

linux内核支持硬中断嵌套吗
描述
火焰图中就是找不到函数名,怀疑符号被优化
提问:yly
参与:自行车 成不晒ᯤ⁶ᴳ
你这个图是有的内核函数还是基本全部符号看不到,用的系统自带的perf的话可以考虑下载对应内涵源码,自己把perf在机器上重新编译一下,我自己已经遇到这个问题好几次了
加noinline强制编译器不要inline
Linux Trace 系统介绍
提问:李泉
参与:广成子 guoqiang Gang 逸 游~游~游 pwl999 乘风破浪的凌杰
mindjet mindmanager 画的架构图:
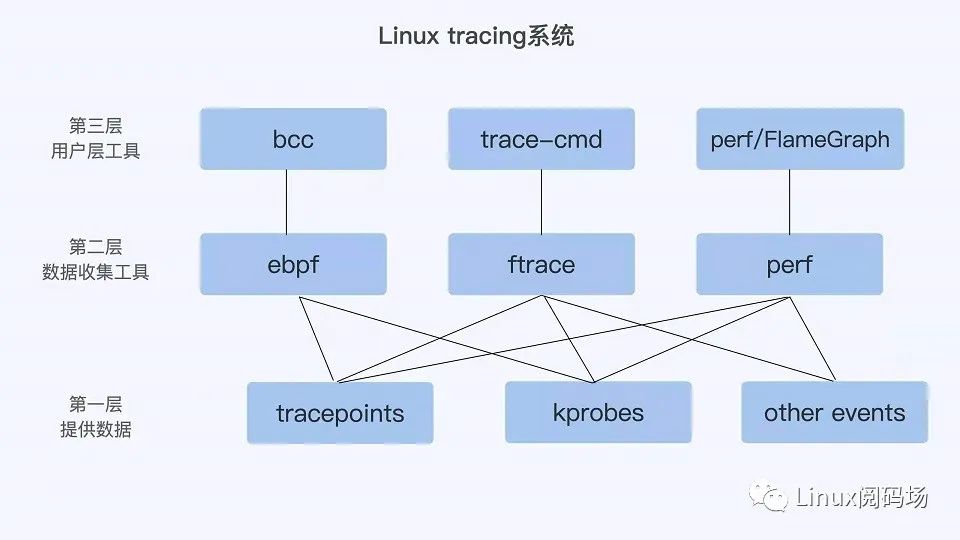
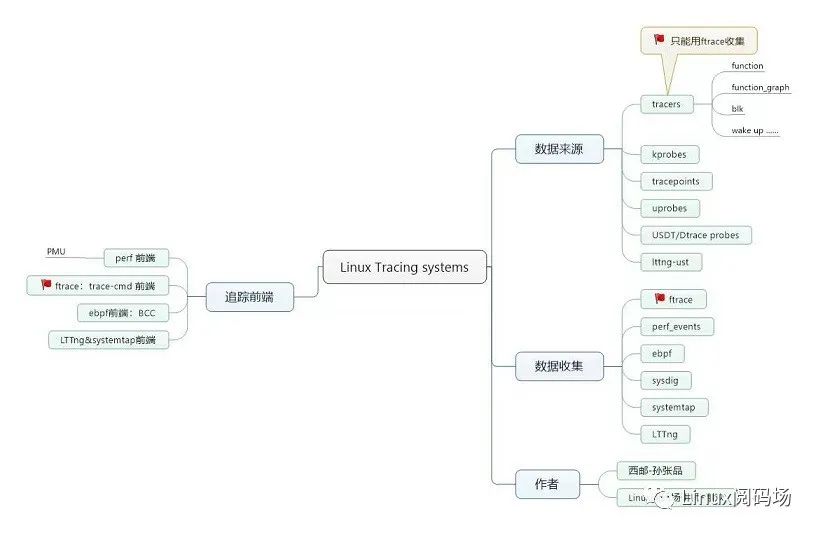
有使用 atrace+prefetto+sql 前端工具组合
Vmcore 分析工具
提问:游~游~游
参与:pwl999
crash
linux-ramdump-parser
VAATools
死机后查看 Trace 日志
提问:晴天
参与:Gang ~jeff CH
crash工具支持扩展的trace命令,如果有kdump的话,可以使用crash> trace show显示trace日志
SOC 增加 Kdump 机制支持
参与:CH pwl999
Linux Kdump 机制详解
栈空间的变量被踩定位
提问:Li
栈空间的变量进入函数时不为空,到某一处就变为空了,中间没有对该变量的操作
参与:LittleEmpero 李佳龙 Gang ~jeff pwl999
大概率是运行时栈内存被踩了。
如果地址恒定,可以尝试用gdb watch命令捕捉:
// 先打印这个栈变量的地址
p &stack_var
0x12345678
// 然后
watch *(long*)0x12345678
栈空间的变量,切换栈,地址就变了?可以尝试把watch和command命令一起用,在函数入口下个断点,在command里下watch,这就相当于动态下观测点,这样跑一晚上估计明天来了就看到踩内存的现场了。
watch失效后,程序就停止了,怎么让它继续往下?在函数退出的地方,或者说在watch失效前的地方,再加个断点,在这个断点的command里把观测点删掉。通常情况下,源代码维度即使有多个返回点,编译成指令后,就只有一个返回点,所有的return都会通过jxx指令跳到唯一返回点,当然通常情况下是这样。可以用disass指令对函数反汇编,然后看看ret指令是不是唯一的,如果ret指令是唯一的,就在ret指令前面用 b*0x12345678这种语法,打一个绝对地址断点。
没有单独delete watchpoints,del all就会把断点这都删除了。
可以试下objtrace。可以设置一个跟踪点,把一个函数参数设置为跟踪点,如果在其它地方访问到(经过了其它的函数参数)会被捕捉到。Introduce objtrace trigger to trace the kernel object
objtrace
objtrace
Introduce objtrace trigger to trace the kernel object
谢欢:向linux内核引进object trace
gdb 录制执行
参与:Li LittleEmpero
rr-project
handlespeculativefault
提问:viho he参与:LittleEmpero 郑杨
投机性缺页异常处理
