

语音识别技术概述
描述
语音是人类最自然的交互方式。计算机发明之后,让机器能够“听懂”人类的语言,理解语言中的内在含义,并能做出正确的回答就成为了人们追求的目标。我们都希望像科幻电影中那些智能先进的机器人助手一样,在与人进行语音交流时,让它听明白你在说什么。语音识别技术将人类这一曾经的梦想变成了现实。语音识别就好比“机器的听觉系统”,该技术让机器通过识别和理解,把语音信号转变为相应的文本或命令。
语音识别技术,也被称为自动语音识别AutomaTIc Speech RecogniTIon,(ASR),其目标是将人类的语音中的词汇内容转换为计算机可读的输入,例如按键、二进制编码或者字符序列。语音识别就好比“机器的听觉系统”,它让机器通过识别和理解,把语音信号转变为相应的文本或命令。
语音识别是一门涉及面很广的交叉学科,它与声学、语音学、语言学、信息理论、模式识别理论以及神经生物学等学科都有非常密切的关系。语音识别技术正逐步成为计算机信息处理技术中的关键技术。
语音识别技术的发展
语音识别技术的研究最早开始于20世纪50年代, 1952 年贝尔实验室研发出了 10 个孤立数字的识别系统。从 20 世纪 60 年代开始,美国卡耐基梅隆大学的 Reddy 等开展了连续语音识别的研究,但是这段时间发展很缓慢。1969年贝尔实验室的 Pierce J 甚至在一封公开信中将语音识别比作近几年不可能实现的事情。
20世纪80年代开始,以隐马尔可夫模型(hidden Markov model,HMM)方法为代表的基于统计模型方法逐渐在语音识别研究中占据了主导地位。HMM模型能够很好地描述语音信号的短时平稳特性,并且将声学、语言学、句法等知识集成到统一框架中。此后,HMM的研究和应用逐渐成为了主流。例如,第一个“非特定人连续语音识别系统”是当时还在卡耐基梅隆大学读书的李开复研发的SPHINX系统,其核心框架就是GMM-HMM框架,其中GMM(Gaussian mixture model,高斯混合模型)用来对语音的观察概率进行建模,HMM则对语音的时序进行建模。
20世纪80年代后期,深度神经网络(deep neural network,DNN)的前身——人工神经网络(artificial neural network, ANN)也成为了语音识别研究的一个方向。但这种浅层神经网络在语音识别任务上的效果一般,表现并不如GMM-HMM 模型。
20世纪90年代开始,语音识别掀起了第一次研究和产业应用的小高潮,主要得益于基于 GMM-HMM 声学模型的区分性训练准则和模型自适应方法的提出。这时期剑桥发布的HTK开源工具包大幅度降低了语音识别研究的门槛。此后将近10年的时间里,语音识别的研究进展一直比较有限,基于GMM-HMM 框架的语音识别系统整体效果还远远达不到实用化水平,语音识别的研究和应用陷入了瓶颈。
2006 年 Hinton]提出使用受限波尔兹曼机(restricted Boltzmann machine,RBM)对神经网络的节点做初始化,即深度置信网络(deep belief network,DBN)。DBN解决了深度神经网络训练过程中容易陷入局部最优的问题,自此深度学习的大潮正式拉开。
2009 年,Hinton 和他的学生Mohamed D将 DBN 应用在语音识别声学建模中,并且在TIMIT这样的小词汇量连续语音识别数据库上获得成功。
2011 年 DNN 在大词汇量连续语音识别上获得成功,语音识别效果取得了近10年来最大的突破。从此,基于深度神经网络的建模方式正式取代GMM-HMM,成为主流的语音识别建模方式。
