

使用PyTorch Lightning构建语音模型和解决方案
描述
人工智能正在推动第四次工业革命,其机器可以在超人的水平上听到、看到、理解、分析,然后做出明智的决定。然而,人工智能的有效性取决于基础模型的质量。因此,无论您是学术研究人员还是数据科学家,您都希望使用各种参数快速构建模型,并确定最有效的解决方案。
在这篇文章中,我们将引导您在 GPU NVIDIA 供电的 AWS 实例上使用 PyTorch Lightning构建语音模型。
PyTorch Lightning + Grid.ai :以更快的速度按比例构建模型
NGC 目录 Lightning 是用于高性能 AI 研究的轻量级 PyTorch 包装。使用 Lightning 组织 PyTorch 代码可以在多个 GPU 和 TPU CPU 上进行无缝培训,并使用难以实施的最佳实践,如检查点、日志记录、分片和混合精度。 PyTorch 上提供了 PyTorch Lightning 容器和开发人员环境。
网格使您能够将培训从笔记本电脑扩展到云端,而无需修改代码。 Grid 在 AWS 等云提供商上运行,支持 Lightning 以及 Sci 工具包、 TensorFlow 、 Keras 、 PyTorch 等所有经典机器学习框架。使用 Grid ,可以缩放 NGC 目录中模型的训练。
NGC : GPU 优化 AI 软件的中心
NGC 目录是 GPU 优化软件(包括AI / ML 容器、预训练模型和 SDK )的中心,这些软件可以轻松部署到内部部署、云、边缘和混合环境中。 NGC 提供 NVIDIA TAO 工具套件,可使用自定义数据和 NVIDIA Triton 推理服务器对模型进行再培训,以便在 CPU 和 GPU 供电系统上运行预测。
本文的其余部分将指导您如何利用NGC 目录中的模型和 NVIDIA NeMo 框架,在 PyTorch 教程的基础上,使用以下tutorial使用带 NeMo 的 ASR Lightning 训练自动语音识别( ASR )模型。
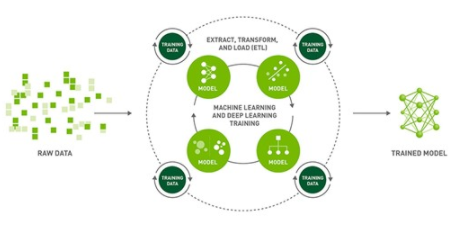
图 1 。人工智能模型训练过程
通过网格课程培训 NGC 模型, PyTorch Lightning 和 NVIDIA NeMo
ASR 是将口语转录成文本的任务,是语音 – 文本系统的关键组成部分。在训练 ASR 模型时,您的目标是从给定的音频输入中生成文本,以最小化人类转录语音的单词错误率( WER )度量。 NGC 目录包含 ASR 最先进的预训练模型。
在本文的其余部分中,我们将向您展示如何使用网格会话 NVIDIA NeMo 和 PyTorch Lightning 在AN4 数据集上对这些模型进行微调。
AN4 数据集,也称为字母数字数据集,由卡内基梅隆大学收集和发布。它包括人们拼写地址、姓名、电话号码等的录音,一次一个字母或号码,以及相应的成绩单。
步骤 1 :创建针对 Lightning 和预训练 NGC 模型优化的网格会话
网格会话运行在需要扩展的相同硬件上,同时为您提供预配置的环境,以比以前更快地迭代机器学习过程的研究阶段。会话链接到 GitHub ,使用 JupyterHub 加载,可以通过 SSH 和您选择的 IDE 进行访问,而无需自己进行任何设置。
对于会话,您只需支付使基线运行所需的计算费用,然后您就可以通过网格运行将工作扩展到云。网格会话针对托管在 NGC 目录上的 PyTorch Lightning 和模型进行了优化。他们甚至提供专门的现货定价。

图 2 。创建网格会话的工作流
步骤 2 :克隆 ASR 演示报告并打开教程笔记本
现在您有了一个针对 PyTorch Lightning 优化的开发人员环境,下一步是克隆 NGC Lightning Grid Workshop repo 。
您可以使用以下命令直接从网格会话中的终端执行此操作:
git clone https://github.com/aribornstein/NGC-Lightning-Grid-Workshop.git
克隆 repo 后,可以打开笔记本,使用 NeMo 和 PyTorch Lightning 对 NGC 托管模型进行微调。
步骤 3 :安装 NeMo ASR 依赖项
首先,安装所有会话依赖项。运行 PyTorch Lightning 和 NeMo 等工具,并处理 AN4 数据集以完成此操作。运行教程笔记本中的第一个单元格,该单元格运行以下 bash 命令来安装依赖项。
## Install dependencies !pip install wget !sudo apt-get install sox libsndfile1 ffmpeg -y !pip install unidecode !pip install matplotlib>=3.3.2 ## Install NeMo BRANCH = 'main' !python -m pip install --user git+https://github.com/NVIDIA/NeMo.git@$BRANCH#egg=nemo_toolkit[all] ## Grab the config we'll use in this example !mkdir configs !wget -P configs/ https://raw.githubusercontent.com/NVIDIA/NeMo/$BRANCH/examples/asr/conf/config.yaml
