

基于TensorFlow的阿里巴巴本地生活推荐系统
描述
案例简介
本案例中,阿里巴巴本地生活场景中,部署了大量使用 TensorFlow 的深度学习推荐模型,这些模型需要对每个用户附近的数千家商户和产品进行排名,对用户响应时间和业务吞吐量(QPS)要求极高。为了满足这样的要求 GPU 落地使用是必然,但由于 TensorFlow 目前对 GPU 使用采用单一 steam 方式,并且逐个调用 GPU 算子的过程中存在大量的 GPU kernel 启动开销, 因此如何在这些系统中充分发挥 GPU 计算能力则需要探索。
阿里巴巴本地生活推荐系统结合 NVIDIA CUDA Graphs 对 GPU 进行算力释放优化,让推理过程单机吞吐增长 110%,耗时 P99 下降 66.7%。
本案例主要应用到 NVIDIA V100 Tensor Core GPU 和 NVIDA CUDA Graphs。
客户简介及应用背景
阿里巴巴集团旗下的阿里巴巴本地生活服务公司,是由饿了么和口碑会师合并组成国内领先的本地生活服务平台,使命是“重新定义城市生活,让生活更美好。”口碑专注到店消费服务,饿了么专注到家生活服务,蜂鸟即配专注即时配送服务,客如云专注为商家提供数字化升级的产品和服务,共同推动本地生活市场的数字化,让天下没有难做的生意。
阿里巴巴本地生活服务公司智能推荐系统基于智能AI系统对用户所在区域万级商户商品进行实时智能推荐和服务。实时智能推荐伴随着深度学习技术的发展,为了追求智能推荐的准确度,推荐模型朝着两个维度快速发展:1. 更宽更深的网络,更复杂的特征增强方式。2. 更多的不同维度的特征。这对在线推理阶段的实时性能和算力提出了更高的挑战。伴随着搜索推荐模型的在 GPU 的广泛落地使用,GPU 在各个场景下的算力优化也被广泛关注。
在线 Inference 过程中,由于考虑到存储 cache 的友好性,会把计算密集型算子和其周边的数据变换算子都在 GPU 中执行,算子数量的增长会导致严重的 kernel 启动开销,主要原因是:1. 大量小 kernel 的执行
2. TensorFlow 的调度机制使得通过大量的线程启动 kernel 到同一个 stream 中;多个线程竞争同个资源加剧 launch 开销。
客户挑战
在阿里巴巴本地生活推荐搜索场景中,有大量的深度学习模型在用户和商户,用户和商品匹配场景中使用,但是总体来看 GPU-Utilization 并不高,GPU 使用成本显得比较高。随着模型复杂度不断攀升(Inference 计算达到 10~20 GFLOPS),算法同学的收益产出一定程度上和模型复杂度成正比关系。目前搜推广的模型设计中部分子结构设计和变换很多,但是基本范式如下:
Feature Generation -》 Embedding -》 Attention/Transformer -》 MLP
绿色部分基本属于计算密集型部分,但是在搜推广场景中,这部分算子不但包含对于算力需求旺盛的深度网络相关算子,也包含数据合并,数据变换等轻量级计算算子,这类算子的特点是:运算时长通常很短(1-10 微秒),而且这一类轻量级计算算子的数量伴随着 Transformer 的落地,数量占比逐步增高。
我们从另一个角度来量化这一过程轻量级计算算子的数量占比,GPU 的繁忙情况通常来说有两个指标:
1. GPU-Utilization,表示 GPU 在单位时间内在执行 kernel 的时间片比例。
2. SM Activity,表示 GPU 中 SM 在单位时间内用于执行 kernel 的 SM 使用比例*时间片比例。
我们可以看到在推荐搜索模型线上 Inference 过程中 SM Activity 通常远远低于 GPU-Utilization,这表示 GPU 虽然在忙碌,但是由于轻量级计算算子的数量占比较高,SM 使用比例使用比例不高,GPU 的实际 “工作量” 并不大。
轻量级计算算子的比例高会导致该部分算子在 CPU 上调度过程中 kernel launch 的执行时长远远大于算子在 GPU 上的执行时长,这个现象会导致严重的 kernel launch bound 现象。
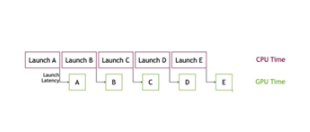
应用方案
基于以上挑战,阿里巴巴本地生活搜索推荐模型选择了 NVIDIA 提供的 AI 加速方案:CUDA Graphs。
1、首先,我们根据业务场景的具体问题,使用 NVIDIA Nsight Systems 进行问题定位和分析。我们利用 NVIDIA Nsight Systems 集成到线上 Inference 环境中,获取了真实环境下 Inference 过程的 GPU Profing 文件。通过 Profing 文件,我们可以清晰的看到 Inference 过程中,kernel launch bound 现象异常严重,符合我们的分析预想(如下图)。
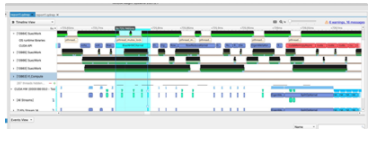
2、后续,我们采用集成 CUDA Graphs 进行模型 Inference 过程优化,理论上 CUDA Graphs 会大幅缓解 kernel launch bound 现象,因为 CUDA Graphs 会合并 N 个 kernel 独立的 launch 操作,变为 1 个 graph launch 操作,这样 kernel launch 不再是整个推理的瓶颈(如下图)。