语音识别的基本原理
所谓语音识别,就是将一段语音信号转换成相对应的文本信息,系统主要包含特征提取、声学模型,语言模型以及字典与解码四大部分,其中为了更有效地提取特征往往还需要对所采集到的声音信号进行滤波、分帧等预处理工作,把要分析的信号从原始信号中提取出来;之后,特征提取工作将声音信号从时域转换到频域,为声学模型提供合适的特征向量;声学模型中再根据声学特性计算每一个特征向量在声学特征上的得分;而语言模型则根据语言学相关的理论,计算该声音信号对应可能词组序列的概率;最后根据已有的字典,对词组序列进行解码,得到最后可能的文本表示。
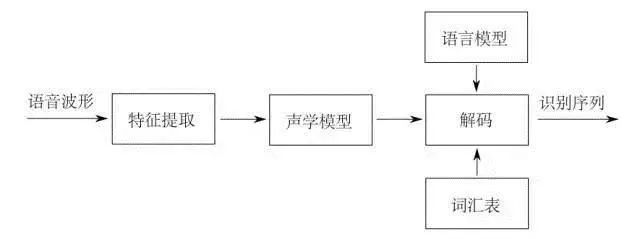
声学信号预处理
作为语音识别的前提与基础,语音信号的预处理过程至关重要。在最终进行模板匹配的时候,是将输入语音信号的特征参数同模板库中的特征参数进行对比,因此,只有在预处理阶段得到能够表征语音信号本质特征的特征参数,才能够将这些特征参数进行匹配进行识别率高的语音识别。
首先需要对声音信号进行滤波与采样,此过程主要是为了排除非人体发声以外频率的信号与50Hz电流频率的干扰,该过程一般是用一个带通滤波器、设定上下戒指频率进行滤波,再将原有离散信号进行量化处理实现的;之后需要平滑信号的高频与低频部分的衔接段,从而可以在同一信噪比条件下对频谱进行求解,使得分析更为方便快捷;分帧加窗操作是为了将原有频域随时间变化的信号具有短时平稳特性,即将连续的信号用不同长度的采集窗口分成一个个独立的频域稳定的部分以便于分析,此过程主要是采用预加重技术;最后还需要进行端点检测工作,也就是对输入语音信号的起止点进行正确判断,这主要是通过短时能量(同一帧内信号变化的幅度)与短时平均过零率(同一帧内采样信号经过零的次数)来进行大致的判定。
声学特征提取
完成信号的预处理之后,随后进行的就是整个过程中极为关键的特征提取的操作。将原始波形进行识别并不能取得很好的识别效果,频域变换后提取的特征参数用于识别,而能用于语音识别的特征参数必须满足以下几点:
1、特征参数能够尽量描述语音的根本特征;
2、尽量降低参数分量之间的耦合,对数据进行压缩;
3、应使计算特征参数的过程更加简便,使算法更加高效。基音周期、共振峰值等参数都可以作为表征语音特性的特征参数。
目前主流研究机构最常用到的特征参数有:线性预测倒谱系数(LPCC)和 Mel 倒谱系数(MFCC)。两种特征参数在倒谱域上对语音信号进行操作,前者以发声模型作为出发点,利用 LPC 技术求倒谱系数。后者则模拟听觉模型,把语音经过滤波器组模型的输出做为声学特征,然后利用离散傅里叶变换(DFT)进行变换。
所谓基音周期,是指声带振动频率(基频)的振动周期,因其能够有效表征语音信号特征,因此从最初的语音识别研究开始,基音周期检测就是一个至关重要的研究点;所谓共振峰,是指语音信号中能量集中的区域,因其表征了声道的物理特征,并且是发音音质的主要决定条件,因此同样是十分重要的特征参数。此外,目前也有许多研究者开始将深度学习中一些方法应用在特征提取中,取得了较快的进展。
声学模型
声学模型是语音识别系统中非常重要的一个组件,对不同基本单元的区分能力直接关系到识别结果的好坏。语音识别本质上一个模式识别的过程,而模式识别的核心是分类器和分类决策的问题。
通常,在孤立词、中小词汇量识别中使用动态时间规整(DTW)分类器会有良好的识别效果,并且识别速度快,系统开销小,是语音识别中很成功的匹配算法。但是,在大词汇量、非特定人语音识别的时候,DTW 识别效果就会急剧下降,这时候使用隐马尔科夫模型(HMM)进行训练识别效果就会有明显提升,由于在传统语音识别中一般采用连续的高斯混合模型GMM来对状态输出密度函数进行刻画,因此又称为GMM-HMM构架。
