

CPU和程序的执行
电子说
描述
关于CPU和程序的执行
1、程序的运行过程,实际上是程序涉及到的、未涉及到的一大堆的指令的执行过程。
当程序要执行的部分被装载到内存后,CPU要从内存中取出指令,然后指令解码(以便知道类型和操作数,简单的理解为CPU要知道这是什么指令),然后执行该指令。再然后取下一个指令、解码、执行,以此类推直到程序退出。
2、这个取指、解码、执行三个过程构成一个CPU的基本周期。
3、每个CPU都有一套自己可以执行的专门的指令集(注意,这部分指令是CPU提供的,CPU-Z软件可查看)。 正是因为不同CPU架构的指令集不同,使得x86处理器不能执行ARM程序,ARM程序也不能执行x86程序。(Intel和AMD都使用x86指令集,手机绝大多数使用ARM指令集)。 注:指令集的软硬件层次之分:硬件指令集是硬件层次上由CPU自身提供的可执行的指令集合。软件指令集是指语言程序库所提供的指令,只要安装了该语言的程序库,指令就可以执行。
4、由于CPU访问内存以得到指令或数据的时间要比执行指令花费的时间长很多,因此在CPU内部提供了一些用来保存关键变量、临时数据等信息的通用寄存器。
所以,CPU需要提供 一些特定的指令,使得可以从内存中读取数据存入寄存器以及可以将寄存器数据存入内存。 此外还需要提供加法、减、not/and/or等基本运算指令,而乘除法运算都是推算出来的(支持的基本运算指令参见ALU Functions),所以乘除法的速度要慢的多。这也是算法里在考虑时间复杂度时常常忽略加减法次数带来的影响,而考虑乘除法的次数的原因。
5、除了通用寄存器,还有一些特殊的寄存器。典型的如:
PC:program counter,表示程序计数器,它保存了将要取出的下一条指令的内存地址,指令取出后,就会更新该寄存器指向下一条指令。
堆栈指针:指向内存当前栈的顶端,包含了每个函数执行过程的栈帧,该栈帧中保存了该函数相关的输入参数、局部变量、以及一些没有保存在寄存器中的临时变量。
PSW:program status word,表示程序状态字,这个寄存器内保存了一些控制位,比如CPU的优先级、CPU的工作模式(用户态还是内核态模式)等。
6、在CPU进行进程切换的时候,需要将寄存器中和当前进程有关的状态数据写入内存对应的位置(内核中该进程的栈空间)保存起来,当切换回该进程时,需要从内存中拷贝回寄存器中。即上下文切换时,需要保护现场和恢复现场。
7、为了改善性能,CPU已经不是单条取指--》解码--》执行的路线,而是分别为这3个过程分别提供独立的取值单元,解码单元以及执行单元。这样就形成了流水线模式。 例如,流水线的最后一个单元——执行单元正在执行第n条指令,而前一个单元可以对第n+1条指令进行解码,再前一个单元即取指单元可以去读取第n+2条指令。这是三阶段的流水线,还可能会有更长的流水线模式。
8、更优化的CPU架构是superscalar架构(超标量架构)。这种架构将取指、解码、执行单元分开,有大量的执行单元,然后每个取指+解码的部分都以并行的方式运行。比如有2个取指+解码的并行工作线路,每个工作线路都将解码后的指令放入一个缓存缓冲区等待执行单元去取出执行。
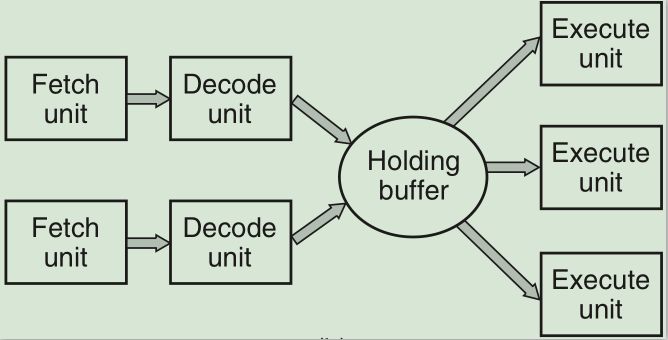
9、除了嵌入式系统,多数CPU都有两种工作模式:内核态和用户态。这两种工作模式是由PSW寄存器上的一个二进制位来控制的。
10、内核态的CPU,可以执行指令集中的所有指令,并使用硬件的所有功能。
