

TPU的系统架构
描述
简单解释:专门用于机器学习的高性能芯片,围绕128x128 16 位乘法累加脉动阵列矩阵单元(“MXU”)设计的加速器。如果这句话能为你解释清楚,那就太好了!如果没有,那么请继续阅读......
介绍
您可能听说过 Google 有一个用于机器学习的特殊芯片,它被称为 TPU(“Tensor Processing Unit,张量处理单元”),它构成了 Google 努力将尽可能多的机器学习能力放入单个芯片中。谷歌云为开发者提供了使用这种能力的机会,但芯片本身感觉是一个黑匣子……今天,让我们剥离这些隐藏的“面纱”,看看我们是否能看到魔法里面的东西。
在本文中,我将尝试讲解 TPU 的系统架构,同时保持足够简单,以使硬件经验最少的软件开发人员也能看懂。
高性能推理
训练和运行神经网络需要大量的计算能力。早在 2013 年,Google 进行了一些简单的计算,以了解他们需要什么来运行语音搜索,结果令人惊讶:
如果我们考虑人们每天只使用三分钟谷歌语音搜索的场景,并且我们在我们使用的处理单元上为我们的语音识别系统运行深度神经网络,我们将不得不将谷歌数据中心的数量增加一倍! — Norm Jouppi( Google 的杰出工程师。他以在计算机内存系统方面的创新而闻名)
ASIC
神经网络是强大的工具,但要在标准计算机上随处运行,它们的成本太高(即使对谷歌来说也是如此)。
值得庆幸的是,这不需要标准计算机来完成繁重的工作。在某些时候,设计一个定制芯片来承载这个任务变得具有成本效益。此定制芯片是专用集成电路(ASIC)。
通常,ASIC 带来的麻烦多于其价值。他们需要很长时间来设计:Google 花了15 个月的时间来开发 TPUv1,这个速度快得惊人。它们最初很昂贵,需要专门的工程师和大约一百万美元的制造成本。而且它们不灵活:一旦完成,就无法更换芯片设计。
但是,如果ASIC的数量足够,那么经济性的好处可以弥补最初的缺点。ASIC 通常是完成任务的最快、最节能的方式。谷歌希望这种性能能够运行神经网络,而 TPU 就是结果。
标量、向量、矩阵
神经网络需要大量的数学运算,但大多数数学运算都非常简单:将一堆数字相乘,然后将结果相加。可以在一个称为乘法累加(MAC) 的操作中将这两者连接在一起。如果我们不需要做任何其他事情,我们可以非常非常快地进行乘法累加。
如果没有新芯片,我们将使用 CPU 或 GPU 来实现。CPU 是一台标量机器,这意味着它一次处理一个指令。这非常适合通用应用程序,例如您的笔记本电脑或服务器,但我们可以通过专业化来挤出更多性能。