同时,随着深度学习的发展,通过深度神经网络来完成声学建模,形成所谓的DNN-HMM构架来取代传统的GMM-HMM构架,在语音识别上也取得了很好的效果。
高斯混合模型
对于一个随机向量 x,如果它的联合概率密度函数符合公式2-9,则称它服从高斯分布,并记为 x ∼N(µ, Σ)。
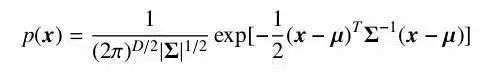
其中,µ 为分布的期望,Σ 为分布的协方差矩阵。高斯分布有很强的近似真实世界数据的能力,同时又易于计算,因此被广泛地应用在各个学科之中。但是,仍然有很多类型的数据不好被一个高斯分布所描述。这时候我们可以使用多个高斯分布的混合分布来描述这些数据,由多个分量分别负责不同潜在的数据来源。此时,随机变量符合密度函数。
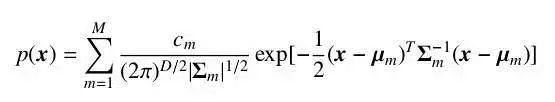
其中,M 为分量的个数,通常由问题规模来确定。
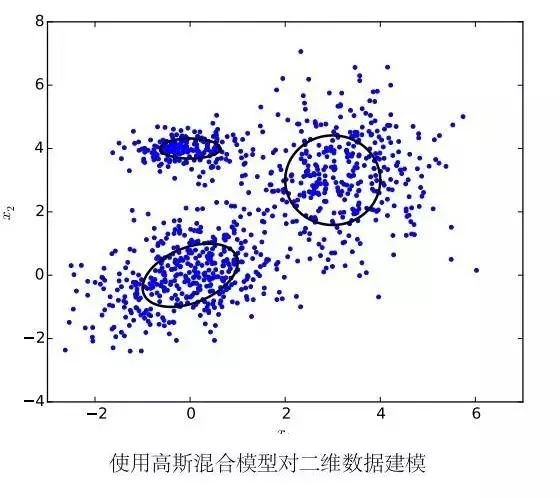
我们称认为数据服从混合高斯分布所使用的模型为高斯混合模型。高斯混合模型被广泛的应用在很多语音识别系统的声学模型中。考虑到在语音识别中向量的维数相对较大,所以我们通常会假设混合高斯分布中的协方差矩阵 Σm 为对角矩阵。这样既大大减少了参数的数量,同时可以提高计算的效率。
使用高斯混合模型对短时特征向量建模有以下几个好处:首先,高斯混合模型的具有很强的建模能力,只要分量总数足够多,高斯混合模型就可以以任意精度来逼近一个概率分布函数;另外,使用 EM 算法可以很容易地使模型在训练数据上收敛。对于计算速度和过拟合等问题,人们还研究出了参数绑定的 GMM 和子空间高斯混合模型 (subspace GMM) 来解决。除了使用 EM 算法作最大似然估计以外,我们还可以使用和词或音素错误率直接相关的区分性的误差函数来训练高斯混合模型,能够极大地提高系统性能。因此,直到在声学模型中使用深度神经网络的技术出现之前,高斯混合模型一直是短时特征向量建模的不二选择。
但是,高斯混合模型同样具有一个严重的缺点:高斯混合模型对于靠近向量空间上一个非线性流形 (manifold) 上的数据建模能力非常差。例如,假设一些数据分布在一个球面两侧,且距离球面非常近。如果使用一个合适的分类模型,我们可能只需要很少的参数就可以将球面两侧的数据区分开。但是,如果使用高斯混合模型描绘他们的实际分布情况,我们需要非常多的高斯分布分量才能足够精确地刻画。这驱使我们寻找一个能够更有效利用语音信息进行分类的模型。
隐马尔科夫模型
我们现在考虑一个离散的随机序列,若转移概率符合马尔可夫性质,即将来状态和过去状态独立,则称其为一条马尔可夫链 (Markov Chain)。若转移概率和时间无关,则称其为齐次 (homogeneous) 马尔可夫链。马尔可夫链的输出和预先定义好的状态一一对应,对于任意给定的状态,输出是可观测的,没有随机性。如果我们对输出进行扩展,使马尔可夫链的每个状态输出为一个概率分布函数。这样的话马尔可夫链的状态不能被直接观测到,只能通过受状态变化影响的符合概率分布的其他变量来推测。我们称以这种以隐马尔可夫序列假设来建模数据的模型为隐马尔可夫模型。
对应到语音识别系统中,我们使用隐马尔可夫模型来刻画一个音素内部子状态变化,来解决特征序列到多个语音基本单元之间对应关系的问题。
