

使用NVIDIA DALI加速医学图像处理
描述
深度学习模型需要大量数据才能产生准确的预测,随着模型规模和复杂性的增加,这种需求日益迫切。即使是大型数据集,例如拥有 100 多万张图像的著名 ImageNet ,也不足以在现代计算机视觉任务中实现最先进的结果。
为此,需要使用数据增强技术,通过对数据引入随机干扰(如几何变形、颜色变换、噪声添加等),人为地增加数据集的大小。这些干扰有助于生成预测更稳健的模型,避免过度拟合,并提供更好的精度。
在医学成像任务中,数据扩充至关重要,因为数据集最多只包含数百或数千个样本。另一方面,模型往往会产生需要大量 GPU 内存的大激活,特别是在处理 CT 和 MRI 扫描等体积数据时。这通常会导致在小数据集上进行小批量的培训。为了避免过度拟合,需要更精细的数据预处理和扩充技术。
然而,预处理通常对系统的整体性能有重大影响。这在处理大输入的应用程序中尤其如此,例如体积图像。由于 NumPy 等库的简单性、灵活性和可用性,这些预处理任务通常在 CPU 上运行。
在某些应用中,例如医学图像的分割或检测,由于数据预处理通常在 CPU 中执行,因此训练期间的 GPU 利用率通常不理想。解决方案之一是尝试完全重叠数据处理和训练,但并不总是那么简单。
这样的性能瓶颈导致了鸡和蛋的问题。由于性能原因,研究人员避免在他们的模型中引入更高级的增强,并且由于采用率较低,库不会将精力放在优化预处理原语上。
GPU 加速解决方案
通过将数据预处理卸载到 GPU ,可以显著提高具有大量数据预处理管道的应用程序的性能。 GPU 在此类场景中通常未得到充分利用,但可用于完成 CPU 无法及时完成的工作。其结果是更好的硬件利用率,最终更快的培训。
就在最近, NVIDIA 在 MICCAI 2021 脑肿瘤分割挑战中获得 10 个顶级排名中的 3 个 ,包括获胜的解决方案。获胜的解决方案通过加快系统的 preprocessing pipeline 速度,使 GPU 利用率高达 98% ,并将总训练时间减少了约 5% ( 30 分钟)(图 1 )。
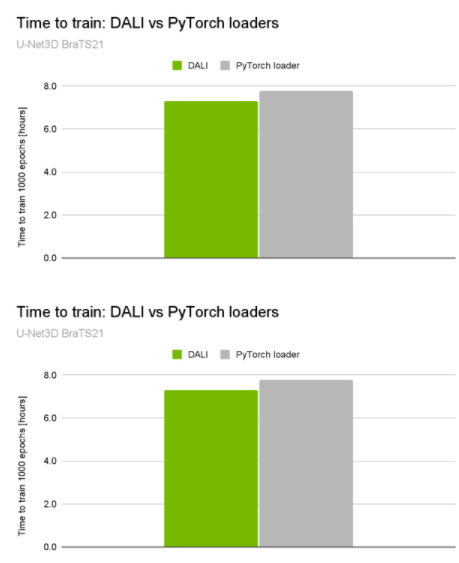
图 1 。 U-Net3D BraTS21 训练性能比较
当你查看NVIDIA 提交的[VZX333 ]时,这种差异变得更加显著。它使用了与BraTS21获奖解决方案相同的网络体系结构,但具有更复杂的数据加载管道和更大的输入量(KITS19数据集)。与本机管道相比,性能提升是令人印象深刻的2倍端到端培训加速(图2)。
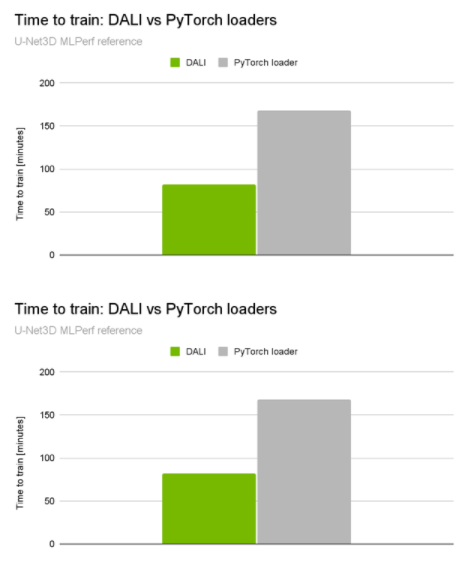
图 2 。 U-Net3D MLPerf 训练 1.1 训练性能比较
