

如何使用COCO数据集训练和优化二维姿态估计模型
描述
存在开发姿态估计的开源方法,但在推理性能方面不是最优的,并且集成到生产应用程序中非常耗时。通过这篇文章,我们将向您展示如何开发和部署姿势估计模型,这些模型易于跨设备配置文件使用,性能非常好,并且非常精确。
姿势估计已与 NVIDIA 转移学习工具包( TLT ) 3.0 集成,因此您可以利用 TLT 的所有功能(如模型修剪和量化)来创建精确和高性能的模型。经过训练后,您可以部署此模型进行推理以获得实时性能。
本系列文章将引导您完成培训、优化、部署实时高性能姿势估计模型的步骤。在第 1 部分中,您将学习如何使用开放源代码 COCO 数据集训练二维姿势估计模型。在 第 2 部分 中,您将学习如何为推理吞吐量优化模型,然后使用 TLT-CV 推理管道部署模型。我们将 TLT 训练模型与其他最先进的模型进行了比较。
用 TLT 训练二维姿态估计模型
在本节中,我们将介绍有关使用 TLT 训练 2D 姿势估计模型的以下主题:
Methodology
环境设置
数据准备
实验配置文件
Training
Evaluation
模型验证
Methodology
BodyPoseNet 模型的目标是预测给定输入图像中每个人的骨架,骨架由关键点和关键点之间的连接组成。
两种常用的姿态估计方法是自顶向下和自下而上。自顶向下的方法通常使用对象检测网络来定位帧中所有人的边界框,然后使用姿势网络来定位该边界框内的身体部位。顾名思义,自下而上的方法从下到上构建骨架。它首先检测一个框架内的所有人体部位,然后使用一种方法对属于特定人的部位进行分组。
采用自下而上的方法有几个原因。一是推理性能较高。与自顶向下的姿势估计方法不同,自下而上的方法不需要单独的人检测器。计算不会随场景中的人数线性缩放。这使您能够实现拥挤场景的实时性能。此外,自底向上还具有全局上下文的优点,因为将整个图像作为输入提供给网络。它可以更好地处理复杂的姿势和拥挤。
鉴于这些原因,这种方法的目的是实现有效的单杆,自下而上的姿态估计,同时也提供竞争力的准确性。本文使用的默认模型是完全卷积模型,由主干网、初始预测阶段组成,该阶段对置信图( heatmap )和部分亲和场( PAF )进行像素级预测,然后对初始预测进行多级细化( 0 到 N 阶段)。此解决方案简化并抽象了自底向上方法的许多复杂性,同时允许针对特定应用程序调整必要的旋钮。
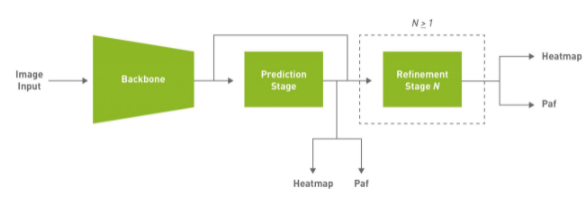
图 1 。默认模型架构的简化框图。
PAFs 是一种用自下而上的方法表示关联分数的方法。有关详细信息,请参阅 基于部分相似域的实时多人二维姿态估计 。它由一组二维向量场组成,对肢体的位置和方向进行编码。这与热图相关联,用于在后处理期间通过执行二部匹配和关联身体部位候选来构建骨架。
环境设置
NVIDIA TLT 工具包有助于抽象出 AI / DL 框架的复杂性,并使您能够更快地构建生产质量模型,而无需编码。有关硬件和软件要求、设置所需依赖项以及安装 TLT 启动器的更多信息,请参阅 TLT 快速入门指南 。
使用以下命令下载最新示例:
ngc registry resource download-version "nvidia/tlt_cv_samples:v1.1.0"
您可以在 tlt_cv_samples:v1.1.0/bpnet 找到示例笔记本,其中还包含所有详细步骤。
为 cleaner 命令行命令设置 env 变量。更新以下变量值:
export KEY=export NUM_GPUS=1 # Local paths # The dataset is expected to be present in $LOCAL_PROJECT_DIR/bpnet/data. export LOCAL_PROJECT_DIR=/home/ /tlt-experiments export SAMPLES_DIR=/home/ /tlt_cv_samples_vv1.1.0 # Container paths export USER_EXPERIMENT_DIR=/workspace/tlt-experiments/bpnet export DATA_DIR=/workspace/tlt-experiments/bpnet/data export SPECS_DIR=/workspace/examples/bpnet/specs export DATA_POSE_SPECS_DIR=/workspace/examples/bpnet/data_pose_config export MODEL_POSE_SPECS_DIR=/workspace/examples/bpnet/model_pose_config
要运行 TLT 启动程序,请使用 ~/.tlt_mounts.json 文件将本地计算机上的~/ TLT-experiments 目录映射到 Docker 容器。有关详细信息,请参阅 TLT 发射器 。
创建 ~/.tlt_mounts.json 文件并更新其中的以下内容:
{
"Mounts": [
{
"source": "/home//tlt-experiments",
"destination": "/workspace/tlt-experiments"
},
{
"source": "/home//tlt_cv_samples_vv1.1.0/bpnet/specs",
"destination": "/workspace/examples/bpnet/specs"
