

使用NVIDIA TAO工具包和Appen实现AI模型微调
描述
从头开始构建人工智能模型需要大量的数据、时间、金钱和专业知识。这与在人工智能领域取得成功的条件不符:快速上市,以及快速发展和定制解决方案的能力。 NVIDIA TAO 是一个人工智能模型调整框架,与从头开始的培训相比,它可以让您利用生产质量、预培训的人工智能模型,并在很短的时间内对其进行微调。
要进一步微调这些模型,或确认模型的精度,需要额外的高质量训练数据。 Appen 是 TAO 的数据注释合作伙伴,如果您没有合适的可用数据,它可以访问高质量的数据集和服务,为您的数据添加标签和注释,以满足您的独特需求。
在帖子中,我将向你展示如何使用 NVIDIA TAO 工具包 一个基于 CLI 的NVIDIA TAO 框架的解决方案,以及 AppEN 的数据标记平台,以简化整个培训过程,并为特定用例创建高度定制的模型。
在您的团队确定了要使用 ML 解决的业务问题后,您可以从 NVIDIA 收集的计算机视觉和对话人工智能中的预训练人工智能模型中进行选择。计算机视觉模型可以包括人脸检测模型、文本识别、分割等。然后,您可以应用 TAO 工具包来构建、培训、测试和部署您的解决方案。
为了加快数据收集和扩充过程,您现在可以使用 Appen 数据注释平台为您的用例创建正确的培训数据。该强大的平台使您能够访问 Appen 全球超过 100 万名熟练的注释员,他们来自 170 多个国家,讲 235 种语言。 Appen 的数据注释平台 和专业知识还为您提供了其他资源:
高质量数据集(用于需要数据时)
全球采购的人工标签机,用于为未标记的数据添加注释
一个易于使用的平台,您可以在其中启动注释作业并监控关键指标
质量保证检查和数据安全控制
有了干净、高质量的数据,您可以调整 经过训练的 NVIDIA 模型 以满足您的需求,并进行修剪和再培训,以达到所需的性能水平。
如何使用 Appen 的平台准备数据
如果您还没有用于训练模型的数据,您可以自己收集这些数据,也可以求助于 Appen ,找到适合您的用例的源数据集。 Appen 数据注释平台( ADAP )可使用多种格式:
音频(. wav ,. mp3 )
图像(. jpeg ,. png )
文本(. txt )
视频(网址)
完成数据收集阶段后,除非您计划与 Appen 合作以满足数据收集需求,否则您可以使用 Appen 的平台快速标记您收集的数据。每行数据批注都需要 Appen 平台许可证和预算。
在此基础上,完成以下步骤,部署一个特别适合您需求的模型。在本文中,假设您正在为对象检测模型注释图像。
准备好你的数据
首先,将图像数据加载到网络可访问的位置:云或 ADAP 可以访问的位置,例如私有 Amazon S3 存储桶。
接下来,用两列结构输入 CSV 文件。第一列包含文件名,第二列包含图像的 URL 。您可以通过以下三种方式之一提供 URL :
对数据使用公开可用的 URL 。
使用预先签名的 URL 。
使用 Appen 的安全数据访问工具,您可以使用该工具将数据库安全地连接到平台; Appen 仅在需要时访问您的数据。
第二列包含设备上的本地文件名。图 1 显示了 CSV 文件的外观。
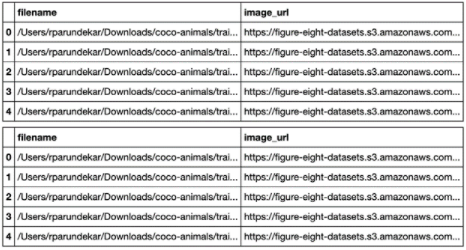
图 1 。用于 ADAP 中数据上传的 CSV 结构
