

利用NVIDIA DALI为加速数据管道提供性能和灵活性
描述
深度学习模型需要使用大量数据进行培训,以获得准确的结果。由于各种原因,例如不同的存储格式、压缩、数据格式和大小,以及高质量数据的数量有限,原始数据通常无法直接输入神经网络。
解决这些问题需要大量的数据准备和预处理步骤,从加载、解码、解压缩到调整大小、格式转换和各种数据扩充。
深度学习框架,如 TensorFlow 、 PyTorch 、 MXNet 等,为一些预处理步骤提供了本地实现。由于使用特定于框架的数据格式、转换的可用性以及不同框架之间的实现差异,这通常会带来可移植性问题。
CPU 瓶颈
直到最近,深度学习工作负载的数据预处理才引起人们的关注,因为训练复杂模型所需的巨大计算资源使其黯然失色。因此,由于 OpenCV 、 Pillow 或 Librosa 等库的简单性、灵活性和可用性,预处理任务通常用于在 CPU 上运行。
NVIDIA 伏特和 NVIDIA 安培体系结构中引入的 GPU 体系结构的最新进展显著提高了深度学习任务中的 GPU 吞吐量。特别是,半精度算法与张量核加速某些类型的 FP16 矩阵计算,这对培训DNNs非常有用。密集的多 GPU 系统,如 NVIDIA DGX-2和DGX A100训练模型的速度远远快于输入管道提供的数据,使 GPU 缺少数据。
今天的 DL 应用程序包括由许多串行操作组成的复杂、多阶段的数据处理管道。依赖 CPU 处理这些管道会限制性能和可扩展性。在图 1 中,可以观察到数据预处理对 ResNet-50 网络训练吞吐量的影响。在左侧,我们可以看到在 CPU 上运行的用于数据加载和预处理的框架工具时网络的吞吐量。在右侧,我们可以看到相同网络的性能,而不受数据加载和预处理的影响,用合成数据替换。当比较不同的数据预处理工具时,这种测量可以用作理论上限。
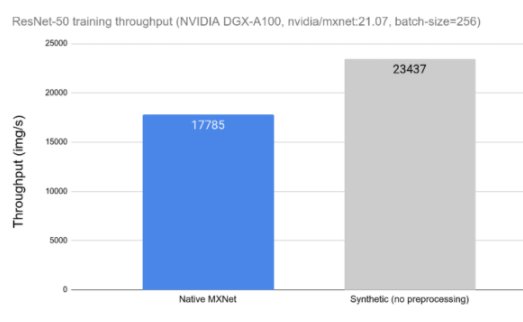
图 1 : ResNet-50 网络的数据预处理对总体训练吞吐量的影响。
大理来营救
NVIDIA 数据加载库( DALI )是我们致力于为上述数据管道问题找到可扩展和可移植解决方案的结果。 DALI 是一组高度优化的构建块和执行引擎,用于加速深度学习( DL )应用程序的输入数据预处理(见图 2 )。 DALI 为加速不同的数据管道提供了性能和灵活性。
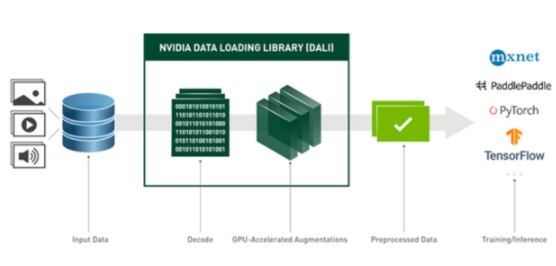
图 2 : DALI 概述及其在 DL 应用程序中作为加速数据加载和预处理工具的使用。
DALI 为各种深度学习应用程序(如分类或检测)提供数据处理原语,并支持不同的数据域,包括图像、视频、音频和体积数据。
支持的输入格式包括最常用的图像文件格式( JPEG 、 PNG 、 TIFF 、 BMP 、 JPEG2000 、 NETPBM )、 NumPy 阵列、使用多种编解码器编码的视频文件( H 。 264 、 HEVC 、 VP8 、 VP9 、 MJPEG )以及音频文件( WAV 、 OGG 、 FLAC )。
DALI 的一个重要特性是插件,它可以作为框架本机数据集的插入式替换。目前, DALI 带有 MxNET PyTorch 、 TensorFlow 和 PaddlePaddle 的插件。只要使用不同的数据迭代器包装器,就可以一次性定义 DALI 管道,并与任何受支持的框架一起使用。
除此之外, DALI 本机支持特定框架中使用的不同存储格式(例如, Caffe 和 Caffe2 中的 LMDB 、 MXNet 中的 RecordIO 、 TensorFlow 中的 TFRecord )。这允许我们使用任何受支持的数据格式,而不管使用的是何种 DL 框架。例如,我们可以对模型使用 MXNet ,同时将数据保存在 TFRecord (原生 TensorFlow 数据格式)中。
通过在 Python 中配置外部数据源,或使用自定义运算符进行扩展,可以轻松地为特定项目定制 DALI 。最后,DALI是一个开源项目,因此您可以轻松地对其进行扩展和调整,以满足您的特定需求。
大理关键概念