步骤 4 :转换并可视化 AN4 数据集
AN4 数据集以原始 Sof 音频文件的形式提供,但大多数模型在mel p 频谱图上处理。请将 Sof 文件转换为 Wav 格式,以便使用 NeMo 音频处理。
import librosa
import IPython.display as ipd
import glob
import os
import subprocess
import tarfile
import wget
# Download the dataset. This will take a few moments...
print("******")
if not os.path.exists(data_dir + '/an4_sphere.tar.gz'):
an4_url = 'http://www.speech.cs.cmu.edu/databases/an4/an4_sphere.tar.gz'
an4_path = wget.download(an4_url, data_dir)
print(f"Dataset downloaded at: {an4_path}")
else:
print("Tarfile already exists.")
an4_path = data_dir + '/an4_sphere.tar.gz'
if not os.path.exists(data_dir + '/an4/'):
# Untar and convert .sph to .wav (using sox)
tar = tarfile.open(an4_path)
tar.extractall(path=data_dir)
print("Converting .sph to .wav...")
sph_list = glob.glob(data_dir + '/an4/**/*.sph', recursive=True)
for sph_path in sph_list:
wav_path = sph_path[:-4] + '.wav'
cmd = ["sox", sph_path, wav_path]
subprocess.run(cmd)
print("Finished conversion.
******")
# Load and listen to the audio file
example_file = data_dir + '/an4/wav/an4_clstk/mgah/cen2-mgah-b.wav'
audio, sample_rate = librosa.load(example_file)
ipd.Audio(example_file, rate=sample_rate)
然后,您可以将音频示例可视化为音频波形的图像。图 3 显示了与音频中每个字母对应的波形中的活动,正如您的扬声器在这里非常清楚地阐明的那样!
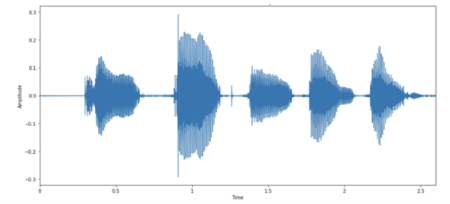
图 3 示例的音频波形
每个口语字母都有不同的“形状”。有趣的是,最后两个字母看起来相对相似,这是因为它们都是字母 N 。
频谱图
在声音频率随时间变化的情况下,音频建模更容易。您可以得到比 57330 个值的原始序列更好的表示。 频谱图是一种很好的可视化音频中各种频率强度随时间变化的方式。它是通过将信号分成更小的、通常重叠的块,并对每个块执行短时傅立叶变换( STFT )来获得的。
图 4 显示了样本的频谱图 的外观。
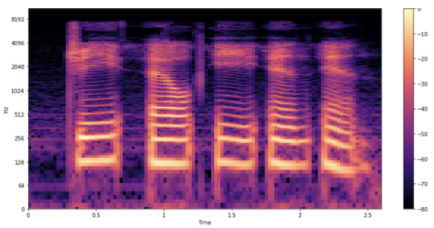
图 4 示例的音频谱图
与前面的波形一样,您可以看到每个字母的发音。你如何解释这些形状和颜色?与前面的波形图一样,您可以看到时间在 x 轴上流逝(所有 2 。 6 秒的音频)。但是,现在 y 轴表示不同的频率(对数刻度),并且图上的颜色显示特定时间点的频率强度。
Mel 频谱图
您仍然没有完成,因为您可以通过使用 mel 频谱图可视化数据来进行一个更可能有用的调整。将频率比例从线性(或对数)更改为 mel 比例,这样可以更好地表示人耳可感知的音调。 Mel 频谱图直观上对 ASR 有用。因为您正在处理和转录人类语音,所以 mel 频谱图可以减少可能影响模型的背景噪声。
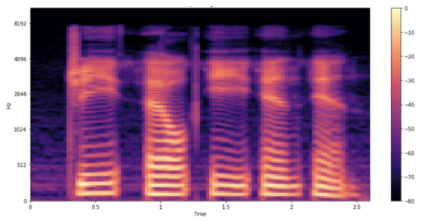
图 5 示例的 Mel spe CTR 图
步骤 5 :从 NGC 加载并推断预训练的 QuartzNet 模型
既然您已经加载并正确理解了 AN4 数据集,那么看看如何使用 NGC 加载一个 ASR 模型,以便使用 PyTorch Lightning 进行微调。 NeMo 的 ASR 集合包含许多构建块,甚至完整的模型,您可以使用它们进行培训和评估。此外,有几种型号带有预训练重量。
要为这篇文章建模数据,可以使用名为来自 NGC 模型中心的 QuartzNet的 Jasper 体系结构。 Jasper 体系结构由重复的块结构组成,这些块结构使用 1D 卷积对 spe CTR 图形数据建模(图 6 )。
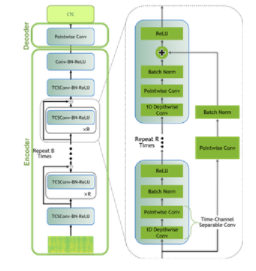
图 6 Jasper / QuartzNet 模型
QuartzNet 是 Jasper 的一个更好的变体,关键区别在于它使用时间通道可分离的一维卷积。这使得它能够在保持类似精度的同时大幅减少权重的数量。
下面的命令从 NGC 目录下载预训练的 QuartzNet15x5 模型,并为您实例化它.