11、用户态的CPU,只允许执行指令集中的部分指令。一般而言,IO相关和把内存保护相关的所有执行在用户态下都是被禁止的,此外其它一些特权指令也是被禁止的,比如用户态下不能将PSW的模式设置控制位设置成内核态。
12、用户态CPU想要执行特权操作,需要发起系统调用来请求内核帮忙完成对应的操作。其实是在发起系统调用后,CPU会执行trap指令陷入(trap)到内核。当特权操作完成后,需要执行一个指令让CPU返回到用户态。
13、除了系统调用会陷入内核,更多的是硬件会引起trap行为陷入内核,使得CPU控制权可以回到操作系统,以便操作系统去决定如何处理硬件异常。
关于CPU的基本组成
1、CPU是用来运算的(加法运算+、乘法运算*、逻辑运算and not or等),例如c=a+b。
2、运算操作涉及到数据输入(input)、处理、数据输出(output),a和b是输入数据,加法运算是处理,c是输出数据。
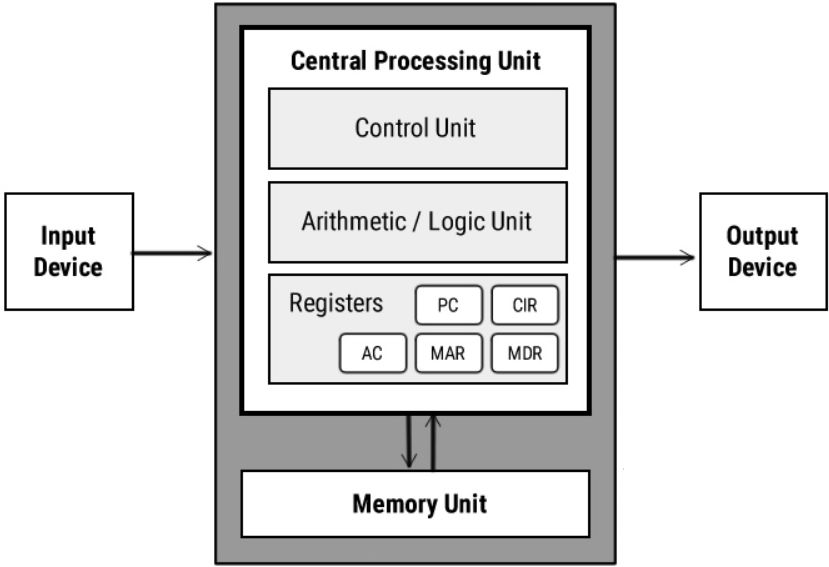
3、CPU需要使用一个叫做存储器(也就是各种寄存器)的东西保存输入和输出数据。以下是几种常见的寄存器(前文也介绍了一些)
MAR: memory address register,保存将要被访问数据在内存中哪个地址处,保存的是地址值
MDR: memory data register,保存从内存读取进来的数据或将要写入内存的数据,保存的是数据值
AC: Accumulator,保存算术运算和逻辑运算的中间结果,保存的是数据值
PC: Program Counter,保存下一个将要被执行指令的地址,保存的是地址值
CIR: current instruction register,保存当前正在执行的指令
4、CPU还要将一些常用的基本运算工具(如加法器)放进CPU,这部分负责运算,称为算术逻辑单元(ALU, Arithmetic Logic Unit)。
5、CPU中还有一个控制器(CU, Control Unit),负责将存储器中的数据送到ALU中去做运算,并将运算后的结果存回到存储器中。
控制器还包含了一些控制信号。
6、控制器之所以知道数据放哪里、做什么运算(比如是做加法还是逻辑运算?)都是由指令告诉控制器的,每个指令对应一个基本操作,比如加法运算对应一个指令。 7、例如,将两个MDR寄存器(保存了来自内存的两个数据)中的值拷贝到ALU中,然后根据指定的操作指令执行加法运算,将运算结果拷贝会一个MDR寄存器中,最后写入到内存。 8、这就是冯诺依曼结构图,也就是现在计算机的结构图。
关于CPU的多核和多线程
1、CPU的物理个数由主板上的插槽数量决定,每个CPU可以有多核心,每核心可能会有多线程。
2、多核CPU的每核(每核都是一个小芯片),在OS看来都是一个独立的CPU。
3、对于超线程CPU来说,每核CPU可以有多个线程(数量是两个,比如1核双线程,2核4线程,4核8线程),每个线程都是一个虚拟的逻辑CPU(比如windows下是以逻辑处理器的名称称呼的),而每个线程在OS看来也是独立的CPU。
这是欺骗操作系统的行为,在物理上仍然只有1核,只不过在超线程CPU的角度上看,它认为它的超线程会加速程序的运行。

4、要发挥超线程优势,需要操作系统对超线程有专门的优化。 5、多线程的CPU在能力上,比非多线程的CPU核心要更强,但每个线程不足以与独立的CPU核心能力相比较。
6、每核上的多线程CPU都共享该核的CPU资源。
例如,假设每核CPU都只有一个“发动机”资源,那么线程1这个虚拟CPU使用了这个“发动机”后,线程2就没法使用,只能等待。