DALI 中的主要实体是数据处理pipeline。管道由operators连接的数据节点的符号图定义。每个操作符通常获得一个或多个输入,应用某种数据处理,并产生一个或多个输出。有一些特殊类型的运算符不接受任何输入并产生输出。这些特殊操作符就像一个数据源——读卡器、随机数生成器和外部_源都属于这一类。管道定义在 Python 中使用命令式语言表示,与当前大多数深度学习框架一样,但以异步方式运行。
构建完成后,管道实例可以通过调用管道的 run 方法显式运行,也可以使用特定于目标深度学习框架的数据迭代器包装。
DALI 为各种处理操作员提供 CPU 和 GPU 实现。 CPU 或 GPU 实现的可用性取决于运营商的性质。确保检查文档中是否有支持的操作的最新列表,因为每个版本都会对其进行扩展。
DALI 运营商要求将输入数据放置在与运营商后端相同的设备上。具有混合后端的运算符是一种特殊类型的运算符,用于接收 CPU 内存中的输入和 GPU 内存中的输出数据。出于性能原因,无法访问 DALI 管道中从 GPU 到 CPU 内存的数据传输。
虽然 DALI 的大部分好处是在将处理卸载到 GPU 时实现的,但有时在 CPU 上保持部分操作运行是有益的。特别是在 CPU 与 GPU 比率较高的系统中,或在 GPU 完全被模型占用的情况下。用户可以尝试 CPU / GPU 位置,以逐个找到最佳位置。
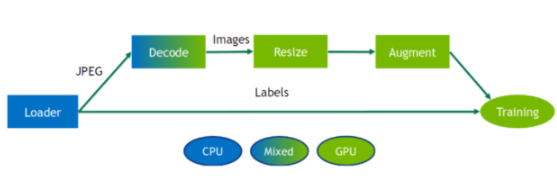
图 3 : DALI 管道的示例。数据加载到 CPU 上,然后使用混合后端操作符进行解码,该操作符在 GPU 内存上输出解码图像,然后在 GPU 上对其进行大小调整和扩充。
如前所述, DALI 的执行是异步的,这允许数据预取,也就是说,在请求批数据之前提前准备批数据,以便框架始终为下一次迭代准备好数据。 DALI 使用可配置的预取队列长度为用户透明地处理数据预取。数据预取有助于隐藏预处理的延迟,当处理时间在迭代中发生显著变化时,这一点很重要(见图 4 )。
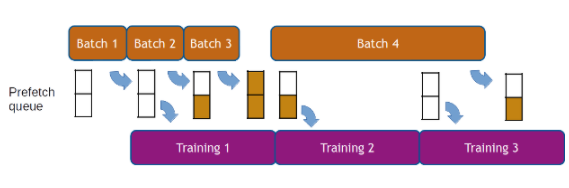
图 4 :数据预取示例,预取队列深度为 2 。较长迭代(第 4 批)的延迟因提前计算而被隐藏。
如何使用大理
定义 DALI 管道的最简单方法是使用pipeline_def Python 装饰器。为了创建管道,我们定义了一个函数,在该函数中实例化并连接所需的运算符,并返回相关的输出。然后用pipeline_def来装饰它。
from nvidia.dali import pipeline_def, fn
@pipeline_def
def simple_pipeline():
jpegs, labels = fn.readers.file(file_root=image_dir,
random_shuffle=True,
name="Reader")
images = fn.decoders.image(jpegs)
return images, labels
在这个示例管道中,没有什么值得注意的事情。第一个操作符是文件读取器,它发现并加载目录中包含的文件。读取器输出文件的内容(在本例中为编码的 JPEG )和从目录结构推断的标签。我们还启用了随机洗牌并为 reader 实例命名,这在稍后与框架迭代器集成时非常重要。第二个运算符是图像解码器。
下一步是实例化simple_pipeline对象并构建它以实际构建图形。在管道实例化过程中,我们还定义了批大小、用于数据处理的 CPU 线程数以及 GPU 设备序号。
pipe = simple_pipeline(batch_size=32, num_threads=3, device_id=0)
pipe.build()
此时,管道已准备好使用。我们可以通过调用 run 方法获得一批数据。
images, labels = pipe.run()
现在,让我们添加一些数据增强,例如,以随机角度旋转每个图像。要生成随机角度,我们可以使用random.uniform,并旋转rotation:
@pipeline_def()
def rotate_pipeline():
jpegs, labels = fn.readers.file(file_root=image_dir,
random_shuffle=True,
name="Reader")
