

一文详细了解APACHE SPARK开源框架
描述
Apache Spark 是一个开源框架,适用于跨集群计算机并行处理大数据任务。它是在全球广泛应用的分布式处理框架之一。
什么是 APACHE SPARK?
伴随数据的巨量增长,Apache Spark 已成为分布式横向扩展数据处理的热门框架之一,可以在本地和云端数以百万计的服务器上运行。
Apache Spark 是应用于大型数据处理的快速通用分析引擎,可在 YARN、Apache Mesos、Kubernetes 上运行,也可独立或在云端运行。借助用于 SQL、流处理、机器学习和图形处理的高级运算符及库,Spark 使开发者能够通过交互式 shell、笔记本或应用程序包来使用 Scala、Python、R 或 SQL 轻松构建并行应用程序。通过功能编程模型和相关查询引擎 Catalyst,Spark 支持批量和交互式分析,可将作业转换为查询方案,并跨集群节点调度查询方案中的操作。
Spark 核心数据处理引擎之上存在多个用于 SQL 和 DataFrame、机器学习、GraphX、图形计算和流处理的库。用户可在来自各种数据源(例如 HDFS、Alluxio、Apache Cassandra、Apache HBase 或 Apache Hive)的海量数据集上结合使用这些库。
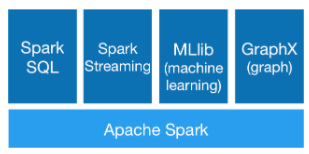
Apache Spark 组件
为何选择 APACHE SPARK?
Apache Spark 继续了 Apache Hadoop 在 15 年前开始的大数据分析工作,并已成为大规模分布式数据处理的先进框架。
2010 年代初,大数据分析的流行促使 Hadoop 的使用量增长,而 Hadoop MapReduce 的性能限制成为了阻碍。MapReduce 的性能因其磁盘检查点结果模型而遭遇瓶颈。同时,MapReduce 的低级别编程模型也限制了 Hadoop 的采用。
Apache Spark 最初是加利福尼亚大学伯克利分校 AMPLab 的一个研究项目,其目标是维持 MapReduce 可扩展、分布式、容错处理框架的优势,同时促使该框架变得更高效、更易于使用。Spark 能够重复利用多线程轻量级任务(并非启动和终止进程),还能跨迭代将数据缓存于内存中,无需在各阶段间写入磁盘,因此 Spark 在数据流程和迭代算法方面比 MapReduce 更高效。Spark 使用容错分布式 DataFrame 来增强并行性能,并可实现 SQL 的易用性。
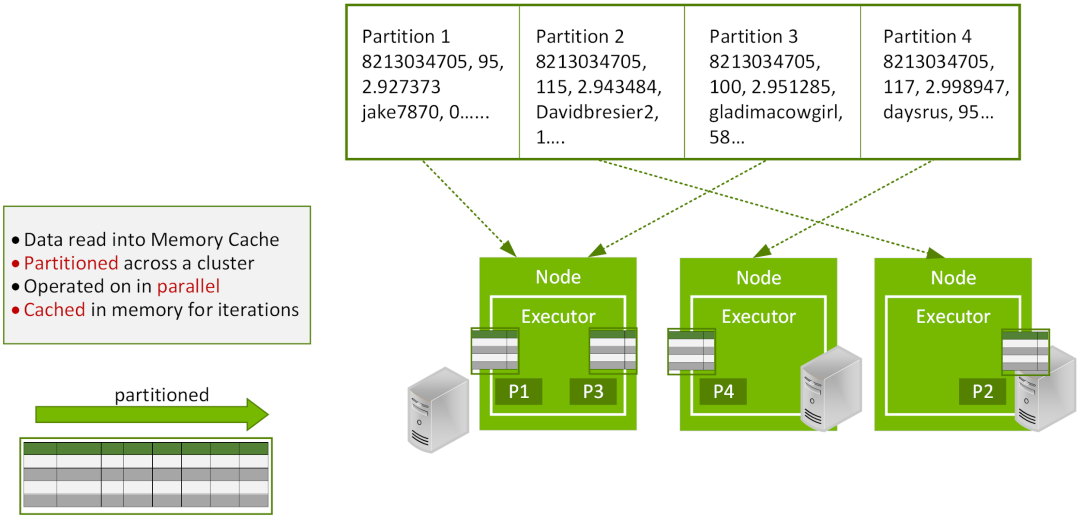
Spark 于 2014 年成为 Apache 软件基金会的高级项目,如今,遍及 16000 多家企业和组织的成千上万名数据工程师和科学家都在使用 Spark。Spark 在 Hadoop 的基础上继往开来的原因之一是,与 MapReduce 相比,其内存数据处理性能能够以快达 100 倍的速度完成某些任务。这些功能由 250 多家公司的 1000 多位贡献者在一个开放社区中创建。Databricks 的创始人率先进行了这项工作,仅仅是其平台每天就运行着 100 多万个虚拟机来分析数据。
为何 SPARK 在应用 GPU 后表现更出色
