

NVIDIA的GPU开源套件加速数据库的应用价值
描述
介绍
NVDashboard 是一个开源软件包,用于在交互式Jupyter 实验室环境中实时可视化 NVIDIA GPU 指标。 NVDashboard 是所有 GPU 用户监视系统资源的好方法。然而,它对于RAPIDS, NVIDIA的GPU开源套件加速数据科学软件库的用户尤其有价值。
考虑到现代数据科学算法的计算强度,在许多情况下 GPU 可以提供改变游戏规则的工作流加速。为了获得最佳性能,底层软件有效地使用系统资源是绝对关键的。尽管加速库(如 cuDNN 和 RAPIDS )是专门设计用于执行性能优化方面的繁重任务的,但对于开发人员和最终用户来说,验证他们的软件是否真正按照预期利用了 GPU 资源是非常有用的。虽然这可以通过 NVIDIA -smi 等命令行工具实现,但许多专业数据科学家更喜欢使用交互式 Jupyter 笔记本进行日常模型和工作流开发。
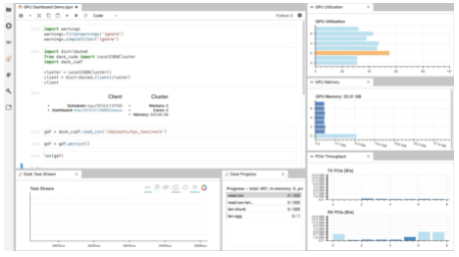
图 1 : NVDashboard Jupyter 实验室扩展正在运行。 GPU 仪表板显示在屏幕右侧,而两个dask-labextension仪表板显示在左下角。
如图 1所示, NVDashboard 使 Jupyter 笔记本用户能够在用于开发的相同交互环境中可视化系统硬件指标。支持的指标包括:
GPU – 计算利用率
GPU – 内存消耗
PCIe 吞吐量
NVLink 吞吐量
该软件包构建在基于 Python 的仪表板服务器上,该服务器支持 Bokeh 可视化库在实时[1]中显示和更新图形。另外一个 Jupyter Lab 扩展将这些仪表板作为可移动窗口嵌入到交互式环境中。大多数 GPU 指标都是通过 PyNVML 收集的, PyNVML 是一个开源的 Python 包,它构成了 NVIDIA 管理库( NVML )的包装。因此,可以修改/扩展可用的仪表板,以显示可通过 NVML 访问的任何可查询 GPU 指标。
使用 NVDashboard
nvdashboard 软件包在PyPI上提供,由两个基本组件组成:
博克服务器:服务器组件利用出色的 Bokeh 可视化库实时显示和更新 GPU -诊断仪表板。所需的硬件指标可通过PyNVML访问,该PyNVML是一个开源的 Python 包,由 NVIDIA 管理库(NVML)的包装组成。因此,可以修改/扩展NVDashboard以显示任何可查询的 GPU 指标,这些指标可以通过NVML轻松地从 Python 访问。
Jupyter 实验室扩建: Jupyter 实验室扩展将 GPU 诊断仪表板嵌入为交互式Jupyter-Lab环境中的可移动窗口。
$ pip install jupyterlab-nvdashboard # If you are using Jupyter Lab 2 you will also need to run $ jupyter labextension install jupyterlab-nvdashboard

必须澄清的是, NVDashboard 自动监控整个机器的 GPU 资源,而不仅仅是本地 Jupyter 环境使用的资源。朱皮特实验室eExtension 当然可以用于非 i Python /笔记本开发。例如,在图 3中,“ NVLink 时间线”和“ GPU 利用率”仪表板在 Jupyter 实验室环境中用于监控从命令行执行的多 GPU 深度学习工作流。
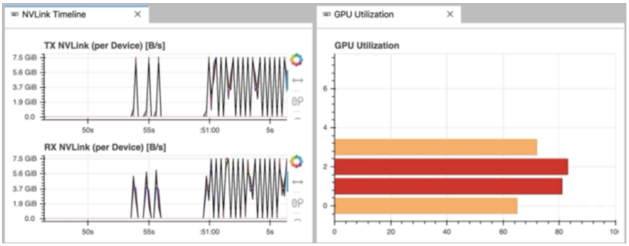
图 3 : Jupyter 实验室使用的“ NVLink Timeline ”仪表板。
博克服务器
虽然 Jupyter 实验室扩展肯定是基于 i Python /笔记本电脑开发的爱好者的理想选择,但其他 GPU 用户也可以使用 sandalone Bokeh 服务器访问仪表板。这是通过运行来完成的。
$ Python -m jupyterlab nvdashboard 。 server 《端口号》
启动 Bokeh 服务器后,可通过在标准 web 浏览器中打开相应的 url (例如 http ://《 ip 地址》:《 port number 》)来访问 GPU 仪表板。如图 4所示,主菜单列出了 NVDashboard 中可用的所有仪表板。

图 4 : NVDashboard 的 Bokeh 服务器组件的主菜单。
例如,选择“ GPU -Resources ”链接将打开图 5中所示的仪表板,该仪表板使用对齐的时间线图总结各种 GPU 资源的利用率。
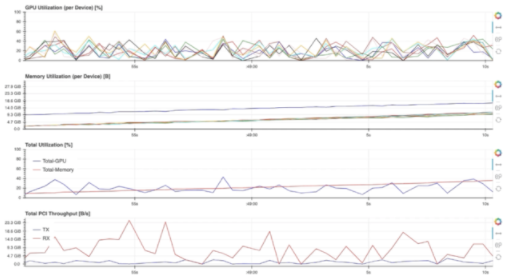
图 5 : Jupyter 实验室外部使用的“ GPU 资源”仪表板。
要以这种方式使用 NVDashboard ,只需要 pip 安装步骤(可以跳过实验室扩展安装步骤):
$ pip 安装 jupyterlab nvdashboard
或者,您也可以克隆jupyterlab-nvdashboard存储库,只需执行server.py脚本(例如python jupyterlab_nvdashboard/server.py 《port-number》)。