},
{
"source": "/home//tlt_cv_samples_vv1.1.0/bpnet/data_pose_config",
"destination": "/workspace/examples/bpnet/data_pose_config"
},
{
"source": "/home//tlt_cv_samples_vv1.1.0/bpnet/model_pose_config",
"destination": "/workspace/examples/bpnet/model_pose_config"
}
]
}
确保要装载的源目录路径有效。这会将主机上的路径 /home/ 装载为容器内的路径 /workspace/tlt-experiments 。它还将下载的规范装载到主机上,使其成为容器内的路径 /workspace/examples/bpnet/specs 、 /workspace/examples/bpnet/data_pose_config 和 /workspace/examples/bpnet/model_pose_config 。
通过运行以下命令,确保已安装所需的依赖项:
# Install requirements pip3 install -r $SAMPLES_DIR/deps/requirements-pip.txt
下载预训练模型
首先,设置一个 NGC 帐户,然后下载预训练模型。目前,只支持 vgg19 主干网。
# Create the target destination to download the model. mkdir -p $LOCAL_EXPERIMENT_DIR/pretrained_vgg19/ # Download the pretrained model from NGC ngc registry model download-version nvidia/tlt_bodyposenet:vgg19 \ --dest $LOCAL_EXPERIMENT_DIR/pretrained_vgg19
数据准备
我们以本文中的 COCO ( context 上的公共对象) 2017 数据集为例。下载数据集并按照说明提取:
将 images 目录解压到 $LOCAL_DATA_DIR 目录中,并将注释解压到 $LOCAL_DATA_DIR/annotations 中。
要准备用于训练的数据,必须生成分段掩码,用于掩盖未标记人员和 TFR 记录的丢失,以提供给训练管道。掩码文件夹基于 coco_spec.json 文件中提供的路径[ mask_root_dir_path 目录是 root_directory_path 的相对路径, mask_root_dir_path 和 annotation_root_dir_path 也是如此。
# Generate TFRecords for training dataset tlt bpnet dataset_convert \ -m 'train' \ -o $DATA_DIR/train \ --generate_masks \ --dataset_spec $DATA_POSE_SPECS_DIR/coco_spec.json # Generate TFRecords for validation dataset tlt bpnet dataset_convert \ -m 'test' \ -o $DATA_DIR/val \ --generate_masks \ --dataset_spec $DATA_POSE_SPECS_DIR/coco_spec.json
要将此示例用于自定义数据集,请执行以下操作:
- 以类似于 COCO 数据集的格式准备数据和注释。
- 在 data \ u pose \ u config 下创建一个数据集规范,类似于 coco \ u spec . json ,其中包括数据集路径、姿势配置、遮挡标记约定等。
- 将注释转换为 COCO 注释格式。
有关更多信息,请参阅以下文档:
列车试验配置文件
下一步是为培训配置 spec 文件。实验规范文件是必不可少的,因为它编译了实现良好模型所需的所有超参数。 BodyPoseNet 训练的规范文件配置训练管道的以下组件:
- Trainer
- Dataloader
- Augmentation
- 标签处理机
- Model
- Optimizer
您可以在 $SPECS_DIR/bpnet_train_m1_coco.yaml 中找到默认规范文件。我们在规范文件的每个组件上展开,但这里不包括所有参数。有关详细信息,请参阅 创建列车试验配置文件 。
培训师(顶级配置)
顶层实验配置包括实验的基本参数;例如,历元数、预训练权重、是否加载预训练图等。根据 checkpoint_n_epoch 值保存加密的检查点。下面是一些顶级配置的代码示例。
checkpoint_dir: /workspace/tlt-experiments/bpnet/models/exp_m1_unpruned checkpoint_n_epoch: 5 num_epoch: 100 pretrained_weights: /workspace/tlt-experiments/bpnet/pretrained_vgg19/tlt_bodyposenet_vvgg19/vgg_19.hdf5 load_graph: False use_stagewise_lr_multipliers: True ...