cache false sharing 定位
提问:nicolas参与:kaka 李佳龙 天空微蓝 pwl999
perf抓取cache miss类的event吧,再分析pc之间的关系,有没有可能是false sharing 造成的
perf c2c
虚拟内存增长怎么分析
提问:Gang

参与:LittleEmpero rocklee viho he nicolas pwl999
感觉虚拟内存即使泄露了应该也没啥风险,64位系统,虚拟地址空间大得很。不过不可否认这肯定不正常,代码肯定有问题。
每隔一段时间cat 一下/proc/PID/smap,然后对比之前的,先看看是哪段地址在增长。是mmap忘了unmap,还是系统堆区在不断增长,然后再具体分析。
手机上虚拟内存可以直接看maps,结合smaps进行分类,和对应物理内存大小,pc上应该也是类似。
或许倒是可以从slab来查,到底是谁在申请大量虚拟内存?vmareastructs。
Memory Overcommit
性能书籍推荐
参与:viho he guoqiang
soft lockup / hard lockup 定义
提问:游~游~游
参与:自行车 pwl999
softlockup是抢占被关了,hardlockup是中断被关了
如果一个内核线程关中断(不持有锁,只是关中断)并且睡眠,会发生什么?
提问:viho he
参与:~jeff 逸 pwl999
关中断的情况下, 如果发生调度,schedule()就会打开中断,会引入中断重入的问题,也对sched out进程在不知情的情况下打开了中断
huge page 对性能的提升
提问:viho he
参与:自行车 pwl999
huge page只是影响了tlb,对cache无影响吧
我们为什么要禁用 THP
Huge Page 是否是拯救性能的万能良药?
linux 内核支持硬中断的嵌套吗?
提问:hw
参与:郑杨 木子丶棒
Linux的中断可以嵌套吗?
FPGA开发者和内核开发者打通
参与:guoqiang hw 小林
pmu 和 Ftrace 是两把钥匙
当你去主导一个基于zynq的图像质检项目,你就会发现,负责项目研发的人如果有一个全通的,会事半功倍
整个华东区未来是全世界的电动车产业集群,上海需要大量这样的人,房子都不一定能赶上这类人才的薪资增长率。
AI和HPC是性能需求的推动者。其实还有个需求是美国实体名单带来的,比如原来7nm的处理器,美国非不让你,你就只能28nm,怎么在28nm的芯片上跑出来更高的性能。
AI 算法书籍推荐
参与:CH guoqiang
有两个细分方向,如果图像就是冈萨雷斯的数字图像处理,如果是机器学习,就是周志华的西瓜书:
这一本作为通识 了解入门级来看 看全貌用的:
这一本再看具体分类:(其它的 在深入细分方向就看paper 综述、做实验)
再往后 往深的走,就需要补数学了,优化理论等:(目前人工智能的本质其实就是求解优化问题,获取次优解)
dma-buf
参与:guoqiang viho he Peter 孙雷 Oops Wenhui
dma-buf的底层机制,安卓的ION也是基于此搭建出来的。但是ION在staging过程中受阻 ,最终upstream放弃了合入ION,而由John Stultz主领,在同样的dma-buf机制上,做了一个叫DMA-BUF Heaps的东西来替代ION。安卓社区也列了相应计划从ION迁移到DMA-BUF Heaps:LVC21-120 Moving to DMA BUF Heaps Now is the time!,从dma-buf往上,ION也好,dma-buf heaps也罢,这一整套方案就是想搞定数据在这些众多硬件之间流转的 零拷贝难题:
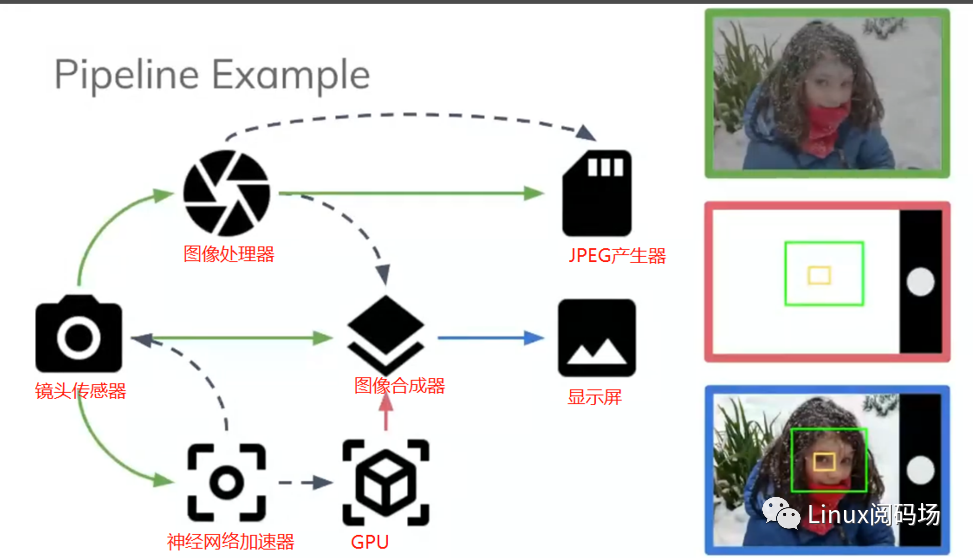
啥应用场景有这样的需求呢?目前需求最大的就是图形图像领域,图像这种大数据处理不共享太慢,dma来回搬太慢。这个图里,7个硬件全要在同一块数据上做读写。如果用拷贝、搬运的话,想想这个性能损耗有多大,分析以后,可能还要送给GPU去绘图(比如手机上人脸识别,打出来的那个框就是GPU绘的)。
在图像处理的时候,比如一帧图像,可能会经过isp, 畸变校正,缩放裁剪,最后可能会送到ai模块作分析 这个过程中的每个环节几乎都是硬件来完成的,如果单纯的使用dma来搬数据,效率就很低了。
TEE也来做零拷贝,会不会有安全隐患?share memory本来就是暴露给linux(REE)的,本来就是安全薄弱的环节。加上Infirmation flow integrity tag checking 就可以安全的share了 Google doc怎么share 内存就可以怎么share。
dma-buf学习分享
Destaging ION
DMA-BUF系列文章
宋宝华:世上最好的共享内存(Linux共享内存最透彻的一篇)
RR实时调度策略,时间片一般是多少?
提问:rocklee
参与:pwl999 viho he

Linux schedule 2、调度算法
有没有这种变态用法?A B线程同一优先级,A线程是fifo调度,B线程是RR调度,这时系统怎么调度?看了一下代码,同一优先级是按先后顺序放在同一个链表上的,如果当前进程是 FIFO 会一直跑完为止,如果当前进程是 RR 时间片用完换链表上的下一个进程。涉及到的关键函数有 tasktickrt()、picknextrtentity()、enqueuert_entity()。
原文标题:彭伟林:火焰图、trace工具、dma-buf和图书推荐
文章出处:【微信公众号:Linux阅码场】欢迎添加关注!文章转载请注明出处。
-
Linux内核中断设计与实现2022-07-29 1361
-
STM32中断与嵌套NVIC快速入门2011-02-11 1144
-
Linux 2.4.x内核软中断机制2017-11-02 1019
-
linux内核中断机制2017-11-14 3580
-
STM32中断与嵌套NVIC快速入门2017-11-30 1229
-
Linux驱动技术之一内核中断2019-05-08 1037
-
MCU中断嵌套总结--51,STM32,DSP,ARM2021-11-05 918
-
【CC2530授课笔记】⑥ 外部中断及中断嵌套 (51内核单片机)2021-11-22 1107
-
linux内核-时钟中断2021-11-23 815
-
[IC]浅谈嵌入式MCU软件开发之中断优先级与中断嵌套2021-12-05 1121
-
Linux内核外部中断解析(下)2023-06-23 1061
-
Cortex-M 内核中断/异常系统、中断优先级/嵌套 详解2023-09-27 4290
-
软中断与硬中断介绍2023-11-07 2274
-
什么是LInux 操作系统中断2023-11-10 1862
-
LInux 操作系统中断介绍2023-11-13 2002
全部0条评论

快来发表一下你的评论吧 !
