

如何将神经网络用于推荐系统应用
描述
深度学习( Deep learning , DL )是解决计算机视觉或自然语言等机器学习问题的最新方法,它的性能优于其它方法。最近的趋势包括将 DL 技术应用于推荐引擎。许多大型公司,如 AirBnB 、 Facebook 、 Google 、 Home Depot 、 LinkedIn 和 Pinterest ,都分享了他们将 DL 用于推荐系统的经验。
最近, NVIDIA 和 RAPIDS 。 AI 团队与 DL 赢得了三场比赛: VZX1 、 信号和日期挑战 和 ACM WSDM2021 Booking 。 com 挑战赛 。
推荐系统的领域是复杂的。在这篇文章中,我将重点介绍神经网络体系结构及其组件,例如嵌入层和完全连接层、递归神经网络单元( LSTM 或 GRU )和变压器块。我讨论了流行的网络架构,比如 Google 的 Wide & Deep 和 Facebook 的 Deep Learning Recommender Model ( DLRM )。
DL 推荐系统的优点
有许多不同的技术来设计推荐系统,例如关联规则、基于内容或协同过滤、矩阵分解或训练线性或基于树的模型来预测交互可能性。
使用神经网络的优点是什么?一般来说, DL 模型可以获得更高的精度。首先, DL 可以利用额外的数据。许多传统的机器学习技术需要更多的数据。但是,当您增加神经网络的容量时,该模型可以使用更多的数据来提高性能。
第二,神经网络的设计是灵活的。例如,您可以针对多个目标(多任务学习)训练 DL 模型,例如“用户是否将项目添加到购物车中?”、“使用项目开始结账?”、或“购买项目?”。每个目标都有助于模型从数据中提取信息,并且目标可以相互支持。
其他设计方法包括向推荐模型中添加多模态数据。您可以通过使用卷积神经网络处理产品图像或使用 NLP 模型处理产品描述来实现这一点。神经网络应用于许多领域。您可以将新开发(如优化器或新层)转移到推荐系统。
最后, DL 框架经过了高度优化,可以处理各种域的数 TB 到数 PB 的数据。下面是如何为推荐系统设计神经网络。
基本构造块:嵌入层
嵌入层用密集向量表示类别。这种技术在自然语言处理中非常流行,可以嵌入具有密集表示的单词。具有相似意义的词具有相似的嵌入向量。
您可以将相同的技术应用于推荐系统。最简单的推荐系统是基于用户和项目的:您应该向用户推荐哪些项目?您有用户 ID 和项目 ID 。单词是 users 和 items ,因此使用两个嵌入表(图 1 )。
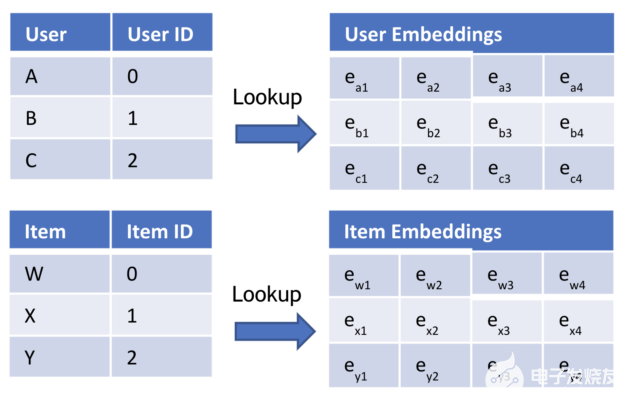
图 1 。嵌入维度为 4 的表
计算用户嵌入和项目嵌入之间的点积,得到最终分数,即用户与项目交互的可能性。最后一步可以应用 sigmoid 激活函数将输出转换为 0 到 1 之间的概率。
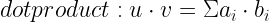
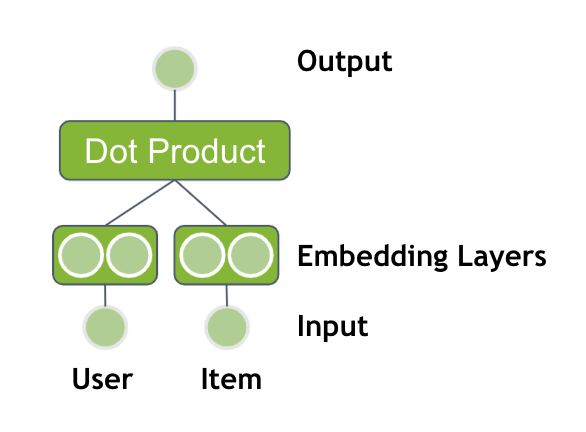