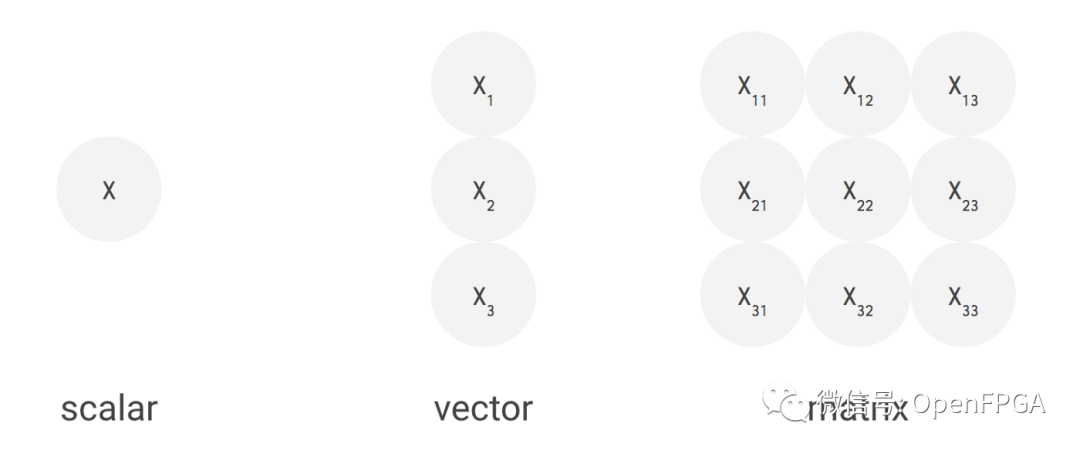
数据维度
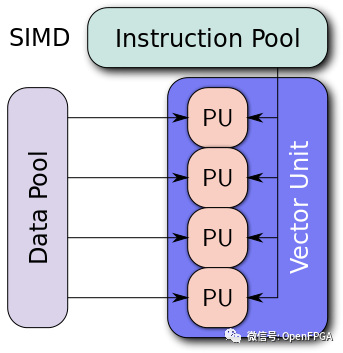
一个简化的向量架构
GPU 是一个向量机(vector machine)。你可以给它一个很长的数据列表——一个一维向量——并同时在整个列表上运行计算。这样,我们每秒可以执行更多的计算,但我们必须对数据向量并行执行相同的计算。这种计算非常适合图形或加密挖掘,其中一项工作必须执行多次。
但我们仍然可以做得更好。神经网络的数据以矩阵形式排列,即二维向量。因此,我们将构建一个矩阵机(matrix machine)。而且我们真的只关心乘法累加,所以我们会优先考虑处理器通常支持的其他指令。我们将把大部分芯片用于执行矩阵乘法的 MAC,而忽略大多其他操作。
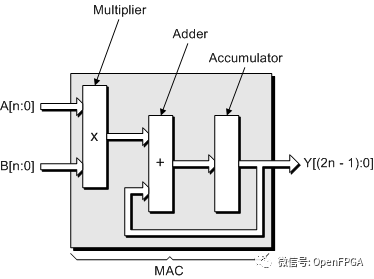
重复这个N 次,你就得到了图片
脉动阵列Enter the Systolic Array
提升矩阵计算性能的方法是通过一种称为脉动阵列的架构。这是有趣的一点,这也是 TPU 具有高性能的原因。脉动阵列是一种硬件算法,它描述了计算矩阵乘法的芯片上的单元模式。“Systolic”描述了数据如何在芯片中以波浪的形式移动,就像人类心脏的跳动。
TPU 中实现脉动阵列版本设计有一些变化。
考虑一个矩阵乘法运算:
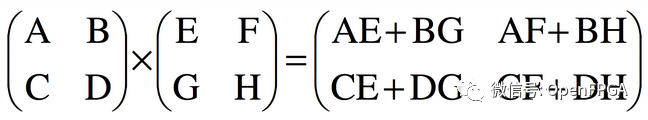
2x2 矩阵相乘
对于 2x2 输入,输出中的每一项都是两个乘积的总和。没有元素被重复使用,但个别元素被重复使用。
我们将通过构建一个 2x2 网格来实现这一点。(它实际上是一个网格,而不仅仅是一个抽象——硬件就是这样有趣)。请注意,2x2 是一个玩具示例,而全尺寸 MXU 是一个巨大的 128x128。
假设 AB/CD 代表我们的激活值,EF/GH代表我们的权重。对于我们的数组,我们首先 像这样加载权重:

稍后我将讨论我们如何做到这一点
接下来激活进入输入队列,在我们的示例中,该队列位于每一行的左侧。
注意用零填充:这可以确保数据在正确的时刻进入数组
每个时钟周期 ,每个单元都会并行执行以下步骤:
乘以我们的权重和来自左侧的激活。如果左侧没有单元格,则从输入队列中取出。
将该产品添加到从上面传入的部分总和中。如果上面没有单元格,则上面的部分总和为零。
将激活传递到右侧的单元格。如果右侧没有单元格,则丢弃激活。
将部分总和传递到底部的单元格。如果底部没有单元格,则收集部分总和作为输出。