所有路径( checkpoint_dir 和 pretrained_weights )都是 Docker 容器的内部路径。要验证正确性,请选中 ~/.tlt_mounts.json 。有关这些参数的更多信息,请参阅 身体姿势训练器 部分。
Dataloader
本节帮助您定义数据路径、图像配置、目标姿势配置、规范化参数等。 augmentation_config 部分提供了一些动态增强选项。它支持基本的空间增强,例如翻转、缩放、旋转和平移,这些都可以在训练实验之前配置。 label_processor_config 部分提供了配置地面实况要素图生成所需的参数。
dataloader: batch_size: 10 pose_config: target_shape: [32, 32] pose_config_path: /workspace/examples/bpnet/model_pose_config/bpnet_18joints.json image_config: image_dims: height: 256 width: 256 channels: 3 image_encoding: jpg dataset_config: root_data_path: /workspace/tlt-experiments/bpnet/data/ train_records_folder_path: /workspace/tlt-experiments/bpnet/data train_records_path: [train-fold-000-of-001] dataset_specs: coco: /workspace/examples/bpnet/data_pose_config/coco_spec.json normalization_params: ... augmentation_config: spatial_augmentation_mode: person_centric spatial_aug_params: flip_lr_prob: 0.5 flip_tb_prob: 0.0 ... label_processor_config: paf_gaussian_sigma: 0.03 heatmap_gaussian_sigma: 7.0 paf_ortho_dist_thresh: 1.0
-
target_shape值取决于image_dims和模型步幅值(target_shape=input_shape/model stride)。当前模型的步幅为 8 。 -
确保使用与
dataset_spec中的root_directory_path相同的root_data_path值。dataset_spec中的掩码和图像数据目录相对于root_data_path。 -
所有路径,包括
pose_config_path、dataset_config和dataset_specs,都是 Docker 的内部路径。 -
支持多种
spatial_augmentation_modes:-
person_centric:增强是围绕一个对基本真相感兴趣的人。
-
standard:增强是标准的(即,以图像中心为中心),并且保留图像的纵横比。
-
standard_with_fixed_aspect_ratio:与标准相同,但纵横比固定为网络输入纵横比。
-
有关每个参数的详细信息,请参阅 Dataloader 部分。
Model
BodyPoseNet 模型可以使用 spec 文件中的 model 选项进行配置。下面是一个示例模型配置,用于实例化基于 VGG19 主干网的自定义模型。
model: backbone_attributes: architecture: vgg stages: 3 heat_channels: 19 paf_channels: 38 use_self_attention: False data_format: channels_last use_bias: True regularization_type: l1 kernel_regularization_factor: 5.0e-4 bias_regularization_factor: 0.0 ...