这是由 NVIDIA 数据加载库( DALI ) 实现的。 DALI 提供了一组 GPU 加速构建块,使您能够构建完整的数据处理管道,包括数据加载、解码和扩充,并将其与所选的深度学习框架集成(图 3 )。
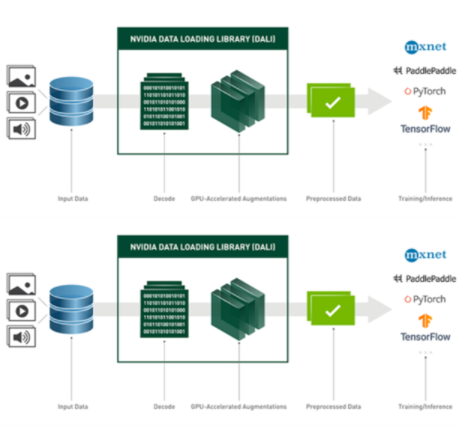
图 3 。 DALI 概述及其应用 在 DL 应用程序中用作加速数据加载和预处理的工具
体积图像操作
最初, DALI 是作为图像分类和检测工作流的解决方案开发的。后来,它被扩展到其他数据域,如音频、视频或体积图像。有关体积数据处理的更多信息,请参阅 3D Transforms 或 NumPy 读卡器 .
DALI 支持多种图像处理操作员。有些还可以应用于体积图像。以下是一些值得一提的例子:
Resize
Warp affine
Rotate
随机对象边界框
为了展示上述的一些操作,我们使用了来自 BraTS19 数据集的一个样本,该样本由标记为脑肿瘤分割的 MRI 扫描组成。图 4 显示了从脑 MRI 扫描体积中提取的二维切片,其中较暗的区域表示标记为异常的区域。
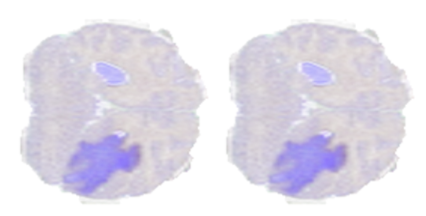
图 4 。来自 BraTS19 数据集样本的切片
调整大小运算符
Resize通过插值输入像素将图像放大或缩小到所需形状。可以分别为每个维度配置“高比例”或“低比例”,包括选择插值方法。
Warp affine通过线性变换将像素坐标从源映射到目标,应用几何变换。
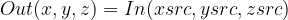
Warp affine可用于一次性执行多个变换(旋转、翻转、剪切、缩放)。
旋转运算符
Rotate允许您绕任意轴旋转体积,该轴作为矢量和角度提供。它还可以选择性地扩展画布,使整个旋转图像包含在其中。
随机对象边界框操作符
随机对象边界框是一种适合于检测和分段任务的运算符。如前所述,医疗数据集往往相当小,目标类别(如异常)占据的区域相对较小。此外,在许多情况下,输入容量远大于网络预期的容量。如果要使用随机裁剪窗口进行训练,则大多数窗口不会包含目标。这可能导致训练收敛速度减慢或使网络偏向假阴性结果。
此运算符选择可能偏向于对特定标签采样的伪随机作物。连接组件分析是在标签图上执行的一个预步骤。然后,以相同的概率随机选择一个连接的 blob 。通过这样做,操作符可以避免过度呈现较大的斑点。
您还可以选择将选择限制为最大的 K 个 blob 或指定最小 blob 大小。选择特定 blob 时,将在包含给定 blob 的范围内生成随机裁剪窗口。图 8 显示了这个裁剪窗口选择过程。
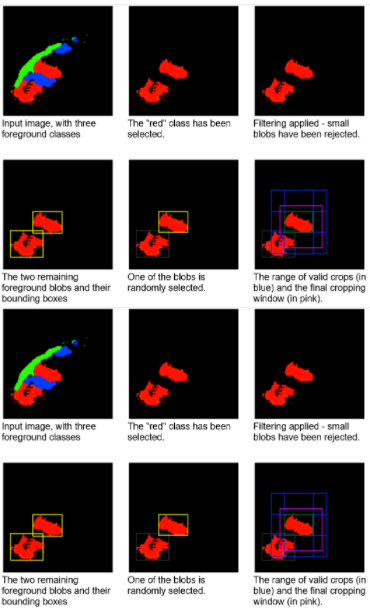
图 8 。想象 the随机对象边界框对具有一组属于三个不同类别(每个类别用不同颜色高亮显示)的对象的人造 2D 图像的操作