上面的Python伪代码:
❝
https://github.com/antonpaquin/SystolicArrayDemo/blob/master/systolic.py
通过这些规则,可以看到激活将从左侧开始,每个周期向右移动一个单元格,部分和将从顶部开始,每个周期向下移动一个单元格。
数据流将如下所示:
这就是上面构建的阵列!让我们来看看第一个输出的执行:
周期 1
左上角从输入队列中读取 A,乘以权重 E 以产生产品 AE。
AE 从上面添加到部分和 0,产生部分和 AE。
激活 A 传递到右上角的单元格。
部分和 AE 传递到左下角的单元格。
周期 2
左下角从输入队列中读取 B,乘以权重 G 生成产品 BG
BG 从上面添加到部分和 AE,产生部分和 AE + BG
激活 B 传递到右下角的单元格
部分和 AE + BG 是一个输出。
可以看到我们已经正确计算了输出矩阵的第一项。同时,在第 2 周期中,我们还在左上角计算 CE,在右上角计算 AF。这些将通过单元格传播,到第 4 周期,将产生整个 2x2 输出。
这里有一些来自谷歌的图表,它们提供了更多的视觉画面。
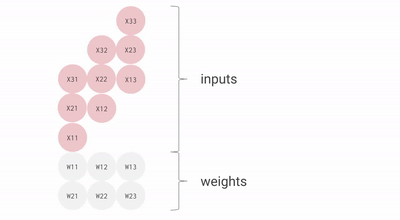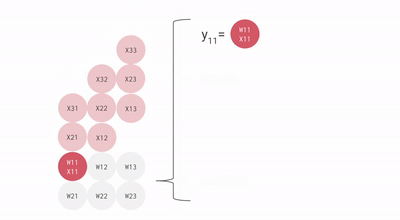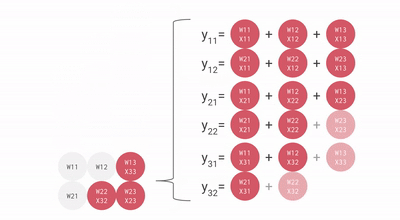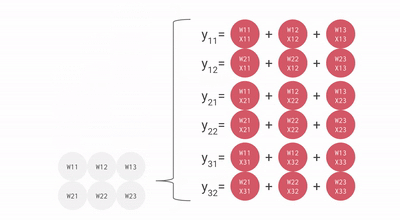
流经数组的数据动画。相对于本文中的其他图像,这个 gif 是转置的——顺时针旋转 90 度,然后水平翻转。
会看到输入激活与零交错,以确保它们在正确的时刻进入数组,并且离开数组的输出也同样交错。完全计算结果矩阵需要 3n-2 个周期,而标准的顺序解决方案是 n³。这是一个不错的结果,将计算量大大降低。
【科普】Xilinx 3D IC技术简介
谷歌的 MXU 图。
因为我们正在并行运行 128x128 MAC 操作。在硬件中实现乘法器通常很大且成本很高,但脉动阵列的高密度让 Google 可以将其中的 16,384 个装入 MXU。这直接转化为速度训练和运行网络。
权重的加载方式与激活方式大致相同——通过输入队列。我们只是发送一个特殊的控制信号(上图中的红色)来告诉数组在权重经过时存储权重,而不是运行 MAC 操作。权重保留在相同的处理元素中,因此我们可以在加载新集合之前发送整个批次,从而减少开销。
就是这样!芯片的其余部分很重要,值得一试,但 TPU 的核心优势在于它的 MXU——一个脉动阵列矩阵乘法单元。