Spark 的各个版本均有所改进,有助于更轻松地编程和执行。Apache Spark 3.0 通过创新来维持此趋势,改善 Spark SQL 性能和 NVIDIA GPU 加速。
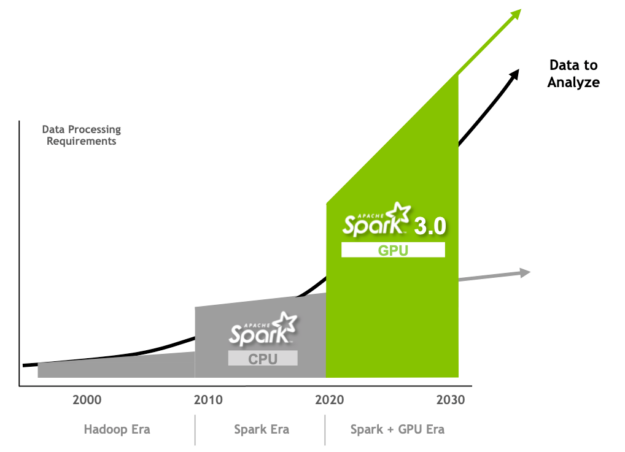
图形处理器 (GPU) 因其超低浮点运算(性能)单价深受欢迎,其还可通过加快多核服务器的并行处理速度,解决当前的计算性能瓶颈问题。CPU 由专为按序串行处理优化的几个核心组成。而 GPU 则拥有一个大规模并行架构,当中包含数千个更小、更高效的核心,专为同时处理多重任务而设计。与仅包含 CPU 的配置相比,GPU 的数据处理速度快得多。过去数年中,GPU 一直推动 DL 和机器学习 (ML) 模型训练的发展。然而,数据科学家 80% 的时间都花费在了数据预处理上。
虽然 Spark 是以分割数据形式在节点分区中分发计算,但其向来是在 CPU 核心上执行计算操作。Spark 虽然通过添加内存数据处理缓解了 Hadoop 中存在的 I/O 问题,但现在瓶颈问题已从 I/O 转变为日益增多的应用程序的计算问题。随着 GPU 加速计算的出现,此性能瓶颈问题迎刃而解。
为满足并超越数据处理的现代需求,NVIDIA 一直与 Apache Spark 社区进行合作,通过推出 Spark 3.0 版本和用于 Spark 的开源 RAPIDS 加速器,将 GPU 应用于 Spark 的本机处理。在 Spark 中引入 GPU 加速具有诸多优势:
数据处理、查询和模型训练能够更快完成,缩短结果获取时间。
同一个 GPU 加速的基础设施可用于 Spark 和 ML/DL(深度学习)框架,因而无需使用单独的集群,并让整个流程都能获得 GPU 加速。
减少所需的服务器数量,降低基础设施成本。
用于 APACHE SPARK 的 RAPIDS 加速器
RAPIDS 是一套开源软件库和 API,可完全在 GPU 上执行端到端数据科学和分析流程,能够实现大幅的速度提升,在大型数据集上尤是如此。用于 Apache Spark 的 RAPIDS 加速器基于 NVIDIA CUDA 和 UCX 构建,支持 GPU 加速的 SQL/DataFrame 操作和 Spark shuffle,且无需更改代码。

Apache Spark 加速的端到端 AI 平台堆栈
加速 SQL/DataFrame
Spark 3.0 支持 SQL 优化器插件,使用列式批量(而非行式)处理数据。列式数据非常适合 GPU,并且 RAPIDS 加速器可插入此功能以加速 SQL 和 DataFrame 运算符。针对 RAPIDS 加速器,Catalyst 查询优化器进行了修改,可识别通过 RAPIDS API 加速的查询方案(主要是一对一映射)中的运算符,并可在执行查询方案时在 Spark 集群中的 GPU 上调度这些运算符。
加速 Shuffle
在阶段之间从现有 DataFrame 创建新 DataFrame 时,按值对数据进行排序、分组或合并的 Spark 操作必须移动分区之间的数据,此过程称为 shuffle,其中涉及磁盘 I/O、数据序列化和网络 I/O。新的 RAPIDS 加速器 shuffle 实施利用 UCX 优化 GPU 数据传输,尽可能在 GPU 上保留更多的数据,通过使用优质的可用硬件资源,找到在节点间移动数据的快速路径(包括绕过 CPU 执行 GPU 到 GPU 显存的节点内和节点间传输)。
