

研究自动驾驶技术的算法需要哪些知识?
描述
编者荐语后台有同学询问自动驾驶的技术栈,这里总结知乎的提问与自己的一些认识,对自动驾驶进行一定的介绍。自动驾驶系统包括环境感知和定位,行为预测和规划控制。作为计算机视觉方面的研究人员,这里就只说说环境感知方面需要的知识吧。
1 前言
感知任务大多涉及算法设计,因此文章的介绍也以算法为主线,特别是深度学习的算法。此外也会涉及一些数据采集,系统测试,算法部署以及量产感知系统的分析。
自动驾驶中的环境感知包含了自动驾驶和环境感知两个概念。首先,什么是自动驾驶呢?下面是维基百科上对自动驾驶汽车的定义。
自动驾驶汽车,又称无人驾驶车、电脑驾驶车、无人车、自驾车,为一种需要驾驶员辅助或者完全不需操控的车辆。作为自动化载具,自动驾驶汽车可以不需要人类操作即能感测其环境及导航。
上述定义里有几个关键词。首先是汽车,我们这里所说的自动驾驶技术涉及的是汽车,而不是飞机火车之类的交通工具。其次是感知环境和导航,也就是说自动驾驶汽车可以自主的采集和理解周边环境信息,并根据设定的目的地进行决策和行进。最后是需要驾驶员辅助或者完全不需操控,这里涉及到自动驾驶系统的分级,是一个非常重要的概念,下面稍微展开说一下。
自动驾驶技术不是从0到1的质变,而是一个渐变迭代的过程。关于自动驾驶系统的分级,目前最常用的标准是由SAE(美国汽车工程师学会)制定的。不同机构制定的标准会略有不同,但是基本的概念是一致的。下表对L0(人工驾驶)到L5(完全自动驾驶)六个级别进行了总结。这些定义可能有些难懂,但是与车辆上不同的功能结合起来就容易理解了。比如说,汽车中现在标配的防抱死制动系统(ABS)和车身电子稳定系统(ESP)就都属于L1级别。此外,定速巡航、自适应巡航(ACC)以及车道保持辅助 (LKA)也属于L1级别的范畴,因为它们只能在一个方向上(横向或纵向)操控车辆。如果同时实现了 ACC和LKA,那么这辆车就来到了L2级别。对于L2及其以下级别的系统来说,车辆的驾驶员都需要监控周围环境并随时做好接管的准备。这一点非常关键,这也是很多L2级别的车辆出现交通事故的主要原因,也就是驾驶员对系统期望过高,在驾驶过程中没有时刻保持对周边环境的关注。如果一个车辆配备了某种Pilot系统,比如Traffic Jam Pilot,那么就达到了L3级别。这就意味着,在某些特定的场景下(比如高速公路,堵车等),驾驶员不需要时刻监控当前路况,可以松手,松脚,松眼,只需要在系统提示时接管车辆即可。在这种限定的情况下,驾驶员已经成为了乘客。对于L4级别的系统,目前只存在于演示车辆中。我们平时看到的诸如“某厂家的车辆在某道路上实现了XX小时无人工接管的自动行驶”,这都属于L4级别的范畴,与L3最大的区别是不需要人工接管了,在限定场景下可以实现车辆的完全自主行驶。L5级别就是把“限定场景”这个条件也去掉了。这个级别的车辆最大的特点就是没有方向盘了,所有人都是乘客,车辆的所有操控权都属于系统。

