

通过Sim2SG模型生成sim-to-real转移学习场景图
描述
场景图( scenegraphs , SGs )在计算机视觉和计算机图形学中都是一种可解释的、结构化的场景表示。场景图总结了场景中的实体以及它们之间的合理关系。 SGs 在计算机视觉、机器人、自主车辆等领域有着广泛的应用。
当前的 SG 生成技术依赖于昂贵的标记数据集的有限可用性。合成数据是解决这个问题的一个可行的选择,因为注释基本上是免费的。尽管合成数据已被用于图像分类、目标检测和语义分割等多种任务,但合成数据用于 SG 生成和视觉关系仍有待探索。由于合成数据和真实数据在外观和内容上的差异,在有标记的合成数据上训练神经网络模型,在无标记的真实数据上进行评价,这就导致了领域差距问题。
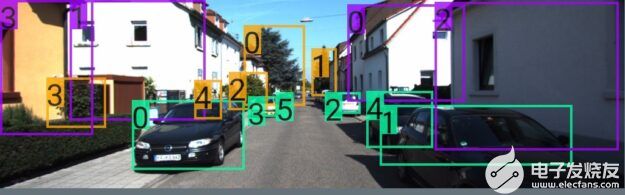
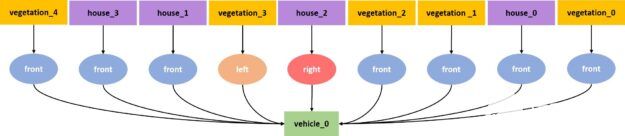
图 1 场景图显示场景中的各种对象,如车辆、植被、房屋以及它们之间的关系。
Sim2SG 框架
为了克服这些挑战,我们提出了 Sim2SG ,一种可扩展的 sim-To-real 场景图生成技术。本研究的主要目的是通过在含有标记 SG 信息的模拟数据集上训练神经网络,然后将学习到的模型转换到真实数据集上,从真实世界的图像中生成场景图。
在训练过程中, Sim2SG 处理域间隙并学习生成场景图。域间隙可细分为以下间隙:
外观间隙 是两个域的外观差异,例如场景中对象的纹理、颜色、光照或反射率的差异。
内容差距 是指两个域之间的差异,包括对象数量分布的差异及其类别、位置、姿势和比例。
我们进一步分析了内容差距,并解决了其子组成部分 – 标签和预测差异。图 1 显示了 Sim2SG 为真实世界的驾驶数据集生成精确的场景图,图 2 显示了整个管道。
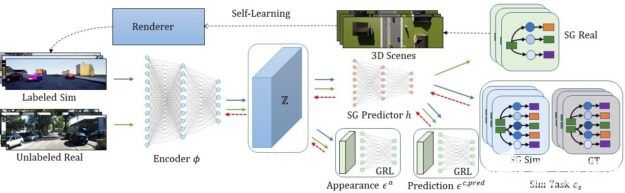
图 2 Sim2SG 管道工作流。
在图 2 中, Sim2SG 管道将来自源域的带标记的合成数据和来自目标域的未标记的真实数据作为输入。使用编码器将标记的合成数据和未标记的真实数据映射到共享表示 Z 。然后,我们使用合成数据在 Z 上训练场景图预测网络 h 。我们使用基于伪统计的自学习方法来处理标签差异,生成标签对齐的合成数据以供训练。我们进一步利用梯度反转层( GRL )和域鉴别器的对抗性技术来调整两个域之间的预测差异和外观差异。
定量评价
我们使用了四种类型:汽车、行人、植被和房屋,以及四种类型的关系:前、左、右和后。所有的关系都以汽车为主题。
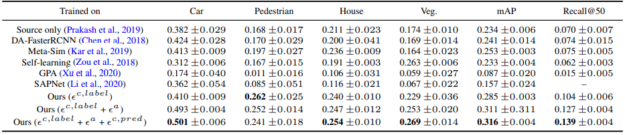
表 1 在人工驾驶环境下训练时对 KITTI hard 的评估。类特定的 AP 和 mAP 报告为 0 。 5iou 。
表 1 显示了与基线相比,标签对齐和外观对齐在所提出的方法中如何显著地减少域间隙。我们将 Sim2SG 与基于随机化的方法( Prakash et al 。, 2019 )、解决内容差距的方法( Kar et al 。, 2019 )、基于伪标签的自学习方法( Zou et al 。, 2018 )和用于目标检测的域自适应方法( Chen et al 。, 2018 ; Xu et al 。, 2020 ; Li et al 。, 2020 )进行了比较。通过结合标签、外观和预测对齐(最后一行),域间隙进一步减小。
定性评价
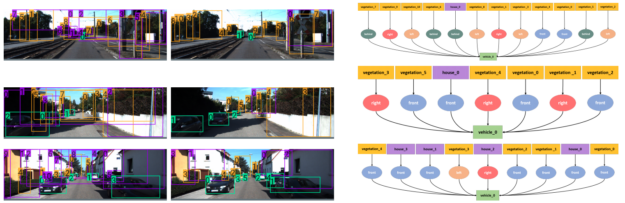
图 3 Sim2SG 在目标域上的定性结果。
图 3 显示了 Sim2SG 在目标域上的定性结果。第一列显示仅源基线无法检测到对象或具有大量误报(错误标记),从而导致场景图不佳。我们的方法能够更好地检测对象,具有更少的误报,并最终生成更精确的场景图,分别如第二列和第三列所示。这是因为外观对齐项减少了假阳性检测。此外,标签对齐项还提高了检测性能,因为它有助于生成用于训练的合成数据,这些数据与目标域的标签对齐程度更高。图 4 显示了一些与目标域样本相对应的标签对齐的合成重建。

