

FPGA中并行计算的流水线计算和交替计算
描述
用过FPGA的人应该都知道,在FPGA中,逻辑是并行地运行的,各个状态机同时都在工作,状态机之间可能会有信号交互,也可能毫无关系、各管各地工作。
这就给了我们一个灵感:如果我们要做的计算(例如级数求和)的规模很大,按顺序一步一步算的话,其时间开销是我们所无法忍受的,那么,我们是否可以想办法利用FPGA的并行特性,通过让计算并行地执行,来减小时间开销(或者说提高计算速度)呢?
基于这个灵感,就让我们看看,FPGA中并行计算的常规方法吧。
流水线计算
现在,我们要在FPGA中做这样一个计算:
B = A × imes× 2 + 1
能用的计算单元为两输入加法器和两输入乘法器
为了保证时序,一个时钟周期内加法器只能执行一次加法
为了保证时序,一个时钟周期内乘法器只能执行一次乘法
对于上述要求完成的计算,看上去,在一个时钟周期内既完成乘法又完成加法是不可能的了。然而,如果我们这么做呢:
1.设计一个模块,模块的输入为时钟和参数A,输出为结果B。
2.该模块在每个时钟周期同时做"C=A×2"的计算和"B=C+1"的计算,其中,C为寄存器。
仿真该模块,就可以发现:
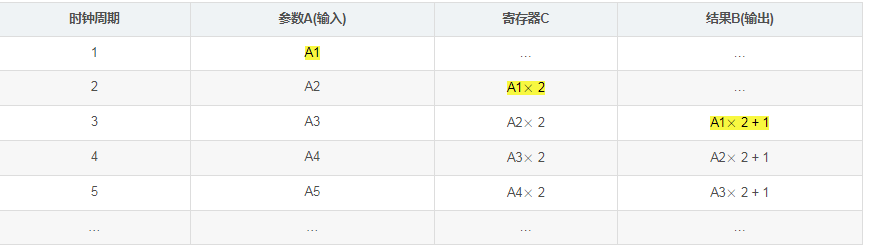
从上表可以看到:
虽然从输入A到输出B,相差了两个时钟周期,但是,每个时钟周期输出的B,都和两个时钟周期前输入的A相对应。即:等效地来看,相当于每个时钟周期,模块都完成了一次"B = A × imes× 2 + 1"的计算!
哇塞,好神奇!这简直就是:
明明一次性无法完成的计算,不知怎么搞的,却等效地"被一次性地完成了"
嗯,这种搞法,就是传说中的"流水线计算",这里为其给出了一个不拘泥于FPGA中的情形的、更加普适的定义:
将一个计算拆分成N级(N ≥ geq≥ 2),每一级的平均数据吞吐速率都相同,前(N-1)级的计算结果在输入下一级之前都经过了缓存,这种方法称为"流水线计算"
注:"平均数据吞吐速率"指的是:在单位时间内,参数平均能够输入多少次,以及计算结果平均能够输出多少次。
流水线计算的结构如下图所示("一条龙"式的结构):

分析定义可知:
正是由于"每一级的平均数据吞吐速率都相同",使得整个计算的平均数据吞吐速率相同,才让输出的结果看上去"像是被一次性地完成的"。
级间缓存在流水线计算中是必不可少的,它们起到了两级间隔离的作用,使得"当第(n+1)级在处理第i ii个输入对应的计算时,第n级已经在处理第( i + 1 ) (i+1)(i+1)个输入对应的计算了"这种情况成为可能。增大级间缓存的延迟时间,会造成整个计算的延迟时间(即输出和输入之间的延迟时间)的加长。
总的来说,流水线计算是个好东西,不过,实际使用时,如果不留心的话,容易为级间缓存分配过长的延迟时间,从而出现"整个计算的延迟时间长"的问题,这一点需要注意。
分布式流水线计算
现在,我们要在FPGA中做这样一个计算:
C = A × imes× 2 + B × imes× 3
能用的计算单元为两输入加法器和两输入乘法器
为了保证时序,一个时钟周期内加法器只能执行一次加法