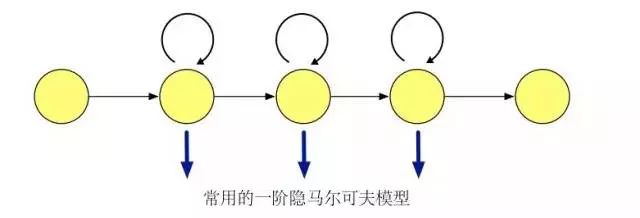
在语音识别任务中使用隐马尔可夫模型需要计算模型在一段语音片段上的可能性。而在训练的时候,我们需要使用 Baum-Welch 算法[23] 学习隐马尔可夫模型参数,进行最大似然估计 (Maximum Likelihood Estimation, MLE)。Baum-Welch 算法是EM (Expectation-Maximization) 算法的一种特例,利用前后项概率信息迭代地依次进行计算条件期望的 E 步骤和最大化条件期望的 M 步骤。
语言模型
语言模型主要是刻画人类语言表达的方式习惯,着重描述了词与词在排列结构上的内在联系。在语音识别解码的过程中,在词内转移参考发声词典、词间转移参考语言模型,好的语言模型不仅能够提高解码效率,还能在一定程度上提高识别率。语言模型分为规则模型和统计模型两类,统计语言模型用概率统计的方法来刻画语言单位内在的统计规律,其设计简单实用而且取得了很好的效果,已经被广泛用于语音识别、机器翻译、情感识别等领域。
最简单又却又最常用的语言模型是 N 元语言模型 (N-gram Language Model,N-gram LM) 。N 元语言模型假设当前在给定上文环境下,当前词的概率只与前N-1 个词相关。于是词序列 w1, . . . , wm 的概率 P(w1, . . . , wm) 可以近似为
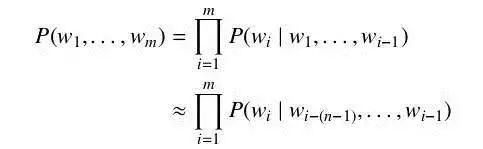
为了得到公式中的每一个词在给定上文下的概率,我们需要一定数量的该语言文本来估算。可以直接使用包含上文的词对在全部上文词对中的比例来计算该概率,即
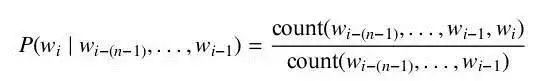
对于在文本中未出现的词对,我们需要使用平滑方法来进行近似,如 Good-Turing估计或 Kneser-Ney 平滑等。
解码与字典
解码器是识别阶段的核心组件,通过训练好的模型对语音进行解码,获得最可能的词序列,或者根据识别中间结果生成识别网格 (lattice) 以供后续组件处理。解码器部分的核心算法是动态规划算法 Viterbi。由于解码空间非常巨大,通常我们在实际应用中会使用限定搜索宽度的令牌传递方法 (token passing)。
传统解码器会完全动态生成解码图 (decode graph),如著名语音识别工具HTK(HMM Tool Kit) 中的 HVite 和 HDecode 等。这样的实现内存占用较小,但考虑到各个组件的复杂性,整个系统的流程繁琐,不方便高效地将语言模型和声学模型结合起来,同时更加难以扩展。现在主流的解码器实现会一定程度上使用预生成的有限状态变换器 (Finite State Transducer, FST) 作为预加载的静态解码图。这里我们可以将语言模型 (G),词汇表(L),上下文相关信息 (C),隐马尔可夫模型(H)四个部分分别构建为标准的有限状态变换器,再通过标准的有限状态变换器操作将他们组合起来,构建一个从上下文相关音素子状态到词的变换器。这样的实现方法额外使用了一些内存空间,但让解码器的指令序列变得更加整齐,使得一个高效的解码器的构建更加容易。同时,我们可以对预先构建的有限状态变换器进行预优化,合并和剪掉不必要的部分,使得搜索空间变得更加合理
语音识别技术的工作原理
首先,我们知道声音实际上是一种波。常见的mp3等格式都是压缩格式,必须转成非压缩的纯波形文件来处理,比如Windows PCM文件,也就是俗称的wav文件。wav文件里存储的除了一个文件头以外,就是声音波形的一个个点了。下图是一个波形的示例。
