

YOLOX目标检测模型的推理部署
描述
YOLOX目标检测模型
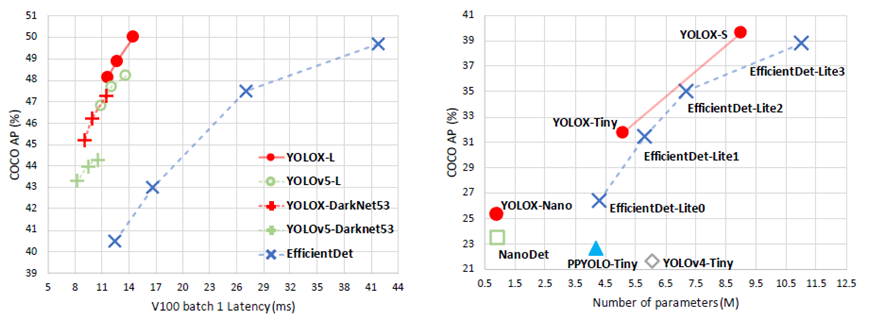
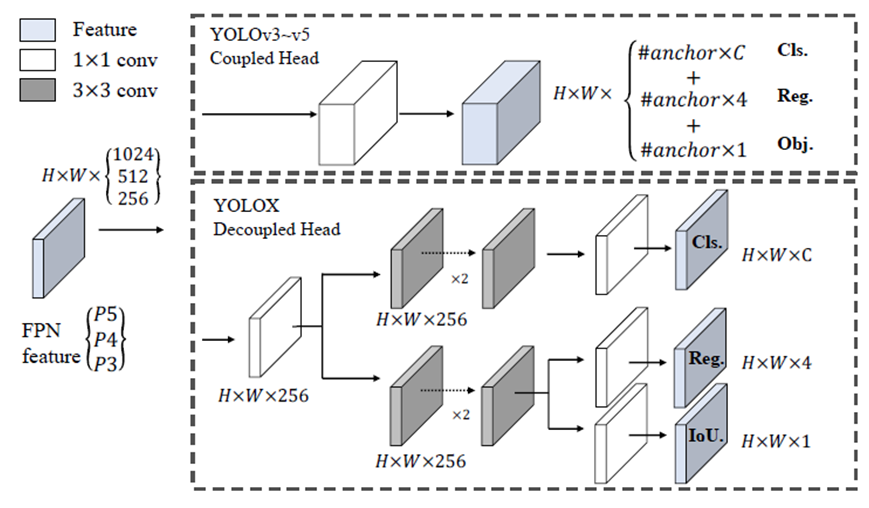
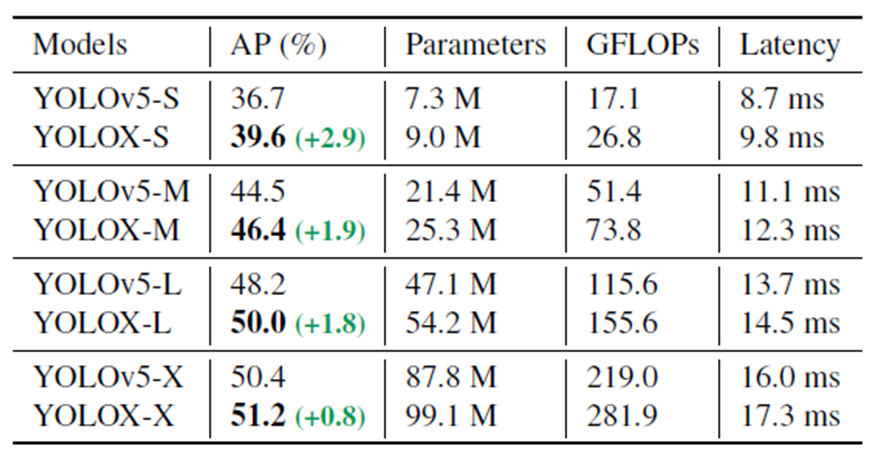
旷视科技开源了内部目标检测模型-YOLOX,性能与速度全面超越YOLOv5早期版本!