使用效果及影响
经过集成 NVIDIA Nsight System 进行 GPU 使用情况查看和细节问题的诊断,我们充分了解和分析了业务中对 GPU 的使用情况的 kernel 执行流程。对性能进一步优化起到了指导作用。后续集成 CUDA Graphs 后,符合预期效果。推荐深度学习模型在 Inference 过程中的耗时 P99 下降 66%,单机吞吐提升 110%。让用户在毫无感知的时间范围内完成了模型算力达到 10 GFLOPS 的 Inference 过程,用户体验得到了极大的提升。
在使用 NVIDIA Nsight Systems 进行 GPU 瓶颈分析过程中,文档查阅和使用教程很方便上手,集成过程也较为方便,指标介绍很丰富,快速完成 GPU 使用情况分析。后续 CUDA Graphs 使用过程中,相关文档也比较完善,包括图的切割和分装,算子 Capture 标准等。
本次优化过程,团队内部积累了一套较为完善的 GPU 优化手段和优化方法理论,后续遇到其他模型性能问题时也有的放矢。多场景进行优化后,对整个 GPU。
审核编辑:郭婷
-
荣邦佳业有阿里巴巴啦2014-04-15 2558
-
《阿里巴巴Android开发手册》正式发布,献给移动开发者的新年礼物2018-02-28 3455
-
阿里巴巴敏捷研发的探索与实践2018-03-07 4172
-
“阿里巴巴大数据系统体系”四大层次2018-08-29 3672
-
国内芯片—阿里巴巴的人工智能实力2018-09-27 4634
-
阿里巴巴禁止开发人员使用isSuccess作为变量名的原因是什么2019-04-08 2812
-
详解阿里巴巴智能对话开发平台2019-07-31 3228
-
哪里可以下载阿里巴巴的地方和链接?2019-11-04 3267
-
数据揭秘你不知道的阿里巴巴数据中心2020-04-30 3387
-
阿里巴巴ai模型破世界纪录_阿里巴巴的人工智能未来发展解析2018-01-16 2101
-
阿里巴巴下跌 分析师下调阿里巴巴目标股价2018-10-11 2317
-
阿里巴巴回应“收缩招聘”:系假新闻,只是阿里巴巴近期的一次人才盘点和人才体系升级2018-10-25 629
-
阿里巴巴马云占股份多少?阿里巴巴马云持股比例?目前马云持股降至4.8%2020-07-13 28040
-
阿里巴巴注册元宇宙2021-11-08 3938
-
阿里巴巴完成双重主要上市2024-08-29 1233
全部0条评论

快来发表一下你的评论吧 !