实施细节
现有的 nvdashboard 包提供了许多有用的 GPU – 资源仪表板。但是,修改现有仪表板和/或创建全新的仪表板非常简单。为了做到这一点,您只需要利用 PyNVML 和 Bokeh 。
PyNVML dasic
PyNVML 是 NVIDIA 管理库( NVML )的 Python 包装器,它是一个基于 C 的 API ,用于监视和管理 NVIDIA GPU 设备的各种状态。 NVML 直接由更知名的 NVIDIA 系统管理接口( NVIDIA -smi )使用。根据 NVIDIA 开发者网站, NVML 提供对以下可查询状态的访问(除了此处未讨论的可修改状态外):
ECC 错误计数:报告可纠正的单位错误和可检测的双位错误。为当前引导周期和 GPU 的生命周期提供错误计数。
GPU 利用率:报告 GPU 和内存接口的计算资源的当前利用率。
主动计算过程:报告在 GPU 上运行的活动进程列表,以及相应的进程名称/ id 和分配的 GPU 内存。
时钟和 PState:报告了几个重要时钟域的最大和当前时钟速率,以及当前 GPU 性能状态。
温度和风扇转速:报告当前堆芯 GPU 温度以及非无源产品的风扇转速。
电源管理:对于支持的产品,会报告当前板功率消耗和功率限制。
Identification:报告各种动态和静态信息,包括板序列号、 PCI 设备 ID 、 VBIOS / Inforom 版本号和产品名称。
尽管目前存在几种不同的 NVML Python 包装器,但我们在 GitHub 上使用 GoAi 托管的PyNVML包。这个版本的 PyNVML 使用 ctypes 包装大多数 nvmlcapi 。 NVDashboard 仅利用查询实时 GPU 资源利用率所需的一小部分 API ,包括:
nvmlInit():初始化 NVML 。初始化成功后,缓存 GPU 句柄,以降低仪表板中活动监视期间的数据查询延迟。
nvmlShutdown(): Finalize NVML
nvmlDeviceGetCount ():获取可用 GPU 设备的数量
nvmlDeviceGetHandleByIndex():获取设备的句柄(给定整数索引)
nvmlDeviceGetMemoryInfo():获取内存信息对象(给定设备句柄)
nvmlDeviceGetUtilizationRates():获取利用率对象(给定设备句柄)
nvmlDeviceGetPcieThroughput():获取 PCIe 吞吐量对象(给定设备句柄)
nvmlDeviceGetNvLinkUtilizationCounter():获取 NVLink 利用率计数器(给定设备句柄和链接索引)
在 PyNVML 的当前版本中, Python 函数名的选择通常与 C API 完全匹配。例如,要查询每个可用设备上的当前 GPU – 利用率,代码如下所示:
可用设备上的当前 GPU – 利用率,代码如下所示:
In [1]: from pynvml import *
In [2]: nvmlInit()
In [3]: ngpus = nvmlDeviceGetCount()
In [4]: for i in range(ngpus):
…: handle = nvmlDeviceGetHandleByIndex(i)
…: gpu_util = nvmlDeviceGetUtilizationRates(handle).gpu
…: print(‘GPU %d Utilization = %d%%’ % (i, gpu_util))
…:
GPU 0 Utilization = 43%
GPU 1 Utilization = 0%
GPU 2 Utilization = 15%
GPU 3 Utilization = 0%
GPU 4 Utilization = 36%
GPU 5 Utilization = 0%
GPU 6 Utilization = 0%
GPU 7 Utilization = 11%
注意,除了 GitHub 存储库之外, PyNVML 还托管在PyPI和锻造伯爵上。
仪表板代码
要修改/添加 GPU 仪表板,只需使用两个文件(jupyterlab_bokeh_server/server.py和jupyterlab_nvdashboard/apps/gpu.py)。添加/修改仪表板所需的大多数 PyNVML 和 bokeh 代码都将在gpu.py中。只有在添加或更改菜单/显示名称的情况下,才需要修改server.py。在这种情况下,必须在 routes dictionary 中指定新的/修改的名称(键为所需的名称,值为相应的仪表板定义):
routes = {
"/GPU-Utilization": apps.gpu.gpu,
"/GPU-Memory": apps.gpu.gpu_mem,
"/GPU-Resources": apps.gpu.gpu_resource_timeline,
"/PCIe-Throughput": apps.gpu.pci,
"/NVLink-Throughput": apps.gpu.nvlink,