TPU的其余部分
上面设计了出色的脉动阵列,但仍有大量工作需要构建支持和基础部分以使其运行。首先,我们需要一种将数据输入和输出芯片本身的方法。然后我们需要在正确的时间将它进出数组。最后,我们需要一些方法来处理神经网络中不是矩阵乘法的内容。让我们看看这一切是如何在硬件中发生的。
完整的系统
下面是旧 TPUv1 的系统图和布局模型。这些不一定适用于较新的 TPUv2 和 TPUv3 — 自本文档发布以来,Google 已经进行了一些架构更改。
在最高级别,TPU 被设计为加速器。这意味着它将插入主机系统,主机将加载要在加速器上计算的数据和指令。结果通过相同的接口返回给主机。通过这种模型,加速器(TPU)可以加速耗时且昂贵的矩阵运算,而主机可以处理其他所有事情。
让我们用一些框图来检查加速器内部的内容。我们将逐步介绍这些。
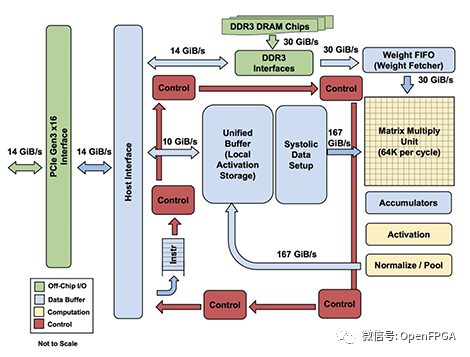
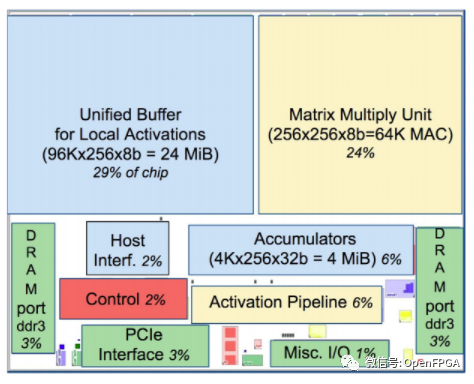
TPUv1 的系统图和布局模型
主机接口将通过 PCIe 连接到加速器(TPU)。我们可以看到通过这个接口传输 3 种形式的数据:权重(到DDR3)、激活activations(到统一缓冲区)和控制指令(到红色控制路径)。
批次中所有输入的权重相同,因此每批次将加载一次。与激活相比,这种情况很少见,因此可以将权重存储在速度较慢的片外DDR3 DRAM中。我们可以连接主机接口来写入这个 DDR3,当我们加载模型时我们会把所有的权重放在那里。在计算之前,权重从 DDR3 读取到权重 FIFO中,这意味着我们可以在计算当前批次时预取下一组权重。
统一缓冲区保存我们的激活。在操作期间,主机需要快速访问此缓冲区,以读取结果并写入新输入。统一缓冲器直接连接到MXU,这两个组件占据了芯片空间的最大份额(53%)。该缓冲区最多可容纳 384 个尺寸为 256x256 的激活矩阵,这将是芯片支持的最大批次。这些激活被非常频繁地读取和写入,这就是为什么我们将 30% 的布局专用于片上内存,以及 MXU 和统一缓冲区路径周围的 167 GiB/s 总线。
MXU 通过Accumulators写回统一缓冲区。首先,累加器从 MXU 中收集数据。然后,激活管道(Activation Pipeline)应用标准的神经网络函数(如 ReLU 和 Maxpool),这些函数的计算量不如矩阵乘法。完成后,我们可以将输出放回统一缓冲区,为下一阶段的处理做好准备。