了解了自动驾驶是什么以后,我们再来看看自动驾驶系统是怎么实现的。一般来说,自动驾驶系统包含感知,决策和控制这三个主要模块。粗略来说,这三个模块对应生物系统的眼睛,大脑和四肢。感知系统(眼睛)负责了解周围障碍物和道路的信息,决策系统(大脑)根据周围的环境以及设定的目标决定下一步需要执行的动作,而控制系统(四肢)则负责执行这些动作,比如转向,加速,刹车等。进一步来说,感知系统里又包括了环境感知和车辆定位两个任务。环境感知负责检测各种移动和静止的障碍物(比如车辆,行人,建筑物等),以及收集道路上的各种信息(比如可行驶区域,车道线,交通标志,红绿灯等),这里需要用到的主要是各种传感器(比如摄像头,激光雷达,毫米波雷达等)。车辆定位则根据环境感知得到的信息来确定车辆在环境中所处位置,这里需要高精度地图,以及惯性导航(IMU)和全球定位系统(GPS)的辅助。
本专栏主要关注环境感知系统,重点会介绍摄像头,激光雷达和毫米波雷达这三种主要的传感器,以及它们的融合。不同的传感器有着不同的特性,各自都有优缺点,因此也适用于不同的任务。摄像头是感知系统中最常用的传感器,优势在于能够提取丰富的纹理和颜色信息,因此适用于目标的分类。但是其缺点在于对于距离的感知能力较弱,并且受光照条件影响较大。激光雷达在一定程度上弥补了摄像头的缺点,可以精确的感知物体的距离和形状,因此适用于中近距的目标检测和测距。但是其缺点在于成本较高,量产难度大,感知距离有限,而且同样受天气影响较大。毫米波雷达具有全天候工作的特点,可以比较精确的测量目标的速度和距离,感知距离较远,价格也相对较低,因此适用于低成本的感知系统或者辅助其它的传感器。但是缺点在于高度和横向的分辨率较低,对于静止物体的感知能力有限。
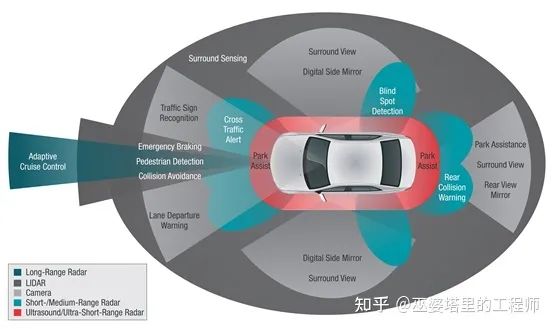
环境感知系统中的多种传感器
2 技术概览
上一节中提到了,环境感知系统的硬件基础是多种传感器以及它们的组合,而软件方面的核心则是感知算法。总的来说,感知算法要完成两个主要的任务:物体检测和语义分割。前者得到的是场景中重要目标的信息,包括位置,大小,速度等,是一种稀疏的表示;而后者得到的是场景中每一个位置的语义信息,比如可行驶,障碍物等,是一种稠密的表示。这两个任务的结合被称为全景分割,这也是自动驾驶和机器人领域最近兴起的一个概念。对于物体目标(比如车辆,行人),全景分割输出其分割Mask,类别和实例ID;对于非物体目标(比如道路,建筑物),则只输出其分割Mask和类别。环境感知系统的终极目标就是要得到车辆周边三维空间中全景分割结果。当然对于不同级别,不同场景下的自动驾驶应用来说,需要的感知输出不也尽相同。