"/NVLink-Timeline": apps.gpu.nvlink_timeline,
"/Machine-Resources": apps.cpu.resource_timeline,
}
为了让服务器不断刷新 bokeh 应用程序使用的 PyNVML 数据,我们使用 bokeh 的 ColumnDataSource 类在每个图中定义数据的source。 ColumnDataSource 类允许为每种类型的数据传递更新函数,可以在每个应用程序的专用回调函数( cb )中调用更新函数。例如,现有 GPU 应用程序的定义如下:
def gpu(doc):
fig = figure(title=“GPU Utilization”, sizing_mode=“stretch_both”, x_range=[0, 100])
def get_utilization():
return [
pynvml.nvmlDeviceGetUtilizationRates(gpu_handles[i]).gpu
for i in range(ngpus)
]
gpu = get_utilization()
y = list(range(len(gpu)))
source = ColumnDataSource({“right”: y, “gpu”: gpu})
mapper = LinearColorMapper(palette=all_palettes[“RdYlBu”][4], low=0, high=100)
fig.hbar(
source=source,
y=“right”,
right=“gpu”,
height=0.8,
color={“field”: “gpu”, “transform”: mapper},
)
fig.toolbar_location = None
doc.title = “GPU Utilization [%]”
doc.add_root(fig)
def cb():
source.data.update({“gpu”: get_utilization()})
doc.add_periodic_callback(cb, 200)
请注意, PyNVML GPU 利用率数据的实时更新是在source.data.update()调用中执行的。有了必要的ColumnDataSource逻辑,可以通过多种方式修改标准 GPU 定义(如上)。例如,交换 x 轴和 y 轴,指定不同的调色板,甚至将图形从 hbar 完全更改为其他图形。
关于作者
Jacob Tomlinson 是 NVIDIA 的高级 Python 软件工程师,专注于分布式系统的部署工具。他的工作包括维护开源项目,包括 RAPIDS 和 Dask 。 RAPIDS 是一套 GPU 加速开源 Python 工具,模拟 PyData 堆栈中的 API ,包括 NumPy 、 pandas 和 SciKit Learn 的 API 。 Dask 为分析提供了高级并行性,包括核心外计算、延迟计算和 PyData 堆栈的分布式执行。
Ken Hester 是 NVIDIA 的解决方案架构师和经理,在 HPC 、 AI 深度学习和机器学习以及 CUDA GPU 计算领域为能源行业提供支持。他来自德克萨斯州休斯顿,在 NVIDIA 工作了近 8 年。在 NVIDIA 之前, Ken 在能源行业工作了 15 年以上,是数据科学、软件架构、软件设计和开发领域的行业专家。
Rick Zamora 是 NVIDIA 在 RAPIDS 和 Dask 工作的高级软件工程师。他有科学计算研究和并行软件开发的背景。
审核编辑:郭婷
-
NVIDIA加速微软最新的Phi-3 Mini开源语言模型2024-04-28 2113
-
搭载英伟达GPU,全球领先的向量数据库公司Zilliz发布Milvus2.4向量数据库2024-04-01 1938
-
177倍加速!NVIDIA最新开源 | GPU加速各种SDF建图!2023-11-09 2833
-
开源数据库迎来拐点|2023开放原子全球开源峰会数据库分论坛成功召开2023-06-14 1346
-
开源数据库迎来技术创新拐点|2023 开放原子全球开源峰会开源数据库分论坛即将启幕2023-06-01 1123
-
开源数据库迎来技术创新拐点|2023开放原子全球开源峰会开源数据库分论坛即将启幕2023-05-31 1234
-
MongoDB开源文档数据库的安装2022-12-06 2235
-
专业水培数据库管理开源分享2022-11-03 803
-
企业级开源数据库openGauss荣获“2020年度最热开源数据库奖”2021-01-18 2915
-
详谈一些主流开源数据库及工具2021-01-11 3454
-
在开源软件的使用中,数据库是香饽饽2020-12-21 2774
-
华为正式宣布开源数据库能力,开放openGauss数据库源代码2020-07-25 5519
-
Nvidia宣布推出了一套新的开源RAPIDS库2020-03-25 3092
-
支持多GPU的数据库2017-09-28 600
全部0条评论

快来发表一下你的评论吧 !