加速器感知型调度
为推动旨在更好地统一深度学习和数据处理的重要 Spark 计划,GPU 在 Apache Spark 3.0 中现已成为可调度资源。这使得 Spark 能够使用特定数量的 GPU 来调度执行程序,并且用户可以指定每个任务所需的 GPU 数量。Spark 将这些资源请求传送至底层集群管理器、Kubernetes、YARN 或 Standalone。用户还可以配置发现脚本,检测集群管理器分配的 GPU。这大大简化了需要 GPU 的 ML 应用程序的运行,因为之前用户需要处理 Spark 应用程序中缺少 GPU 调度的问题。
加速 XGBoost
XGBoost 是一种可扩展的分布式梯度提升决策树 (GBDT) ML 库。
XGBoost 提供并行树提升功能,是应用于回归、分类和排序问题的出色 ML 库。RAPIDS 团队与 Distributed Machine Learning Common (DMLC) XGBoost 组织密切合作,而且 XGBoost 现已包含无缝嵌入式 GPU 加速。另外,Spark 3.0 XGBoost 现已与 Rapids 加速器集成,借助 Spark SQL/DataFrame 操作的 GPU 加速、XGBoost 训练时间的 GPU 加速,以及内存优化存储功能的高效 GPU 显存利用率,可改善性能、准确性和成本。
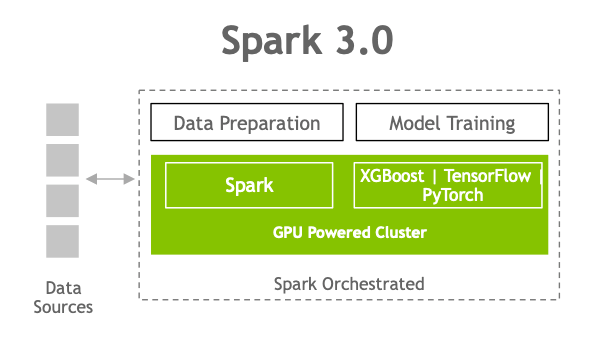
在 Spark 3.0 中,您现在可以有单个流程,从数据提取到数据准备,再到在 GPU 驱动的集群上训练模型,皆包含在内
SPARK 用例示例
欺诈检测
对于需要快速决策并涉及多个数据源的情况而言,运行快速的 Spark 是不二之选。例如,金融机构检测信用卡欺诈的方法之一是,分析单一帐户上的交易量和交易地点。如果交易次数超出个人能力范围,或者多个交易发生在不同地点,而交易地点相距不合情理,则表明一个帐户已被泄露。
银行可以使用 Apache Spark 来根据使用模式创建帐户持有者的统一视图。机器学习可用于根据先前观察到的模式,检测超出规范的模式。这还可以使机构更好地根据客户个人需求来定制优惠。
医疗健康
在美国,药物的不良相互作用是第四大致死原因,排在肺癌、糖尿病和肺炎之前。确定多种药物如何相互作用以对患者造成不良后果,这一问题的复杂程度呈指数级增加,随着新药不断推出,这一问题在每一年都更加复杂。
借助 Spark,数据科学家可以创建算法,扫描数百万份病例记录并查找提及的药物类型。某些药物的组合可以与治疗结果相关联,并按原先存在的状况和病史等因素加权。然后可以将结果应用于个别患者的健康记录,在开具处方或填写处方之前提醒医生和药师注意出现不良反应的可能性。
为何 APACHE SPARK 如此重要
Spark 3.0 是数据科学家和数据工程师在分析和 AI 领域协作的一个重要里程碑,其使 ETL 操作得到加速,同时 ML 和 DL 应用程序也能够利用相同的 GPU 基础设施。
数据科学团队
将数据转化为可用形式需要完成众多普通任务,数据科学的“魔力”对此也无计可施。该过程涉及对数百万或数十亿条记录中的非结构化数据(例如邮政编码、日期和 SKU 编号)进行分类和排序。数据集越大,处理时间越长。据估计,数据准备会占用数据科学家 80% 的时间。