创建作业并上载数据
如果尚未登录,可以 创建 ADAP 帐户 并登录。在运行新作业之前,您必须拥有平台的活动许可证。要了解更多有关计划和定价的信息, 联系 Appen 。
登录后,在Jobs下选择创造就业机会。
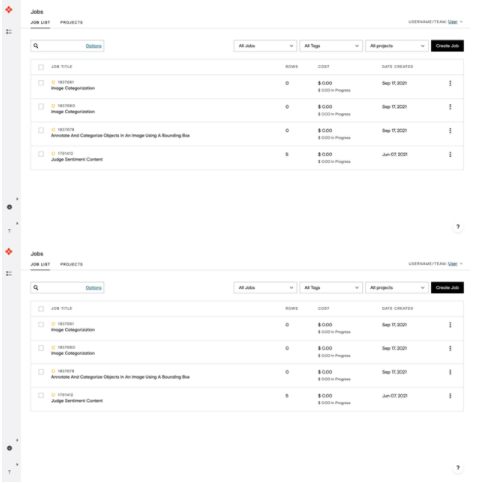
图 2 。 ADAP 工作概述页面
选择最适合工作的模板(情绪分析、搜索相关性等)。对于本例,请选择Image Annotation。
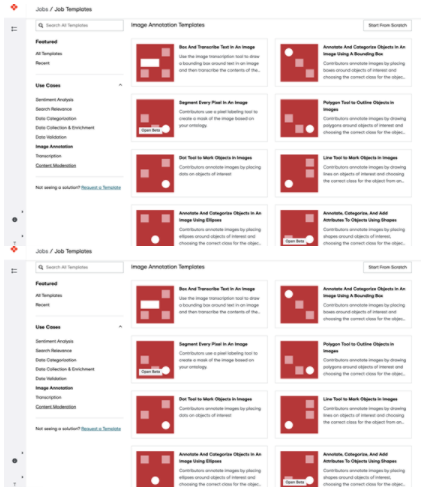
图 3 。 ADAP 作业模板页面–图像注释
在Image Annotation下,选择使用边界框对图像中的对象进行注释和分类。将 CSV 文件拖放到Upload选项卡中,上传 CSV 文件。
设计你的工作
为 Appen 的 100 多万名数据标签员提供指导,说明他们应该寻找什么,以及他们应该知道的任何要求。该模板提供了一个简单的工作设计来帮助您开始。
接下来,选择管理图像注释本体,在这里定义应该检测的类。更新说明,以提供有关用例的更多上下文,并描述注释者应如何识别和标记图像中的对象。您可以预览作业,并查看注释员将如何查看它。
最后,创建测试问题来测量和跟踪贴标机的性能。
启动作业
在平台上正式启动注释作业之前,先进行测试运行。在你开始工作后, Appen 的全球数据标签员会根据你的规格标注你的数据。
班长
实时监控注释的准确率。在工作设计、试题或注释员等领域根据需要进行调整。
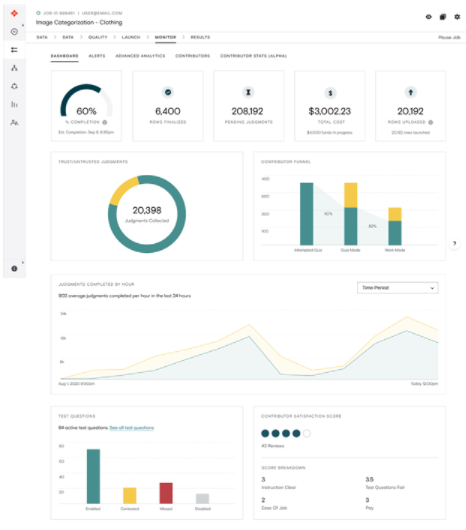
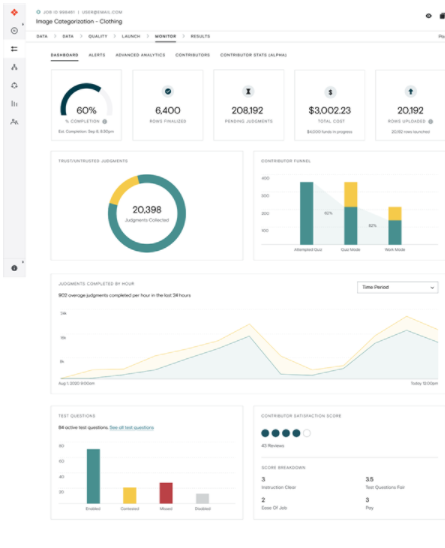
图 8 。 ADAP 注释进度监控页面
后果
选择Download、Full下载标签数据输出的报告。
将输出转换为 KITTI 格式
从这里开始,您需要一个脚本来将标记的数据转换为可供 TAO 工具包使用的格式,例如 KITTI 格式。
使用上一步的输出,可以使用以下部分将标记的数据转换为类似 Pascal Visual Object Class ( VOC )格式的格式。
训练你的模特
用 Appen 注释的数据现在可以用于训练对象检测模型。 TAO 工具包允许您根据数据调整流行的网络架构和主干,从而训练、微调、删减和导出高度优化和精确的人工智能模型,以供部署。对于本例,您可以选择 YOLOV3 对象检测模型,如下例所示:
$ wget --content-disposition https://api.ngc.nvidia.com/v2/resources/nvidia/tlt_cv_samples/versions/v1.0.2/zip -O tlt_cv_samples_v1.0.2.zip $ unzip -u tlt_cv_samples_v1.0.2.zip -d ./tlt_cv_samples_v1.0.2 && rm -rf tlt_cv_samples_v1.0.2.zip && cd ./tlt_cv_samples_v1.0.2
下载笔记本示例后,您可以使用以下命令启动笔记本:
$ jupyter notebook --ip 0.0.0.0 --port 8888 --allow-root