为了保证时序,一个时钟周期内乘法器只能执行一次乘法
对于上述要求完成的计算,看上去,在一个时钟周期内既完成乘法又完成加法是不可能的了。然而,如果我们这么做呢:
1.设计一个模块,模块的输入为时钟和参数A、参数B,输出为结果C。
2.该模块在每个时钟周期同时做"D=A×2"的计算、"E=B×3"的计算和"C=D+E"的计算,其中,D、E为寄存器。
仿真该模块,就可以发现:
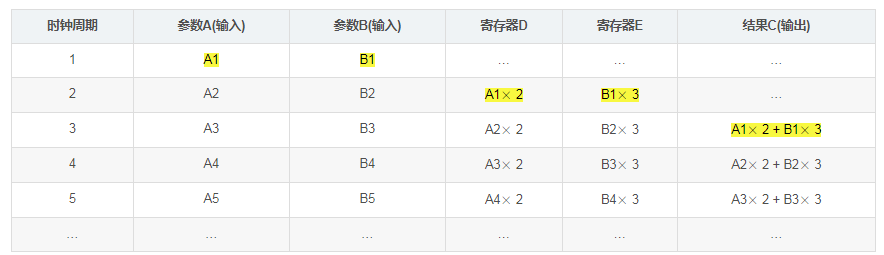
从上表可以看到:
等效地来看,相当于每个时钟周期,模块都完成了一次"C = A × imes× 2 + B × imes× 3"的计算
这种做法明显蕴含了"流水线计算",不过又跟流水线计算的"一条龙"结构似乎不同,这种做法的结构是"树形"的:
对于输入的参数A和B,先是"你算你的,我算我的",分别输出并缓存D和E。然后拿D和E计算得到结果C。
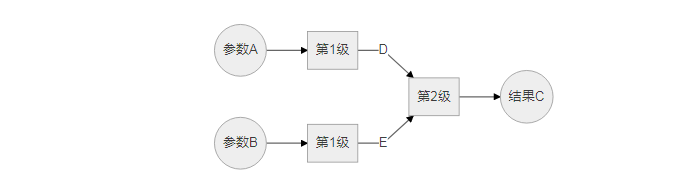
对于这种做法,我称之为"分布式流水线计算",这个名称借鉴了计算机网络领域的术语"分布式计算"。使用分布式流水线计算的必要前提是:
计算所需的输入参数不止一个
分布式流水线计算可以看成是"在输入参数不止一个的情况下,展露出计算细节的流水线计算",或者说,从本质上来讲,分布式流水线计算属于流水线计算,不要因为看上去是树形结构就帮它"自立门户"了。不信?没事,我将上面的"计算C = A × imes× 2 + B × imes× 3"的模块的结构重新画一下你就信了:

既然说"分布式流水线计算属于流水线计算",那为什么还要专门在这里讲分布式流水线计算呢?原因是这样的:分布式流水线计算展露了计算细节,更加有助于逻辑开发人员弄清楚计算过程中的延时情况,防止在不知不觉间,增大了整个计算的延迟时间。比如,对于上面的"C = A × imes× 2 + B × imes× 3",如果不加注意的话,可能会变成这样:
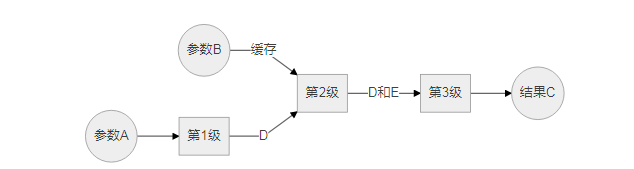
从上图就能看出来,明明两级就能完成的计算,一不留神就变成了三级,整个计算的延迟时间变长了。不过需要说明的是,"整个计算的延迟时间"并不是衡量"一个并行计算结构的优劣"的标准。比如,在做并行卷积计算时,采取流水线的结构可以节省计算资源(但是整个计算的延迟时间长),而采取多相的结构可以缩短整个计算的延迟时间(但是消耗更多的计算资源,虽然其实也多不了太多)。
这里展示一个更加复杂的分布式流水线计算的案例:
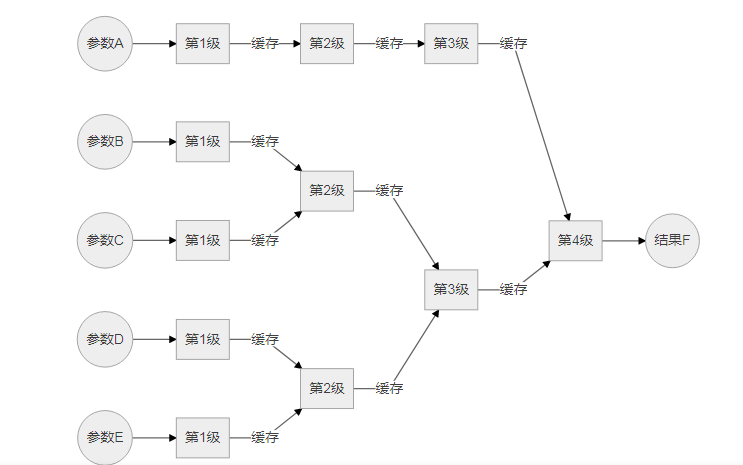
交替计算
现在,我们要在FPGA中做这样一个计算:
C = A + B
能用的计算单元为两输入加法器
为了保证时序,一个时钟周期内加法器只能执行一次加法,时钟频率最高为100MHz
可以用寄存器来存储数据
为了保证时序,寄存器最高只能工作在300MHz的时钟频率下
乍一看,这情况让人有点迷茫:表达式都简单成这样了,还需要玩并行计算?别急,我们的问题是这样的:
A和B都是在300MHz时钟的驱动下刷新的,在这种情况下,如何才能完成"C = A + B"的计算?