images = fn.decoders.image(jpegs)
angle = fn.random.uniform(range=(-10.0, 10.0))
rotated_images = fn.rotate(images, angle=angle, fill_value=0)
return rotated_images, labels
将计算卸载到 GPU
我们现在可以修改我们的简单_管道,以便它使用.gpu()执行扩充。 DALI 使这种转变非常容易。唯一改变的是rotate运算符的定义。我们只需要将device参数设置为“gpu”,并确保通过调用 GPU 将其输入传输到 GPU 。
self.rotate = fn.rotate(images.gpu(), angle=angle, device="gpu")
为了使事情更简单,我们甚至可以省略device参数,让 DALI 直接从输入位置推断出运算符。
self.rotate = fn.rotate(images.gpu(), angle=angle)
也就是说,simple_pipeline现在在 GPU 上执行旋转。请记住,生成的图像也会分配到 GPU 内存中,这通常是我们想要的,因为模型需要 GPU 内存中的数据。在任何情况下,运行管道后将数据复制回 CPU 内存都可以通过调用Pipeline.run返回的对象as_cpu轻松实现。
images, labels = pipe.run()
images_host = images.as_cpu()
框架集成
与不同深度学习框架的无缝互操作性代表了 DALI 的最佳功能之一。例如,要将您的管道与 PyTorch 模型一起使用,我们可以通过使用DALIClassificationIterator包装它来轻松实现。对于更一般的情况,例如任意数量的管道输出,请使用DALIGenericIterator。
from nvidia.dali.plugin.pytorch import DALIGenericIterator
train_loader = DALIClassificationIterator([pipe], reader_name='Reader')
注意参数reader_name,该值与reader实例的 name 参数匹配。迭代器将使用该读取器作为一个历元中样本数的信息源。
我们现在可以枚举train_loader实例并将数据批提供给模型。
for i, data in enumerate(train_loader):
images = data[0]["data"]
target = data[0]["label"].squeeze(-1).long()
# model training
关于框架集成的更多信息可以在文档的框架插件部分中找到。
推理中的达利
为训练和推理提供数据处理步骤的等效定义对于获得良好的精度结果至关重要。多亏了 NVIDIA Triton 推理服务器及其专用的大理后端,我们现在可以轻松地将 DALI 管道部署到推理应用程序,使数据管道完全可移植。在图 6 所示的体系结构中, DALI 管道作为 Triton 集成模型的一部分进行部署。这种配置有两个主要优点。首先,数据处理是在服务器中执行的,通常是一台比客户机功能更强大的机器。第二个好处是数据可以被压缩后发送到服务器,这节省了网络带宽。
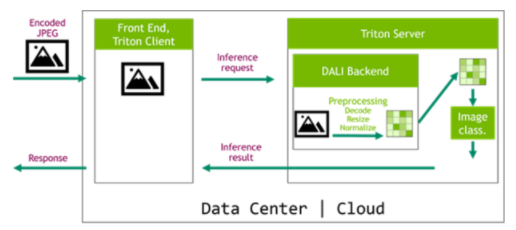
图 6 : DALI 在推理配置中,带有 NVIDIA Triton 推理服务器和用于服务器端预处理的 DALI 后端。
请务必查看我们的专用文章使用 NVIDIA Triton 推理服务器和 NVIDIA DALI 加速推理,详细介绍此主题。
达利对绩效的影响
NVIDIA 展示了 DALI 对 SSD 、 ResNet-50 和 RNN-T 的实现,这是我们的MLPerf基准成功中的一个促成因素。
让我们比较一下使用 DALI 和使用框架的本机解决方案时 ResNet-50 网络的训练吞吐量。在图 7 中,我们可以看到与图 1 中所示类似的比较,这一次显示了将 DALI 作为选项之一用于数据加载和预处理的结果。我们可以看到 DALI 的训练吞吐量如何更接近理论上限(合成示例)。