然后是控制流:从主机获取指令的红色路径。该路径将执行诸如控制 MXU 何时乘法、权重 FIFO 将加载哪些权重或激活管道将执行哪些操作等操作。把它想象成告诉芯片的其余部分做什么的leader。
完整的流程如下:
1、芯片启动,缓冲区和 DDR3 为空
2、用户加载 TPU 编译的模型,将权重放入 DDR3 内存
3、主机用输入值填充激活缓冲区
4、发送控制信号将一层权重加载到 MXU(通过权重 FIFO)
5、主机触发执行,激活通过 MXU 传播到累加器
6、当输出出来时,它们通过激活管道运行,新层替换缓冲区中的旧层
7、重复 4 到 6 直到我们到达最后一层
8、最后一层的激活被发送回主机
TPUv1 推理的全貌。在较新的 TPUv2 中经历了类似的事情……
新一代 TPU 允许训练(即更新权重),因此需要有一条从 MXU 到重量存储。在 TPUv1 框图中,情况并非如此。
但是,只要知道 TPUv2 能做什么,我们就可以猜到一些不同之处:
TPUv1 中的 MXU 是一个 8 位整数 256x256 数组,比 TPUv2 中的 16 位 bfloat16 128x128 MXU 更大但精度更低。
TPUv1 中的激活管道被 TPUv2 中的全向量和标量单元所取代。与 TPUv1 中有限的“激活”和“标准化/池”相比,这些功能为其提供了更广泛的可用功能。
统一缓冲区似乎被高带宽内存所取代。这将为芯片的其余部分腾出一些空间,但代价是延迟。
这些差异主要是因为 TPUv1 是为推理而非训练而设计的,因此可以接受低精度算术和较少的操作。升级意味着新一代 TPU 更加灵活——足以让谷歌轻松地将它们布置在他们的云上。
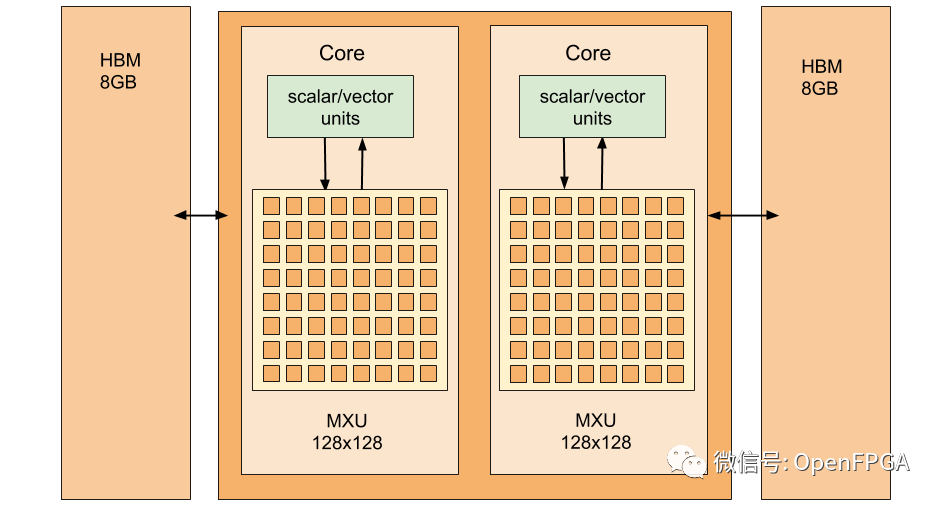
其他概念
bfloat16
大多数 CPU/GPU 机器学习计算都是使用 32 位浮点数完成的。当我们降到 16 位时,ML 工程师往往更担心数字的范围而不是精度。舍入小数点的几个分数是可以的,但是超出数字表示的最大值或最小值是一件令人头疼的事情。传统的 float16 精度很高,但范围不够。谷歌对此的回答是 bfloat16 格式,它有更多的位用于指数,而更少的位用于有效位。
为了比较,浮点数中的位是:
float32:1 位符号,8 位指数,23 位有效数
float16:1 位符号,5 位指数,10 位有效数
bfloat16:1 位符号,8 位指数,7 位有效数
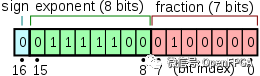
bfloat16.