呵呵,加法器最高工作频率为100MHz,而数据的刷新频率都飙到300MHz去了,没法玩了好吧!咳咳,其实还是可以玩的。考虑一下这么做:
设计一个模块,模块的输入为300MHz时钟和参数A、参数B,输出为结果C(C为寄存器)。
在300MHz时钟的驱动下:
在第(i+1)个时钟周期将A、B的值分别赋给A1、B1寄存器,
在第(i+2)个时钟周期将A、B的值分别赋给A2、B2寄存器,
在第(i+3)个时钟周期将A、B的值分别赋给A3、B3寄存器,
在第(i+4)个时钟周期将A、B的值分别赋给A1、B1寄存器,
在第(i+5)个时钟周期将A、B的值分别赋给A2、B2寄存器,
模块中,将300MHz的时钟三分频后得到100MHz时钟:clk100m_1,clk100m_2,clk100m_3。
三个100MHz时钟之间的相位都相差(360°/3=)120°。
在100MHz时钟的驱动下(假定分配的100MHz时钟都能满足所需的建立保持时间需求):
使用加法器,在clk100m_1的每个时钟周期计算C1 = A1 + B1,其中,C1为寄存器。
使用加法器,在clk100m_2的每个时钟周期计算C2 = A2 + B2,其中,C2为寄存器。
使用加法器,在clk100m_3的每个时钟周期计算C3 = A3 + B3,其中,C3为寄存器。
在300MHz时钟的驱动下:
在第(k+1)个时钟周期将C1的值赋给C,(其中,k=i+4)
在第(k+2)个时钟周期将C2的值赋给C,
在第(k+3)个时钟周期将C3的值赋给C,
在第(k+4)个时钟周期将C1的值赋给C,
在第(k+5)个时钟周期将C2的值赋给C,
上述模块的时序如下图所示:
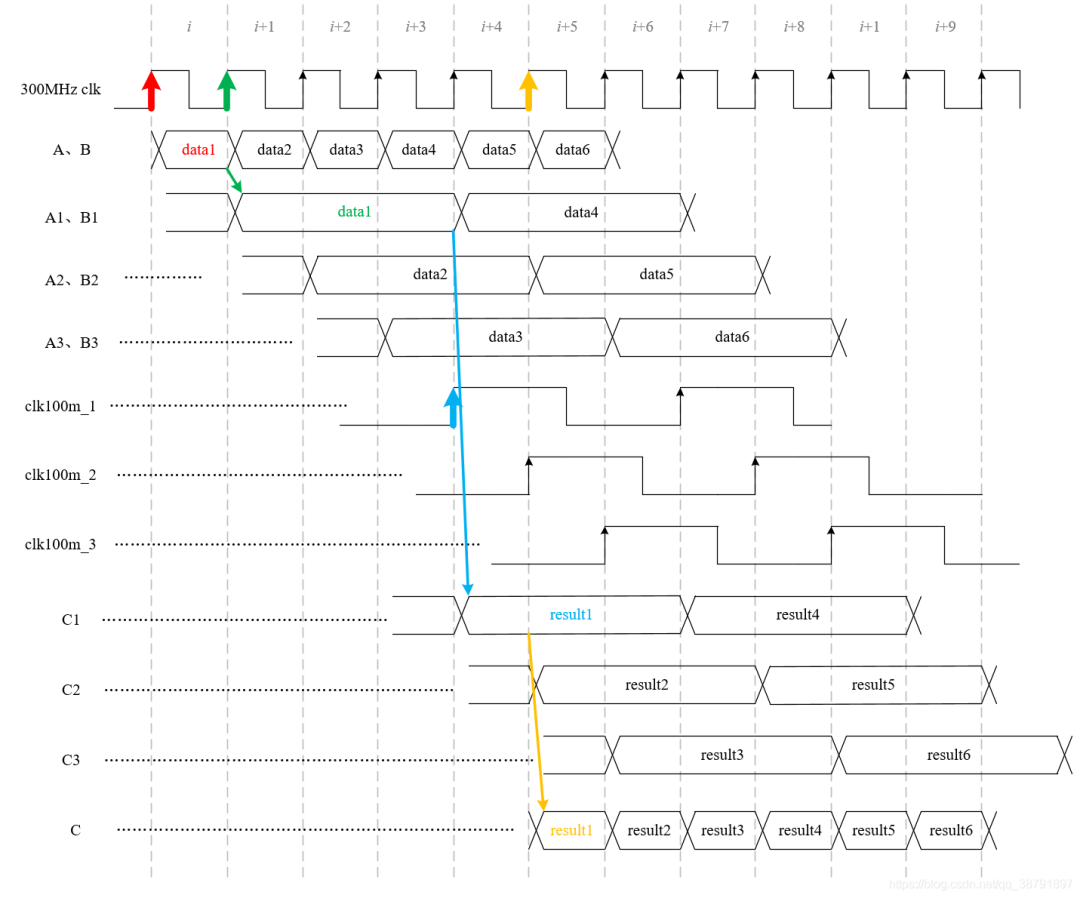
从上图可以看到:
加法器都工作在100MHz的时钟下
A、B、C的刷新频率都是300MHz
可见,我们利用3个最高工作频率100MHz的加法器,等效地实现了1个最高工作频率300MHz的加法器。