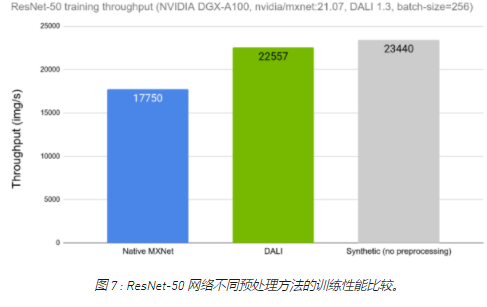
图 7 : ResNet-50 网络不同预处理方法的训练性能比较。
现在让我们看看 DALI 如何影响 Triton 服务器中 Resnet50 推理的性能。图 8 显示了脱机预处理的平均推断请求延迟,这意味着在启动请求之前数据已经过预处理,以及联机服务器端预处理。所花费的时间细分为通信开销、数据预处理和模型推理。由于解码数据的大小较大,预处理请求的延迟会受到通信开销的严重影响。因此,服务器端预处理比离线预处理快,即使前者在度量中包含数据预处理时间。
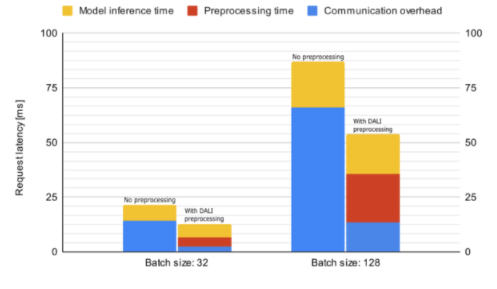
图 8 : Resnet50 模型推断的平均请求延迟(越低越好)比较。这些数字是使用 NVIDIA / Triton 服务器在 DGX A100 机器上使用单个 GPU 收集的: 21 。 07-py3 容器。
今天就从 DALI 开始吧
您可以下载预构建和测试的 DALI pip 包的最新版本。]:、MXNetMXNet的 NVIDIA GPU 云( NGC )容器已集成 DALI 。您可以查看许多examples并阅读最新的发行说明,以获取新功能和增强功能的详细列表。
关于作者
Joaquin Anton Guirao 是 NVIDIA 深度学习框架团队的高级软件工程师,专注于 NVIDIA DALI
Rafal Banas 是 NVIDIA 的软件开发工程师。他致力于 DALI 项目,专注于推理用例。拉法在华沙大学获得计算机科学学士学位。
Krzysztof Łęcki 是 NVIDIA 的高级软件开发工程师,在 DALI 工作。他以前的工作包括为 GPU 和 SIMD 体系结构编写高度优化的数据处理代码,重点关注计算机视觉和图像处理应用。
Janusz Lisiecki 是 NVIDIA 的深度学习经理,致力于快速数据管道。他过去的经验涵盖从面向大众消费市场的嵌入式系统到高性能硬件软件数据处理解决方案。
Albert Wolant 是软件开发工程师,在 NVIDIA 的 DALI 团队工作。他在深度学习和 GP GPU 软件开发方面都有经验。他在并行算法和数据结构方面做了一些研究工作。
Michał Zientkiewicz 是 NVIDIA 的高级软件工程师,目前正在开发 DALI 。他的专业背景包括 GPU 编程、图像处理和编译器开发。米莎先生在华沙工业大学获得计算机科学硕士学位。
Kamil Tokarski 是 NVIDIA 的软件工程师,在 DALI 团队工作,热衷于深度学习和密码学。
Michał Szołucha 是 NVIDIA 的软件工程师,从事图像处理和深度学习项目。曾与移动 3D 技术合作。热衷于使波兰民间传说适应现代接受者的认知。
审核编辑:郭婷
-
嵌入式Linux的灵活性2021-11-04 1305
-
开放式FPGA能否增加测试的灵活性?2021-05-11 1199
-
如何去提高电源管理的灵活性?2021-04-23 1598
-
8 通道、同时采样 ADC 实现真正 18 位性能并提供前所未有的灵活性2021-03-20 1388
-
弹性块存储的灵活性怎么样2020-03-21 1535
-
EVAL-PRAOPAMP-4RZ,为不同的应用电路和配置提供多种选择和广泛的灵活性2019-11-04 1923
-
EVAL-PRAOPAMP-2RMZ,为不同的应用电路和配置提供多种选择和广泛的灵活性2019-11-01 2771
-
集成组件为超声系统设计提供了灵活性2019-07-16 1649
-
开关电容变换器在能量收集电路中提供了性能和灵活性2017-06-17 958
-
MCU 集成式模数转换器提供 MSP 应用灵活性2017-04-26 1209
-
数字可调参考电压源为设计提供灵活性2017-04-18 4678
-
Altera设计坊第一期如何通过FPGA提高工业应用灵活性?2013-10-11 16361
-
超声设计考虑及灵活性实现2011-05-18 1781
-
基于FPGA的网络处理技术的性能和灵活性分析2009-12-26 1151
全部0条评论

快来发表一下你的评论吧 !
