

用NVIDIA NeMo生成高质量的语音识别标签
描述
使用 NVIDIA NeMo 和 标签工作室 中的自动语音识别( ASR )模型处理音频数据时,可以节省时间并产生更准确的结果。
NVIDIA NeMo 提供了可重用的神经模块,使得创建新的神经网络架构变得容易,包括 ASR 的预构建模块和现成模型。借助 NVIDIA NeMo 的强大功能,您可以从预训练语音识别模型中获得音频转录。添加 labelstudio 及其开源数据标记功能,您可以进一步提高转录质量。
解决方案
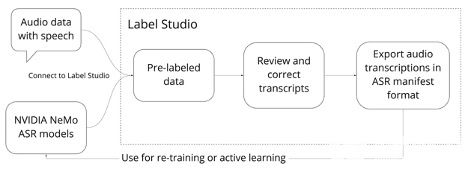
图 1 使用 Label Studio 和 NeMo 注释和更正转录本的 ASR 工作流。
按照本文中的步骤使用 Label Studio 设置 NVIDIA NeMo ASR ,以生成高质量的音频转录本。
连接 NVIDIA NeMo 模型,在 Label Studio 中自动转录音频文件。
设置音频转录项目。
从 Label Studio 验证和导出修订的音频转录本。
微调 NeMo ASR 模型与修改后的音频转录从标签工作室。
先决条件
开始之前,请确保您拥有以下资源:
音频数据文件。 此音频 MIG 可以是客户服务电话、电话订单、销售对话的录音,也可以是其他与人交谈的录音。音频文件必须采用以下文件格式之一:
WAV
AIFF
MP3
AU
FLAC
已安装 Label Studio 。 在本地计算机或云服务器上使用首选方法安装 Label Studio 。有关更多信息,请参阅 Label Studio 文档中的 Quickstart 。
NeMo 工具箱已安装
免费音频数据
如果您没有任何音频数据,可以使用示例数据集或历史音频数据集:
LJ 语音数据集 是非小说类书籍段落的公共域数据集。
Librispeech 还提供了一个 基于开放 SLR 的开源 ASR 语料库 。
您可以使用许多其他 ASR 数据集。有关详细信息,请参阅 数据集 – 简介 。您还可以使用国会图书馆网站上的公共域录音集,如 美国棒球运动员访谈录 。
确定要转录的音频后,就可以开始处理它了。
安装 Label Studio ML 后端
安装 Label Studio 后,请安装 Label Studio 机器学习后端。从命令行运行以下命令:
git clone https://github.com/heartexlabs/label-studio-ml-backend
设置环境:
cd label-studio-ml-backend # Install label-studio-ml and its dependencies pip install -U -e . # Install the nemo example dependencies pip install -r label_studio_ml/examples/requirements.txt
连接 NVIDIA NeMo 模型,在 Label Studio 中自动转录音频文件
要使用预先训练的 ASR 模型的预测对数据进行预标记,请在 Label Studio 中将 NeMo 工具箱设置为机器学习后端。 Label Studio 机器学习后端允许您使用预先训练的模型来预标记数据。
Label Studio 包括使用 利用 NGC 云中的 NeMo 开发的预训练 QuartzNet15x5 模型 的 一个例子 ,但是如果另一个模型更适合,您可以用您的数据设置一个不同的模型。有关更多信息,请参阅 NeMo 提供的 ASR 型号列表 。
在命令行中,将 NeMo 设置为机器学习后端,并使用该模型启动一个新的 Label Studio 项目。
安装 NeMo 工具箱 在 Docker 容器中或使用 pip 。
下载 NeMo ASR 模型。提供的 Label Studio 示例脚本从 NGC 云下载预先训练的 QuartzNet 模型。要使用不同的模型,请从 NGC 下载该模型。
从命令行启动 Label Studio 机器学习后端。
label-studio-ml init my_model --from label_studio_ml/examples/nemo/asr.py
启动机器学习后端。默认情况下,模型在本地主机上以端口 9090 启动。
label-studio-ml start my_model
用模型启动 Label Studio 。