自动驾驶驾驶技术这一轮的爆发很大程度上来源于深度学习在计算机视觉领域取得的突破,而这个突破首先是从图像分类和图像中的物体检测开始的。在自动驾驶环境感知中,深度学习最先取得应用的任务是单张二维图像中的物体检测。这个领域中的经典算法,比如Faster R-CNN,YOLO,CenterNet等都是不同时期视觉感知算法的主流。但是,车辆不能仅仅依靠一张二维图像上的检测结果来行驶。因此,为了满足自动驾驶应用的需求,这些基础的算法还需要进行进一步的扩展,其中最重要的就是融合时序信息和三维信息。前者衍生出了物体跟踪算法,后者衍生出了单目/双目/多目的三维物体检测算法。以此类推,语义分割包含了图像语义分割,视频语义分割,稠密深度估计。
为了得到更加精确的三维信息,激光雷达也一直是自动驾驶感知系统的重要组成部分,尤其是对于L3/4级别的应用。激光雷达的数据是相对稀疏的点云,这与图像稠密的网格结构差别非常大,因此图像领域常用的算法需要经过一定的改动才能应用到点云数据。点云感知的任务也可以按照物体检测和语义分割来划分,前者输出三维的物体边框,而后者输出点云中每个点的语义类别。为了利用图像领域的算法,点云可以转换为鸟瞰视图(Bird‘s Eye View)或者前视图(Range View)下的稠密网格结构。此外,也可以改进深度学习中的卷积神经网络(Convolutional Neural Network, CNN),使其适用于稀疏的点云结构,比如PointNet或者Graph Neural Network。
毫米波雷达由于其全天候工作,测速准确,以及低成本的特点,也被广泛的用于自动驾驶感知系统中,不过一般应用在L2级别的系统中,或者在L3/4级系统中作为其它传感器的辅助。毫米波雷达的数据一般来说也是点云,但是比激光雷达的点云更为稀疏,空间分辨率也更低。相比于摄像头和激光雷达,毫米波雷达的数据密度非常低,因此一些传统方法(比如聚类和卡尔曼滤波)表现的并不比深度学习差很多,而这些传统方法的计算量相对较低。最近几年来,开始有研究者从更底层的数据出发,用深度学习代替经典的雷达信号处理,通过端对端的学习取得了近似激光雷达的感知效果。
单个传感器的感知能力总是有限的,如果把系统成本先放在一边,多传感器融合的方案自然更好的选择。一般来说,摄像头是感知系统的必备的传感器,为了得到深度信息和360度的视场,可以采用双目或者多目融合的方案。为了更准确的获得三维和运动信息,摄像头也可以与激光雷达和毫米波雷达进行融合。这些传感器的坐标系不同,数据形式不同,甚至采集频率也不同,因此融合算法的设计并不是一件简单的任务。粗略来说,融合可以在决策层(融合不同传感器的输出)或者数据层(融合不同传感器的数据或者中间结果)来进行。数据层融合理论上说是更好的方法,但是对传感器之间的空间和时间对齐要求会更高。
以上大致介绍了环境感知中所涉及的算法部分,算法部分的其它一些内容,比如多目相机的融合,多传感器的空间和时间对齐,后续也会进行介绍。
除了核心算法设计以外,感知系统中其它重要的部分还包括数据的采集和标注,算法的测试和迭代,以及系统的部署等,这些内容之后专栏中也会推出系列文章进行分析。
3 行业现状