因为它具有相同数量的指数位,所以 bfloat16 只是 float32 的两个高位字节。这意味着它的范围与 float32 大致相同,但精度较低。在实践中,这种策略效果很好。在 TPU 上,大部分数据仍以 float32 格式存储。但是,MXU 具有 bfloat16 乘法器和 float32 累加器。较小的乘法器降低了芯片的功率和面积要求,为更多以更快时钟运行的乘法器留出了空间。这提高了芯片的性能,而不会降低精度。
XLA
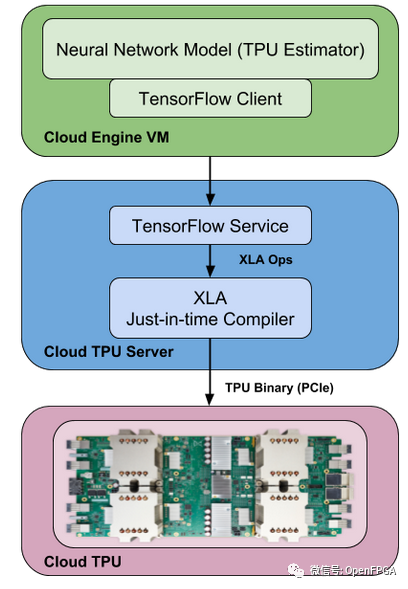
XLA 是一个用于 Tensorflow 后端的实验性 JIT 编译器。它将您的 TF 图转换为线性代数,并且它有自己的后端可以在 CPU、GPU 或 TPU 上运行。
Pods
Google云中的 TPU 存在于“pod”中,它们是具有大量计算能力的大型机架。每个 pod 可容纳 64 个 TPUv2 板,用于 11.5 petaflops的工作性能。
单个 TPU 通常不足以以所需的速度训练大型模型,但训练涉及频繁的权重更新,需要在所有相关芯片之间分配。Pod 使 TPU 保持紧密的网络连接,因此分布在 Pod 上的所有芯片之间的训练几乎可以线性扩展。
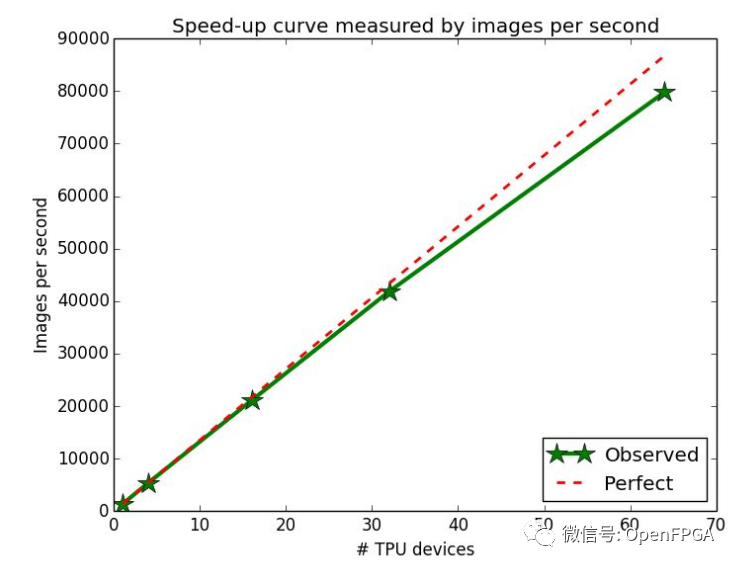
这种线性缩放是一个重要的原则。如果数据科学家想要更多的权力,他们会添加更多的芯片,没有任何问题。
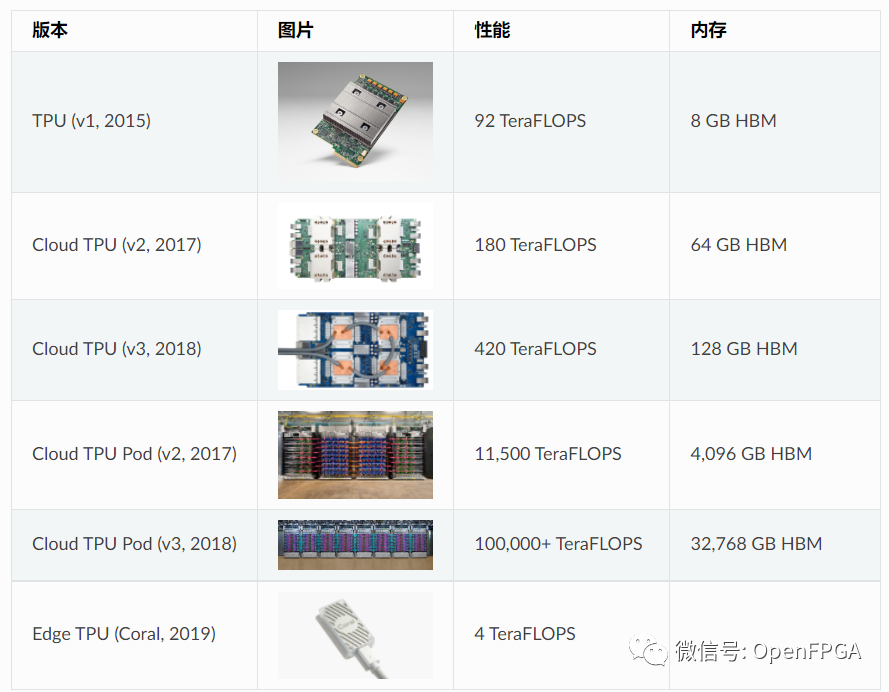
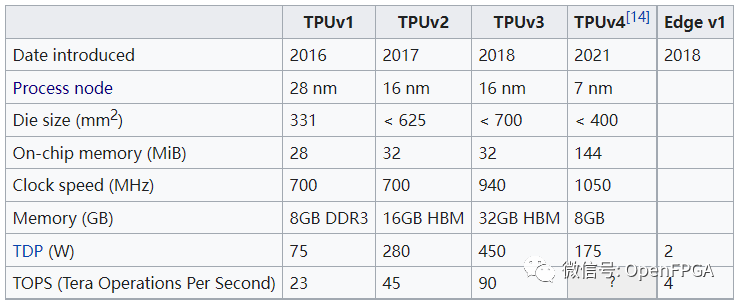
TPU发展历史
结论
这是我能找到有关TPU工作原理的所有信息,可能她并不完整,但是我希望你明白了TPU的工作原理。