Hadoop 是一项大规模执行数据分析的突破性技术,使数据科学家能够针对超大型数据存储执行查询。但是,处理时间通常很长,尤其是在需要对现有数据集执行重复扫描时,这在进行分类和数据发现时经常发生。
Spark 专为跨大型数据集的迭代查询而构建。与 Hadoop/MapReduce 相比,其速度快达 100 倍,迅速获得了数据科学家的青睐。Spark 还可轻松适应 Python、R 和 Scala 等面向数据科学的开发语言。由于大多数数据科学家都习惯于使用单个编程工具,因此 Spark 能够轻松适应个人需求。
Spark SQL 还引入了名为 DataFrame 的数据抽象概念,该概念支持结构化和半结构化数据,并且支持多语言操作。通过这种概念,熟悉的 SQL 语言能够以新方式应用于非结构化数据。Spark ML 提供了一套统一的高级别 API,这些 API 基于 DataFrame 构建,用于搭建 ML 流程或 ML 工作流程。基于 DataFrame 构建 ML 流程可实现分区数据处理的可扩展性,且便于通过 SQL 进行数据操作。
数据工程团队
数据工程师弥补了数据科学家与开发者之间的差距。数据科学家选择合适的数据类型和算法来解决问题,而数据工程师则与数据科学家和开发者开展合作,处理与数据流程创建相关的所有工作,用于数据提取转换、存储和分析,以构建大数据分析应用程序。
Spark 将复杂性从存储方程中抽象出来。该框架可以处理几乎任何底层存储(包括 Hadoop 分布式文件系统),因此比 Hadoop 更灵活,更适用于云和本地基础设施的组合。Spark 还可以轻松整合流数据源,使其成为适用于新一代物联网应用程序的引擎。
原文标题:NVIDIA大讲堂 | 什么是 APACHE SPARK?
文章出处:【微信公众号:NVIDIA英伟达】欢迎添加关注!文章转载请注明出处。
审核编辑:汤梓红
- 相关推荐
- 热点推荐
- NVIDIA
- 开源框架
- apache spark
-
Spark基于DPU的Native引擎算子卸载方案2024-06-28 1830
-
RDMA技术在Apache Spark中的应用2024-03-25 2754
-
一文详细了解OpenHarmony新图形框架2022-04-27 3629
-
利用Apache Spark和RAPIDS Apache加速Spark实践2022-04-26 2912
-
Apache Spark 3.2有哪些新特性2021-11-17 2823
-
详细了解下ups的相关计算2021-11-16 1765
-
大数据分析中Spark,Hadoop,Hive框架该用哪种开源分布式系统2020-09-17 5539
-
基于Spark 2.1版本的Apache Spark内存管理2019-04-26 2005
-
Apache Spark上的分布式机器学习的介绍2018-11-05 3957
-
Apache Spark的分布式深度学习框架BigDL的概述2018-10-30 4413
-
机器学习实例:Spark与Python结合设计2018-07-01 3207
-
Apache Spark 1.6预览版新特性展示2017-10-13 725
-
如何使用Apache Spark 2.02017-09-28 831
-
基于Apache Spark 的下一波智能应用2016-12-28 1077
全部0条评论

快来发表一下你的评论吧 !