这里所采用的方法通常被称为是"乒乓计算"(或者"乒乓操作"),不过,窃以为这个名称不够形象,因此,为这种方法取了个新名称:“交替计算”。交替计算的基本思想是:
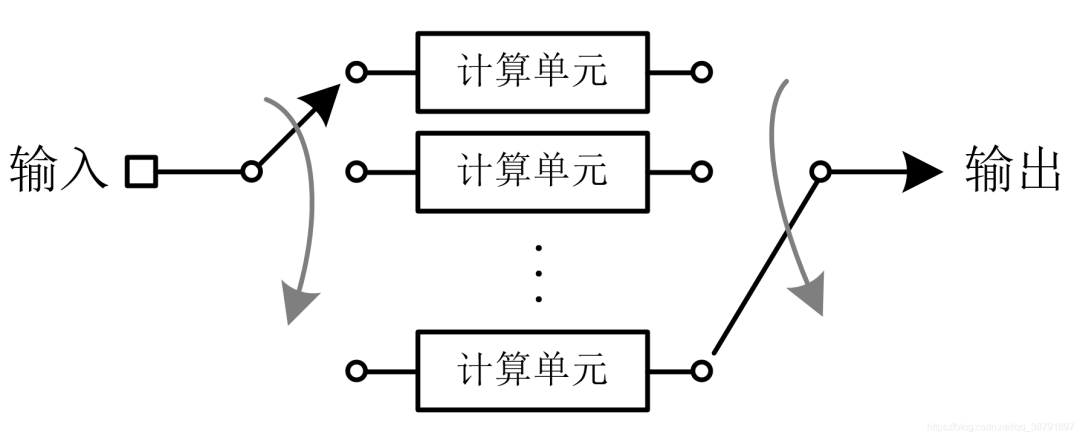
将计算单元复制若干份,交替地将输入的参数分配给各个计算单元,并且交替地将各个计算单元的计算结果输出,从而实现"以N倍的计算单元换取N倍的计算速度"。
交替计算的基本结构如下图所示:
混合型并行计算
在实际的FPGA并行计算中,常常将流水线计算、交替计算混合使用,来满足计算需求。嗯,这就是所谓的"混合型并行计算",没毛病。
用一句话将本论述归纳总结一下,那就是:
FPGA中并行计算的基本常规方法为:流水线计算和交替计算。
原文标题:FPGA学习-FPGA中并行计算的常规方法
文章出处:【微信公众号:FPGA设计论坛】欢迎添加关注!文章转载请注明出处。
审核编辑:汤梓红
-
基于FPGA并行计算的图像处理案例2020-11-04 5028
-
arm系统中并行计算优化2015-12-30 8477
-
FPGA中的流水线设计2020-10-26 3313
-
什么是异构并行计算2021-07-19 2328
-
现代RISC中的流水线技术2023-03-01 989
-
基于流水线技术的并行高效FIR滤波器设计2009-03-28 1073
-
流水线中的相关培训教程[3]2010-04-13 1118
-
并行计算和嵌入式系统实践教程2011-05-09 985
-
并行计算和分布式计算的区别和联系2017-12-08 38586
-
基于云计算的电磁问题并行计算方法2018-03-20 1118
-
并行计算的黄金时代到了?2020-04-03 3084
-
浅析云计算和并行计算2020-05-03 5579
-
CRC校验码并行计算的FPGA实现2021-03-28 1949
-
什么是流水线 Jenkins的流水线详解2023-05-17 1847
-
Google GPipe为代表的流水线并行范式2023-05-26 2247
全部0条评论

快来发表一下你的评论吧 !