网络中用于姿势估计的总阶段数(细化阶段+ 1 )由 stages 参数捕获,该参数取任何值>= 2 。我们建议在修剪前训练网络时使用 L1 正则化器,因为 L1 正则化使修剪网络权重更容易。有关模型中每个参数的详细信息,请参阅 Model 部分。
优化
本节介绍如何配置优化器和学习速率计划:
optimizer: __class_name__: WeightedMomentumOptimizer learning_rate_schedule: __class_name__: SoftstartAnnealingLearningRateSchedule soft_start: 0.05 annealing: 0.5 base_learning_rate: 2.e-5 min_learning_rate: 8.e-08 momentum: 0.9 use_nesterov: False
默认的 base_learning_rate 是为单个 GPU 训练设置的。要使用多 GPU 训练,可能需要修改“学习率”值以获得类似的精度。在大多数情况下,将学习率提高一倍 $NUM_GPUS 将是一个良好的开端。例如,如果您使用两个 GPU ,请在一个 GPU 设置中使用 2 * base_learning_rate ,如果您使用四个 GPU ,请使用 4 * base_learning_rate 。有关模型中每个参数的详细信息,请参阅 Optimizer 部分。
训练
在完成生成 TFRecords 和 mask 的步骤并设置了一个 train 规范文件之后,现在就可以开始训练 body pose estimation 网络了。使用以下命令启动培训:
tlt bpnet train -e $SPECS_DIR/bpnet_train_m1_coco.yaml \ -r $USER_EXPERIMENT_DIR/models/exp_m1_unpruned \ -k $KEY \ --gpus $NUM_GPUS
使用更多 GPU 进行培训可以使网络更快地接收更多数据,从而在开发过程中节省宝贵的时间。 TLT 支持多 GPU 训练,因此可以使用多个 GPU 并行训练模型。我们建议使用四个或更多的 GPU 来训练模型,因为一个 GPU MIG ht 需要几天才能完成。训练时间大致减少了一个系数 $NUM_GPUS 。确保根据 Optimizer 一节中描述的线性缩放方法相应地更新学习速率。
BodyPoseNet 支持从检查点重新启动。如果训练作业过早终止,只需重新运行相同的命令,就可以从上次保存的检查点恢复训练。重新启动培训时,请确保使用相同数量的 GPU 。
评估
从配置推断和评估规范文件开始。下面的代码示例是一个示例规范:
model_path: /workspace/tlt-experiments/bpnet/models/exp_m1_unpruned/bpnet_model.tlt
train_spec: /workspace/examples/bpnet/specs/bpnet_train_m1_coco.yaml
input_shape: [368, 368]
# choose from: {pad_image_input, adjust_network_input, None}
keep_aspect_ratio_mode: adjust_network_input
output_stage_to_use: null
output_upsampling_factor: [8, 8]
heatmap_threshold: 0.1
paf_threshold: 0.05
multi_scale_inference: False
scales: [0.5, 1.0, 1.5, 2.0]
此处的 input_shape 值可以不同于用于培训的 input_dims 值。 multi_scale_inference 参数可在提供的比例上启用多比例优化。因为您使用的是步幅 8 的模型, output_upsampling_factor 设置为 8 。
为了使评估与自底向上的人体姿势估计研究保持一致,有两种模式和规范文件来评估模型:
-
$SPECS_DIR/infer_spec.yaml:单刻度,非严格输入。此配置对输入图像进行单比例推断。通过固定网络输入的一侧(高度或宽度),并调整另一侧以匹配输入图像的纵横比,来保持输入图像的纵横比。 -
$SPECS_DIR/infer_spec_refine.yaml:多尺度、非严格输入。此配置对输入图像进行多尺度推断。电子秤是可配置的。
还有一种模式主要用于验证最终导出的 TRT 模型。在后面的章节中使用这个。
-
$SPECS_DIR/infer_spec_strict.yaml:单刻度,严格输入。此配置对输入图像进行单比例推断。当 TRT 模型的输入尺寸固定时,根据需要在侧面填充图像以适应网络输入尺寸,从而保留输入图像的纵横比。
--model_filename 参数重写推理规范文件中的 model_path 变量。