label-studio start my_project --ml-backends http://localhost:9090
设置音频转录项目
启动 Label Studio 后,导入音频数据并设置正确的模板来配置标签。 VZX19 是自动语音识别的最佳选择,它使音频数据的注释变得容易。
打开 Label Studio ,导入数据,然后选择模板。
选择 Import 并以纯文本或 JSON 文件的形式导入音频数据,这些文件引用在线存储(如 Amazon S3 )中托管的音频文件的有效 url 。
2 从 Tasks 列表中,选择 Settings 。
3 在 标签界面 选项卡上,浏览模板并选择 自动语音识别 模板。
4 选择 Save 。
验证并输出模型预测
作为注释器,检查任务界面上音频数据的任务并验证。如有必要,纠正 NeMo 语音模型预测的转录本。
从 Label Studio 中的任务列表中,选择 Label 。
对于每个音频样本,聆听音频并回顾 NeMo 模型产生的转录,作为预标记过程的一部分。
如果成绩单中有任何单词不正确,请更新。
保存对成绩单的更改。选择 Submit 提交成绩单并查看下一个音频样本。
接下来,按照 NVIDIA NVIDIA 文档中的 NeMo ASR 集合 所述,以 NeMo 模型所期望的正确格式从 Label Studio 导出完成的音频转录本。
要导出完成的音频,请执行以下操作:
从 Label Studio 中的任务列表中,选择 Export 。
选择名为 ASR_MANIFEST 的音频转录 JSON 格式。
有关 Label Studio 中可用导出格式的详细信息,请参阅 从 Label Studio 导出结果 。
使用高质量的成绩单来微调您的 ML 模型
当您处理完音频并调整完转录的文本后,剩下的是音频转录本,您可以用来重新培训 NeMo 中包含的 ASR 模型。 Label Studio 生成与 NeMo 培训完全兼容的注释。
要更新 QuartzNet 模型检查点,您可以在几行代码中完成,从头开始训练模型,或者使用 PyTorch Lightning 。例子也可以在 NeMo Jupyter 笔记本中找到。
通过同时使用 Label Studio 和 NeMo ,您可以节省从头开始处理每个音频文件的时间 NeMo 可以立即为您提供高度准确的预测,而 Label Studio 可以帮助您实现完美的预测 今天就试试 !
关于作者
Nikolai Liubimov是Heartex的CTO。 完成博士学位后 他在CS担任机器学习研究员,后来进入该行业,并花了10年的时间将深度学习技术应用于现实世界中的问题。 这项经验为当前缺少哪些工具提供了宝贵的见解,从而创建了一家初创公司来帮助数据科学和机器学习工程团队构建和改进其ML模型。
Sarah Moir是Heartex的产品内容和教育主管,为Heartex的数据注释和标签解决方案撰写文档,博客文章和教育教程。 萨拉(Sarah)在过去的八年中一直是数据和安全领域的技术作家,并且对数据分析,机器学习和编写充满热情。
审核编辑:郭婷
-
protel输出高质量gerber2011-12-12 26413
-
高质量C++、C编程指南2012-08-06 5126
-
高质量C&C++2012-08-16 2751
-
高质量C语言编程2013-07-22 14044
-
编写高质量C语言代码2013-07-31 4767
-
林锐《高质量C语言编程》2013-08-17 2467
-
高质量编程2016-02-27 7273
-
请问怎么才能设计出高质量的印制线路板?2021-04-23 1530
-
中国联通:2019全网开通VoLTE,确保5G高质量语音2019-03-15 7446
-
用Riva和NeMo Megatron构建语音AI2022-03-31 2274
-
NVIDIA通过NeMo 1.0加速会话AI从研究到生产过程2022-04-01 1834
-
采用人工智能技术的高质量合成语音开发和定制2022-04-08 2197
-
NVIDIA CloudXR将提供高质量的XR流媒体2022-04-17 1844
-
语音合成数据的重要性:训练高质量语音合成模型的关键2023-05-15 1977
-
生成高质量 3D 网格,从重建到生成式 AI2023-08-17 1669
全部0条评论

快来发表一下你的评论吧 !