在 localhost 上打开 internet 浏览器并打开以下 URL :
http://0.0.0.0:8888
因为您正在创建一个 YOLOv3 模型,所以打开 yolo _ v3 / yolo _ v3 。 ipynb 笔记本。按照笔记本上的说明训练模型。
根据结果,微调模型,直到达到度量目标。如果需要,您可以在此阶段创建自己的主动学习循环。根据置信度或其他选择指标,使用 CSV 文件方法对数据进行优先级排序,如前面步骤所述。您还可以提前加载数据(包括输入和预测),这样 Appen 的注释员可以在模型经过培训后验证模型,并使用我们的领域专家和 open crowd 查看预测。
Pro tip:使用 Appen 解决方案 Workflows 轻松构建和自动化多步骤数据注释项目。
迭代
随着您不断提高模型性能, Appen 可以在后续的模型培训中进一步帮助您进行数据收集和注释。为了避免模型漂移或适应不断变化的业务需求,请定期对模型进行再培训。
结论
NVIDIA TAO 工具包与 Appen 的数据平台相结合,使您能够训练、微调和优化预训练模型,以更快地启动人工智能解决方案。在不牺牲质量的情况下,将开发时间缩短十倍。在NVIDIA 和 Appen 的综合专业知识和工具的帮助下,您将满怀信心地推出人工智能。
关于作者
Titus Capilnean 领导 Appen 的营销传播,推动负责任、包容的人工智能,并与全球公司进行培训数据对话。他拥有 2016 年的机器学习证书、霍尔特国际商学院( Hult International Business School )的行政 MBA 学位,并在 Forbes 上发表了几篇关于人工智能的评论文章。
审核编辑:郭婷
-
MediaTek与NVIDIA TAO加速物联网边缘AI应用发展2024-06-12 1166
-
Edge Impulse发布新工具,助 NVIDIA 模型大规模部署2024-03-25 1777
-
使用 NVIDIA TAO Toolkit 5.0 体验最新的视觉 AI 模型开发工作流程2023-07-31 3778
-
GTC23 | 使用 NVIDIA TAO Toolkit 5.0 体验最新的视觉 AI 模型开发工作流程2023-03-29 2151
-
LabVIEW开放神经网络交互工具包【ONNX】,大幅降低人工智能开发门槛,实现飞速推理2023-03-17 4031
-
使用 NVIDIA TAO 工具套件和预训练模型加快 AI 开发2022-12-15 2284
-
使用最新的TAO工具包简化AI模型开发2022-06-21 2469
-
基于TAO人工智能模型调整平台应对NVIDIA训练挑战2022-04-10 1753
-
利用TAO工具包加速AI工作流过程的方法2022-04-08 1755
-
使用NVIDIA TAO工具包构建对话AI和应用程序2022-04-01 2939
-
STM32Cube.AI工具包使用初探2022-02-22 1208
-
利用NVIDIA TAO Toolkit 和 Deep stream 快速搭建车辆信息识别系统2021-12-15 3165
-
什么是TAO和TAO工具套件2021-09-05 4183
-
NI LabVIEW 模型接口工具包2015-02-15 9725
全部0条评论

快来发表一下你的评论吧 !