https://arxiv.org/pdf/2107.08430.pdfhttps://github.com/Megvii-BaseDetection/YOLOX
ONNX格式模型转与部署
下载YOLOX的ONNX格式模型(github上可以下载)https://github.com/Megvii-BaseDetection/YOLOX/tree/main/demo/ONNXRuntimehttps://github.com/Megvii-BaseDetection/YOLOX/releases/download/0.1.1rc0/yolox_s.onnx
下载ONNX格式模型,打开之后如图:
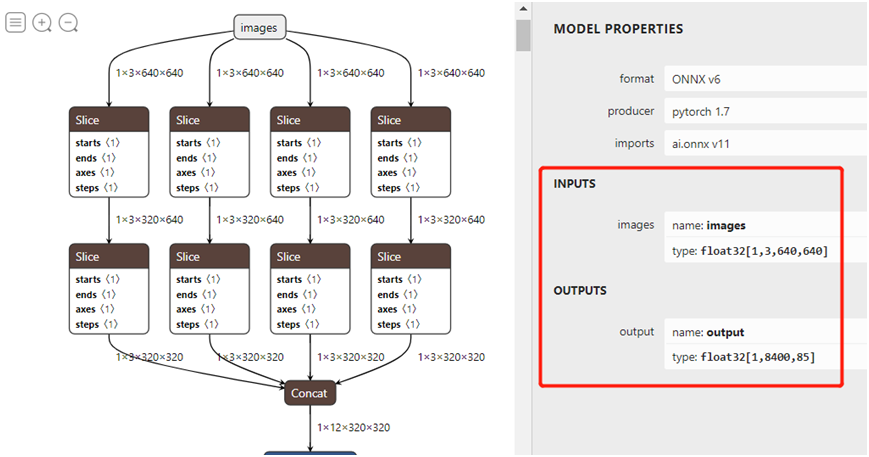
官方说明ONNX格式支持OpenVINO、ONNXRUNTIME、TensorRT三种方式,而且都提供源码,官方提供的源码参考如下:输入格式:1x3x640x640,默认BGR,无需归一化。输出格式:1x8400x85
https://github.com/Megvii-BaseDetection/YOLOX/tree/main/demo
本人就是参考上述的代码然后一通猛改,分别封装成三个类,完成了统一接口,公用了后处理部分的代码,基于本人笔记本的硬件资源与软件版本:
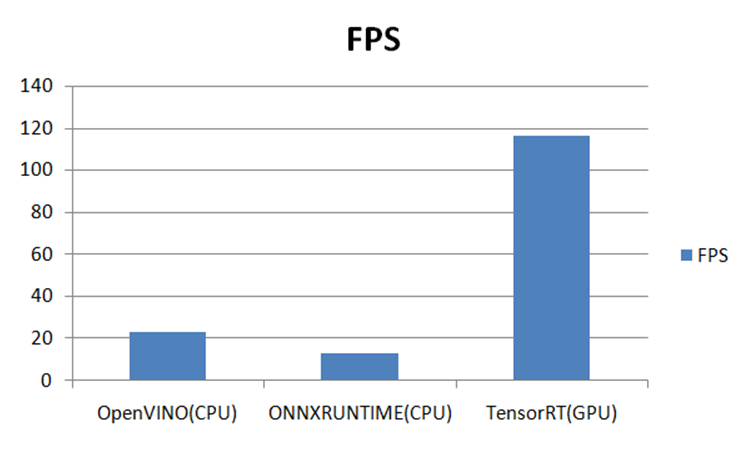
在三个推理平台上测试结果如下:-GPU 3050Ti-CPU i7 11代-OS:Win10 64位-OpenVINO2021.4-ONNXRUNTIME:1.7-CPU-OpenCV4.5.4-Python3.6.5-YOLOX-TensorRT8.4.x

OpenVINO推理

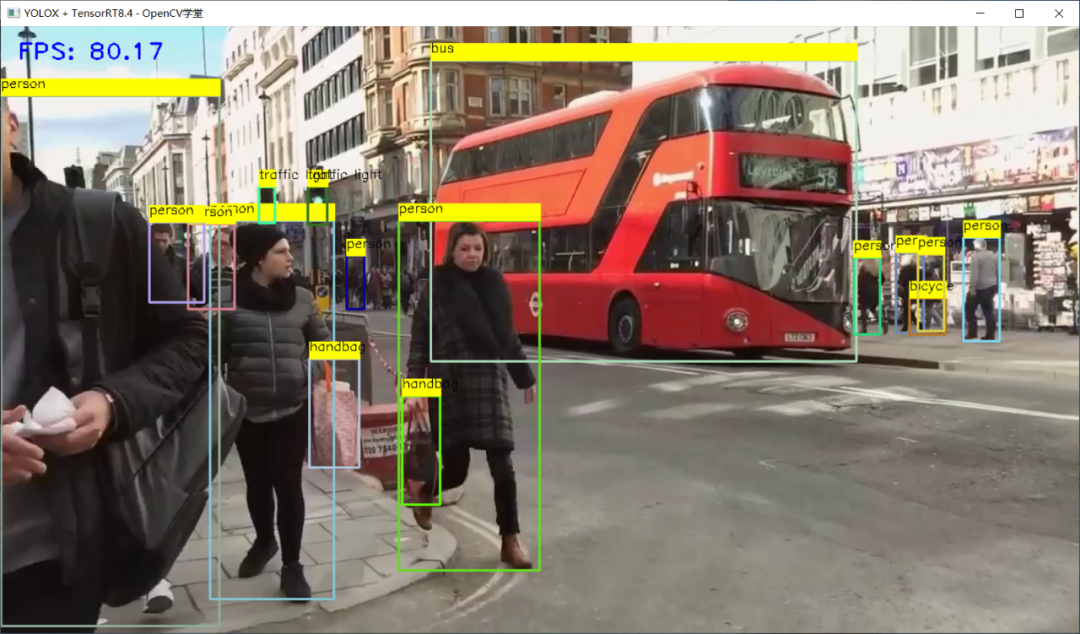
TensorRT推理 - FP32
转威FP16
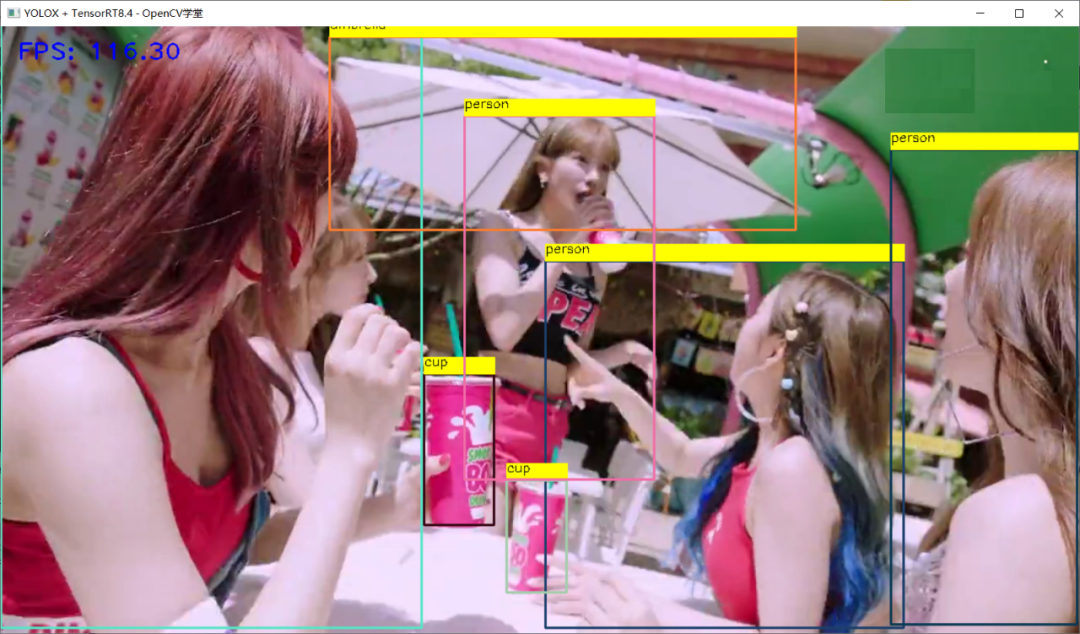
TensorRT推理 - FP16
总结
