

CUDA强大新工具:nvprof 命令行探查器
描述
CUDA 5 为 CUDA 工具箱添加了一个强大的新工具: nvprof 。 nvprof 是一个可用于 Linux 、 Windows 和 OS X 的命令行探查器。乍一看, nvprof 似乎只是 NVIDIA Visual Profiler 和 NSight 日蚀版 中图形分析功能的无 GUI 版本。但是 nvprof 远不止这些;对我来说, nvprof 是一个轻量级的分析器,它达到了其他工具所不能达到的水平。
使用 nvprof 进行快速检查
我经常想知道我的 CUDA 应用程序是否按预期运行。有时这只是一个正常的检查:应用程序是否在 GPU 上运行内核?它是否执行过多的内存复制?通过使用 nvprof ./myApp 运行我的应用程序,我可以快速看到它所使用的所有内核和内存副本的摘要,如下面的示例输出所示。
==9261== Profiling application: ./tHogbomCleanHemi
==9261== Profiling result:
Time(%) Time Calls Avg Min Max Name
58.73% 737.97ms 1000 737.97us 424.77us 1.1405ms subtractPSFLoop_kernel(float const *, int, float*, int, int, int, int, int, int, int, float, float)
38.39% 482.31ms 1001 481.83us 475.74us 492.16us findPeakLoop_kernel(MaxCandidate*, float const *, int)
1.87% 23.450ms 2 11.725ms 11.721ms 11.728ms [CUDA memcpy HtoD]
1.01% 12.715ms 1002 12.689us 2.1760us 10.502ms [CUDA memcpy DtoH]
在默认的 摘要模式 中, nvprof 提供了应用程序中 GPU 内核和内存副本的概述。摘要将对同一内核的所有调用组合在一起,显示每个内核的总时间和总应用程序时间的百分比。除了摘要模式之外, nvprof 还支持 GPU – 跟踪和 API 跟踪模式 ,它可以让您看到所有内核启动和内存副本的完整列表,在 API 跟踪模式下,还可以看到所有 CUDA API 调用的完整列表。
下面是一个使用 nvprof --print-gpu-trace 评测在我的电脑上的两个 GPUs 上运行的 nbody 示例应用程序的示例。我们可以看到每个内核在哪个 GPU 上运行,以及每次启动使用的网格维度。当您想验证 multi- GPU 应用程序是否按预期运行时,这非常有用。
nvprof --print-gpu-trace ./nbody --benchmark -numdevices=2 -i=1 ... ==4125== Profiling application: ./nbody --benchmark -numdevices=2 -i=1 ==4125== Profiling result: Start Duration Grid Size Block Size Regs* SSMem* DSMem* Size Throughput Device Context Stream Name 260.78ms 864ns - - - - - 4B 4.6296MB/s Tesla K20c (0) 2 2 [CUDA memcpy HtoD] 260.79ms 960ns - - - - - 4B 4.1667MB/s GeForce GTX 680 1 2 [CUDA memcpy HtoD] 260.93ms 896ns - - - - - 4B 4.4643MB/s Tesla K20c (0) 2 2 [CUDA memcpy HtoD] 260.94ms 672ns - - - - - 4B 5.9524MB/s GeForce GTX 680 1 2 [CUDA memcpy HtoD] 268.03ms 1.3120us - - - - - 8B 6.0976MB/s Tesla K20c (0) 2 2 [CUDA memcpy HtoD] 268.04ms 928ns - - - - - 8B 8.6207MB/s GeForce GTX 680 1 2 [CUDA memcpy HtoD] 268.19ms 864ns - - - - - 8B 9.2593MB/s Tesla K20c (0) 2 2 [CUDA memcpy HtoD] 268.19ms 800ns - - - - - 8B 10.000MB/s GeForce GTX 680 1 2 [CUDA memcpy HtoD] 274.59ms 2.2887ms (52 1 1) (256 1 1) 36 0B 4.0960KB - - Tesla K20c (0) 2 2 void integrateBodies(vec4::Type*, vec4::Type*, vec4::Type*, unsigned int, unsigned int, float, float, int) [242] 274.67ms 981.47us (32 1 1) (256 1 1) 36 0B 4.0960KB - - GeForce GTX 680 1 2 void integrateBodies(vec4::Type*, vec4::Type*, vec4::Type*, unsigned int, unsigned int, float, float, int) [257] 276.94ms 2.3146ms (52 1 1) (256 1 1) 36 0B 4.0960KB - - Tesla K20c (0) 2 2 void integrateBodies(vec4::Type*, vec4::Type*, vec4::Type*, unsigned int, unsigned int, float, float, int) [275] 276.99ms 979.36us (32 1 1) (256 1 1) 36 0B 4.0960KB - - GeForce GTX 680 1 2 void integrateBodies(vec4::Type*, vec4::Type*, vec4::Type*, unsigned int, unsigned int, float, float, int) [290] Regs: Number of registers used per CUDA thread. SSMem: Static shared memory allocated per CUDA block. DSMem: Dynamic shared memory allocated per CUDA block.