了解了感知系统中所包含的技术之后,下一步我们来看看这些传感器在目前的量产或者演示车辆中的应用现状。
粗略来说,自动驾驶公司可以分为两大类别。一类是传统的车企(比如国外的大众,宝马,通用,丰田等,国内的长城,吉利等),新能源车企(比如特斯拉,蔚来,小鹏等)和Tier1(比如国外老牌的博世,大陆,安波福)等,以及国内新兴的华为,大疆等)。这类公司的首要目标是量产,一般以L2级别方案为主,目前也在向L3级别扩展。另外一类是一些方案提供商或者初创公司(比如Waymo,Mobileye,Pony.AI,Momenta,TuSimple等)。这些公司致力于发展L4级别的自动驾驶技术,面向的是诸如Robotaxi,Robotruck和Robobus之类的应用。
对于不同的自动驾驶级别,不同的应用场景,传感器的配置方案也不尽相同。对于L2级别的应用,比如紧急制动和自适应巡航,可以只采用前视单目摄像头或者前向毫米波雷达。如果需要变道辅助功能,则需要增加传感器对相邻车道进行感知。常用的方案是在车头和车尾增加多个角雷达,以实现360度的目标检测能力。对于L3级别的应用,需要在特定场景下实现车辆的完全自主驾驶,因此需要扩展车辆对周边环境的感知能力。这时就需要增加激光雷达,侧视和后视的摄像头和毫米波雷达,以及GPS,IMU和高精度地图来辅助车辆定位。到了L4级别以后,由于在特定场景下不需要人工接管了,传感器就不仅需要高精确度,还需要高可靠性。这就需要增加传感器的冗余性,也就是说需要备用系统。
下面我们来看几个具体的案例。
首先是特斯拉近期推出的纯视觉方案。虽然一提起自动驾驶,很多人脑子里最先想到的就是特斯拉,但是特斯拉其实也只是L2级别(或者说高级L2)的自动驾驶系统,因为还是需要驾驶员随时准备好接管车辆。如果你只在L2级别的系统里横向对比,那么特斯拉的方案还是很有竞争力的。这个系统只采用了视觉传感器,包括了安装在车身不同位置,多种焦距和视野范围的摄像头。这些摄像头可以覆盖360度的视野,并且有一定的冗余性。特斯拉在AI Day上展示的基于深度学习的的多摄像头融合算法,个人觉得还是非常值得研究一下的,后续也会推出文章进行详细分析。
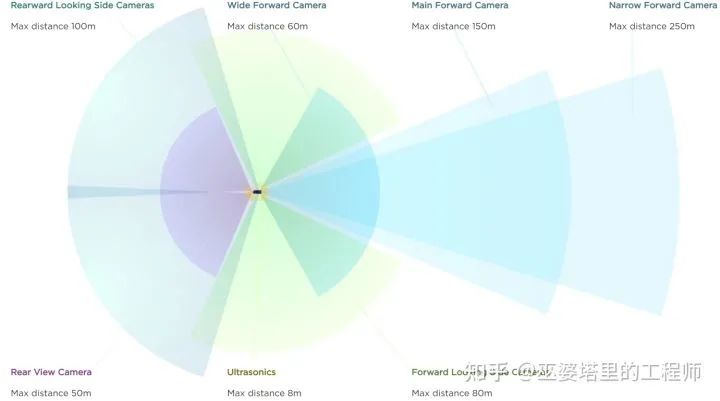
特斯拉的纯视觉传感器配置(L2级别)
2017年夏天,奥迪发布了第四代A8,其中最大的亮点就是搭载了Traffic Jam Pilot(TJP)系统。前文提到了,TJP系统已经属于L3的范畴,因此奥迪A8可以说是全球首个“量产”的L3级系统。为什么加上引号呢,这是因为该功能在交付的车辆中一直没有开启,用户只能在奥迪自己的演示车中体验。奥迪官方的解释是法规方面的问题,但其实最核心的原因还是技术方面的,也就是L3中的所谓的“接管悖论”问题。在60公里时速以下的结构化道路堵车场景中,TJP系统允许驾驶员低头玩手机或者睡觉。这时如果出现突发状况,可能就会出现接管不及的情况。