之前我写过一篇文章比较了YOLOv5最新版本在OpenVINO、ONNXRUNTIME、OpenCV DNN上的速度比较,现在加上本篇比较了YOLOX在TensorRT、OpenVINO、ONNXRUNTIME上推理部署速度比较,得到的结论就是:能不改代码,同时支持CPU跟GPU推理是ONNXRUNTIMEOpenCV DNN毫无意外的速度最慢(CPU/GPU)CPU上速度最快的是OpenVINOGPU上速度最快的是TensorRT
原文标题:YOLOX在OpenVINO、ONNXRUNTIME、TensorRT上面推理部署与速度比较
文章出处:【微信公众号:OpenCV学堂】欢迎添加关注!文章转载请注明出处。
声明:本文内容及配图由入驻作者撰写或者入驻合作网站授权转载。文章观点仅代表作者本人,不代表电子发烧友网立场。文章及其配图仅供工程师学习之用,如有内容侵权或者其他违规问题,请联系本站处理。
举报投诉
-
yolox_bytetrack_osd_encode示例自带的yolox模型效果不好是怎么回事?2024-07-05 718
-
AI模型部署边缘设备的奇妙之旅:目标检测模型2024-12-19 2791
-
用tflite接口调用tensorflow模型进行推理2021-12-22 1665
-
【飞凌RK3568开发板试用体验】RKNN模型推理测试2022-12-08 3115
-
基于YOLOX目标检测算法的改进2023-03-06 1630
-
如何在MIMXRT1064评估套件上部署tflite模型?2023-04-06 595
-
【KV260视觉入门套件试用体验】Vitis-AI加速的YOLOX视频目标检测示例体验和原理解析2023-10-06 12548
-
如何在移动设备上训练和部署自定义目标检测模型2021-08-16 4931
-
YOLOX模型ONNX格式说明2022-04-13 8152
-
YOLOX高性能实时目标检测器2022-06-17 580
-
YOLOv6在LabVIEW中的推理部署(含源码)2024-11-06 1828
-
三种主流模型部署框架YOLOv8推理演示2023-08-06 4286
-
如何使用Vitis-AI加速YOLOX模型实现视频中的目标检测2023-10-16 3211
-
如何开启Stable Diffusion WebUI模型推理部署2024-12-11 1597
-
摩尔线程宣布成功部署DeepSeek蒸馏模型推理服务2025-02-06 1624
全部0条评论

快来发表一下你的评论吧 !