图 2 。具有两个嵌入表和点积输出的神经网络
该方法等价于矩阵分解或交替最小二乘法( ALS )。
具有完全连接层的较深模型
神经网络的性能是基于具有多个非线性层的深层结构。通过将嵌入层的输出通过多个具有 ReLU 激活的完全连接层提供,可以扩展先前的模型。
一个设计选择是如何组合两个嵌入向量。您可以仅串联嵌入向量,也可以将向量逐元素相乘,类似于点积。输出之后是多个隐藏层。
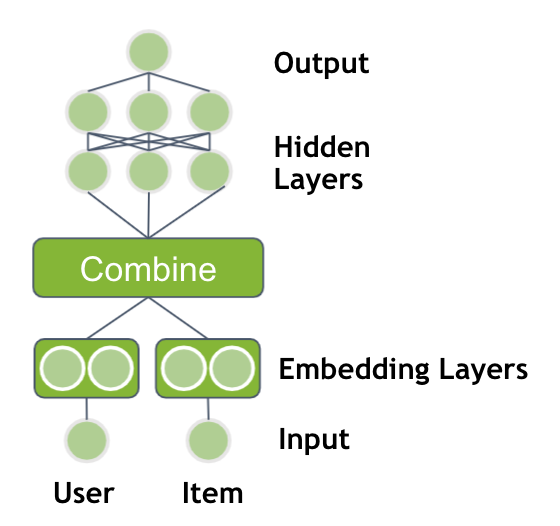
图 3 。具有两个嵌入表和多个完全连接层的神经网络
向神经网络中添加元数据信息
到目前为止,您只使用了用户 ID 和产品 ID 作为输入,但是您通常可以获得更多的信息。其他用户信息可以是性别、年龄、城市(地址)、自上次访问以来的时间或用于支付的信用卡。一件商品通常有一个品牌、价格、类别或在过去 7 天内售出的数量。这些信息有助于模型更好地推广。修改神经网络以使用附加特征作为输入。
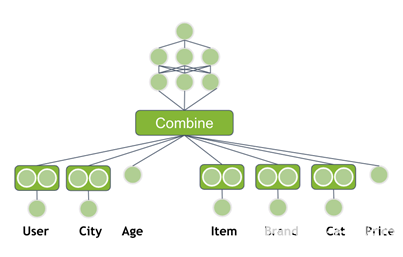
图 4 。具有元信息和多个完全连接层的神经网络
流行建筑
嵌入层和完全连接层是理解一些最新出版的神经网络结构的主要组成部分。在这篇文章中,我将从 2016 年开始报道谷歌的广度和深度,从 2019 年开始报道 Facebook 的 DLRM 。
谷歌的广度和深度
谷歌的广度和深度包含两个部分:
记忆共同特征组合的宽塔
用来概括罕见或未观察到的特征组合的深塔
创新之处在于,这两个组件同时训练,这是可能的,因为神经网络是灵活的。深塔通过嵌入层提供分类特征,并将输出与数字输入特征连接起来。级联向量通过多个完全连接的层馈送。
你听上去熟悉吗?是的,那是你以前的神经网络设计。新的组成部分是宽塔,它只是输入特征的线性组合,具有类似的线性/逻辑回归。每个塔的输出相加,得到最终的预测值。
Facebook 的 DLRM
Facebook 的 DLRM 与带有元数据的神经网络结构类似,但有一些特定的差异。数据集可以包含多个分类特征。 DLRM 要求所有的分类输入都通过一个具有相同维数的嵌入层。稍后,我将讨论这一点的重要性。
接下来,将连续的输入串联起来并通过称为底部多层感知器( MLP )的多个完全连接的层馈送。底层 MLP 的最后一层具有与嵌入层向量相同的维数。
DLRM 使用了一个新的组合层。它在所有嵌入向量对和底部 MLP 输出之间应用按元素相乘。这就是为什么每个向量都有相同的维数。所得到的向量被串联并馈送到另一组完全连接的层(顶部 MLP )。
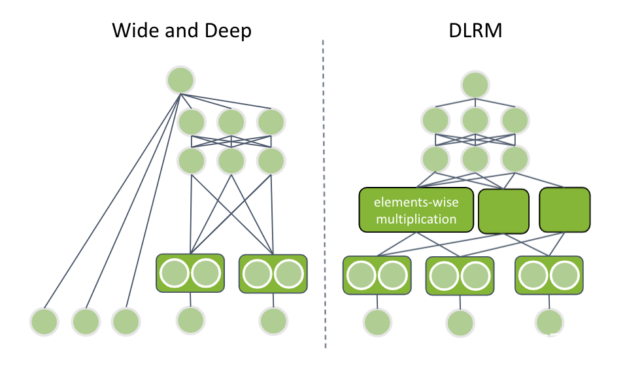
图 5 。左侧显示广度和深度架构,右侧显示 DLRM 架构。
基于会话的推荐系统
当我为推荐系统分析不同的基于 DL 的体系结构时,我假设输入具有表格数据结构,而忽略了用户交互的本质。但是,用户在访问网站时,在一个会话中有多个交互。例如,他们访问一家商店并查看多个产品页面。您可以使用用户交互序列作为输入来提取模式吗?