使用nvprof to Profile Anything
nvprof 知道如何评测运行在 GPUs NVIDIA 上的 CUDA 内核,不管它们是用什么语言编写的(只要它们是使用 CUDA 运行时 API 或驱动程序 API 启动的)。这意味着我可以使用 nvprof 来评测 OpenACC 程序(没有显式内核),甚至可以在内部生成 PTX 汇编内核的程序。 Mark Ebersole 在他最近关于 CUDA Python 的 CUDA Cast ( 第十集 )中展示了一个很好的例子,其中他使用 NumbaPro 编译器(来自 Continuum Analytics )及时编译了一个 Python 函数,并在 GPU 上并行运行。
在 OpenACC 或 CUDA Python 程序的初始实现过程中,函数是否在 nvprof 或 GPU 上运行可能并不明显(尤其是如果您没有计时)。在 Mark 的例子中,他在 GPU 内部运行 Python 解释器,捕捉应用程序的 CUDA 函数调用和内核启动的跟踪,显示内核确实在 GPU 上运行,以及用于将数据从 CPU 传输到 GPU 的 cudaMemcpy 调用。这是一个很好的例子,说明了像 nvprof 这样的轻量级命令行 GPU 探查器的“健全性检查”功能。
使用 nvprof 进行远程分析
有时,您正在部署的系统不是您的桌面系统。例如,如果您使用的是 GPU 集群或云系统,如 Amazon EC2 ,并且您只能通过终端访问机器。这是 nvprof 的另一个重要用途。只需连接到远程计算机(例如使用 ssh ,并在 nvprof 下运行应用程序。
通过使用 --output-profile 命令行选项,您可以输出一个数据文件,以便以后导入到 nvprof 或 NVIDIA 可视化探查器中。这意味着您可以在远程计算机上捕获一个概要文件,然后在可视化分析器中可视化并分析桌面上的结果(有关详细信息,请参见“ 远程分析 ”)。
nvprof 提供了一个方便的选项( --analysis-metrics ),用于捕获 visualprofiler 在其“引导分析”模式下所需的所有 GPU 指标。下面的屏幕截图显示了用于确定内核瓶颈的可视化分析器。此分析的数据是使用下面的命令行捕获的。
nvprof --analysis-metrics -o nbody-analysis.nvprof ./nbody --benchmark -numdevices=2 -i=1
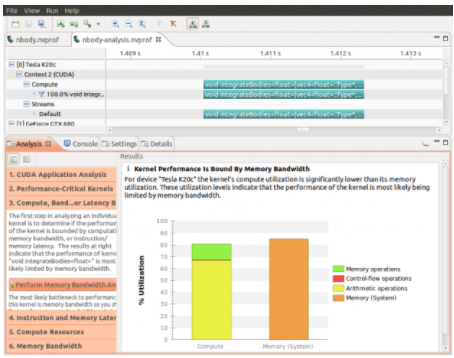 分析从 nvp 命令行分析器导入的数据的 NVIDIA 可视化分析器( nvp )的屏幕截图。
分析从 nvp 命令行分析器导入的数据的 NVIDIA 可视化分析器( nvp )的屏幕截图。非常方便的工具
如果您是命令行工具的粉丝,我想您会喜欢使用 nvprof 。 nvprof 可以做的还有很多,我在这里还没有提到,比如在 NVIDIA 可视化分析器中收集分析指标。 关于作者
Mark Harris 是 NVIDIA 杰出的工程师,致力于 RAPIDS 。 Mark 拥有超过 20 年的 GPUs 软件开发经验,从图形和游戏到基于物理的模拟,到并行算法和高性能计算。当他还是北卡罗来纳大学的博士生时,他意识到了一种新生的趋势,并为此创造了一个名字: GPGPU (图形处理单元上的通用计算)。
审核编辑:郭婷
-
Linux命令行工具2019-07-25 1585
-
caxa命令行中的应用2009-10-18 2704
-
CMD的命令行高级教程2017-10-24 1392
-
监控jvm常用的5个命令行工具2018-02-06 6644
-
Xilinx软件命令行工具:XSCT开发和调试2018-11-21 15838
-
Xilinx软件命令行工具进行开发和调试2018-11-22 7886
-
Git常见的误区和命令行工具等综述2021-08-31 951
-
Shell命令行解释器简介2022-08-19 4410
-
Golang基于flag库实现一个命令行工具2022-10-28 2400
-
新的开源命令行工具west2022-11-11 965
-
在STM32实现命令行2022-12-09 3732
-
介绍Go里面经常使用到的命令行工具2023-05-22 2359
-
PetaLinux工具文档:命令行参考指南2023-09-15 613
-
eclipse怎么使用命令行2023-12-06 4650
-
HarmonyOS开发:【基于命令行(安装库和工具集)】2024-04-25 1447
全部0条评论

快来发表一下你的评论吧 !