所以,超线程技术的主要目的是为了增加流水线(参见前文对流水线的解释)上更多个独立的指令,这样线程1和线程2在流水线上就尽量不会争抢该核CPU资源。所以,超线程技术利用了superscalar(超标量)架构的优点。
7、多线程意味着每核可以有多个线程的状态。比如某核的线程1空闲,线程2运行。
8、多线程没有提供真正意义上的并行处理,每核CPU在某一时刻仍然只能运行一个进程,因为线程1和线程2是共享某核CPU资源的。可以简单的认为每核CPU在独立执行进程的能力上,有一个资源是唯一的,线程1获取了该资源,线程2就没法获取。 但是,线程1和线程2在很多方面上是可以并行执行的。比如可以并行取指、并行解码、并行执行指令等。所以虽然单核在同一时间只能执行一个进程,但线程1和线程2可以互相帮助,加速进程的执行。 并且,如果线程1在某一时刻获取了该核执行进程的能力,假设此刻该进程发出了IO请求,于是线程1掌握的执行进程的能力,就可以被线程2获取,即切换到线程2。这是在执行线程间的切换,是非常轻量级的。(WIKI: if resources for one process are not available, then another process can continue if its resources are available)
9、多线程可能会出现一种现象:假如2核4线程CPU,有两个进程要被调度,那么只有两个线程会处于运行状态,如果这两个线程是在同一核上,则另一核完全空转,处于浪费状态。更期望的结果是每核上都有一个CPU分别调度这两个进程。
关于CPU上的高速缓存
1、最高速的缓存是CPU的寄存器,它们和CPU的材料相同,最靠近CPU或最接近CPU,访问它们没有时延(《1ns)。但容量很小,小于1kb。
32bit:32*32比特=128字节
64bit:64*64比特=512字节
2、寄存器之下,是CPU的高速缓存。分为L1缓存、L2缓存、L3缓存,每层速度按数量级递减、容量也越来越大。
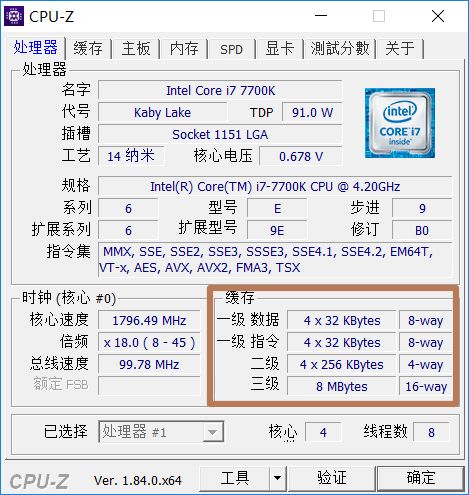
3、每核心都有一个自己的L1缓存。L1缓存分两种:L1指令缓存(L1-icache)和L1数据缓存(L1-dcache)。L1指令缓存用来存放已解码指令,L1数据缓存用来放访问非常频繁的数据。
4、L2缓存用来存放近期使用过的内存数据。更严格地说,存放的是很可能将来会被CPU使用的数据。
5、多数多核CPU的各核都各自拥有一个L2缓存,但也有多核共享L2缓存的设计。无论如何,L1是各核私有的(但对某核内的多线程是共享的)。
审核编辑 :李倩
-
CPU的各种指令和执行流程2025-04-18 3163
-
CPU中断程序:从硬件看什么是中断?2024-03-26 6864
-
cpu执行程序内部变化2023-12-05 1437
-
证明CPU指令是乱序执行的2023-03-15 1621
-
中断服务子程序是如何被执行的 ?2022-02-07 879
-
如何写出让CPU执行更快的代码?2020-10-29 3165
-
西门子PLC用于循环程序处理的组织块:循环程序执行的顺序2020-10-19 9370
-
如何理解plc执行程序的顺序?2020-05-01 14137
-
自制CPU(四)程序编写2018-07-16 8091
-
mfc程序执行流程小结,MFC程序的执行顺序2017-12-08 10229
-
什么是CPU分枝预测和推测执行技术?2010-02-04 982
全部0条评论

快来发表一下你的评论吧 !