tgmuartznet = nemo_asr.models.EncDecCTCModel.from_pretrained(model_name="QuartzNet15x5Base-En")
步骤 6 :使用 Lightning 微调模型
当您拥有一个模型时,您可以使用 PyTorch Lightning 对其进行微调,如下所示。
import pytorch_lightning as pl from omegaconf import DictConfig trainer = pl.Trainer(gpus=1, max_epochs=10) params['model']['train_ds']['manifest_filepath'] = train_manifest params['model']['validation_ds']['manifest_filepath'] = test_manifest first_asr_model = nemo_asr.models.EncDecCTCModel(cfg=DictConfig(params['model']), trainer=trainer) # Start training!!! trainer.fit(first_asr_model)
因为您使用的是 Lightning Trainer ,所以您获得了一些关键优势,例如默认情况下的模型检查点和日志记录。您还可以使用 50 +种最佳实践策略,而无需修改模型代码,包括多 GPU 训练、模型切分、深度速度、量化感知训练、提前停止、混合精度、渐变剪裁和分析。

图 7 微调策略
步骤 7 :推断和部署
既然您有了一个基线模型,那么就推断它。
图 9 运行推断
步骤 8 :暂停会话
现在您已经训练了模型,您可以暂停会话,并保存您需要的所有文件。
图 9 监视网格会话
暂停的会话是免费的,可以根据需要恢复。
结论
现在,您应该对 PyTorch Lightning 、 NGC 和 Grid 有了更好的了解。您已经对第一个 NGC NeMo 模型进行了微调,并通过网格运行对其进行了优化。我们很高兴看到您下一步如何使用 Grid 和 NGC。
关于作者
Ari Bornstein 是一名人工智能研究人员,他热爱历史、新技术和计算医学。作为 Grid 。 ai 的开发人员宣传负责人,他与机器学习社区合作,利用改变游戏规则的技术解决现实世界中的问题,这些技术随后被记录在案、开源并与世界其他地方共享。
Chintan Patel是NVIDIA的高级产品经理,致力于将GPU加速的解决方案引入HPC社区。 他负责NVIDIA GPU Cloud注册表中HPC应用程序容器的管理和提供。 在加入NVIDIA之前,他曾在Micrel,Inc.担任产品管理,市场营销和工程职位。他拥有圣塔克拉拉大学的MBA学位以及UC Berkeley的电气工程和计算机科学学士学位。
Shokoufeh Monejzi Kouchak 是 NVIDIA 的技术营销工程师,专注于深度学习模型。肖库菲从亚利桑那州国家大学获得了计算机工程学博士学位,她把重点放在驾驶行为分析和驾驶员注意力检测上,并用深度学习模型。
审核编辑:郭婷
-
PyTorch 中RuntimeError分析2026-03-06 1216
-
Pytorch模型训练实用PDF教程【中文】2018-12-21 5203
-
Pytorch AI语音助手2022-03-06 32172
-
将pytorch模型转化为onxx模型的步骤有哪些2022-05-09 3636
-
怎样使用PyTorch Hub去加载YOLOv5模型2022-07-22 3575
-
通过Cortex来非常方便的部署PyTorch模型2022-11-01 2448
-
将Pytorch模型转换为DeepViewRT模型时出错怎么解决?2023-06-09 895
-
pytorch模型转换需要注意的事项有哪些?2023-09-18 716
-
pytorch如何构建网络模型2023-07-20 654
-
基于PyTorch AMD的解决方案2023-09-04 2285
-
物联网的构建模块:构建物联网的技术和解决方案2023-11-22 517
-
如何使用PyTorch建立网络模型2024-07-02 1618
-
解读PyTorch模型训练过程2024-07-03 2894
-
PyTorch神经网络模型构建过程2024-07-10 1887
-
pytorch中有神经网络模型吗2024-07-11 3694
全部0条评论

快来发表一下你的评论吧 !