TPU 是一个非常好的硬件,但它可能在 v1 出现之前就已经存在多年了。这主要是因为谷歌做了很多线性代数(由机器学习驱动),这种芯片在商业上变得可行。其他公司也抓住了这一趋势:Groq是 TPU 项目的衍生产品,英特尔希望尽快开始销售Nervana芯片,还有 更多的公司 希望加入竞争。专用硬件有望降低训练和运行模型的成本;希望这将加快我们创新的步伐。
审核编辑 :李倩
-
tpu材料的用途和特点2024-01-16 7135
-
TPU-MLIR开发环境配置时出现的各种问题求解2024-01-10 1125
-
谷歌发布多模态Gemini大模型及新一代TPU系统Cloud TPU v5p2023-12-12 2584
-
如何适配新架构?TPU-MLIR代码生成CodeGen全解析!2023-11-02 3157
-
Google的TPU芯片的发展历史和硬件架构2023-10-18 6239
-
TPU和NPU的区别2023-08-27 13025
-
TPU内存(二)2023-08-18 1170
-
如何验证MC68332 TPU配置是否正确?2023-05-09 887
-
采购TPU复牌料.复牌TPU原料.TPU复牌透明塑料.TPU废边料.TPU废膜料.TPU低温料2021-11-22 713
-
TPU透明副牌.TPU副牌料.TPU抽粒厂.TPU塑胶副牌.TPU再生料.TPU低温料2021-11-21 842
-
CORAL-EDGE-TPU:珊瑚开发板TPU2019-05-29 3695
-
tpu是什么材料_tpu硬度范围_tpu的应用2017-12-01 24792
全部0条评论

快来发表一下你的评论吧 !