学习速度的提高是非常显著的。在 KITS19 数据集上, nnU Net 在使用随机对象边界框运算符的测试运行时段中, 2134 达到与 3222 个随机裁剪时段相同的精度。
通常,查找连接组件的过程很慢,但数据集中的样本数可能很小。操作员可以配置为缓存连接的组件信息,以便仅在培训的第一个历元中计算。
关于作者
Janusz Lisiecki 是 NVIDIA 的深度学习经理,致力于快速数据管道。他过去的经验涵盖从面向大众消费市场的嵌入式系统到高性能硬件软件数据处理解决方案。
Joaquin Anton Guirao 是 NVIDIA 深度学习框架团队的高级软件工程师,专注于 NVIDIA DALI
Pablo Ribalta 是 NVIDIA 的深度学习算法经理,致力于 2D 和体积数据的基于图像的模型。他的研究经验包括启发式、元启发式、优化以及深度学习的不同应用,如医学和卫星图像。
Michal Futrega 是 NVIDIA 的软件工程师,致力于医学图像分割的神经网络和药物发现的图形神经网络。他获得了华沙大学理学硕士学位和计算机科学理学士学位。
Michał Marcinkiewicz 是 NVIDIA 深度学习软件组的高级 CUDA 算法工程师,专注于医学图像分析的计算机视觉。米莎从法国蒙彼利埃大学获得博士学位,从事拓扑相变研究。获得博士学位后,他完全转向机器学习。
审核编辑:郭婷
-
图像处理2013-05-19 0
-
求基于sift的医学图像处理的matlab程序,有偿!2018-05-22 0
-
深度学习在医学图像分割与病变识别中的应用实战2023-09-04 0
-
国内医学图像处理技术的最新动态2008-11-17 1104
-
生物信号和生物医学的图像处理:以Matlab为基础的应用程序2009-02-17 1061
-
一种基于二维离散小波变换的医学图像增强算法2010-02-22 695
-
DSP的医学图像2010-03-30 410
-
基于MFC编程的图像处理在核医学中的应用_付兴建2017-03-17 672
-
基于GPU加速的医学图像配准技术2018-01-03 1026
-
基于FPGA的HEIF图像处理加速方案2020-10-23 2546
-
NVIDIA DALI概述及主要特性2022-08-03 2733
-
NVIDIA Clara Holoscan 助力微识医疗加速消化内镜 AI 应用产品化2022-12-01 664
-
CTAccel图像处理(CIP)加速器2023-09-15 266
-
NVIDIA 知乎精彩问答甄选 | 分享 NVIDIA 助力医学研究的相关精彩问答2023-11-24 579
-
卷积神经网络在图像和医学诊断中的优势2024-07-01 1285
全部0条评论

快来发表一下你的评论吧 !