要计算模型,请使用以下命令:
# Single-scale evaluation tlt bpnet evaluate --inference_spec $SPECS_DIR/infer_spec.yaml \ --model_filename $USER_EXPERIMENT_DIR/models/exp_m1_unpruned/$MODEL_CHECKPOINT \ --dataset_spec $DATA_POSE_SPECS_DIR/coco_spec.json \ --results_dir $USER_EXPERIMENT_DIR/results/exp_m1_unpruned/eval_default \ -k $KEY
模型验证
现在您已经训练了模型,运行推断并验证预测。要使用 TLT 直观地验证模型,请使用 tlt bpnet inference 命令。该工具支持对 .tlt 模型和 TensorRT .engine 模型运行推理。它在 detections.json 中生成带注释的图像,在这些图像上渲染骨架,并逐帧序列化关键点标签和元数据。例如,要使用经过训练的 .tlt 模型运行推理,请运行以下命令:
tlt bpnet inference --inference_spec $SPECS_DIR/infer_spec.yaml \ --model_filename $USER_EXPERIMENT_DIR/models/exp_m1_unpruned/$MODEL_CHECKPOINT \ --input_type dir \ --input $USER_EXPERIMENT_DIR/data/sample_images \ --results_dir $USER_EXPERIMENT_DIR/results/exp_m1_unpruned/infer_default \ --dump_visualizations \ -k $KEY
图 1 显示了原始图像的一个示例,图 2 显示了渲染姿势结果的输出图像。如您所见,该模型对不同于 COCO 训练数据的图像具有鲁棒性。
结论
在这篇文章中,您学习了如何使用 TLT 中的 BodyPoseNet 应用程序训练身体姿势模型。这篇文章展示了从 NGC 获取一个带有预训练主干的开源 COCO 数据集,用 TLT 训练一个模型。要优化用于推理和部署的训练模型,请参见 二维姿态估计模型的训练与优化,第 2 部分 。
关于作者
Sakthivel Sivaraman 是 NVIDIA 的高级软件工程师,专注于开发深度学习和计算机视觉解决方案,并将其部署到边缘。在 2018 参加“ ZVK3]之前,他从宾夕法尼亚大学获得机器人学博士学位。他的研究兴趣包括计算机视觉、深度学习和机器人技术。
Rajath Shetty 是 NVIDIA 的工程经理,负责在汽车和医疗保健领域应用深度学习和计算机视觉的项目。他的兴趣涉及边缘计算、算法和人工智能应用软件栈。他拥有乔治亚理工学院的电子和计算机工程硕士学位。
Chintan Shah 是 NVIDIA 的产品经理,专注于智能视频分析解决方案的 AI 产品。他管理工具箱,用于有效的深度学习培训和实时推理。在他之前的工作中,他正在为 NVIDIA GPU 开发硬件 IP 。他拥有北卡罗来纳州立大学电气工程硕士学位。
Niral Pathak 是 NVIDIA 的软件工程师,致力于计算机视觉解决方案的部署。他拥有加州大学圣地亚哥分校电子和计算机工程硕士学位。他的兴趣包括计算机视觉、深度学习和机器人技术。
审核编辑:郭婷
-
【爱芯派 Pro 开发板试用体验】人体姿态估计模型部署前期准备2024-01-01 1813
-
Pytorch模型训练实用PDF教程【中文】2018-12-21 5202
-
MNIST数据集训练手写数字识别模型的优化2019-10-21 2836
-
如何使用eIQ门户训练人脸检测模型?2023-04-06 778
-
相干分布式信源二维波达方向估计算法2009-11-24 726
-
一种快速二维到来方向估计算法2012-03-28 502
-
利用空域稀疏性的L型阵下二维波达方向估计2017-01-07 616
-
基于协方差矩阵降维稀疏表示的二维波达方向估计方法2017-12-14 1133
-
C语言程序设计教程之二维数组如何应用二维数组的资料概述2018-10-26 1697
-
3D姿态估计 时序卷积+半监督训练2020-12-08 1787
-
基于深度学习的二维人体姿态估计方法2021-03-22 1380
-
基于深度学习的二维人体姿态估计算法2021-04-27 1221
-
用NVIDIA迁移学习工具箱如何训练二维姿态估计模型2022-04-10 2762
-
基于OnePose的无CAD模型的物体姿态估计2022-08-10 2529
-
Ansys二维光栅出瞳扩展系统优化2023-05-23 1848
全部0条评论

快来发表一下你的评论吧 !