虽然奥迪在2019年底取消了L3级自动驾驶项目,但是这个探索也为后续的L4和各种高级L2系统的研发提供了宝贵的经验。更多的细节这里就不展开说了,我们下面来看看这套系统中传感器方案。奥迪A8全车共有12个超声波传感器、4个全景摄像头、1个前置摄像头、4个中程雷达、1个远程雷达、1个红外摄像机。此外,奥迪A8首次搭载了一个4线的车规级激光雷达,并且配备中央驾驶辅助系统控制单元(zFAS),这些都是L3级自动驾驶系统的必备选项。
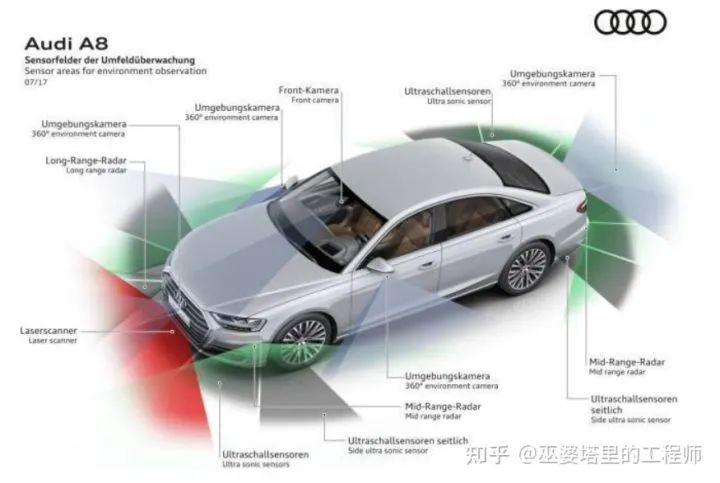
奥迪A8的传感器配置(L3级别)
从L2到L3,再到L4,传感器方面最大的变化就是增加了激光雷达,而且数量逐渐增加。比如,在Waymo的传感器方案中,除了前向的激光雷达外,还增加了后向和车顶的360度激光雷达。而且激光雷达的线束数量显著提高,可以达到300米左右的感知范围。除了Waymo,其它各家公司的L4系统都不可避免的包含了一个或者多个激光雷达。从目前的技术发展趋势来看,实现L4级别的自动驾驶主要还是靠增加传感器,从而大幅提升对驾驶路况和环境的感知能力,而这其中最重要的就是激光雷达。到了L4级别,车辆在限定场景下完全自主行驶,这时99%的准确度就不够了,而需要的是99.99999%的准确度,而激光雷达就是小数点后几位的保障。这种保障来自激光雷达与其它各种传感器之间的配合,而不仅仅是简单的堆叠,因此高效精确的传感器融合在L4级别的系统中起到至关重要的作用。
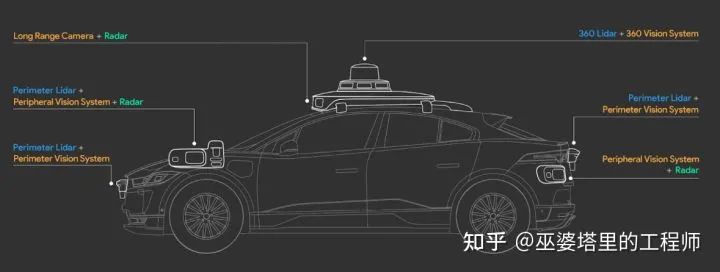
Waymo的传感器配置(L4级别)
以上只是简单的介绍了L2/3/4级别中传感器配置的一些典型案例,专栏会在后续的文章中详细分析不同公司的自动驾驶技术路线,以及相应的传感器配置和感知系统设计。
审核编辑 :李倩
-
FPGA在自动驾驶领域有哪些应用?2024-07-29 8404
-
自动驾驶技术的实现2021-09-03 3268
-
自动驾驶系统设计及应用的相关资料分享2021-08-30 2488
-
联网安全接受度成自动驾驶的关键2020-08-26 3375
-
为何自动驾驶需要5G?2020-06-08 4320
-
如何让自动驾驶更加安全?2019-05-13 3788
-
自动驾驶汽车的定位技术2019-05-09 3555
-
即插即用的自动驾驶LiDAR感知算法盒子 RS-Box2017-12-15 6159
-
自动驾驶的到来2017-06-08 7479
-
细说关于自动驾驶那些事儿2017-05-15 7237
-
自动驾驶真的会来吗?2016-07-21 14605
-
【话题】特斯拉首起自动驾驶致命车祸,自动驾驶的冬天来了?2016-07-05 14383
-
汽车自动驾驶技术2016-04-14 5612
-
谷歌的自动驾驶汽车是酱紫实现的吗?2011-06-14 4834
全部0条评论

快来发表一下你的评论吧 !