在一个会话中,用户连续查看多条牛仔裤,您应该推荐另一条牛仔裤。在另一个会话中,同一个用户连续查看多双鞋,您应该推荐另一双鞋。这就是基于会话的推荐系统背后的直觉。
谢天谢地,您可以将 NLP 中的一些技术应用于推荐系统域。用户的交互具有顺序结构。
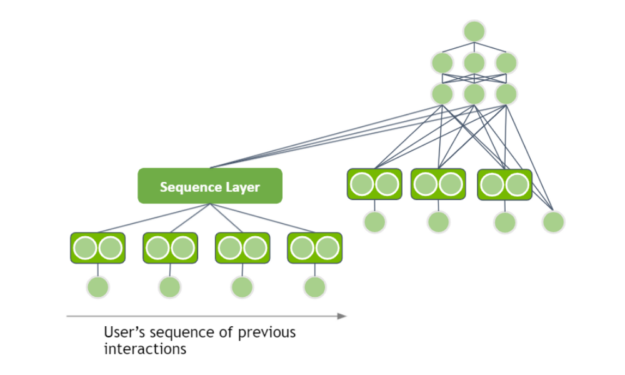
图 6 。基于会话的神经网络体系结构
序列可以通过使用递归神经网络( RNN )或基于变压器的结构作为序列层来处理。用嵌入向量表示项目 ID ,并通过序列层提供输出。序列层的隐藏表示可以添加为深度学习体系结构的输入。
其他选择
当我把这篇文章的重点放在将 DL 应用于推荐系统的理论上时,我没有涉及到很多其他的挑战。我在这里简要介绍一下,以提供一个起点:
嵌入表可以超过 CPU 或 GPU 内存。由于在线服务可能有数百万用户,嵌入表可以达到数兆字节。 NVIDIA 提供了 HugeCTR 框架,可以将嵌入表扩展到 CPU 或 GPU 内存之外。
在培训期间最大限度地利用 GPU 。基于 DL 的推荐系统有一个浅层的网络结构,只有几个完全连接的层。数据加载器有时是训练管道中的瓶颈。为了抵消这一点, NVIDIA 为 PyTorch 和 TensorFlow 开发了一个 高度优化的 GPU 数据加载器 。
生成建议需要对用户项对进行评分。最坏的情况是预测所有可用产品的可能性,并选择最佳产品。在实践中,这是不可行的,候选人产生了一个低开销的模型,如近似近邻。
概括
这篇文章向您介绍了基于 DL 的推荐系统。我首先介绍了基于两个输入的基本矩阵分解,然后介绍了使用 transformer 层的最新基于会话的体系结构。
您可以使用递归神经网络( RNN )或基于转换器的体系结构作为序列层来处理序列。用嵌入向量表示项目 ID ,并通过序列层提供输出。添加序列层的隐藏表示作为 DL 架构的输入。
关于作者
Benedikt Schifferer 是 NVIDIA 的深度学习工程师,致力于推荐系统。在他在 NVIDIA 的工作之前,他毕业于纽约哥伦比亚大学的数据科学硕士,并为德国电子商务公司开发了推荐系统。
审核编辑:郭婷
-
NMSIS神经网络库使用介绍2025-10-29 281
-
卷积神经网络简介:什么是机器学习?2023-02-23 25564
-
神经网络移植到STM32的方法2022-01-11 3278
-
图像预处理和改进神经网络推理的简要介绍2021-12-23 1533
-
基于BP神经网络的PID控制2021-09-07 2748
-
matlab实现神经网络 精选资料分享2021-08-18 1762
-
如何构建神经网络?2021-07-12 2026
-
【案例分享】基于BP算法的前馈神经网络2019-07-21 3407
-
卷积神经网络如何使用2019-07-17 2894
-
【PYNQ-Z2试用体验】神经网络基础知识2019-03-03 3988
-
神经网络系统辨识程序2018-01-04 1624
-
如何将脉冲耦合神经网络,体视学等结合实现药材显微图像的特征提取?2015-04-16 2772
-
粒子群优化模糊神经网络在语音识别中的应用2010-05-06 2579
-
神经网络在入侵检测系统中的应用2009-06-04 662
全部0条评论

快来发表一下你的评论吧 !