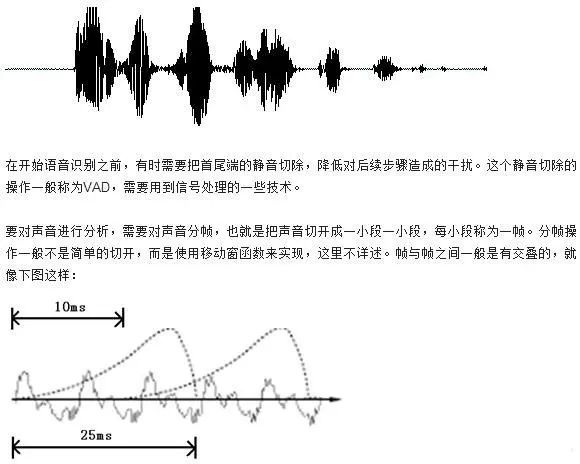
图中,每帧的长度为25毫秒,每两帧之间有25-10=15毫秒的交叠。我们称为以帧长25ms、帧移10ms分帧。
分帧后,语音就变成了很多小段。但波形在时域上几乎没有描述能力,因此必须将波形作变换。常见的一种变换方法是提取MFCC特征,根据人耳的生理特性,把每一帧波形变成一个多维向量,可以简单地理解为这个向量包含了这帧语音的内容信息。这个过程叫做声学特征提取。
至此,声音就成了一个12行(假设声学特征是12维)、N列的一个矩阵,称之为观察序列,这里N为总帧数。观察序列如下图所示,图中,每一帧都用一个12维的向量表示,色块的颜色深浅表示向量值的大小。
接下来就要介绍怎样把这个矩阵变成文本了。首先要介绍两个概念:
音素:单词的发音由音素构成。对英语,一种常用的音素集是卡内基梅隆大学的一套由39个音素构成的音素集。汉语一般直接用全部声母和韵母作为音素集,另外汉语识别还分有调无调,不详述。
状态:这里理解成比音素更细致的语音单位就行啦。通常把一个音素划分成3个状态。
语音识别是怎么工作的呢?实际上一点都不神秘,无非是:
第一步,把帧识别成状态。
第二步,把状态组合成音素。
第三步,把音素组合成单词。
如下图所示:
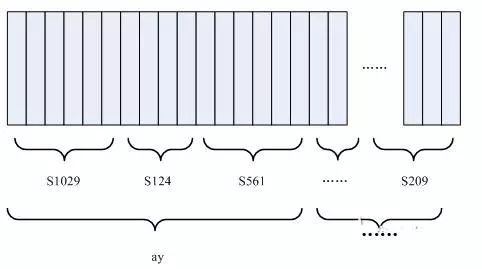
图中,每个小竖条代表一帧,若干帧语音对应一个状态,每三个状态组合成一个音素,若干个音素组合成一个单词。也就是说,只要知道每帧语音对应哪个状态了,语音识别的结果也就出来了。
那每帧音素对应哪个状态呢?有个容易想到的办法,看某帧对应哪个状态的概率最大,那这帧就属于哪个状态。比如下面的示意图,这帧在状态S3上的条件概率最大,因此就猜这帧属于状态S3。
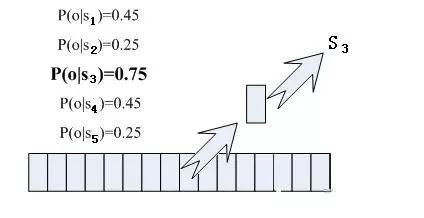
那这些用到的概率从哪里读取呢?有个叫“声学模型”的东西,里面存了一大堆参数,通过这些参数,就可以知道帧和状态对应的概率。获取这一大堆参数的方法叫做“训练”,需要使用巨大数量的语音数据。
但这样做有一个问题:每一帧都会得到一个状态号,最后整个语音就会得到一堆乱七八糟的状态号,相邻两帧间的状态号基本都不相同。假设语音有1000帧,每帧对应1个状态,每3个状态组合成一个音素,那么大概会组合成300个音素,但这段语音其实根本没有这么多音素。如果真这么做,得到的状态号可能根本无法组合成音素。实际上,相邻帧的状态应该大多数都是相同的才合理,因为每帧很短。
解决这个问题的常用方法就是使用隐马尔可夫模型(Hidden Markov Model,HMM)。这东西听起来好像很高深的样子,实际上用起来很简单:
第一步,构建一个状态网络。
第二步,从状态网络中寻找与声音最匹配的路径。
这样就把结果限制在预先设定的网络中,避免了刚才说到的问题,当然也带来一个局限,比如你设定的网络里只包含了“今天晴天”和“今天下雨”两个句子的状态路径,那么不管说些什么,识别出的结果必然是这两个句子中的一句。
那如果想识别任意文本呢?把这个网络搭得足够大,包含任意文本的路径就可以了。但这个网络越大,想要达到比较好的识别准确率就越难。所以要根据实际任务的需求,合理选择网络大小和结构。
搭建状态网络,是由单词级网络展开成音素网络,再展开成状态网络。语音识别过程其实就是在状态网络中搜索一条最佳路径,语音对应这条路径的概率最大,这称之为“解码”。路径搜索的算法是一种动态规划剪枝的算法,称之为Viterbi算法,用于寻找全局最优路径。
