetes 内置负载平衡器,这是一个第 4 层(传输层)负载平衡器,它很容易部署,但是使用gRPC的limitation可以实现。
在这个演示中,使用 Prometheus ,您会发现 autoscaler 新添加的 POD 无法使用 Kubernetes 内置的负载平衡器获得工作负载。要改进这一点,请使用NGINX Plus,它是第 7 层(应用程序层)负载平衡器。工作负载均匀地分布在所有 POD 中,包括新扩展的 POD 。
首先,您应该创建 NGINX Plus 映像,因为 Docker Hub 无法提供 NGINX Plus 的商业产品。在 Docker 容器中创建 NGINX 实例使用 Docker Hub 的 NGINX 开源映像。然后,将本地映像推送到私有 Docker 注册表。
接下来,要部署 NGINX Plus ,请使用以下命令使用role=nginxplus 标记要在其上部署 NGINX Plus 的节点:
$ kubectl label node
修改服务,将clusterIP设置为none,,以便所有副本端点都由 NGINX Plus 公开和标识。为避免混淆,请创建一个新的服务文件flower-service-nginx.yml,并应用它:
apiVersion: v1
kind: Service
metadata:
name: flower-nginx
labels:
app: flower
Spec:
clusterIP: None
selector:
app: flower
ports:
- protocol: TCP
port: 8000
name: http
targetPort: 8000
- protocol: TCP
port: 8001
name: grpc
targetPort: 8001
接下来,为 NGINX 创建一个配置文件。下面的代码示例假定您正在使用位置/path/to/nginx/config/nginx.conf。
resolvervalid=5s; upstream backend { zone upstream-backend 64k; server resolve; } upstream backendgrpc { zone upstream-backend 64k; server resolve; } server { listen 80; status_zone backend-servers; location / { proxy_pass http://backend; health_check uri=/v2/health/ready; } } server { listen 89 http2; location / { grpc_pass grpc://backendgrpc; } } server { listen 8080; root /usr/share/nginx/html; location = /dashboard.html { } location = / { return 302 /dashboard.html; } location /api { api write=on; } }
最后,您应该在下面的nginxplus-rc.yml文件中为 NGINX Plus 创建一个ReplicationController。要从私有注册表中提取映像, Kubernetes 需要credentials。配置文件中的imagePullSecrets字段指定 Kubernetes 应从名为regcred的机密中获取凭据。在此配置文件中,还必须将上一步创建的 NGINX 配置文件装载到位置/etc/nginx/conf.d。
apiVersion: v1
kind: ReplicationController
metadata:
name: nginxplus-rc
spec:
replicas: 1
selector:
app: nginxplus
template:
metadata:
labels:
app: nginxplus
spec:
nodeSelector:
role: nginxplus
imagePullSecrets:
- name: regcred
containers:
- name: nginxplus
command: [ "/bin/bash", "-c", "--" ]
args: [ "nginx; while true; do sleep 30; done;" ]
imagePullPolicy: IfNotPresent
image: nvcr.io/nvidian/swdl/nginxplus:v1
ports:
- name: http
containerPort: 80
hostPort: 8085
- name: grpc
containerPort: 89
hostPort: 8087
- name: http-alt
containerPort: 8080
hostPort: 8086
- name: flower-svc
containerPort: 8000
hostPort: 32309
volumeMounts:
- mountPath: "/etc/nginx/conf.d"
name: etc-nginx-confd
volumes:
- nfs:
server:
path:
readOnly: false
name: etc-nginx-confd
使用以下命令创建 ReplicationController :
kubectl create -f nginxplus-rc.yml
验证部署。您应该发现 NGINX Plus 正在运行:
$kubectl get pods NAME READY STATUS RESTARTS AGE flower-5cf8b78894-jng2g 1/1 Running 0 8h nginxplus-rc-nvj7b 1/1 Running 0 10s
现
apiVersion: autoscaling/v2beta1
kind: HorizontalPodAutoscaler
metadata:
name: flower-hpa
spec:
scaleTargetRef:
apiVersion: apps/v1beta1
kind: Deployment
name: flower
minReplicas: 1
maxReplicas: 7
metrics:
- type: Pods
pods:
metricName: avg_time_queue_ms
targetAverageValue: 50
使用命令kubectl apply -f flower-hpa.yml创建 HPA 并确认:
$ kubectl get hpa NAME REFERENCE TARGETS MINPODS MAXPODS REPLICAS AGE flower-hpa Deployment/flower 0/50 1 7 1 22s
现在,当客户端向服务器发送推断请求时,您可以看到 NGINX Plus 仪表板(图 6 ):
autoscaler 将豆荚的数量从 1 逐渐增加到 7 。
工作负载在所有 POD 中均匀分布,如流量所示。
您还可以通过检查普罗米修斯中所有 POD 的度量值或自定义度量值来确认新添加的 POD 正在工作。
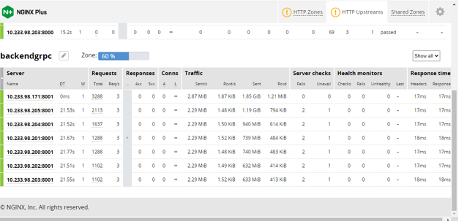
图 6 NGINX Plus仪表板显示了按 HPA 缩放的 NVIDIA Triton 服务器数量和每台服务器的信息。
Conclusion
这篇文章展示了在 Kubernetes 环境中使用 MIG 大规模部署 Triton 推理服务器的分步说明和代码。我们还向您展示了如何使用两种不同类型的负载平衡器自动调整服务器数量和平衡工作负载。
关于作者
Maggie Zhang 是 NVIDIA 的深度学习工程师,致力于深度学习框架和应用程序。她在澳大利亚新南威尔士大学获得计算机科学和工程博士学位,在那里她从事 GPU / CPU 异构计算和编译器优化。
Dai Yang 是 NVIDIA 的高级解决方案架构师。他负责使用 GPU 和网络产品定制客户优化的解决方案,重点关注工业、汽车和 HPC 客户。 Dai 积极参与 EMEA 地区 DGX 解决方案的规划、部署和培训。在加入 NVIDIA 之前,戴是慕尼黑工业大学的研究助理,在那里他研究了高性能计算的各个方面,并为 MPI 标准扩展了 MPI 论坛的草案。戴是在 ISC2020 汉斯梅尔奖获奖团队的一部分。
Davide Onofrio 是 NVIDIA 的高级深度学习软件技术营销工程师。他在 NVIDIA 专注于深度学习技术开发人员关注内容的开发和演示。戴维德在生物特征识别、虚拟现实和汽车行业担任计算机视觉和机器学习工程师已有多年经验。他的教育背景包括米兰理工学院的信号处理博士学位。
审核编辑:郭婷
-
阿里云宣布推出Serverless Kubernetes服务 30秒即可完成应用部署2018-05-03 3355
-
NVIDIA Triton 推理服务器助力西门子提升工业效率2021-11-16 4473
-
NVIDIA Triton推理服务器帮助Teams使用认知服务优化语音识别模型2022-01-04 2501
-
NVIDIA Triton推理服务器简化人工智能推理2022-04-08 3330
-
使用NVIDIA Triton推理服务器简化边缘AI模型部署2022-04-18 3796
-
利用NVIDIA Triton推理服务器加速语音识别的速度2022-05-13 3143
-
基于NVIDIA Triton的AI模型高效部署实践2022-06-28 3243
-
腾讯云TI平台利用NVIDIA Triton推理服务器构造不同AI应用场景需求2022-09-05 3555
-
使用NVIDIA Triton解决人工智能推断挑战2022-10-11 2221
-
NVIDIA Triton推理服务器的功能与架构简介2022-11-02 4068
-
NVIDIA Triton 系列文章(4):创建模型仓2022-11-15 2361
-
NVIDIA Triton 系列文章(6):安装用户端软件2022-11-29 3569
-
如何使用NVIDIA Triton 推理服务器来运行推理管道2023-07-05 2331
-
使用NVIDIA Triton推理服务器来加速AI预测2024-02-29 1942
-
香港服务器支持Docker和Kubernetes吗?2025-10-21 1087
全部0条评论

快来发表一下你的评论吧 !