图4 基于标签对齐的驾驶环境中目标 KITTI 样本的综合重建。基蒂样品(右)和相应的合成样品(左)。
概括
在这项工作中,我们提出了 Sim2SG ,一个模型,实现了 sim-to-real 转移学习场景图生成上未标记的真实世界数据集。我们将域间隙分解为合成域和真实域之间的标记、预测和外观差异。我们提出了解决这些差异的方法,并在所有三种环境( Clevr 、 dinning-Sim 和 Drive-Sim )中实现了基线的显著改进。
关于作者
Aayush Prakash 是多伦多人工智能实验室的高级研究员。他的研究兴趣在于机器学习、计算机视觉和计算机图形学的结合点。具体来说,他致力于模拟现实问题的感知。他想通过模拟训练有效的真实世界模型。在 NVIDIA 之前,他是多伦多 IBM 实验室的一员,在那里从事编译器的工作,这是他过去一直感兴趣的另一个领域。他于 2010 年毕业于印度哈拉格布尔印度理工学院( IIT ),获得电子 CTR 和电子 CTR 通信工程学士学位, 2013 年毕业于加拿大滑铁卢大学计算机工程硕士学位。
Shoubhik Debnath 是 NVIDIA 的研发工程师,致力于机器人技术、仿真和深度学习。他于 2014 年毕业于印度曼迪印度理工学院( IIT )计算机科学与工程理学学士学位,并于 2018 年在南加州大学 Gaurav Suhkatme 教授的指导下获得计算机科学硕士学位,专注于机器人研究。此前, Shoubhik 还在微软工作了两年,专注于数据科学和基于云的技术。
Jean-Francois Lafleche 是一位充满干劲和激情的工程师,热爱用创新的解决方案解决复杂的挑战。他是一个自学成才的终身学习者,拥有广泛多样的技能,专注于机器学习和机器人应用。
Eric Cameracci 是滑铁卢大学计算机工程专业的 2015 届毕业生。
Gavriel State 是 NVIDIA 系统软件团队的高级主管。他在多伦多工作,除了为 NVIDIA SHIELD TV 平台重新制作游戏外,还负责将 AI 技术应用于游戏,反之亦然。此前, Gavriel 成立了 TransGaming , Inc ,并花了 15 年时间专注于游戏和渲染技术。
Marc T. Law 是 NVIDIA 的高级研究科学家,致力于机器学习和计算机视觉。他在加拿大多伦多人工智能实验室工作,由 Sanja Fidler 教授领导。 2015 年,他获得法国巴黎皮埃尔玛丽居里大学(现为索邦大学)计算机科学博士学位。他的博士生导师是马蒂厄·科德教授和斯蒂芬·甘萨尔斯基教授,他还受到尼古拉斯·托马斯教授的指导。 Marc 曾于 2015 ~ 2016 年在卡内基梅隆大学计算机学院任 Eric Xing 教授团队访问研究学者。 2016 年至 2019 年,他在多伦多大学和向量研究所计算机科学系(机器学习组)担任博士后研究员,由 Raquel Urtasun 教授和 Richard Zemel 教授指导。
审核编辑:郭婷
-
探索具身智能边界,地瓜机器人邀你共战ICRA 2025 Sim2Real挑战赛2025-01-13 1308
-
苹果为何总想消灭SIM卡?电子学习 2023-02-08
-
SIM卡PCB封装+原理图2022-05-11 7901
-
NVIDIA DRIVE Sim摄像头模型的验证2022-04-18 4240
-
SIM 8PIN全塑带铁盖翻盖式SIM-215-P8原理图2022-01-05 1409
-
SIM卡座电路原理图的说明2021-12-22 11016
-
MICRO与SIM NANO和TF卡座三合一的SIM卡座规格原理图2020-01-09 3135
-
MICRO和SIM与NANO和TF贴片接插件的SIM卡座规格原理图2020-01-06 2730
-
NANO SIM卡座与MICRO SIM卡座的差别2018-09-13 10699
-
sim900a模块简介_sim900a原理图2018-05-30 160816
-
sim900的原理图2016-01-15 1578
-
SIM900A原理图2015-12-21 6091
-
SIM300应用文档:SIM300与SIM100S的区别2009-09-28 1409
-
sim卡电路图2008-07-13 9243
全部0条评论

快来发表一下你的评论吧 !