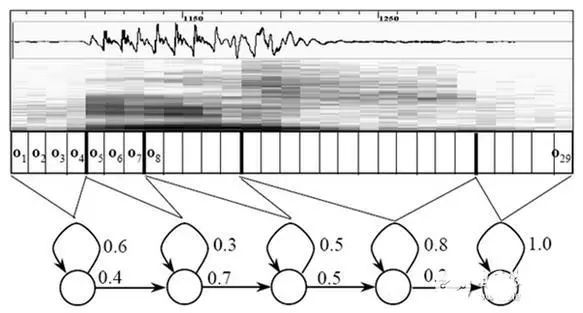
这里所说的累积概率,由三部分构成,分别是:
观察概率:每帧和每个状态对应的概率
转移概率:每个状态转移到自身或转移到下个状态的概率
语言概率:根据语言统计规律得到的概率
其中,前两种概率从声学模型中获取,最后一种概率从语言模型中获取。语言模型是使用大量的文本训练出来的,可以利用某门语言本身的统计规律来帮助提升识别正确率。语言模型很重要,如果不使用语言模型,当状态网络较大时,识别出的结果基本是一团乱麻。
这样基本上语音识别过程就完成了,这就是语音识别技术的工作原理。
语音识别技术的工作流程
一般来说,一套完整的语音识别系统其工作过程分为7步:
1、对语音信号进行分析和处理,除去冗余信息。
2、提取影响语音识别的关键信息和表达语言含义的特征信息。
3、紧扣特征信息,用最小单元识别字词。
4、按照不同语言的各自语法,依照先后次序识别字词。
5、把前后意思当作辅助识别条件,有利于分析和识别。
6、按照语义分析,给关键信息划分段落,取出所识别出的字词并连接起来,同时根据语句意思调整句子构成。
7、结合语义,仔细分析上下文的相互联系,对当前正在处理的语句进行适当修正。
语音识别原理有三点:
1、对语音信号中的语言信息编码是按照幅度谱的时间变化来进行;
2、由于语音是可以阅读的,也就是说声学信号可以在不考虑说话人说话传达的信息内容的前提下用多个具有区别性的、离散的符号来表示;
3、语音的交互是一个认知过程,所以绝对不能与语法、语义和用语规范等方面分裂开来。
预处理,其中就包括对语音信号进行采样、克服混叠滤波、去除部分由个体发音的差异和环境引起的噪声影响,此外还会考虑到语音识别基本单元的选取和端点检测问题。反复训练是在识别之前通过让说话人多次重复语音,从原始语音信号样本中去除冗余信息,保留关键信息,再按照一定规则对数据加以整理,构成模式库。再者是模式匹配,它是整个语音识别系统的核心部分,是根据一定规则以及计算输入特征与库存模式之间的相似度,进而判断出输入语音的意思。
前端处理,先对原始语音信号进行处理,再进行特征提取,消除噪声和不同说话人的发音差异带来的影响,使处理后的信号能够更完整地反映语音的本质特征提取,消除噪声和不同说话人的发音差异带来的影响,使处理后的信号能够更完整地反映语音的本质特征。
审核编辑 :李倩
-
语音识别与自然语言处理的关系2024-11-26 2983
-
影响语音芯片识别率的因素概述2023-11-27 2052
-
离线语音识别及控制是怎样的技术?2023-11-24 2241
-
语音识别技术的应用及优化2023-10-10 4336
-
语音识别技术:原理、应用与未来2023-09-19 3752
-
语音识别技术的基本原理及应用是什么?2021-05-31 5158
-
超全语音识别技术概述!2021-03-26 7864
-
基于MSP432 MCU的语音识别设计概述2019-07-30 2305
-
基于labview的语音识别2019-03-10 13029
-
语音识别技术的发展历程,语音识别是如何工作的?语音识别资料概述2018-09-01 11353
-
语音识别技术是什么_语音识别技术应用领域介绍2018-01-02 17364
-
国内语音识别技术上市公司汇总_语音识别技术现状_语音识别原理及应用2017-12-13 10963
-
什么是语音识别技术2010-03-06 2119
全部0条评论

快来发表一下你的评论吧 !
